本内容是对知名性能评测博主 Anton Putra TCP vs UDP performance (Round 3) 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准
在本期视频中,我们将再次对比 TCP 和 UDP,这次重点关注吞吐量。
多亏了几天前我收到的一个 PR,我成功将 TCP 和 UDP 的吞吐量提高了 10 倍。TCP 的吞吐量从 每秒 100 万条消息 增加到了 1000 万条,而 UDP 则从 每秒 30 万条 增长到了 300 万条。
我认为这是使用标准 Linux API 能够达到的最优成绩。
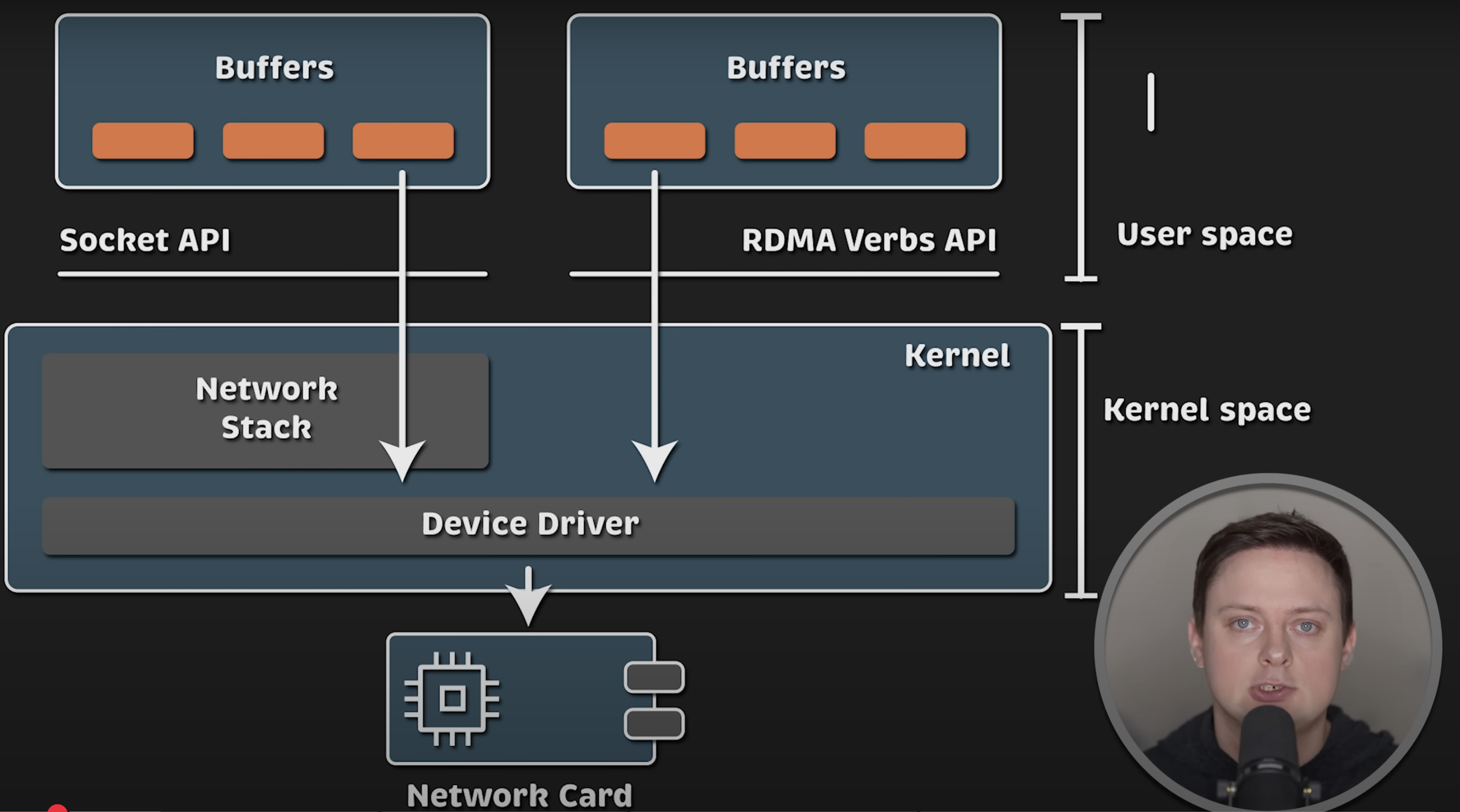
如果这还不够,你可以绕过内核,直接与网卡交互,这在高频交易系统中非常常见,我以后也会讲到这一点。
