standford Chelsea Finn团队
Chelsea Finn是Stanford计算机科学与电气工程系的助理教授。她的实验室IRIS通过大规模的机器人互动研究智能,并与SAIL(斯坦福人工智能实验室)和ML Group(机器学习团队)有合作关系。他还在谷歌的Google Brain团队工作。她对机器人和其他智能体通过学习和互动来发展广泛智能行为的能力感兴趣。他在UC Berkely完成了计算机科学博士学位,师从Sergey Levine,本科毕业于MIT。
主题相关作品
- ALOHA
- Mobile ALOHA
ALOHA提出了一个低成本的开源硬件系统ALOHA,并设计了ACT模仿学习算法。
ALOHA
精细操作任务,例如螺纹电缆连接或安装电池,对于机器人来说是非常困难的,因为它们需要精确、仔细协调接触力和闭环视觉反馈。这通常需要高端机器人、精确的传感器或仔细的校准,这可能昂贵且难以设置。提出了一个低成本的系统,该系统直接从真实的演示中执行端到端模仿学习,使用自定义远程操作接口收集。然而,模仿学习提出了其自身的挑战,特别是在高精度领域:策略中的错误会随着时间的推移而复合 compound,人类演示可能是非平稳的 non-stationary。为此开发了Action Chunking with Transformers (ACT) ,该算法学习动作序列的生成模型 a generative model。ACT 允许机器人在现实世界中学习 6 个困难的任务,例如打开半透明条味杯以及以 80-90% 成功率插入电池这些只有 10 分钟的演示的任务。

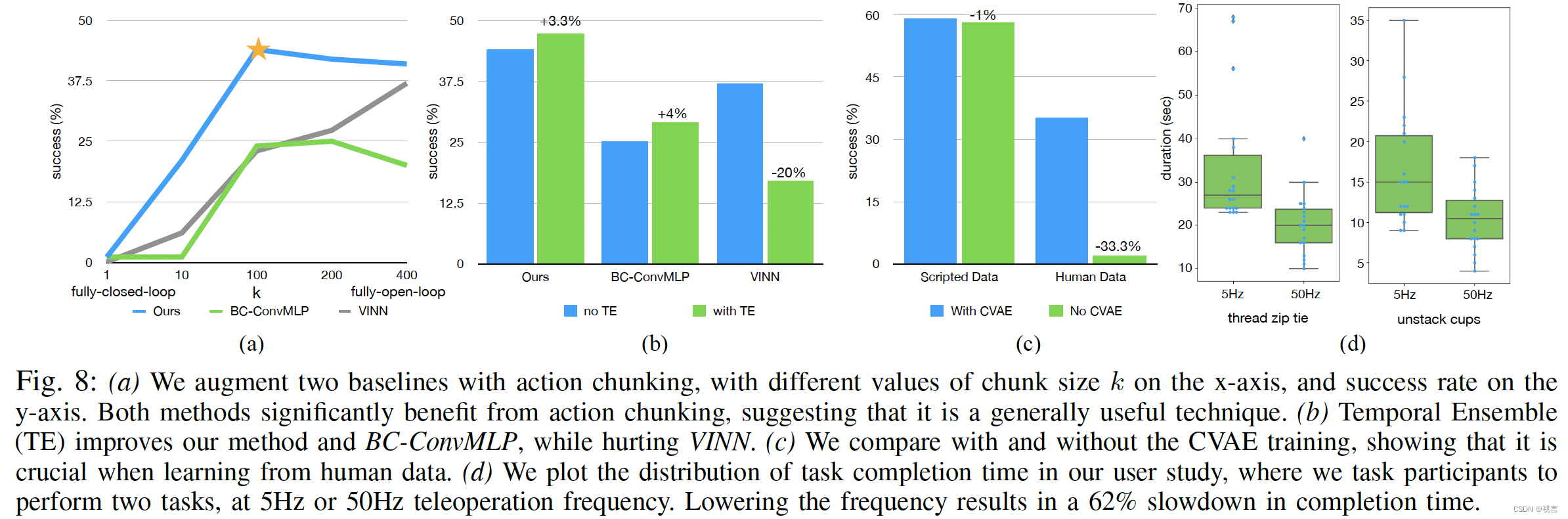
