文章目录
- 前言
- 向量、令牌、嵌入
- 分块
- 按字符拆分
- 按字符递归拆分
- 按token拆分
- 向量化
- 使用 TextEmbedding 实现语义搜索
- 数据准备
- 通过 DashScope 生成 Embedding 向量
- 通过 DashVector 构建检索:向量入库
- 语义检索:向量查询
- 完整代码
- 总结
前言
Transformer 架构已经成为当今深度学习的趋势,大家一定也经常听到 token, 向量化,嵌入等名词概念,可以说这三个是 Transformer 架构实现自注意力的关键,限于本文主题,下边会简单介绍下这三个概念,以及之间的关系,但不会详细多说,网上已经有很多比较好的文章进行了说明总结。
现在有很多开源的库可以对文本进行分块,比如说 langchain的 text_splitter包,以及许多优秀的开源向量数据库,比如说Chroma,Milvus,Weaviate等,虽然我们可以使用这些开源的工具进行分块和向量化存储,但是我一直认为上云,使用云服务才是大势所趋(将这些中间件服务交给云服务商可以大大减少公司的运维费用)。
本文首先会对阿里云的向量检索服务DashVector进行简单使用说明,然后会结合灵积模型服务上的Embedding API,来从0到1构建基于文本索引的构建+向量检索基础上的语义搜索能力。具体来说,我们将基于QQ 浏览器搜索标题语料库(QBQTC:QQ Browser Query Title Corpus)进行实时的文本语义搜索,查询最相似的相关标题。
前提条件:
- 开通灵积模型服务,并获得 API-KEY:开通DashScope并创建API-KEY。
- 开通DashVector向量检索服务,并获得 API-KEYAPI-KEY管理。
- 已创建向量检索服务Cluster:创建Cluster。
- 已获得向量检索服务API-KEY:API-KEY管理。
- 已安装最新版SDK:安装DashVector SDK。
向量、令牌、嵌入
向量 (Vectors)
- 向量在LLM中扮演了基石的角色,通过将文本数据转换成高维向量空间中的表示,使机器能够理解语言。这种转换后的向量称为“语义向量嵌入”,能够编码和体现文本的实际语义信息。
- 与传统离散符号表示相比,语义向量嵌入能够自动捕捉并编码单词间的同义关系、语法关联及上下文语义信息,使得语义相似的词语在向量空间中彼此接近。
- 这种连续的向量表示简化了数据结构的复杂度,为神经网络模型提供了紧凑且信息丰富的内部数据形式,显著提升了模型的学习和表现能力。
令牌 (Tokens)
- 令牌是文本数据在LLM内部的表示形式,可以是单词、子词或字符,具体取决于令牌化策略。
- 令牌化是将原始文本转换为模型可解释的离散符号序列的过程,这一过程对模型的输入表示和计算效率产生直接影响。
- 合理的令牌化策略不仅能减少词汇表大小,解决未知词问题,还能为模型提供更好的语义信号,提高其泛化能力。不同LLM会采用不同的令牌化方案以最大化发挥模型潜力。
嵌入 (Embeddings)
- 嵌入是赋予令牌以语义语境的关键环节,代表了文本的意义和上下文信息。它是一种融入了语境的令牌表征,由嵌入模型生成,以向量形式存在,捕捉了令牌之间的语义关联和上下文依赖。
- 嵌入不仅编码了令牌的身份,更重要的是捕捉了令牌间的关系,使得LLM能够理解语境、微妙语义和词语/短语的细微差异。高质量的嵌入使得LLM在各类自然语言处理任务中展现出人类甚至超人类水平的能力。
三者关系
- 令牌、向量和嵌入在LLM的处理流程中紧密相关又各具特色。令牌是语言的最小单元,每个令牌在模型底层表现为向量,便于机器计算。
- 向量为令牌提供了数学框架,但仅凭向量难以准确反映语义信息,此时嵌入技术显得尤为重要。
- 嵌入是经过专门训练的向量表示,能够体现词语/短语间的相似性、类比关系等丰富语义,为LLM提供更细腻的语义理解基础。
- 令牌化将文本转换为离散标记,而嵌入则将这些标记映射到语义向量空间,赋予上下文语境,实现了从离散语言符号到连续语义空间的转变。
分块
pip install langchain
按字符拆分
# 读取需要拆分的文本内容
with open("../../splitters_test.txt") as f:state_of_the_union = f.read()from langchain_text_splitters import CharacterTextSplittertext_splitter = CharacterTextSplitter(separator="\n\n",chunk_size=1000,chunk_overlap=200,length_function=len,is_separator_regex=False,
)texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
- separators - 分隔符字符串数组
- chunk_size - 每个文档的字符数量限制
- chunk_overlap - 两份文档重叠区域的长度
- length_function - 长度计算函数
- is_separator_regex - 如果为真:应当被解释为正则表达式,因此不需要转义。如果为假:应当被当作普通字符串分隔符,并转义任何特殊字符。
将元数据与文档一起传递:
meta_datas = [{"document": 1}, {"document": 2}]
documents = text_splitter.create_documents([state_of_the_union, state_of_the_union], metadatas=meta_datas
)
print(len(documents))
print(documents[0])
print(documents[3])
按字符递归拆分
对于通用文本,建议使用此文本拆分器。它由字符列表参数化。它试图按顺序分割它们,直到这些块足够小。默认列表是 [“\n\n”, “\n”, " ", “”] 。这样做的效果是尽量将所有段落(然后是句子,然后是单词)保持在一起,因为这些段落一般看起来是语义最相关的文本片段。
