
目录
一. 常用的数据类型
1.数值类型
1.1 整形类型
1.2 浮点型类型
2.字符串类型
char和varchar的区别
如何选择char和varchar
3.日期类型
4.二进制类型
二. 表的操作
1.查看所有表
2.表的创建
3.查看表的结构
4.表的修改
4.1 添加新的列
4.2 修改表中现有的列
4.3 删除表中现有的列
4.4 重命名表中现有的列
4.5 重命名当前表
5.表的删除
一. 常用的数据类型
在我们日常开发中最用的MySQL数据类型有:数值类型、字符串类型、日期型类型、二进制类型,MySQL中的数据类型和我们之前学习的java中的基本类型是类似的,都是用来存储不同类型的数据,接下来我们分别来认识一下这些类型的特点。
1.数值类型
1.1 整形类型
注:M表示每个值的位数
| 类型 | 大小 | 说明 |
| BIT[(M)] | bit | 只能存0或者1(相当于只能存二进制位的数)取值范围为1 ~ 64,省略M则默认大小为1 |
| TINYINT | 1byte | 取值范围-2^7 ~ 2^7-1,无符号取值范围2^8-1 |
| BOOL | 1byte | 只能包含1位数字的值,值为0则为假,非零则为真 |
| SMALLINT[(M)] | 2byte | 取值范围 -2^15 ~ 2^15-1,无符号取值范围2^16-1 |
| MEDIUMINT[(M)] | 3byte | 取值范围 -2^23 ~ 2^23-1,无符号取值范围2^24-1 |
| INT[(M)] | 4byte | 取值范围 -2^31 ~ 2^31-1,无符号取值范围2^32-1 |
| INTEGER[(M)] | 4byte | INT[(M)]的同义词(用哪个都行) |
| BIGINT[(m)] | 8byte | 取值范围 -2^63 ~ 2^63-1,无符号取值范围2^64-1 |
在现在存储资源不缺乏的情况下,我们能用BIGINT类型就用BIGINT类型,因为取值范围更大,避免不必要的错误
1.2 浮点型类型
| 类型 | 大小 | 说明 |
| FLOAT[(M,D)] | 4byte | 单精度浮点型,M表示总位数,D表示小数点后面的位置,大约可以精确到小数点后面7位 |
| DOUBLE[(M,D)] | 8byte | 双精度浮点型,M表示总位数,D表示小数点后面的位置,大约可以精确到小数点后面15位 |
| DECIMAL[(M,D)] | 动态 | 不存在精度丢失,DECIMAL的最大位数为65 ,最⼤⼩数位数为30。如果省略M,则默认为10,如果省略D,则默认为0。M中不计算⼩数点和负数的-号,如果D为0,则值没有⼩数点和⼩数部分。 |
因为FLOAT和DOUBLE的精度丢失问题,在我们的开发中时一般不使用这两种类型,我们都使用DECIMAL,那么DECIMAL是如何保证数据精度是不受损失的?
