引言
XPath 是一种用于从 XML 文档中选取特定节点的查询语言。如果你对 XML 文档不太熟悉,XPath 可以帮你完成网页抓取的所有工作。
实战
XML,即扩展标记语言,它与 HTML,也就是我们熟知的超文本标记语言,有相似之处,但也有显著的不同。HTML 有一套固定的标签,比如 body、head 或 p(段落),这些标签对于浏览器来说都有特定的含义。然而,XML 并不预设任何标签,你可以自由地为标签命名,而这些标签本身并不携带特定的含义。
XML 文档的设计初衷是简单、通用,易于在互联网上使用。因此,你可以自由地命名标签,而且 XML 现在通常用于在不同的网络服务之间传输数据,这是 XML 的一个主要应用场景。
再回到 XPath,它是一种专门用于 XML 文档的查询语言,其核心功能是选取节点。你可能会好奇,节点是什么?你可以将 XML 文档或 HTML 文档想象成一棵树,每个元素都是树上的一个节点。
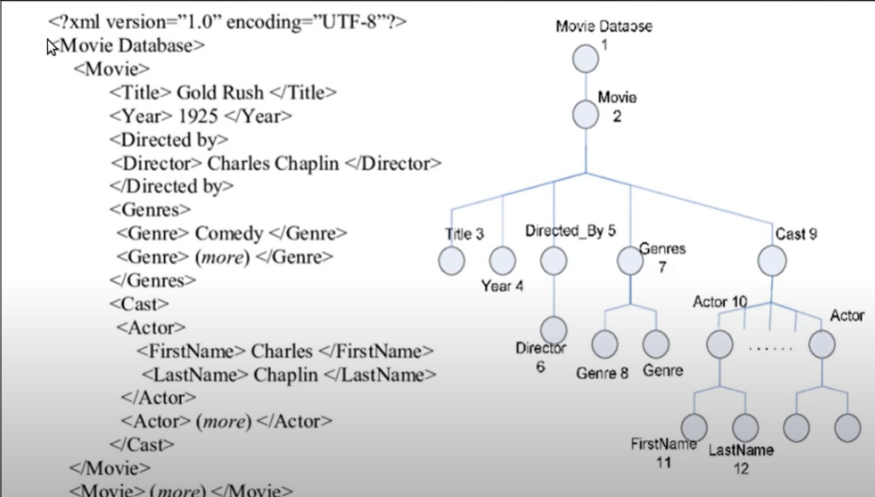
我之所以这样讲,是因为当你查看这个特定的 XML 文档时,你会发现有一个标签叫做 "Movie Database",在它下面可以包含多个电影标签。每部电影标签下,又可以细分出标题、年份、导演等子标签。
通过这种方式,我们构建了一个层级化的结构。如果用树状图来表示,我们可以看到:电影数据库是一个根标签,它下面可以挂载多部电影。每部电影作为一个节点,进一步包含了如标题、年份等信息。同样,在演员列表这个标签下,演员的名字和姓氏也被分别用不同的标签来表示。
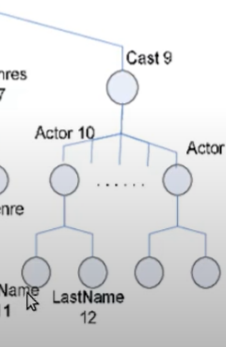
标签的嵌套结构让我们能够将 XML 或 HTML 文档想象成树状结构。因此,在树的概念中,我们引入了节点。这些标签元素实际上就是树中的节点。同样地,HTML 文档也可以通过树状结构来表示并进行解析。
在解析过程中,我们可以利用 Beautifulsoup 等库来实现。这样,无论是 HTML 还是 XML 文档,都可以被想象成一棵树,并且可以通过 XPath 语法来查询和选取文档中符合特定模式的节点。
这就是 XPath 的核心思想。接下来,我将通过一些示例来展示如何使用 XPath 语法,以便我们能更深入地理解它。
示例
我们不会详细介绍 Xpath 语法本身,因为在本视频中我们的主要目标是学习如何使用 Xpath 进行网页抓取。

假设我有一个 XML 文档,其中包含以下代码。我的根目录有一个书店标签,其中有多个图书标签,里面有标题和价格标签。您可以在此网站上找到此 Xpath 测试器。这是我测试 XML 和 Xpath 表达式的地方。
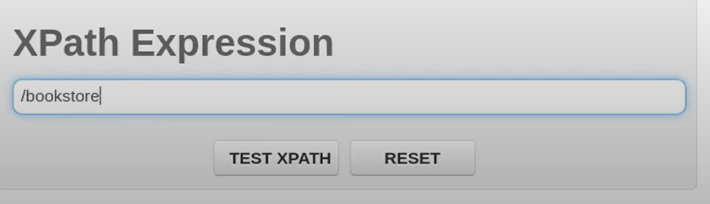
现在,如果我在其中输入“/”,则意味着我想从树的根部进行搜索,并且我将编写“书店”。因此,它要做的就是从根目录搜索书店。所以,现在如果我点击 TEST XPATH,我就会得到这个。

这就是完整的书店。现在,假设我想在书店购买我们拥有的所有书籍。因此,为此,你将这样做。

然后我会得到这个结果。书店里的书都得到了。
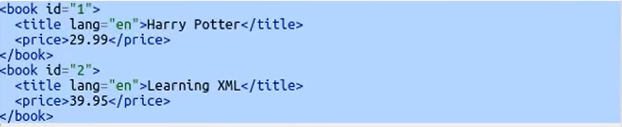
现在,假设您只想获取 ID 为 2 的那本书。因此,您只需放置一个方括号,然后在其中传递“@id=”2””。

当您将 @ 与某些属性一起使用时,在这种情况下您指的是图书标签内的特定属性,并且您在说嘿!找到所有 ID 为 2 的图书标签。当我们运行它时,我们得到了这个。

看看这个,我们只获取 ID 为 2 的那本书。现在,假设我想获取 ID 为 2 的那本书的价格。为此,我将简单地这样做。

结果:

这就是 Xpath 的工作原理。现在,如果您想了解有关 Xpath 语法的更多信息,则可以访问 w3schools 了解更多详细信息。
本文由 mdnice 多平台发布