有关 Payload(负载)
首先我们来谈谈 payload。我使用的是一个 JSON 消息,服务器将其发送给客户端,并统计每秒发送和接收的消息数量。
虽然 JSON 不适用于高性能应用,但这对我的测试来说并不重要。让我解释一下原因:
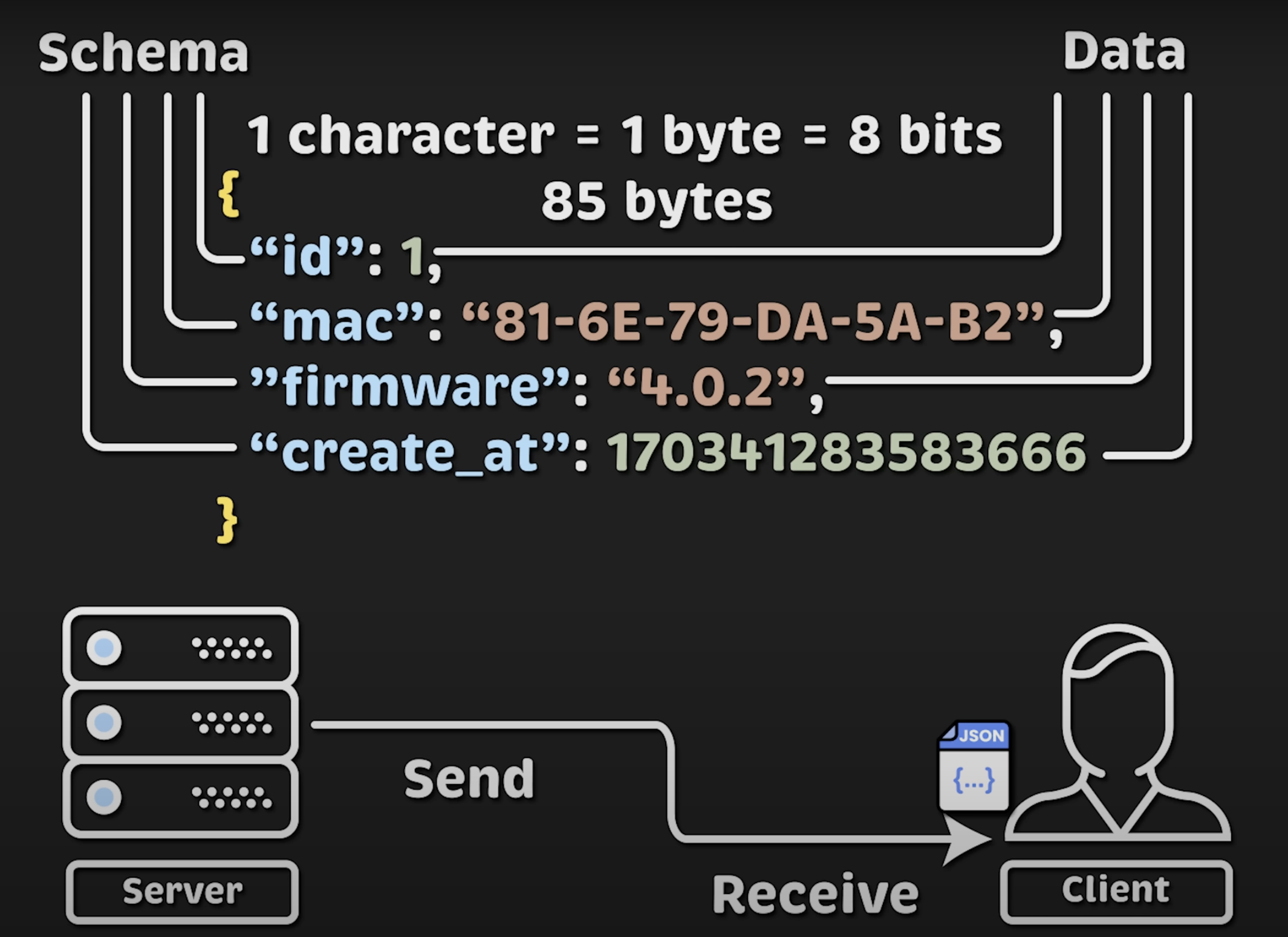
JSON 包含一个结构体,键值对共同组成一个对象。每个字符占用 1 字节(8 位)。所以,去掉空格后,整个 JSON 消息大小为 85 字节。
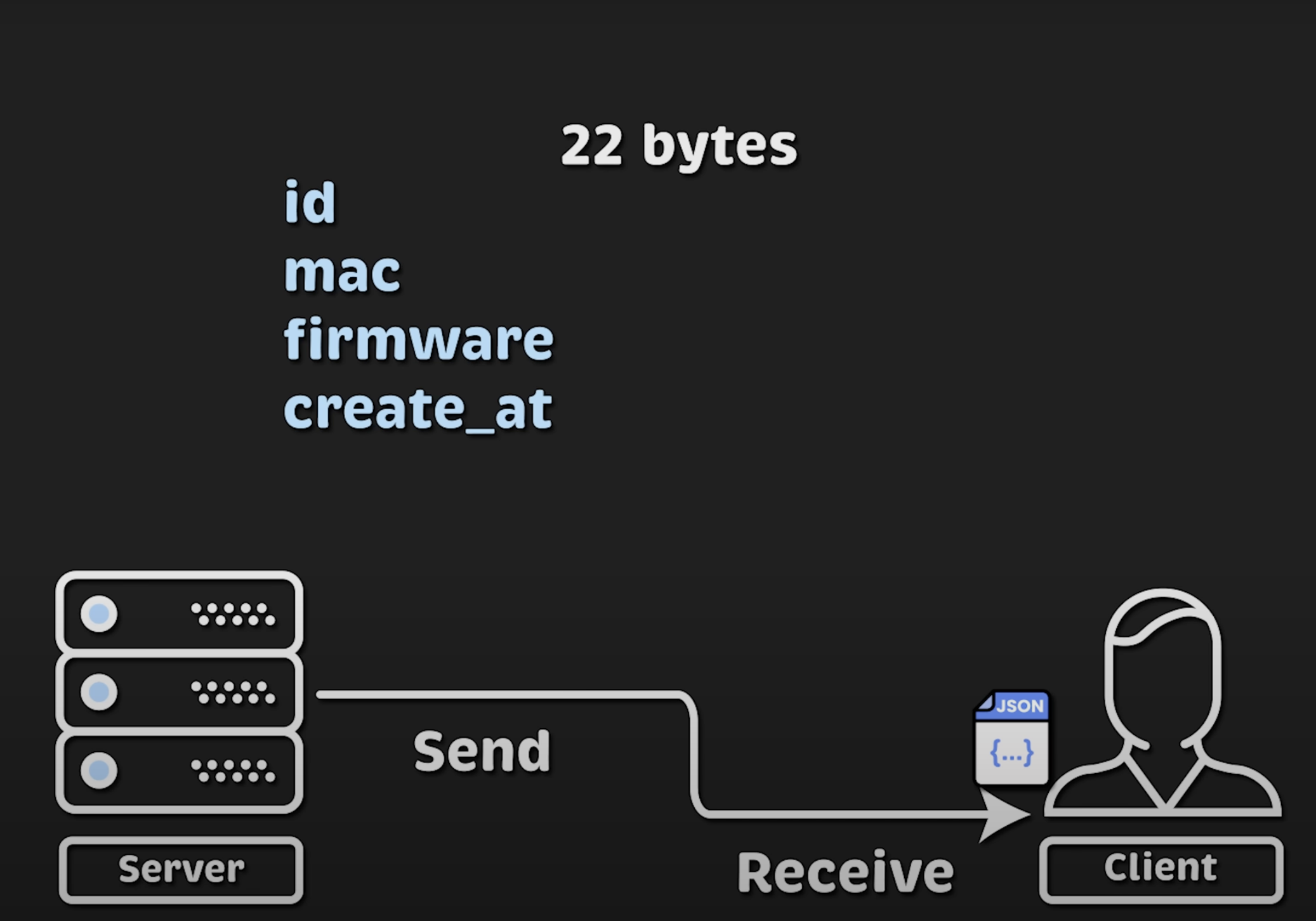
其中光是键名就占了 22 字节,如果加上双引号(JSON 语法要求),就是 30 字节,约占整个消息大小的 35%。

当我们向客户端发送多条消息时,每次都重复这些键名,会浪费 35% 的空间。如果我们去掉这部分开销,就可以将这 35% 的空间转化为 吞吐量提升。
为了解决这个问题,可以使用诸如 RPC 等二进制格式。在这种格式中,你可以预定义所有键的结构,并用它来序列化消息。

比如,相同的 JSON 消息,用 RPC 序列化后只有 38 字节,几乎是原来的一半大小。
换句话说,只需要发送 38 字节的数据给客户端,吞吐量就可以翻倍。

在我的测试中,我选择了一个固定的 payload 大小:85 字节。
最重要的是,我对 TCP 和 UDP 都使用完全相同的消息,并没有解析 JSON。你可以把它看作是简单的文本,我只是把它发送给客户端。
我没有使用 RPC,是因为这会涉及额外的库,并使示例变得复杂,而对我的测试并没有明显好处。
什么是 MTU?