假设我们现在有一个浮点数:123456789987654321123456789.123456789987654321123456789
那么Decimal的底层是将这个浮点数进行拆分,每一份用一个int表示:(小数点和符号不记录)
整数位:123456789 | 987654321 | 123456789 | 小数位:123456789 | 987654321 | 123456789
整数部分用了3个int表示,小数部分用了3个int表示
那么假设后面还有多余的小数(剩余部分),那么就会使用最小的合适的数据类型进行存储,最终通过这样的方式保存数据,就保证了数据精度不受损失。
那么在我们真实的开发过程中,如果遇上描述金额的所需要的数据类型时,一般有以下两种解决方式:
- 用上述说的不损失精度的Decimal类型
- 将金额的单位转换成分或者更小的单位,使用int类型去存储(这是一个小技巧)
2.字符串类型
| 类型 | 说明 |
| CHAR[(M)] | 固定长度的字符串,以字符为单位,取值范围为0 ~ 255,M省略长度默认为1 |
| VARCHAR[(M)] | 可变长度字符串,取值范围为0 ~ 65535 ,有效字符个数取决于实际字符数和使用字符集,例如使用utf8mb4字符集时65535/4约等于16383个字符 |
| TINYTEXT | 小文本类型,最大长度为255个字节 |
| TEXT[(M)] | 文本类型,最大长度为65535字节 |
| MEDIUMTEXT | 中文本类型,最大长度为16777215字节 |
| LONGTEXT | 大文本类型,最大长度为4294967295字节 |
| enum(value,value...) | 枚举类型:
|
| set(value,value...) | 集合
|
注:当我们使用TEXT类型时,如果超出的最大长度,那么它就是自动变为MEDIMTEXT类型,当超出 MEDIMTEXT类型时就会自动转变成LONGTEXT类型
char和varchar的区别
- char是固定长度的字符串,获取列的值时会从尾部删除空格(就像java中的next()读入一样,不会读入末尾的空格,但是一个字符串如果中间存在空格,那么是会保留的)
- varchar是可变长度字符串,有效⻓度取决于实际字符数和使⽤的字符集,获取列的值时不会从尾部删除空格,插⼊数据时会删除超出⻓度的空格。
举个例子:
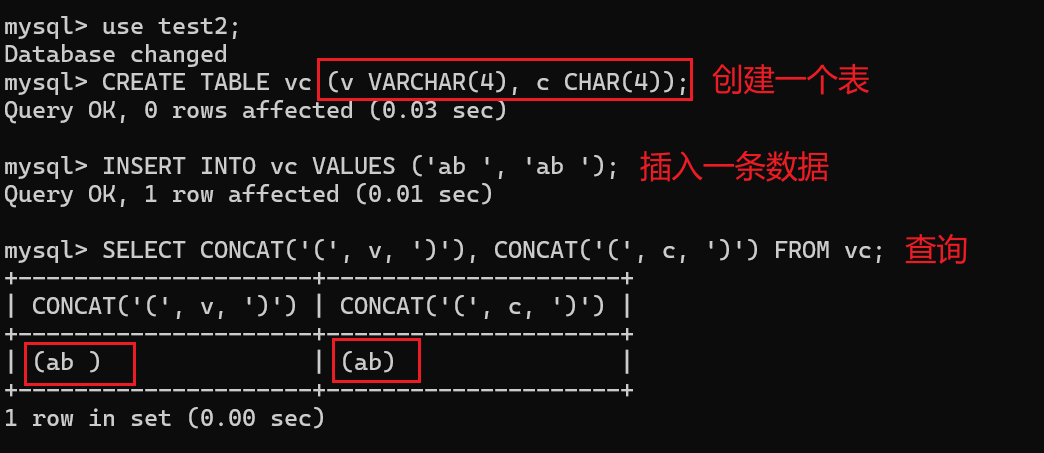
varchar类型的字符串是会保留空格的,char类型的字符串将后面的空格进行了删除
