文章目录
- 1、为什么要使用线程池
- 2、线程池的执行原理
- 2.1 七个核心参数
- 2.2 线程池的执行原理
- 3、线程池用到的常见的阻塞队列有哪些
- 4、如何确定核心线程数开多少个?
- 5、线程池的种类有哪些?
- 6、为什么不建议用Executors封装好的静态方法创建线程池
- 7、线程池的使用场景
- 8、如何控制某个方法运行并发访问线程的数量
- 9、ThreadLocal相关
- 9.1 理解
- 9.2 ThreadLocal的内存泄露问题
1、为什么要使用线程池
- 降低资源消耗:降低避免频繁创建和销毁线程的代价
- 提高响应速度:任务达到时,不用再等待创建线程
- 线程管理方便:线程过多,调度开销大,用线程池可防止过分调度,且可以做统一的监控、分配、调优
此外,还有:
- 每次创建线程,都要占用一定的内存空间,如果无限制的创建线程,会浪费内存
- 一核的CPU,同一时刻只能处理一个线程,如果大量请求一来就创建对应数量的线程,那很多线程也没有CPU时间片,只能阻塞,还会导致线程之间频繁切换
2、线程池的执行原理
2.1 七个核心参数
以银行为例对比:银行大厅一共有10个窗口(最大线程数量),但平时一般只开5个(常驻线程数量),某天办理业务的人很多,5个窗口不够用,其余人来了就先在大厅椅子上坐着等(阻塞队列),结果椅子坐满了,还有人陆续来,于是10个窗口全开,还来很多人,那就只能告诉新来的今天轮不到你办了(拒绝策略)。

解释:
- corePoolSize:核心线程数目
- maximumPoolSize:最大线程数目 = 核心线程+ 救急线程的最大数目
- keepAliveTime:救急线程的生存时间,没有活跃的任务给救急线程处理了,超过了生存时间就会释放
- unit:救急线程的生存时间单位
- workQueue:当没有空闲核心线程时,新来任务会加入到此队列排队,队列满会创建救急线程执行任务(阻塞队列)
- threadFactory:线程工厂,定制线程对象的创建,如设置线程名字、是否是守护线程
- handler:拒绝策略 ,当所有线程都在繁忙, workQueue 也放满时,会触发拒绝策略
2.2 线程池的执行原理
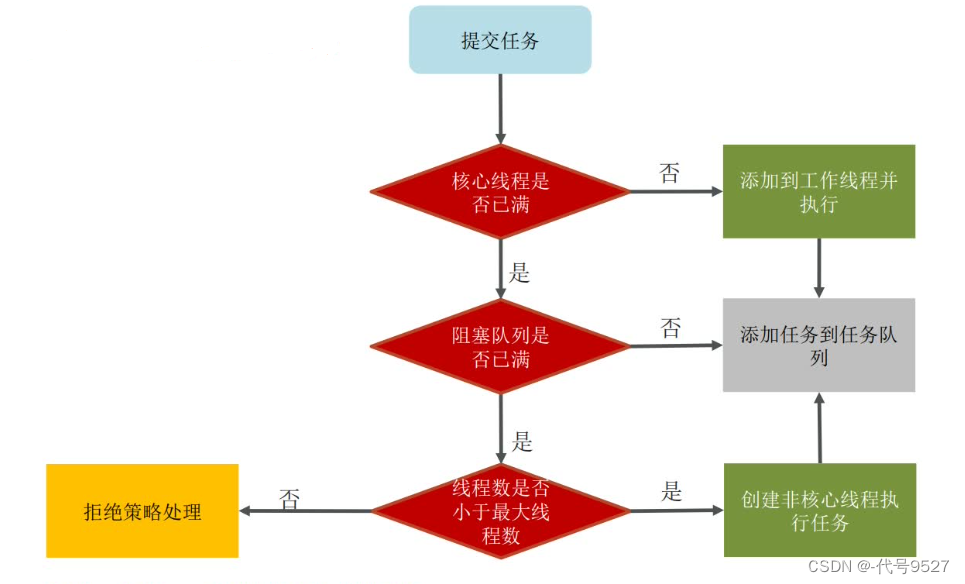
提交一个任务到线程池以后:先判断核心线程数是否满了,否则直接让核心线程去执行,反之继续判断阻塞队列是否已满,没满就扔阻塞队列,满了就看线程数是否超过总数,没超,说明还有应急线程可用,反之则走拒绝策略:
- AbortPolicy:直接抛出异常,默认策略
- CallerRunsPolicy:用调用者所在的线程来执行任务,如main线程
- DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务
- DiscardPolicy:直接丢弃当前任务,不抛异常
注意,救急线程(或者叫临时线程、非核心线程)执行完手里的任务后,会检查阻塞队列中是否有需要执行的线程,有则继续干。对于核心线程,正式工,它们一直存在,自然更要检查阻塞队列,然后继续干队列里的活儿。
3、线程池用到的常见的阻塞队列有哪些
【阻塞队列】
当没有空闲核心线程时,新来任务会加入到此队列排队,队列满会创建救急线程执行任务,常见的有:
- ArrayBlockingQueue:基于数组结构的有界阻塞队列,FIFO
- LinkedBlockingQueue:基于链表结构的有界阻塞队列(长度默认Int的最大值),FIFO
- DelayedWorkQueue :是一个优先级队列,它可以保证每次出队的任务都是当前队列中执行时间最靠前
- SynchronousQueue:不存储元素的阻塞队列,每个插入操作都必须等待一个移出操作
LinkedBlockingQueue最为常用:

关于两把锁和一把锁:每个提交的任务封装成一个Node对象放进阻塞队列时,LinkedBlockingQueue 使用了两个锁,一个是 takeLock 用于控制出队操作,另一个是 putLock 用于控制入队操作。ArrayBlockingQueue则出队和入队都是同一把锁。

最后,PS:
线程池的阻塞队列中存储的是任务对象(实现了 Runnable 或 Callable 接口的实例),线程池中的工作线程不断从阻塞队列中取出任务并执行
4、如何确定核心线程数开多少个?
假设N为CPU的核心数。
1)如果场景是高并发且任务执行时间短,核心线程数设置为N+ 1,减少线程上下文切换
2)如果是并发不高,且执行任务时间长,则:
- 对于IO密集型任务,如文件读写、DB读写、网络请求,核心线程数设置为
2N + 1 - 对于CPU密集型任务,如计算型代码、Bitmap转换,核心线程数设置为
N+ 1
因为对于IO密集的任务,其不耗费CPU,而偏计算型的任务(CPU密集型任务),设置为N + 1可以避免频繁切换CPU

最后,如果是并发高且每个业务执行时间也长,那这是优化重点就不是线程池了,而是整体架构,比如是否加入缓存,是否增加服务器,再看核心数是N+1 还是 2N+1
5、线程池的种类有哪些?
java.util.concurrent.Executors中提供了大量创建线程池的静态方法,常见的有:
1)固定线程数的线程池

- 核心线程数与最大线程数相等,没有救急线程
- 阻塞队列是 LinkedBlockingQueue,最大容量为int最大值
适用于任务量已知,相对耗时的任务
2)单线程的线程池

- 核心线程数与最大线程数都是1,没有救急线程
- 阻塞队列是 LinkedBlockingQueue,最大容量为int的最大值
只有一个线程,后面的请求过来,对应的线程进入阻塞队列,因此可以保证所有任务按顺序执行
3)可缓存的线程池
若线程池长度超过了处理需要,则灵活回收空闲线程,反之,则新建线程

