在快速发展的人工智能领域,大语言模型(LLMs)正成为各类应用的核心。无论是在智能客服、内容生成,还是在教育与医疗等领域,这些模型的应用潜力巨大。然而,云端服务的高昂费用和数据隐私的担忧,让越来越多的用户希望能够在本地环境中部署这些强大的模型。本文将详细介绍如何利用多款优秀的软件工具,包括 Ollama、LM Studio、GPT4All、LLaMA.cpp、NVIDIA Chat with RTX、Llamafile、ChatTTS、GPT-SoVITS,以及 Stable Diffusion 进行本地部署。
一、环境准备
在开始部署大语言模型之前,需要确保您的计算机环境满足以下基本要求:
- 操作系统:Windows、MacOS 或 Linux。
- 硬件要求:建议至少有 16GB 内存和一块支持 CUDA 的 NVIDIA GPU,以便加速模型推理。
- 软件依赖:Python 3.8 及以上版本,CUDA 工具包(如果使用 NVIDIA GPU),以及相关的库和工具(如 CMake、Make 等)。
二、工具软件
1、 Ollama
Ollama 是一种命令行界面 (CLI) 工具,可快速操作大型语言模型, 支持在 Windows、Linux 和 MacOS 上本地运行大语言模型的工具。它允许用户非常方便地运行和使用各种大语言模型,比如 Qwen 模型等。用户只需一行命令就可以启动模型。主要特点包括跨平台支持、丰富的模型库、支持用户上传自己的模型、支持多 GPU 并行推理加速等。
特点优势:
- 多模型支持:Ollama 支持流行的语言模型,如 GPT、LLaMA 等,用户可根据需求选择。
- 安装简便:只需简单的命令行操作即可完成安装,配备详细文档,适合新手使用。
- 高效性能:本地运行时能提供更低的延迟和更快的响应速度,提升用户体验。
- 社区支持:活跃的社区能够提供及时的帮助和资源,帮助用户解决问题。
安装步骤:
- Windows:
- 从 Ollama 官网下载 Windows 安装包。
- 双击安装包进行安装。
- 安装完成后,在命令行输入
ollama验证安装是否成功。
- Mac:
- 下载 Mac 安装包。
- 打开安装包并按照提示进行安装。
- 安装完成后,在终端输入
ollama验证安装是否成功。
- Linux:
- 可以通过脚本安装或源码编译的方式来安装 Ollama。
- 使用
curl -fsSL https://ollama.com/install.sh | sh命令进行一键安装。 - 安装完成后,在终端输入
ollama验证安装是否成功。
2、 LM Studio
LM Studio 用户界面非常出色,点击即可安装 Hugging Face Hub 中的任何模型。此外,它还提供 GPU 使用比率调整等。但 LM Studio 是一个封闭源代码,它通过读取项目文件来生成上下文感知响应的选项。
特点优势:
- 友好的用户界面:直观的图形界面使操作简单易懂,适合各种水平的用户。
- 调试工具:内置调试功能可以快速识别和解决开发中的问题。
- 可视化工具:提供数据处理和模型评估的可视化工具,帮助用户理解模型的表现。
- 丰富的社区资源:用户可以访问大量示例项目和共享资源,加速开发过程。
安装步骤:
- 从 LM Studio 官网下载相应的安装包,根据操作系统选择 Windows、Mac 或 Linux 版本。
- 安装完成后,打开 LM Studio。
- 按照界面提示进行配置和模型导入。
3、 GPT4All

GPT4All 是一款尖端的开源软件,使用检索增强生成(RAG)生成响应,且对用户友好、速度快。如果安装了 CUDA (Nvidia GPU),GPT4ALL 将自动开始使用你的 GPU 生成每秒最多 30 个 token 的快速响应。
特点优势:
- 高性能推理:优化后的模型能够在本地高效运行,确保低延迟和高响应速度。
- 灵活的 API 接口:用户可通过 API 与模型交互,方便集成到各种应用中。
- 丰富的示例代码:提供多种应用示例,帮助用户迅速了解如何使用和扩展功能。
- 活跃的社区支持:开源社区持续更新和改进,用户可以共享经验和获取支持。
安装步骤:
- 从 GPT4All 的 GitHub 仓库下载源码或预编译的二进制文件。
- 解压下载的文件。
- 按照 README 文件中的说明进行安装和配置。