如何选择char和varchar
- 如果数据确定⻓度都⼀样,就使⽤定⻓ CHAR 类型,⽐如:⾝份证,md5,学号,邮编。
- 如果数据⻓度有变化,就使⽤变⻓ VARCHAR , ⽐如:名字,地址,但要规划好⻓度,保证最⻓的字符串能存的进去。
- 定⻓ CHAR 类型⽐较浪费磁盘空间,但是效率⾼。
- 变⻓ VARCHAR 类型⽐较节省磁盘空间,但是效率低
3.日期类型
| 类型 | 大小 | 说明 |
| DATE | 3 bytes | 日期类型 ⽀持范围 1000-01-01 ~ 9999-12-31 显⽰格式为 YYYY-MM-DD |
| TIME | 3 bytes | 时间类型 ⽀持范围 -838:59:59.000000 ~ 838:59:59.000000 显⽰格式为 hh:mm:ss |
| DATETIME | 8 bytes | ⽇期类型和时间类型的组合 ⽀持范围 1000-01-01 00:00:00.000000 ~ 9999-12-31 23:59:59.499999 显⽰格式为 YYYY-MM-DD hh:mm:ss[.fraction] |
| YEAR | 1 bytes | 4位格式的年份 ⽀持范围 1901 ~ 2155 显⽰格式为 YYYY |
4.二进制类型
| 类型 | 说明 |
| BINARY | 固定长度二进制字节,存储的是二进制字节,取值范围0~255 |
| VARBINARY | 可变长度二进制字节,存储的是二进制字节 |
注:在现在的开发中我们已经不使用二进制类型来存储数据了 ,了解即可
二. 表的操作
数据库中的表就像java中的一个类,那么我们一起来学习一下表的基本操作,那么我们需要先新建一个库,在库中来实现表的一些操作~
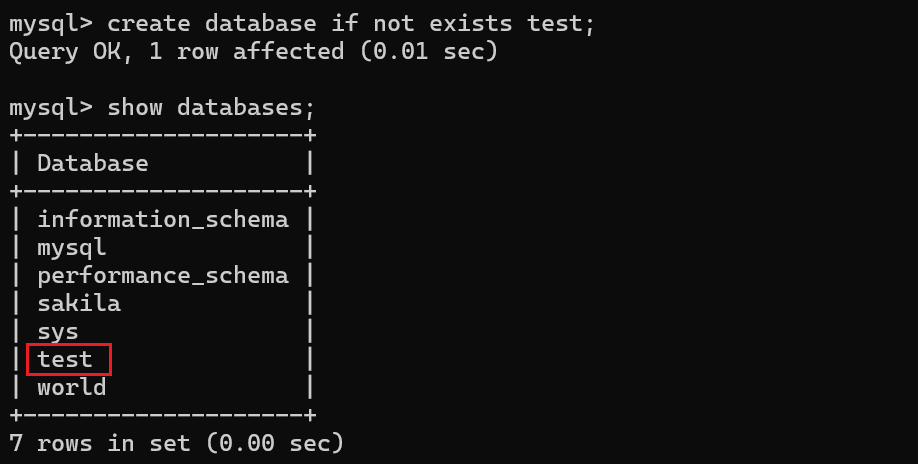
1.查看所有表
在创建表之前,我们肯定需要查看一下当前库中已经具备了哪些表,以防止重复创建:
show tables;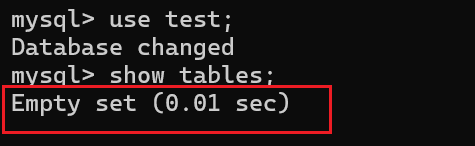
那么可以看见当前库中没有任何的表,这时候我们就要来创建表啦!
2.表的创建
创建表的语法:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_namefield datatype [约束] [comment '注解内容'][, field datatype [约束] [comment '注解内容']] ...
