爬虫入门之爬虫原理以及请求响应
爬虫需要用到的库, 叫requests.
在导入requests库之前, 需要安装它, 打开cmd:
输入pip install 库名
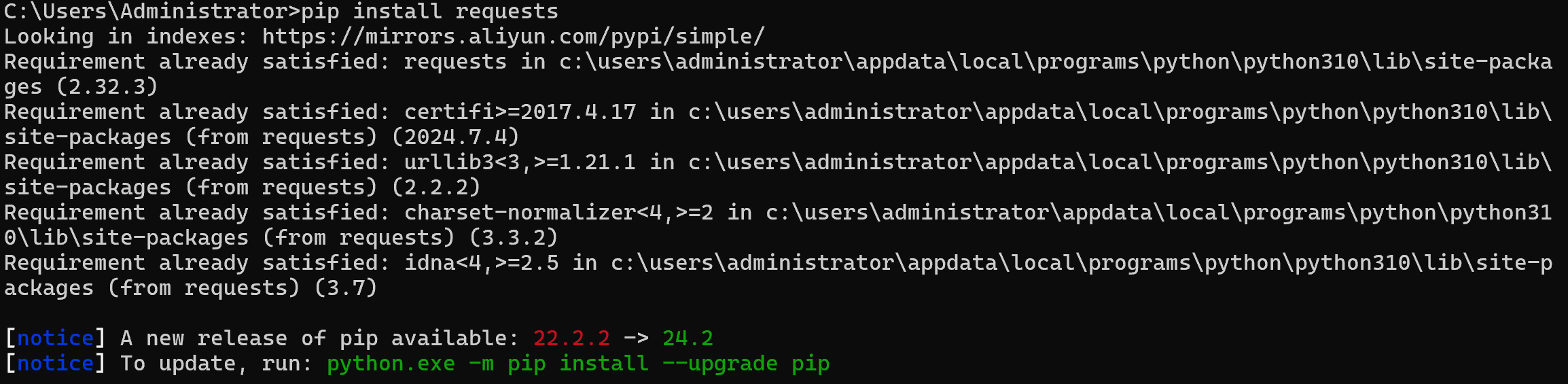
pip install requests
后面出现successful或requirement already就说明已经下载成功了!!!
下载出现的问题:
1.有报错或者是下载慢
修改镜像(从国内的仓库下载)
一、临时修改:
pip install 库名 -i 国内仓库地址
pip install requests -i https://mirrors.aliyun.com/pypi/simple/
二、永久修改
pip config set global.index-url http://mirrors.aliyun.com/pypi/simple/
pip install requests
导入第三方库
下载好requests第三方库之后, 我们需要导入第三方库
import requests
get请求(获取百度网站的响应):
url = 'http://www.baidu.com'
res = requests.get(url)
# 获取响应输出的时候, 响应数据中有乱码
# 解决办法: 在输出内容之前, 设置响应编码
# 响应对象.encoding = '检查内容中charset的值'
res.encoding = "utf-8"
print(res.text)
# 关闭请求, 不关闭会导致资源浪费
res.close()
控制台输出:
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
爬取网上图片
实现用爬虫下载网上图片:
步骤:
1.找到图片地址, url
2.发起请求, res = requests.get(url)
3.接收响应
4.保存到文件, 用with open
"""
互联网上所有的图片都要自己的网址