4、 LLaMA.cpp

LLaMA.cpp 是一个提供 CLI 和图形用户界面 (GUI) 的工具。该工具是高度可定制的,并且可以快速响应任何查询,因为它完全是用纯 C/C++ 编写的,它支持所有类型的操作系统、CPU 和 GPU。同时还可以使用多模态模型,例如 LLaVA、BakLLaVA、Obsidian 和 ShareGPT4V。
特点优势:
- 资源节省:对计算资源的要求较低,适合个人用户和小型企业。
- 简单编译与配置:用户只需简单设置即可开始使用,降低了入门门槛。
- 灵活性与可扩展性:支持模型微调和个性化定制,满足多样化需求。
- 高效推理性能:在本地环境中,LLaMA.cpp 能够快速响应用户请求,提供流畅体验。
安装步骤:
-
从 GitHub 下载 LLaMA.cpp 的源码。
-
使用 CMake 和 Make 进行编译:
mkdir build cd build cmake .. make -
编译完成后,运行
./llama命令启动模型。
5、 NVIDIA Chat with RTX
NVIDIA Chat with RTX 利用 RTX 显卡的加速能力,提供上下文相关的答案。适用于需要高性能推理的场景,但硬件要求也比较高。
特点优势:
- GPU 加速:显卡加速显著提升模型的推理速度,适合需要快速响应的应用场景。
- 内存管理优化:针对大规模模型进行了内存优化,确保高负载下平稳运行。
- 易于集成与扩展:与 NVIDIA 生态系统无缝结合,方便用户利用现有资源快速搭建应用。
- 丰富的开发工具:提供多种开发工具和 SDK,支持二次开发,提升整体开发效率。
安装步骤:
- 确保系统中安装了 NVIDIA 驱动和 CUDA 工具包。
- 从 NVIDIA 官网下载 Chat with RTX 的安装包。
- 按照安装指南进行配置和运行。
6、 Llamafile
Llamafile 将 llama.cpp 和 Cosmopolitan Libc 结合到一个框架中,该框架将 LLMS 的所有复杂性压缩为一个单文件可执行文件 (称为“llamafile”),该文件在大多数计算机上本地运行,无需安装。
特点优势:
- 便捷模型更新:用户可以快速切换不同版本的模型,适应不同的应用需求。
- 版本控制功能:确保实验的可重复性,方便管理模型的不同版本。
- 社区共享平台:用户可以共享训练模型,促进知识传播与交流。
- 与其他工具的集成:支持与其他开发工具的集成,提高开发灵活性。
安装步骤:
- 下载 llava-v1.5-7b-q4.llama 文件 (3.97 GB)
- 打开计算机的终端
- 如果您使用的是 macOS、Linux 或 BSD,则需要授予计算机执行此新文件的权限(您只需执行一次)
chmod +x llava-v1.5-7b-q4.llamafile
- 如果您使用的是 Windows,请通过在末尾添加“.exe”来重命名该文件
- 运行 llama 文件
./llava-v1.5-7b-q4.llamafile -ngl 9999
- 浏览器应该自动打开并显示聊天界面(如果没有,只需打开浏览器并将其指向http://localhost:8080)
聊天完毕后,返回终端并点击Control-C关闭 llamafile
7、 ChatTTS
ChatTTS 是一款面向多语言环境的高质量对话语音合成工具,通过细粒度控制如笑声和停顿来增强语音的真实感,特别适合用于 AI 交互和对话内容创作,拥有活跃的社区支持进行持续优化。
特点优势:
- 自然的语音合成:提供高质量的语音输出,增强用户体验,适合多种场景。
- 多语言支持:支持多种语言的文本转语音,满足全球用户的需求。
- 易于集成:用户可轻松集成至现有应用中,实现语音交互功能。
- 可定制性:允许用户根据需求调整语音风格,创造个性化体验。
安装步骤:
- 从 ChatTTS 的官网下载安装包。
- 安装完成后,按照配置指南进行设置。
8、 GPT-SoVITS
GPT-SoVITS 擅长利用少量语音样本实现高保真声音克隆,支持中英日等多种语言,以其较低的硬件需求和强大的跨语言推理能力脱颖而出,为用户提供了一个功能强大的语音合成平台,尽管某些 API 功能有待改进,但仍显著提升了个性化语音合成的可及性。
特点优势:
- 个性化语音合成:用户可训练自己的语音模型,实现独特的个性化语音助手。