) [engine 存储引擎] [character set 字符集] [collate 排序规则];
- field:列名
- datatype:数据类型
- comment:对列的描述或说明
- engine:存储引擎,不指定则使⽤默认存储引擎
- character set:字符集,不指定则使⽤默认字符集
- collate:排序规则,不指定则使⽤默认排序规则
现在我们来创建一个学生表:
create table users (name VARCHAR(20) comment'姓名',age BIGINT COMMENT'年龄',class VARCHAR(20)COMMENT'班级'
) CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci; 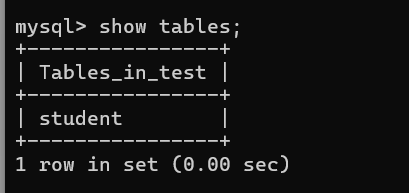
此时一个学生表就创建完成了,接下来我们查看一下当前学生表的结构~
3.查看表的结构
语法:
desc 表名;
查看刚才创建的学生表:
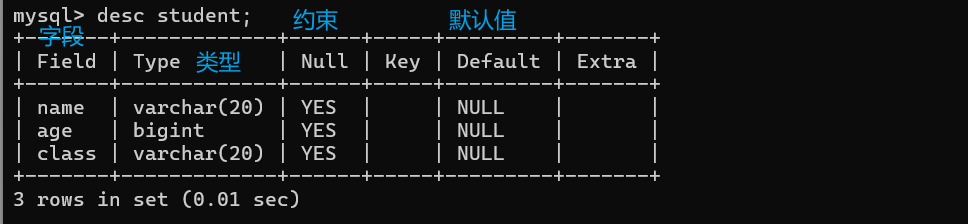
- Field:表中的列名
- Type:列的数据类型
- Null:该列的值是否允许为Null
- Key:该列的索引类型
- Default:该列的默认值
- Extra:扩展信息
4.表的修改
在我们的项目实际开发中,经常会对表结构进行调整,这个时候就要对表进行修改操作
ALTER TABLE tbl_name [alter_option [, alter_option] ...];