低成本硬件不可避免地不如高端平台精确,这使得传感和规划挑战更加明显,将学习纳入系统这个方向或许希望解决这一问题。能够通过从闭环视觉反馈中学习并积极补偿误差来执行精细的任务。使用端到端的策略,该策略将网络摄像头的RGB图像直接映射到动作。这种像素到动作的方式特别适合精细操作,因为精细操作通常涉及具有复杂物理特性的对象,因此学习操作策略比对整个环境建模要简单得多。策略的性能在很大程度上取决于训练数据的分布,在精细操作的情况下,高质量的人类演示可以通过允许系统从人类灵巧中学习来提供巨大的价值。因此,我们为数据收集构建了一个低成本但灵巧的远程操作系统,以及一种新颖的模仿学习算法,可以有效地从演示中学习。预测动作中的小错误会导致状态的巨大差异,加剧了模仿学习的“复合错误”问题:从动作分块中获得灵感,动作序列如何组合在一起作为一个块,并作为一个单元执行;预测下 k 个时间步的目标关节位置,而不是一次只预测一个步骤,这将任务的有效范围减少了 k 倍,减轻了复合错误。为了进一步提高策略的平滑度,提出了时间集成 temporal ensembling,它更频繁地查询策略,并在重叠的动作块之间进行平均。
ALOHA:双手遥控低成本开源硬件系统
低成本的开源硬件系统,具备以下五个特点:
- 低成本:整个系统应该在大多数机器人实验室的预算之内,可与单个工业手臂相媲美
- 通用性:它可以应用于广泛的与现实物体的精细操作任务
- 人性化:系统应该直观、可靠、易于使用
- 可修复:当设置不可避免地出现故障时,研究人员可以轻松修复设置
- 易于搭建:研究人员可以快速组装,材料来源容易
本方法没有将VR控制器或摄像头捕获的手部姿势映射到机器人的末端执行器姿势,即任务空间映射,而是使用来自同一家公司制造的小型机器人WidowX的直接关节空间映射,成本为3300美元。

- 左侧为前、顶部和两个手腕摄像机的视角(总计4个摄像机),以及ALOHA双手工作空间的示意图。
具体而言,这4个Logitech C922x网络摄像头,每个流输出480×640 RGB图像
其中两个网络摄像头安装在跟随机器人手腕上,以提供夹具的近距离视角(allowing for a close-up view of the grippers)