当我们使用底层网络库时,需要了解一个概念:MTU(最大传输单元)。
MTU 表示一次网络传输中,数据包最大字节数。超过这个大小的数据会被分片。
在互联网上发送数据时,通常的 MTU 是 1500 字节,这是 广域网(WAN) 的标准。
但 MTU 并不是固定的,在本地网络中你可以修改它。
比如在 AWS 或 GCP 的 VPC 中,你可以选择任意大小。
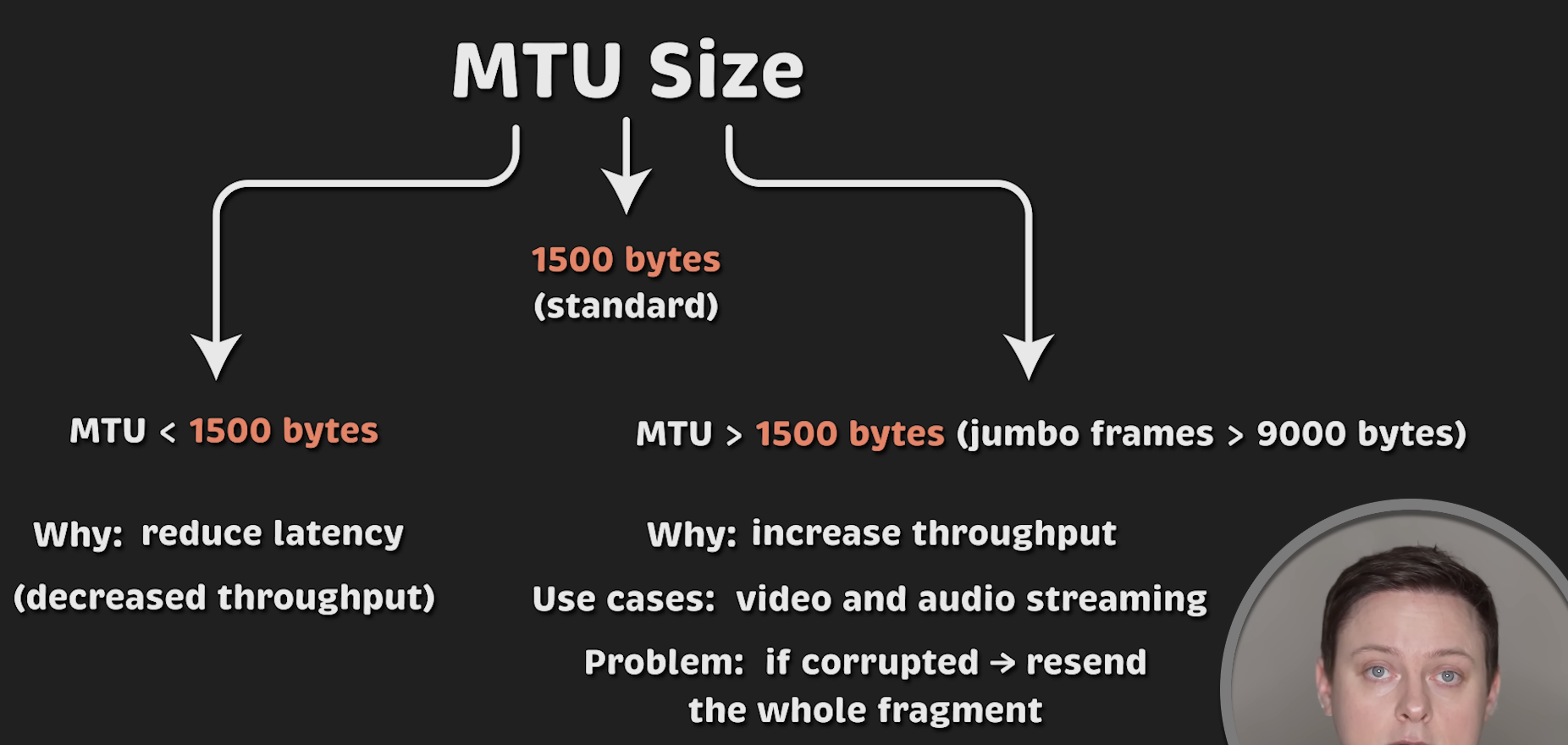
关于 MTU 大小的选择,有以下几点考虑:
- 较小的 MTU 可以降低延迟。因为 TCP 默认会将你的消息缓存,直到达到 1500 字节才发送。
- 减小 MTU 会减少延迟,但也会降低吞吐量。
- 你也可以使用更大的 MTU,比如 Jumbo Frame(巨帧),大小在 9000 字节左右。
- 这样可以在一次传输中发送更多数据,减少分片和重组带来的开销。
- 常见的应用场景包括:视频、音频流媒体传输以及数据备份。
不过,使用更大的 MTU 时要注意:如果整个 9000 字节的数据包损坏,就需要重传整个数据包。1500 字节的 MTU 也会有这种情况,但需要重传的数据量更少。
优化与错误
现在来说说我的一些错误和优化方式。
我们先从 TCP 开始。
如前所述,我使用的是 85 字节的 JSON 消息,并通过 send 系统调用发送给客户端,同时使用的是默认的 1500 字节 MTU。
实际上,去掉头部后,实际可传输的数据量是 1432 字节。
在测试中,每次我通过 send 发送消息时,内核会缓存这些消息,直到它们达到 MTU 大小,再一次性发送给客户端。
你可以通过设置 TCP_NODELAY 来关闭这个行为。
但即使关闭了,我们仍然有一个 1432 字节的缓冲区。要用 85 字节的消息填满它,大约需要 16 次 send 系统调用。
所以第一个优化是:提前合并这些消息,然后一次性调用 send,从而大幅减少系统调用的开销。

在客户端,我使用的 receive 函数每次只读取一个消息的大小。
这意味着即使服务器一口气发来了 16 条消息,客户端仍然要调用 16 次 receive,增加了开销。
解决方法是:使用一个可以容纳整个数据片段的缓冲区,一次性读取整个数据,然后再从缓冲区中逐条解析。
UDP 方面也类似,不过 UDP 在发送时没有任何延迟机制。
为了提升 UDP 吞吐量,我们也可以采用相同的逻辑:填满整个缓冲区后,一次性发送。
这确实能提升吞吐量,但也会增加延迟,因此这是一个需要权衡的选择。
测试