- 高效交互体验:结合文本生成和语音输出,提升用户的互动体验,适合教育、娱乐等多种应用场景。
- 广泛应用潜力:适用于多个领域,如教育、娱乐、客户服务等,推动智能化应用的多样化发展。
- 开放性与扩展性:支持与其他系统和工具的集成,用户可根据需求进行功能扩展。
安装步骤:
- 从 GPT-SoVITS 的 GitHub 仓库下载源码。
- 按照 README 文件中的说明进行安装和配置。
9、Stable Diffusion
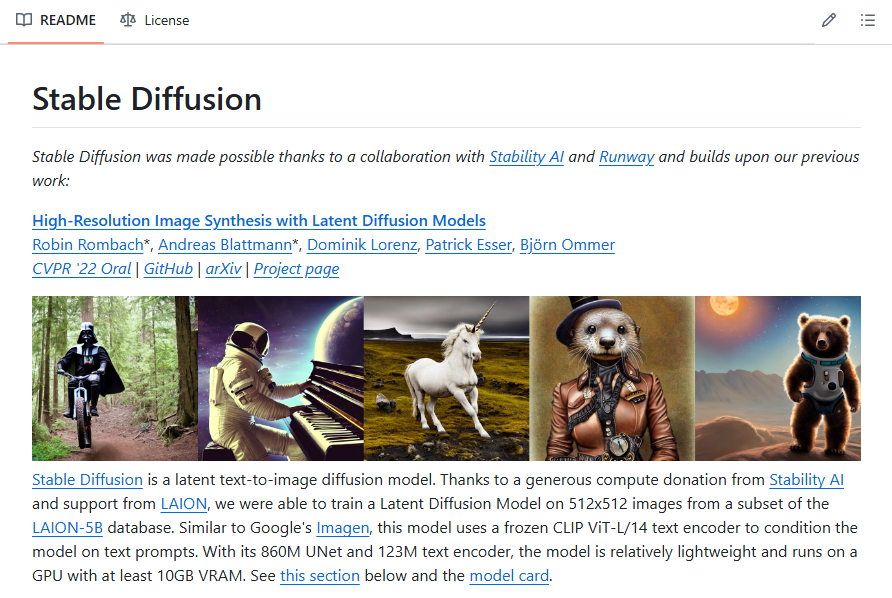
Stable Diffusion 是一个开源的 AI 绘画模型,可以根据文本提示生成图像。它适用于 AIGC(人工智能生成内容)领域,特别是在 AI 艺术创作方面。
特点优势:
- 高质量图像生成:能够根据用户输入的文本生成高分辨率的图像,适合创意工作者使用。
- 易于使用:用户可以通过简单的命令行操作或图形界面进行图像生成,使用门槛低。
- 开放性与可扩展性:用户可以根据需要对模型进行微调,甚至训练自己的数据集,提升生成结果的质量。
- 强大的社区支持:活跃的开发者社区不断推动技术进步,提供丰富的插件和扩展功能,用户可轻松获取支持和灵感。
安装步骤:
- 环境准备:
- 确保系统中安装了 NVIDIA 驱动和 CUDA 工具包。
- 安装 Python 3.8 及以上版本。
- 安装 Git 和 Conda(可选)。
- 下载源码:
- 从 GitHub 下载 Stable Diffusion 的源码:
git clone https://github.com/CompVis/stable-diffusion.git
- 或者从网页下载源码 ZIP 包并解压到本地。
- 安装依赖项:
- 进入源码目录,安装项目的依赖项:
pip install -r requirements.txt
- 下载预训练模型:
- 从 Hugging Face 下载预训练模型,并将其放置在
checkpoints文件夹中。
- 运行 Stable Diffusion:
- 使用以下命令生成图像:
python scripts/txt2img.py --prompt "a professional photograph of an astronaut riding a horse" --ckpt ./checkpoints/v2-1_768-ema-pruned.ckpt --config ./configs/stable-diffusion/v2-inference-v.yaml --H 768 --W 768
- 安装 WebUI(可选):
- 下载并安装 Stable Diffusion WebUI:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitcd stable-diffusion-webuiip install -r requirements.txt
- 运行 WebUI:
python webui.py
- 打开浏览器访问
http://127.0.0.1:7860,即可使用图形界面生成图像。
三、部署优化
1、模型选择
根据具体应用场景选择合适的模型。例如,GPT-4 适用于生成高质量的文本内容,而 LLaMA.cpp 更适合在资源有限的设备上运行。
2、模型训练
如果需要自定义模型,可以使用上述工具进行模型训练。训练数据的质量和数量对模型性能有很大影响。
3、模型优化
使用多 GPU 并行计算、混合精度训练等技术可以显著提升模型的推理速度和效率。
四、应用场景
1、文本生成
使用 GPT-4 或 GPT4All 生成高质量的文章、报告和创意内容。
2、机器翻译
利用大语言模型进行多语言翻译,提高翻译的准确性和流畅度。
3、问答系统
部署问答系统,提供智能客服和知识库查询服务。
4、语音交互
结合 ChatTTS 和 GPT-SoVITS,实现语音助手和语音交互应用。
5、图像生成
使用 Stable Diffusion 根据文本提示生成高质量的图像,适用于艺术创作、广告设计等领域。
总结
本地部署大语言模型可以通过多种工具和软件实现,每个工具都有其独特的优势和适用场景。通过上述步骤,您可以在本地环境中高效地运行和管理大语言模型,满足不同的应用需求。
原文地址