剩下的两个相机分别安装在前方和顶部位置,遥控操作和数据记录均以50Hz频率进行 - 中间是“手柄和剪刀”机制和定制夹具的详细视图
- 根据上面的原则1、4和5,建立了一个双手平行颚夹持器设置与两个ViperX 6-DoF机器人手臂,上图右侧列出了ViperX 6dof机器人的技术规格
出于价格和维护方面的考虑,不使用灵巧手。使用的ViperX臂具有750克和1.5米跨度的工作有效载荷,精度为5-8毫米
且该机器人模块化,维修简单:在电机出现故障的情况下,低成本的Dynamixel电机可以轻松更换。这种机器人可以以5600美元左右的价格购买到现货。然而,OEM的手指不够通用,无法处理精细的操作任务。因此,设计了自己的3D打印“透明”手指,并将其贴合在夹持胶带(gripping tape)上
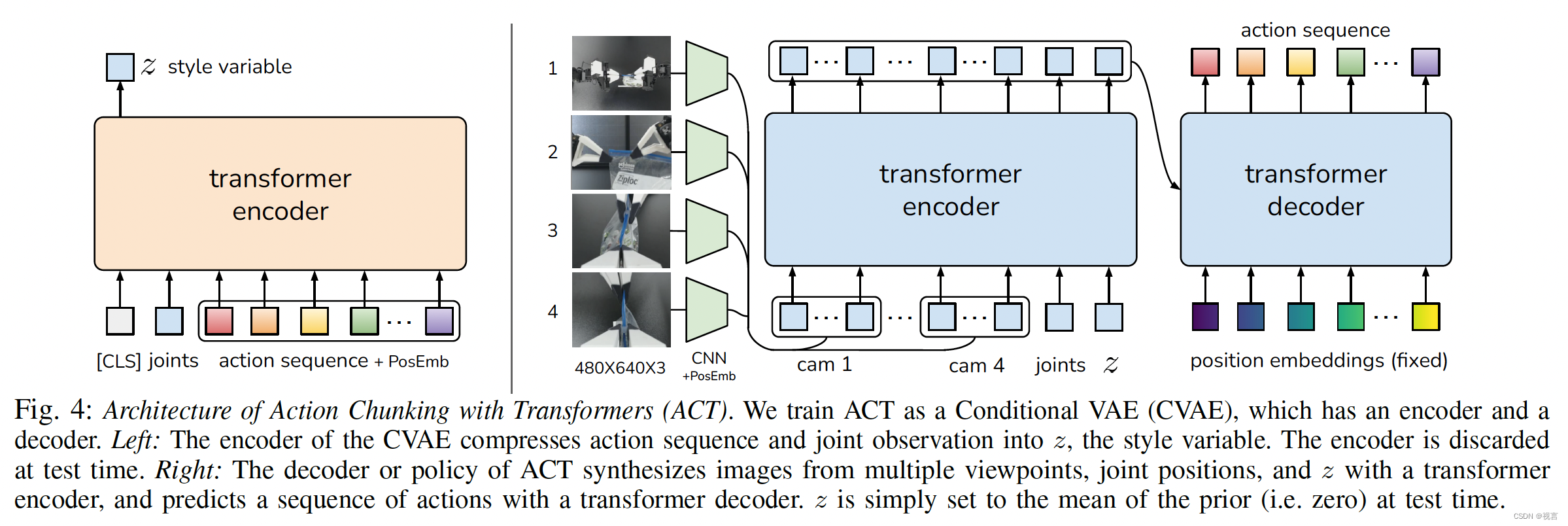
Action Chunking with Transformers (ACT)
数据采集:记录leader机器人的关节位置(即来自人类操作员的输入),并将其作为行动。 重要的是使用leader关节位置而不是跟随关节位置,因为施加的力的大小是通过低级PID控制器由它们之间的差异隐式定义的。 观察结果由跟随机器人的当前关节位置和来自4个摄像机的图像馈送组成。
训练ACT在给定当前观察结果的情况下预测未来行动的顺序。 这里的一个动作对应于下一个时间步中双臂的目标关节位置。ACT试图模仿操作员在给定当前观测值的情况下,在以下时间步长内会做什么。然后加载验证损失最小的策略。出现的主要挑战是复合错误,即先前操作的错误导致训练分布之外的状态。
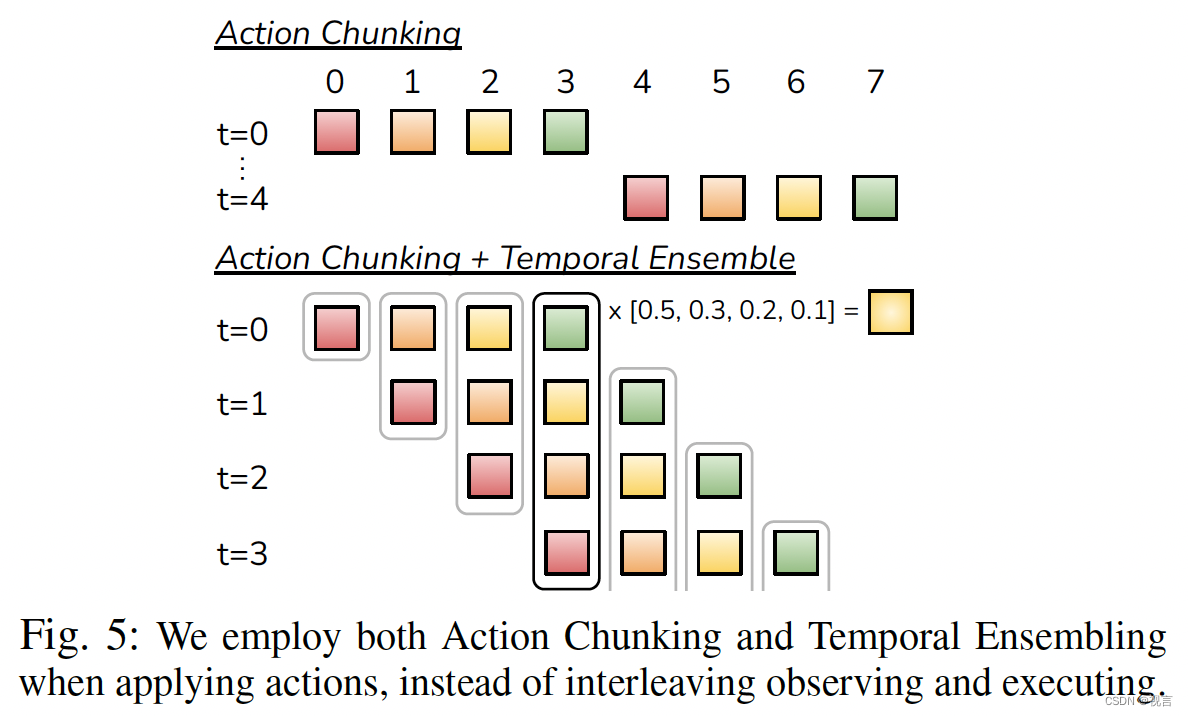
Action Chunking and Temporal Ensemble
action chunking:一种神经科学概念,将单个动作分组并作为一个单元执行,使其存储和执行更加高效。
