一、引言
上一篇讲了人工智能是怎么学习的,这一期开始作者会开始讲实践,首先就是要在本地搭建一个预训练的大模型,后面才可以进一步的对他进行微调、搭载agent、向量数据库,完成自己想要的模型。
二、环境准备
1、基础库
准备好环境,才能支持模型的运行与训练,那么第一步是准备python环境。
作者是mac电脑,所以用homebrew安装
brew install python安装之后进行必备库的安装,之前说过大模型的深度学习框架不是PyTorch
pip install torch torchvision transformers就是TensorFlow
pip install tensorflow transformers这里有个坑,安装完python,结果pip命令不生效
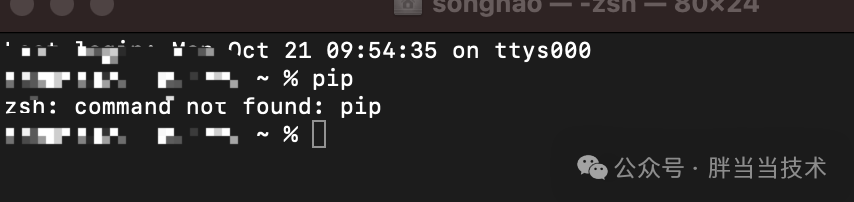
实际上是pip3

所以命令应该是
pip3 install torch torchvision transformers2、python编译
接下来就需要写代码,从hugging face上面拉取预训练的模型,那么需要把python的代码环境准备一下
下载PyCharm,社区版应该就够用了,研究本来就是要试错的
brew install --cask pycharm-ce
下载之后,新建了项目进行main代码,结果显示无法启动,作者觉得是因为没和homebrew安装的python编译器匹配
一般homebrew安装的python路径是 /opt/homebrew/lib/python3.11
要在PyCharm里面的Python Interpreter修改一下
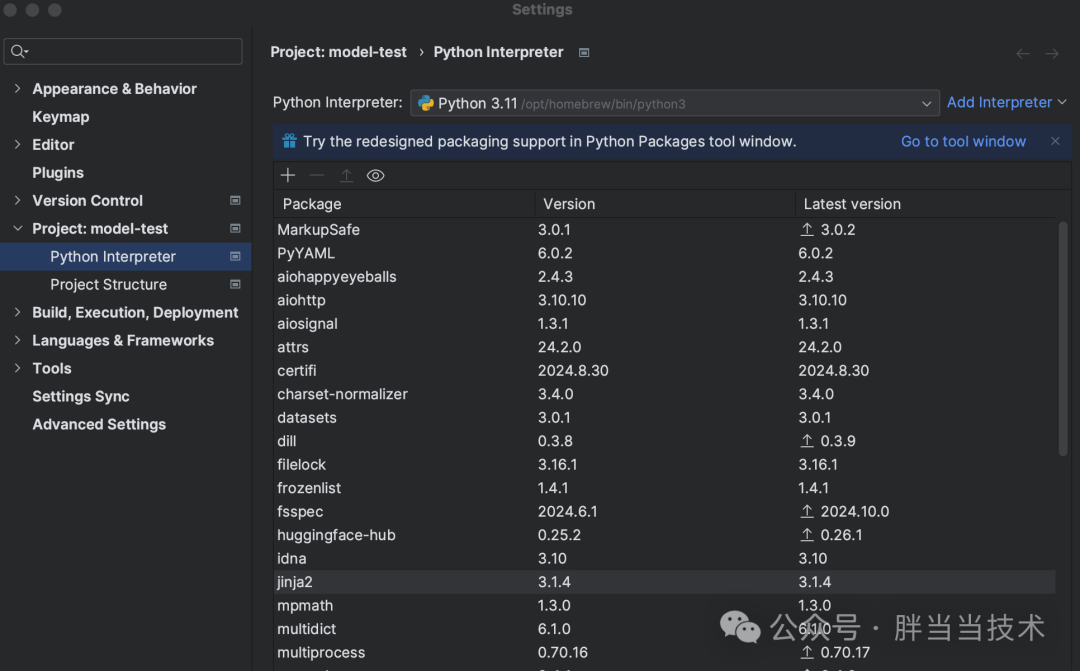
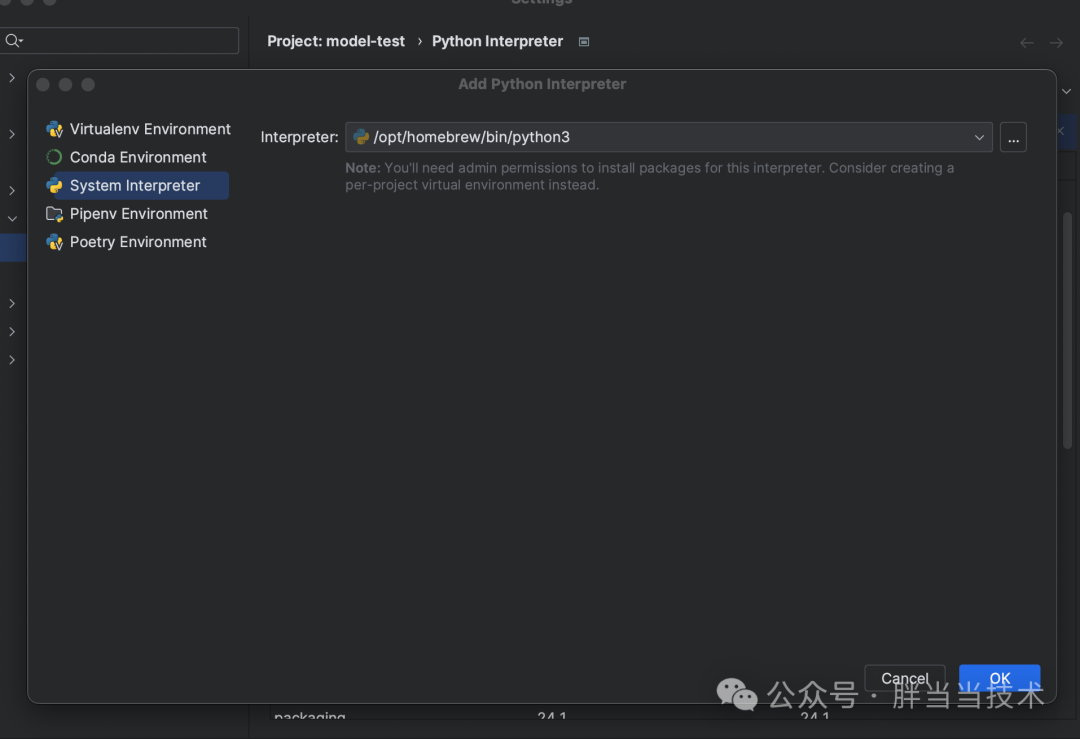
环境好了就可以开始安装模型了
三、模型搭建
1、选型
首先需要知道模型的一些基础要求,我们用一些知名的模型进行比对
| 模型名 | 参数数量 | 显存要求 | RAM 要求 | 推荐 GPU | 备注 |
|---|---|---|---|---|---|
| LLaMA 7B | 70 亿 | ≥ 14 GB (FP16) | ≥ 32 GB | NVIDIA RTX 3090 或A100 | 高性能 GPU,全精度需要更多显存 |
| LLaMA 13B | 130 亿 | ≥ 26 GB (FP16) | ≥ 64 GB | NVIDIA A100 或V100 | 更高计算和内存需求 |
| LLaMA 30B | 300 亿 | ≥ 60 GB (FP16) | ≥ 128 GB | NVIDIA A100 或多 GPU | 需要多 GPU 或超高显存的 GPU |
| LLaMA 65B | 650 亿 | ≥ 130 GB (FP16) | ≥ 256 GB | 多个 A100 或V100 | 超大规模训练环境或云服务 |
| GPT-2 Small | 1.17 亿 | ≥ 4 GB | ≥ 8 GB | NVIDIA GTX 1060 | 消耗较低,适合入门级硬件 |
| GPT-2 Medium | 3.45 亿 | ≥ 8 GB | ≥ 16 GB | NVIDIA GTX 1070 | 较小规模的模型训练 |
| GPT-3 Ada | 3.5 亿 | ≥ 8 GB | ≥ 16 GB | NVIDIA GTX 1070 | 较小规模模型,适合一般研究 |
| BERT Base | 1.1 亿 | ≥ 4 GB | ≥ 8 GB | NVIDIA GTX 1060 | 入门级显卡和内存适用 |
| BERT Large | 3.4 亿 | ≥ 12 GB | ≥ 16 GB | NVIDIA GTX 1080 | 一般用途较佳配置 |
说白了,个人电脑上想要训练模型,基本也就是7B以下的才能玩的转,其实也不需要那么大的量,因为我们都是想针对性的进行训练使用,面向企业用户或者自己的团队。