- 核心线程数为 0
- 最大线程数为int的最大值
- 阻塞队列为 SynchronousQueue,是一种不存储元素的阻塞队列,一个线程写入了数据,就必须得有一个线程取,否则不能再继续添加,用于传递性的场景
适合任务数比较密集,但每个任务执行时间较短的情况,否则会创建出大量线程
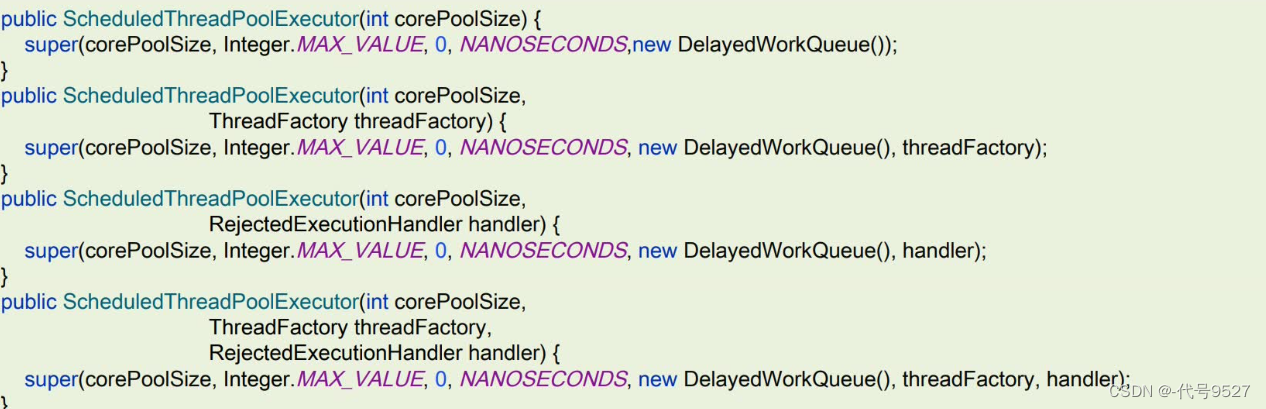
4)可执行延迟任务的线程池
源码:
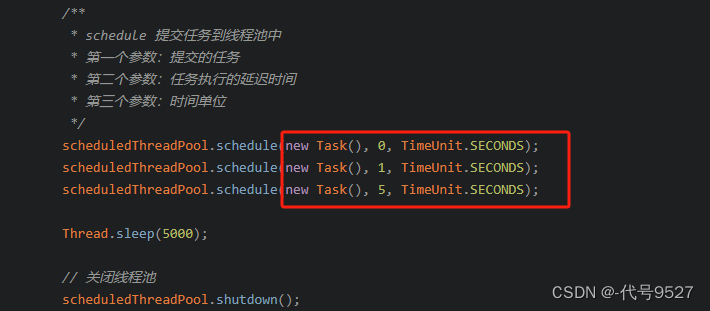
如下,提交三个任务,分别延时0、1、5秒后可以从延迟队列中取到这个任务,然后从线程池分配个线程去执行
6、为什么不建议用Executors封装好的静态方法创建线程池

7、线程池的使用场景
单个任务处理时间比较短,但需要处理的任务的数量大。具体场景有:
- 批量导入:如MySQL同步到ES。线程池 + CountDownLatch,分批导入Especially,防止OOM
- 数据汇总:如资产全景、报表展示。调用多个接口汇总数据,且这些接口之间没有依赖关系,可用线程池 + future提高性能
- 异步:如保存搜索记录,异步线程调用下一个方法,不影响上一级方法的性能
【以上三个使用场景的代码实现】
8、如何控制某个方法运行并发访问线程的数量
【JUC辅助类】
使用JUC辅助类Semaphore,维护一定数量的信号量,底层为AQS。常用于实现限流。
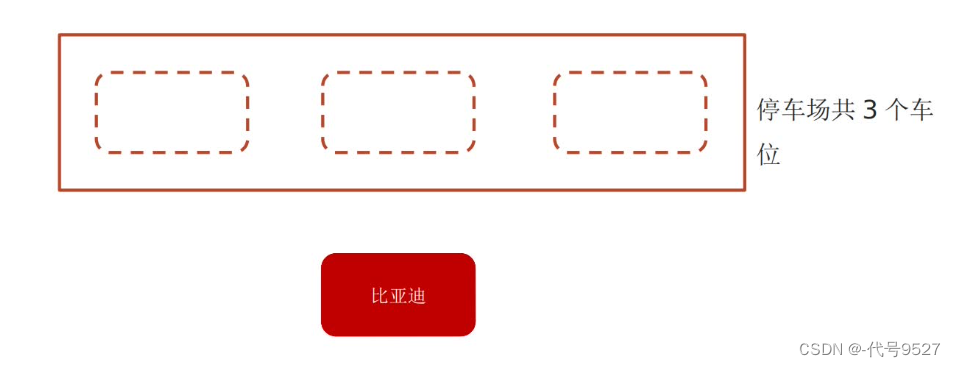
public class SemaphoreDemo {public static void main(String[] args) {//创建Semaphore,设置许可数量,三个车位,对应三个许可证Semaphore semaphore = new Semaphore(3);//模拟6辆汽车for (int i = 1; i <= 6; i++) {new Thread(() -> {try {//抢占许可证semaphore.acquire();System.out.println(Thread.currentThread().getName() + "抢到了车位");//设置一个5s以内的随机时间,模拟停车TimeUnit.SECONDS.sleep(new Random().nextInt(5));System.out.println(Thread.currentThread().getName() + "=====> 离开了车位");} catch (InterruptedException e) {e.printStackTrace();} finally {//释放许可semaphore.release();}},String.valueOf(i)).start();}}
}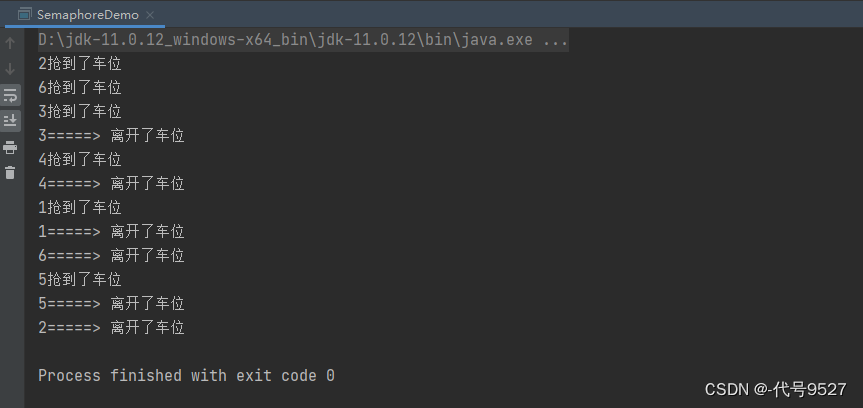
和对象锁类似,不同的是,一个对象一把锁,而Semaphore可以自己指定信号量,一个信号量类似一把锁。
9、ThreadLocal相关
9.1 理解
成员变量,本来有线程安全问题,用ThreadLocal包装一下,则可实现每个线程都有自己的独立副本。 如用JDBC操作数据库时,会将各自的Connection对象用ThreadLocal包装,从而保证每个线程都在自己的Connection上操作数据库
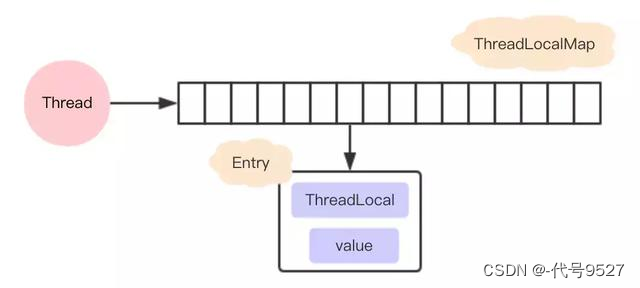
ThreadLocal让每个线程只操作自己内部的值,从而实现线程数据隔离。ThreadLocal的结构如下,其有个内部类ThreadLocalMap,而ThreadLocalMap中有个table属性,是一个数组,数组里存着一个个的Entry对象。