在我们的实现中,我们将块大小固定为k:每k个步骤,agent接收一个observation,生成下次k个actions,并按顺序执行这些actions。这意味着任务的有效范围减少了k倍。Chunking还可以帮助模拟人类演示中的非马尔可夫行为。单步策略将难以处理时间相关的混杂因素,例如演示中间的停顿,当混杂因素在一个块中时,动作块可以缓解这个问题
Temporal Ensemble:每k步突然加入一个新的环境观察,可能导致机器人运动不平稳。我们在每个时间步查询策略。这使得不同的动作块彼此重叠,并且在给定的时间步中,将有多个预测动作。使用指数加权方案 w i = e x p ( − m ∗ i ) w_i = exp(−m ∗ i) wi=exp(−m∗i)对这些预测执行加权平均合并新观察的速度由 m 控制,其中较小的 m 表示更快的合并聚合同一时间步预测的动作不产生额外的训练成本,只产生额外的推理时间。
Modeling human data
给定相同的观察结果,人类可以使用不同的轨迹来解决任务。在精度不那么重要的地区,人类也将更加随机。因此,该策略对于专注于高精度很重要的区域非常重要。我们通过将动作分块策略训练为生成模型来解决这个问题。
具体来说,我们将策略训练为conditional variational autoencoder (CVAE) 以生成以当前观察为条件的动作序列。CVAE编码器只用于训练CVAE解码器(策略),在测试时被丢弃。具体来说,CVAE编码器在给定当前观测值和动作序列作为输入的情况下,预测风格变量z的分布的均值和方差,该分布被参数化为对角高斯分布。为了在实践中更快地训练,我们省略了图像观察,仅以本体感觉观察和动作序列为条件。CVAE解码器,即策略,以z和当前观测(图像+关节位置)为条件来预测动作序列。每次,我们设置z为先验分布的均值,即零,以确定解码。整个模型被训练成使用标准VAE目标最大化演示动作块的对数似然,该目标有两个项:重建损失和将编码器正则化为高斯先验的项。用一个超参数对第二项进行加权。