要想面向C端用户,至少得几千台大型GPU的集群,不然涵盖不了那么多的数据。
我们再看看模型的token量级与模型文件大小的比对,7B以下基本也可以适用
| 模型名 | 参数数量 | 文件大小 (FP32) | 文件大小 (FP16) |
|---|---|---|---|
| LLaMA 7B | 7,000,000,000 | ≈ 28,000 MB (≈ 27.34 GB) | ≈ 14,000 MB (≈ 13.67 GB) |
| LLaMA 13B | 13,000,000,000 | ≈ 52,000 MB (≈ 50.63 GB) | ≈ 26,000 MB (≈ 25.31 GB) |
| LLaMA 30B | 30,000,000,000 | ≈ 120,000 MB (≈ 114.44 GB) | ≈ 60,000 MB (≈ 57.22 GB) |
| LLaMA 65B | 65,000,000,000 | ≈ 260,000 MB (≈ 248.43 GB) | ≈ 130,000 MB (≈ 124.22 GB) |
| GPT-2 Small | 117,000,000 | ≈ 468 MB (≈ 0.46 GB) | ≈ 234 MB (≈ 0.23 GB) |
| GPT-2 Medium | 345,000,000 | ≈ 1,380 MB (≈ 1.35 GB) | ≈ 690 MB (≈ 0.67 GB) |
| GPT-3 Ada | 350,000,000 | ≈ 1,400 MB (≈ 1.37 GB) | ≈ 700 MB (≈ 0.68 GB) |
| BERT Base | 110,000,000 | ≈ 440 MB (≈ 0.42 GB) | ≈ 220 MB (≈ 0.21 GB) |
| BERT Large | 340,000,000 | ≈ 1,360 MB (≈ 1.30 GB) | ≈ 680 MB (≈ 0.66 GB) |
最适合的还是1.3B左右的模型,用FP16的方式节省资源,大概可以训练一千万样本数据,每条1KB
2、安装模型
首先尝试gpt2,后面3、4都是api调用,不能拿到本地安装
from transformers import GPT2Tokenizer, GPT2LMHeadModel# 加载预训练的 GPT-2 模型和分词器
print("开始加载")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
print("加载完成")input_text = "你能明白中文吗"
input_ids = tokenizer.encode(input_text, return_tensors='pt')
print(f"输入 ID: {input_ids}")# 模型生成输出
print("开始生成输出...")
outputs = model.generate(input_ids, max_length=50)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("模型生成输出完成")# 打印生成的文本
print(f"生成的文本: {generated_text}")
加载模型需要一会时间
Connected to pydev debugger (build 232.9559.58)
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's attention_mask to obtain reliable results.
Setting pad_token_id to eos_token_id:None for open-end generation.