而每个线程对象,又有ThreadLocal.ThreadLocalMap类型的属性,即每个线程对象,都有一个ThreadLocalMap对象。调用ThreadLocal的set、get、remove时,都是操作的当前线程的ThreadLocalMap的Entry类型的数组,这也是ThreadLocal对象实现线程隔离的关键,普通对象的set、get改的是普通对象自己,而ThreadLocal对象set、get改的当前线程对象的属性。
Thread、ThreadLocal、ThreadLocalMap的Entry数组,分别就像人、人的各种卡片(如身份证、学生证)、存各种卡片的卡包。每个人都有一个自己的卡包,卡包里装的卡片外形都一样(类比ThreadLcoal类型的成员变量),但卡片上面记录的信息是私有的,每个人的都不同(类比每个线程给ThreadLcoal类型的成员变量赋的值都不同)。
【ThreadLocal】
9.2 ThreadLocal的内存泄露问题
ThreadLocalMap 中的 key是弱引用,value 为强引用,key会被GC释放内存,关联 value的内存并不会释放,建议主动remove 释放 key,value

虽然弱引用,保证了key指向的ThredLocal对象能被及时回收,但是v指向的value对象是需要ThreadLocalMap调用get、set时发现key为nul时才会去回收整个entry、value,因此弱引用不能100%保证内存不泄露,我们要在不使用某个ThreadLocal对象后,手动调用remoev方法来删除它,尤其是在线程池中,不仅仅是内存泄露的问题,因为线程池中的线程是重复使用的,意味着这个线程的ThreadLocalMap对象也是重复使用的,如果我们不手动调用remove方法,那么后面的线程就有可能获取到上个线程遗留下来的value值,造成bug。
【ThreadLocal内存泄漏】
总之一句话,使用ThreadLocal,在用完后remove掉线程里ThreadLocalMap的Entry数组的Entry<<ThreadLocal>, value>对象