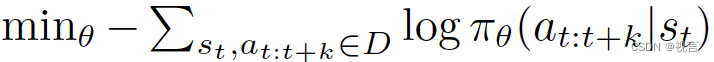
直观地说,z值越高,传递的信息就越少。总的来说,我们发现CVAE目标对于从人类演示中学习精确的任务至关重要。
Implementing ACT
我们使用ResNet图像编码器、transformer编码器和transformer解码器来实现CVAE解码器。observation包括4张RGB图像,每张图像分辨率为480 × 640,两个机械臂关节位置(共7+7=14自由度)。策略在给定当前观察的情况下输出一个 k × 14 张量。
ResNet18主干对图像进行处理,将480 × 640 × 3RGB图像转换为15 × 20 × 512的特征图,沿空间维度展平以获得 300 × 512 的序列。为了保留空间信息,我们在特征序列中添加了二维正弦位置嵌入 。当前关节位置和“风格变量”z。它们分别通过线性层从其原始维度投影到 512。

实验
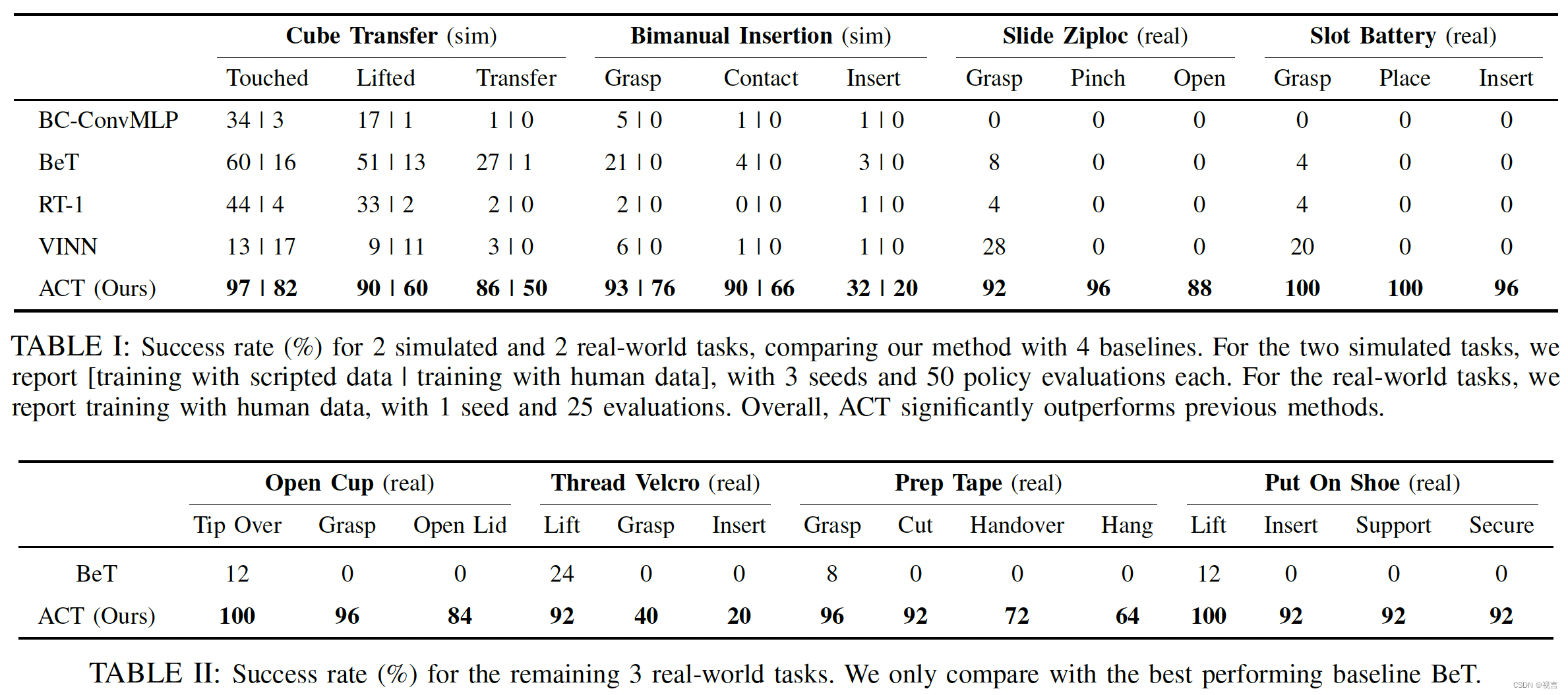
在 MuJoCo中构建了两个模拟的精细操作任务,6个现实任务。两个仿真任务是在双臂间传递物体 Cube Transfer ;一个是“Bimanual Insertion”,左臂和右臂需要分别拿起插座和插销,然后在半空中插入,使插销接触插座内的“引脚”。每种操作进行50次成功的演示,所有人类的演示本质上都是随机的。实验结果将ACT与四种先验模仿学习方法进行比较。
我们将先前方法的较差性能归因于数据中的复合错误和非马尔可夫行为:行为在事件结束时显著退化,机器人可以无限期地暂停某些状态。ACT通过动作分块来缓解这两个问题。在模拟任务中从脚本数据切换到人工数据时,所有方法的性能都有所下降:人工演示的随机性和多模式使模拟学习变得更加困难。