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's attention_mask to obtain reliable results.
Once upon a time, the world was a place of great beauty and great danger. The world was a place of great danger, and the world was a place of great danger. The world was a place of great danger, and the world was a加载之后运行后面的代码报错
输出的信息是关于注意力掩码和填充符 ID 的警告,可以传入 attention_mask 以确保生成更可靠的结果。
from transformers import GPT2Tokenizer, GPT2LMHeadModel# 加载预训练的 GPT-2 模型和分词器
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")input_text = "你能明白中文吗"
input_ids = tokenizer.encode(input_text, return_tensors='pt')# 创建注意力掩码
attention_mask = input_ids.ne(tokenizer.pad_token_id).long()# 模型生成输出时传入 attention_mask
print("开始生成输出...")
outputs = model.generate(input_ids, attention_mask=attention_mask, max_length=50, num_beams=5, no_repeat_ngram_size=2, # 防止生成重复 n-gramsearly_stopping=True
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("模型生成输出完成")# 打印生成的文本
print(f"生成的文本: {generated_text}")又报错了
Traceback (most recent call last):
File "/Applications/PyCharm CE.app/Contents/plugins/python-ce/helpers/pydev/pydevd.py", line 1500, in _exec
pydev_imports.execfile(file, globals, locals) # execute the script
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Applications/PyCharm CE.app/Contents/plugins/python-ce/helpers/pydev/_pydev_imps/_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "/Users/songhao/PycharmProjects/model-test/main.py", line 15, in <module>
attention_mask = input_ids.ne(tokenizer.pad_token_id).long()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: ne() received an invalid combination of arguments - got (NoneType), but expected one of:(Tensor other)
didn't match because some of the arguments have invalid types: (!NoneType!)