1.找到图片地址
2.发起请求
3.接收响应
4.保存到文件
"""
import requestsurl = 'https://wx1.sinaimg.cn/mw690/8409f7e1gy1hpx58vyj42j21qk2r1u12.jpg'
res = requests.get(url)
# 响应对象.text 获取响应数据(字符串类型)
# print(res.text)# 图片, 视频, 音频等这些资源在电脑中保存的都是字节(二进制)数据 应当直接写入到文件当中"""
open()函数:
第一个参数: 文件路径 (相对路径或绝对路径)
第二个参数: 模式:
文件的后缀
针对数据的不同, 文件后缀也不同:
图片: png jpg gif
视频: mp4
音频: mp3
文本数据: txt
html数据: html
python数据: py
"""
with open("图片.png", "wb") as f:f.write(res.content)
运行结果:

在同级文件下面, 多出了一个图片.png
打开来图片:
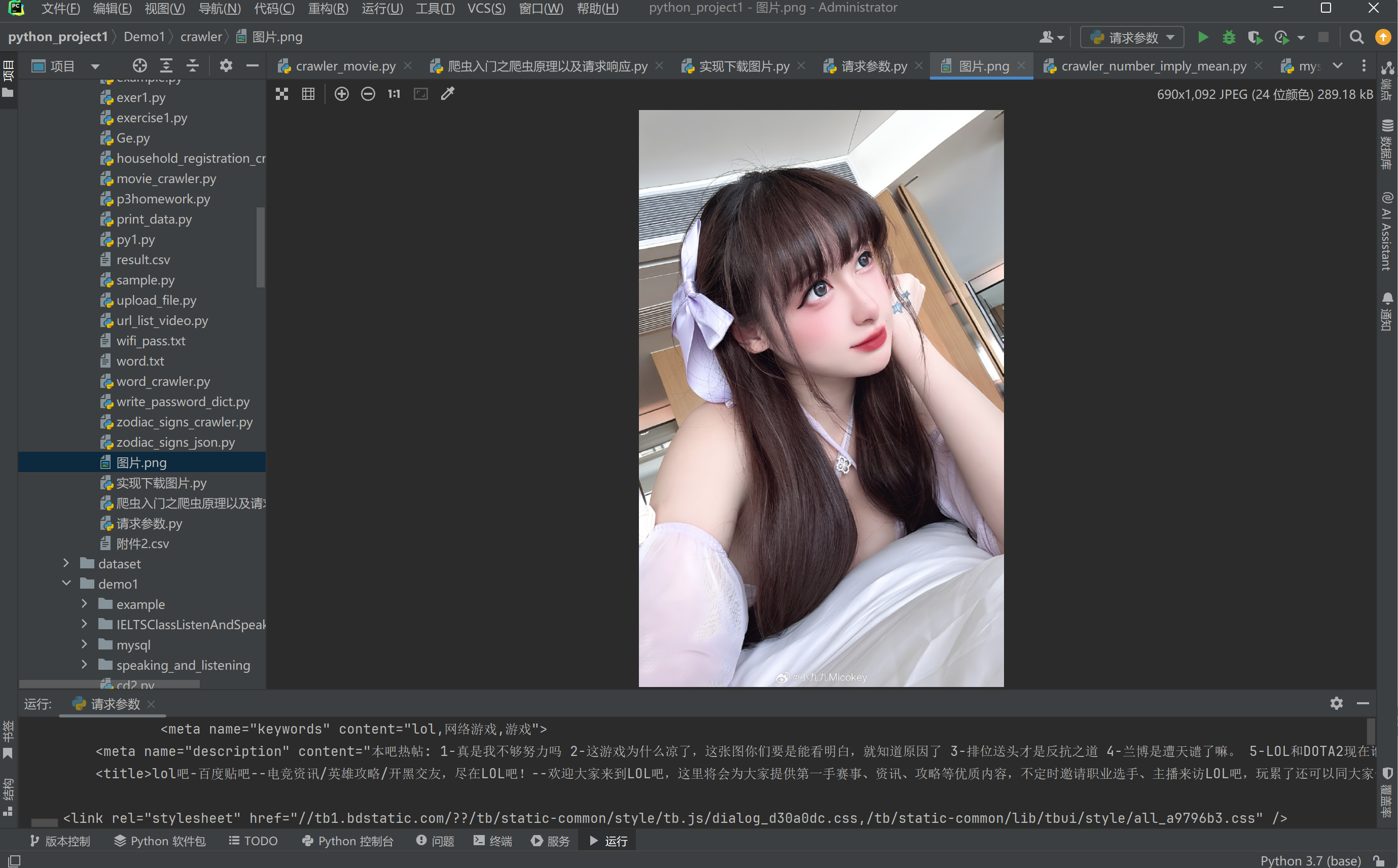
说明我们成功爬了一张图片
请求参数
第一种写法:
import requestsurl = f"https://tieba.baidu.com/f?ie=utf-8&kw={name}&fr=search"response = requests.get(url)
print(response.text)
第二种写法:
import requests# url和参数进行了拆分
url = "https://tieba.baidu.com/f"
p = {'ie': 'utf-8','kw': name,'fr': 'search'
}
response = requests.get(url, p)
print(response.text)
获取腾讯招聘页面里面的信息