alter_option: {table_options| ADD [COLUMN] col_name column_definition [FIRST | AFTER col_name]| MODIFY [COLUMN] col_name column_definition [FIRST | AFTER col_name]| DROP [COLUMN] col_name| RENAME COLUMN old_col_name TO new_col_name| RENAME [TO | AS] new_tbl_name
- tbl_name:要修改的表名
- ADD:向表中添加列
- MODIFY:修改表中现有的列
- DROP:删除表中现有的列
- RENAME COLUMN:重命名表中现有的列
- RENAME [TO | AS] new_tbl_name:重命名当前的表
这么多修改表的操作,我们一个一个来看:
4.1 添加新的列
假设我们现在需要为刚才创建的添加一个birthday列;
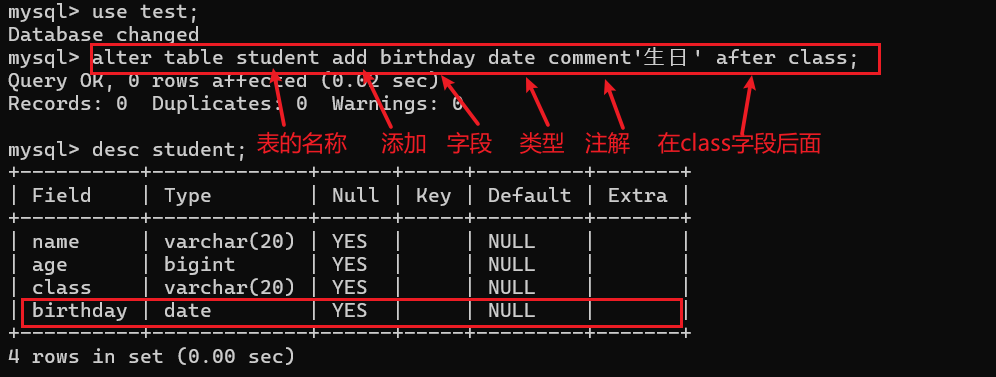
此时birthday列就被添加成功了,那么这是在尾部插入一个新的列,那么现在我想在头部插入一个gender列能不能实现呢?其实是可以实现的,只需要将最后的after改成first即可:
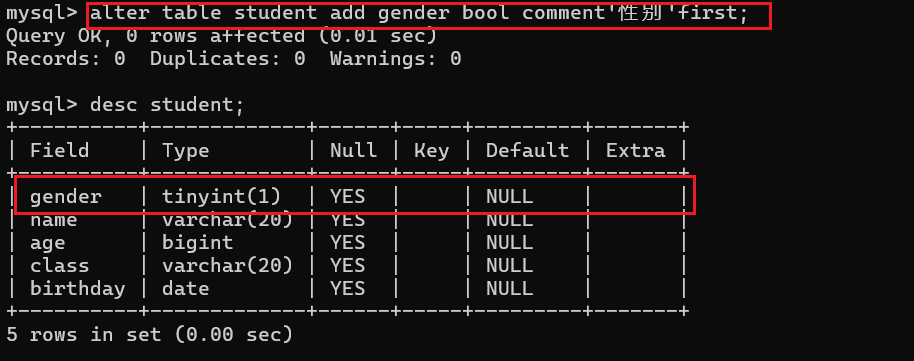
4.2 修改表中现有的列