(Number other)
didn't match because some of the arguments have invalid types: (!NoneType!)显示 tokenizer.pad_token_id 是 None,因为 GPT-2 预训练模型默认没有设置填充符令牌(PAD token)。需要手动设置 pad_token_id 为 eos_token_id(句末符号)
from transformers import GPT2Tokenizer, GPT2LMHeadModel# 加载预训练的 GPT-2 模型和分词器
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token_id = tokenizer.eos_token_id
model = GPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id) # 手动设置 pad_token_id
# 输入示例
input_text = "你能明白中文吗"
print(f"输入文本: {input_text}")
input_ids = tokenizer.encode(input_text, return_tensors='pt')
print(f"输入 ID: {input_ids}")# 创建注意力掩码
attention_mask = input_ids.ne(tokenizer.pad_token_id).long()# 模型生成输出时传入 attention_mask 和 pad_token_id
print("开始生成输出...")
outputs = model.generate(input_ids, attention_mask=attention_mask, max_length=50, num_beams=5, no_repeat_ngram_size=2, # 防止生成重复 n-gramsearly_stopping=True,pad_token_id=tokenizer.pad_token_id # 设置 pad_token_id 为 eos_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("模型生成输出完成")# 打印生成的文本
print(f"生成的文本: {generated_text}")
运行结果很不好,他主要是基于英文学术文本和互联网文本进行训练。对于中文不是很敏捷
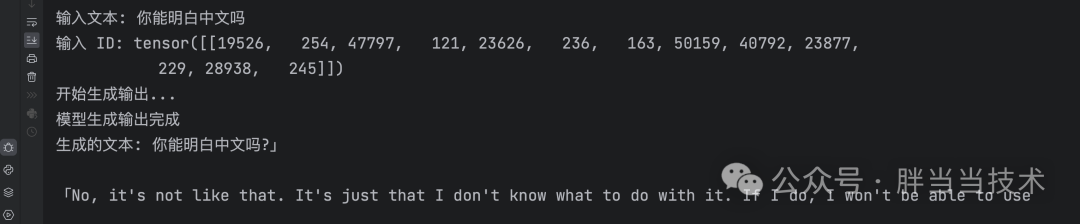
需要换一个中文的预训练模型,Hugging Face上面有很多公开的模型,找找合适的,比如ckiplab/gpt2-base-chinese 模型,该模型专门针对中文进行了微调
from transformers import GPT2LMHeadModel, BertTokenizerFast# 使用 Hugging Face 模型库中的模型和分词器
model_name = "ckiplab/gpt2-base-chinese"# 加载模型和分词器
model = GPT2LMHeadModel.from_pretrained(model_name)
tokenizer = BertTokenizerFast.from_pretrained(model_name)# 打印模型参数数量
num_parameters = model.num_parameters()
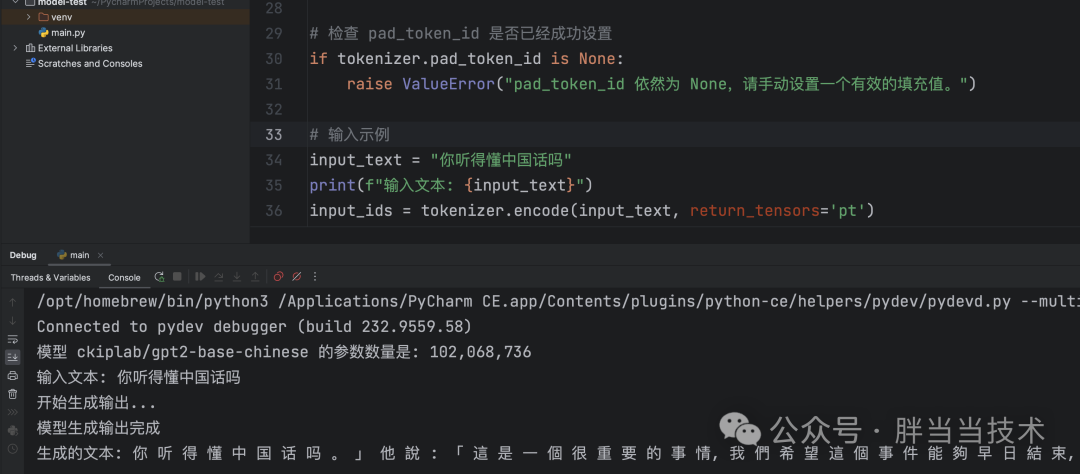
print(f"模型 {model_name} 的参数数量是: {num_parameters:,}")# 设置 pad_token_id,如果 eos_token_id 不存在,则手动设置一个填充值
if tokenizer.pad_token_id is None:if tokenizer.eos_token_id is not None:tokenizer.pad_token_id = tokenizer.eos_token_idelse:# 使用 [PAD] token 的 ID,若其存在于分词器中pad_token = "[PAD]"if pad_token in tokenizer.get_vocab():tokenizer.pad_token_id = tokenizer.convert_tokens_to_ids(pad_token)else:# 如果都不存在,可以选择一个任意的 token ID 做填充符# 例如使用 0 作为填充值tokenizer.pad_token_id = 0
model.config.pad_token_id = tokenizer.pad_token_id# 检查 pad_token_id 是否已经成功设置
if tokenizer.pad_token_id is None:raise ValueError("pad_token_id 依然为 None,请手动设置一个有效的填充值。")# 输入示例
input_text = "你能明白中文吗"
print(f"输入文本: {input_text}")
input_ids = tokenizer.encode(input_text, return_tensors='pt')# 创建 attention_mask
attention_mask = input_ids.ne(tokenizer.pad_token_id).long()# 模型生成输出
print("开始生成输出...")