腾讯招聘网页里面, 有分页功能, 所以我们可以在url里面分析哪个参数, 是展现第几页网页的数据的。
这个url是https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1726840260871&countryId=&cityId=&bgIds=&productId=&categoryId=40001001,40001002,40001003,40001004,40001005,40001006&parentCategoryId=&attrId=1&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn, 这个url就是我们之后要找到的请求。
经过研究发现:是pageIndex这个参数, 意义是查看的数据是第几页数据。比如pageIndex=1, 那么我们查看到的数据是第一页的数据。
现在的任务, 就是需要爬取腾讯网站的1到10页的数据
目标:获取红色方框里面的数据



这里面是第一页数据, 我们需要爬取10页数据, 而且都是在红色框内的那块数据。
我们打开开发者工具, 电脑快捷键是f12, 找到网络选项。
然后点击一下左上角的第二个圆圈带一斜杠的按钮, 清空数据。
然后再刷新一下网络, 再从下面看, 有很多的请求, 我们需要找到Query开头的那个请求, 点击它, 再右边选择响应。

点进去了以后, 我们可以看到里面有一堆数据, 是json格式的数据。
import requests"""
pageIndex: 查看的数据是第几页数据
"""
# 获取1到10页数据
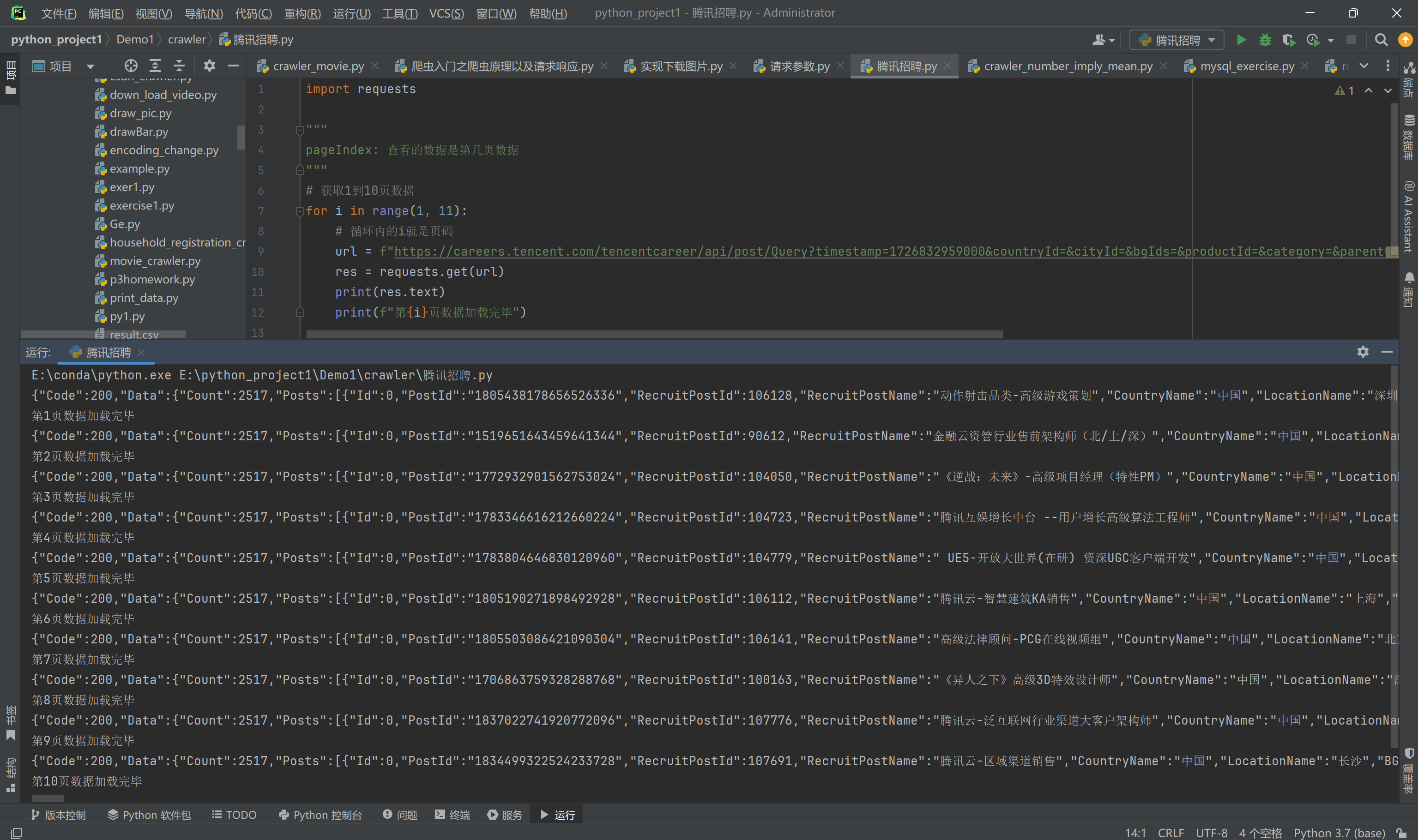
for i in range(1, 11):# 循环内的i就是页码url = f"https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1726832959000&countryId=&cityId=&bgIds=&productId=&category=&parentCategory=&attrId=1&keyword=&pageIndex={i}&pageSize=10&language=zh-cn&area=cn"res = requests.get(url)print(res.text)print(f"第{i}页数据加载完毕")
控制台输出结果:
实战:
1-获取首页数据输出在控制台上
2-从当前首页随便找一张图片通过requests模块进行保存
url网址: http://www.tjwenming.cn/
先不要马上看答案, 尝试自己做一做哦。
参考答案:
import requestsurl = 'http://www.tjwenming.cn/'
res = requests.get(url)
res.encoding = "utf-8"
print(res.text)
img_url = "http://pic.enorth.com.cn/006/031/038/00603103840_3200b509.jpg"
res2 = requests.get(img_url)
with open("picture1.png", "wb") as f:f.write(res2.content)
res.close()
res2.close()
结果:
1-获取首页数据输出在控制台上

2-从当前首页随便找一张图片通过requests模块进行保存(在代码里面就是用的requests模块)

你写出来了吗?如果写出来的话, 给自己一个掌声哦。👏
以上就是爬虫入门之爬虫原理以及请求响应的所有内容了, 如果有哪里不懂的地方,可以把问题打在评论区, 欢迎大家在评论区交流!!!
如果我有写错的地方, 望大家指正, 也可以联系我, 让我们一起努力, 继续不断的进步.
学习是个漫长的过程, 需要我们不断的去学习并掌握消化知识点, 有不懂或概念模糊不理解的情况下,一定要赶紧的解决问题, 否则问题只会越来越多, 漏洞也就越老越大.
人生路漫漫, 白鹭常相伴!!!