那么假设说现在name列的varchar( 20 )不够用了,我需要做出调整改成varchar( 40 ):
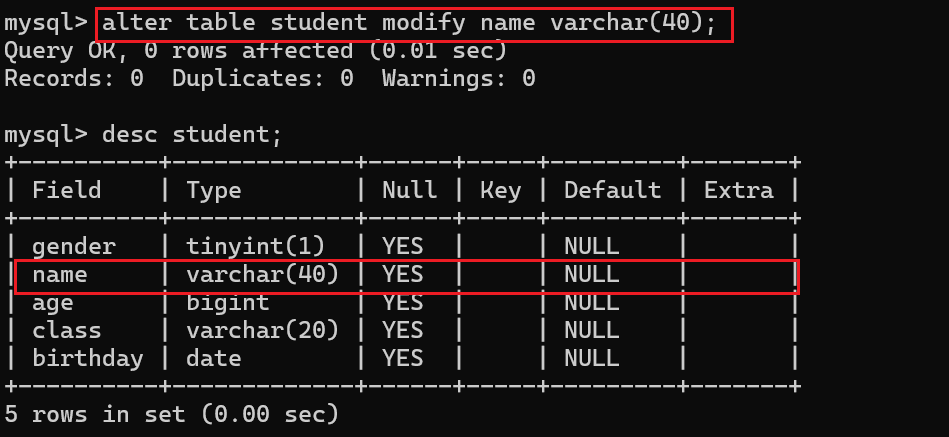
4.3 删除表中现有的列
现在我不需要birthday这个列了,需要将它删除:
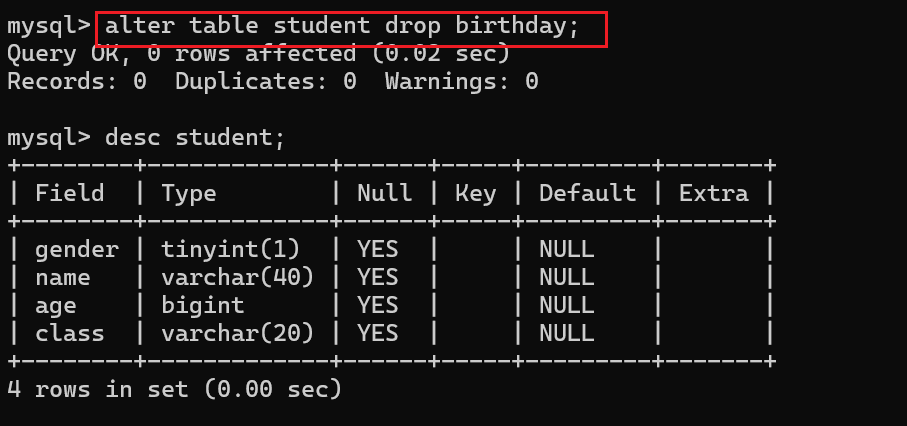
此时表中的birthday这个字段就被删除了
4.4 重命名表中现有的列
现在我需要将表中的name字段重命名成studentname:
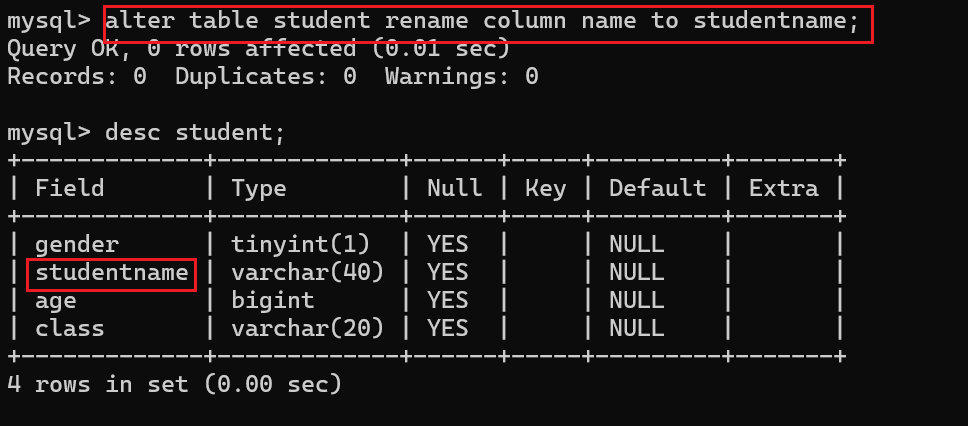
4.5 重命名当前表
我现在需要将当前student表重命名成students:
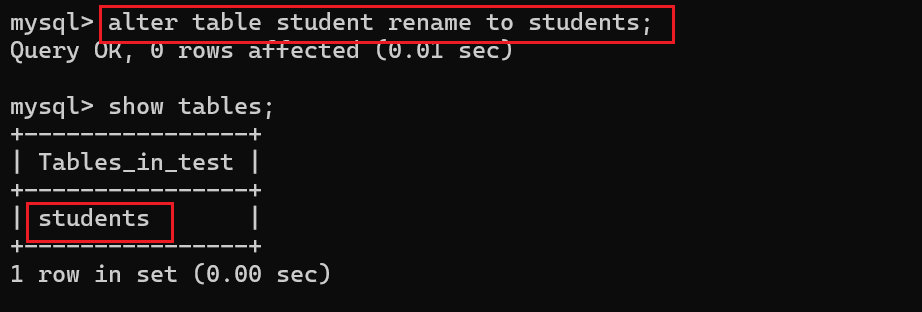
5.表的删除
语法:
DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name] ...
- TEMPORARY:表⽰临时表
- tbl_name:将要删除的表名
现在我们将刚才创建的students表删除:
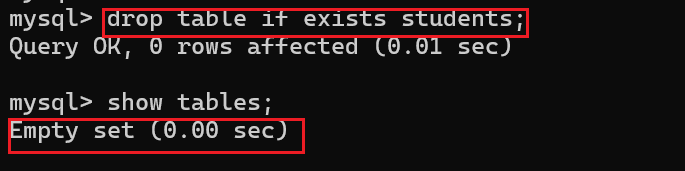
删除表不仅可以单个删除,同时也可以进行多个删除,那么我们现在重新创建两个表:student表和class表,然后进行多个表同时删除
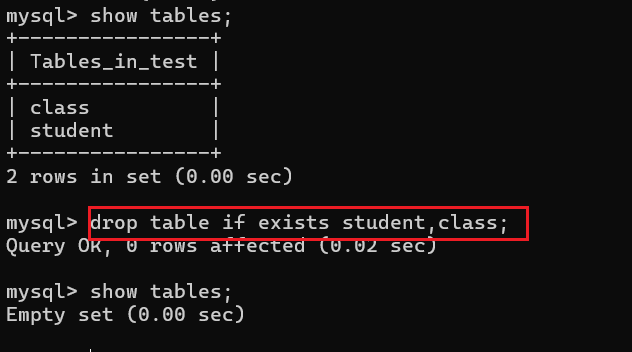
注:表的创建和删除跟库的创建和删除是类似的,都可以加上 if not exists 和 if exists来防止报错