outputs = model.generate(input_ids,attention_mask=attention_mask,max_length=50,num_beams=5,no_repeat_ngram_size=2, # 防止生成重复 n-gramsearly_stopping=True,pad_token_id=tokenizer.pad_token_id # 确保 pad_token_id 一致
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("模型生成输出完成")# 打印生成的文本
print(f"生成的文本: {generated_text}")运行结果牛头不对马嘴,这个模型也不太适合,还需要再试验,切换到一个对于中文理解较好的的预训练模型,然后在针对业务数据进行训练微调,生成我们自己的大模型
3、代码分析
-
model_name:指定了我们要加载的模型名称
-
from_pretrained:从预训练模型加载 GPT-2 和分词器
-
input_ids:输入文本的编码
-
attention_mask:关注实际的输入
-
max_length:生成的最大长度
-
num_beams:beam search 的数目,提高生成质量
-
no_repeat_ngram_size:防止生成重复的 n-grams
-
early_stopping:当生成的序列满足条件时提前停止
-
pad_token_id:填充值的 token id
-
tokenizer.decode:将生成的 token id 转换回文本,同时跳过特殊 token
from transformers import GPT2LMHeadModel, BertTokenizerFast# 使用 Hugging Face 模型库中的模型和分词器
model_name = "ckiplab/gpt2-base-chinese"# 加载模型和分词器
model = GPT2LMHeadModel.from_pretrained(model_name)
tokenizer = BertTokenizerFast.from_pretrained(model_name)# 打印模型参数数量
num_parameters = model.num_parameters()
print(f"模型 {model_name} 的参数数量是: {num_parameters:,}")# 设置 pad_token_id,如果 eos_token_id 不存在,则手动设置一个填充值
if tokenizer.pad_token_id is None:if tokenizer.eos_token_id is not None:tokenizer.pad_token_id = tokenizer.eos_token_idelse:# 使用 [PAD] token 的 ID,若其存在于分词器中pad_token = "[PAD]"if pad_token in tokenizer.get_vocab():tokenizer.pad_token_id = tokenizer.convert_tokens_to_ids(pad_token)else:# 如果都不存在,可以选择一个任意的 token ID 做填充符# 例如使用 0 作为填充值tokenizer.pad_token_id = 0
model.config.pad_token_id = tokenizer.pad_token_id# 检查 pad_token_id 是否已经成功设置
if tokenizer.pad_token_id is None:raise ValueError("pad_token_id 依然为 None,请手动设置一个有效的填充值。")# 输入示例
input_text = "你能明白中文吗"
print(f"输入文本: {input_text}")
input_ids = tokenizer.encode(input_text, return_tensors='pt')# 创建 attention_mask
attention_mask = input_ids.ne(tokenizer.pad_token_id).long()# 模型生成输出
print("开始生成输出...")
outputs = model.generate(input_ids,attention_mask=attention_mask,max_length=50,num_beams=5,no_repeat_ngram_size=2, # 防止生成重复 n-gramsearly_stopping=True,pad_token_id=tokenizer.pad_token_id # 确保 pad_token_id 一致
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("模型生成输出完成")# 打印生成的文本
print(f"生成的文本: {generated_text}")四、总结
这一章主要是讲了模型搭建,接下来作者会分享大模型的训练、微调,以及后续搭载agent与向量数据库