首先,我在 AWS 上使用了 m7a.medium 实例 作为服务器和客户端。
我先运行一个未优化版本的测试代码,其中包含很多不必要的系统调用,并且没有对 UDP 消息进行缓冲。
这次,我不再逐步增加负载,而是直接以最大负载运行 TCP 和 UDP。
你会发现结果与之前的测试几乎一样:
- UDP 约为 42 万请求每秒
- TCP 超过 100 万请求每秒

虽然 UDP 延迟更低,但因为 TCP 有更好的拥塞控制机制,所以 TCP 在吞吐量上更胜一筹。
接着我重启测试,运行优化后的 TCP 和 UDP 实现。
这次:
- UDP 达到了 650 万条消息/秒
- TCP 达到了 750 万条消息/秒
如果你查看网络吞吐量,会发现:
- TCP 达到了带宽上限,无法超过 5Gbps
- 而 UDP 没有这个限制
从 CPU 使用率图表来看,UDP 已经满负荷运行,而 TCP 的服务器和客户端只用了大约 60% 和 70% 的 CPU。
所以我推测:如果没有带宽限制,TCP 可能还可以提升 30% 的吞吐量。
根据 AWS 官方文档,EC2 实例的网络带宽上限是 12.5 Gbps,而我只达到了 5 Gbps。

于是我尝试换用更大的实例。
虽然 AWS 上说 m7a.large 实例的网络带宽与 medium 实例一样,但我还是希望它能超过 5Gbps。
我更新了基础设施,把 medium 实例换成了 large 实例,并重新运行测试。
因为是单线程程序,最多只能使用 50% 的 CPU(这些实例有 2 个 CPU),但问题仍然存在:带宽仍被限制在 5Gbps。
为了完全透明,我展示了我的 Grafana 仪表板,用 node_exporter 来测量网络吞吐量。
下一个不受限制的选项是使用 8xlarge 实例,但我最终选择使用我的 homelab 来完成这次测试。
我的 homelab 基于 AMD EPYC 处理器,并使用 VMware 创建虚拟机。
我仍然创建了 4 个实例,但请注意:我的服务器比 m7a 实例稍慢,所以数值会略低。
首先,我运行了未优化版本,结果是:
- UDP 为 33 万
- TCP 为 100 万
这与之前测试一致。
接着,我运行了优化后的版本,并且网络不再是瓶颈。
你可以看到:
- TCP 达到了 1000 万条消息/秒
- UDP 稍低一些,约为 350 万条消息/秒
TCP 的网络吞吐量也超过了 6Gbps。
总结
测试到此结束。(译者注: 下面两行堪称金句)
-
TCP 由于拥塞控制机制,拥有更高的吞吐量;
-
UDP 因为没有连接和确认机制,延迟更低。