from langchain_text_splitters import RecursiveCharacterTextSplitter# This is a long document we can split up.
with open("./demo_static/splitters_test.txt") as f:state_of_the_union = f.read()text_splitter = RecursiveCharacterTextSplitter(# Set a really small chunk size, just to show.chunk_size=100,chunk_overlap=20,length_function=len,is_separator_regex=False,
)texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
从没有单词边界的语言中拆分文本
一些书写系统没有单词边界,例如 中文 、日文和泰文。使用默认分隔符列表拆分文本[“\n\n”, “\n”, " ", “”]会导致单词在单词块之间拆分。
text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n","\n"," ",".",",","\u200B", # Zero-width space"\uff0c", # Fullwidth comma"\u3001", # Ideographic comma"\uff0e", # Fullwidth full stop"\u3002", # Ideographic full stop"",],# Existing args
)
按token拆分
使用 tiktoken
pip install --upgrade --quiet langchain-text-splitters tiktoken
from langchain_text_splitters import CharacterTextSplitter
# This is a long document we can split up.
with open("./demo_static/splitters_test.txt") as f:state_of_the_union = f.read()text_splitter = CharacterTextSplitter.from_tiktoken_encoder(model_name="gpt-4", chunk_size=100, chunk_overlap=0
)
texts = text_splitter.split_text(state_of_the_union)
使用 spacypip install --upgrade --quiet spacy
from langchain_text_splitters import SpacyTextSplitter
# This is a long document we can split up.
with open("./demo_static/splitters_test.txt") as f:state_of_the_union = f.read()text_splitter = SpacyTextSplitter(chunk_size=1000)texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
使用 SentenceTransformers
from langchain_text_splitters import SentenceTransformersTokenTextSplittersplitter = SentenceTransformersTokenTextSplitter(chunk_overlap=0)
text = "Lorem "count_start_and_stop_tokens = 2
text_token_count = splitter.count_tokens(text=text) - count_start_and_stop_tokens
print(text_token_count)token_multiplier = splitter.maximum_tokens_per_chunk // text_token_count + 1# `text_to_split` does not fit in a single chunk
text_to_split = text * token_multiplierprint(f"tokens in text to split: {splitter.count_tokens(text=text_to_split)}")text_chunks = splitter.split_text(text=text_to_split)print(text_chunks[1])
使用 NLTKpip install nltk
from langchain_text_splitters import NLTKTextSplitter# This is a long document we can split up.
with open("./demo_static/splitters_test.txt") as f:state_of_the_union = f.read()text_splitter = NLTKTextSplitter(chunk_size=1000)texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
向量化
这里使用阿里云的 DashVector云服务进行向量化操作,包括存储与检索,首先需要确定我们已经开通了上边的前提条件。(现在可以免费开通试用一个月),向量检索服务官方文档。
pip install dashvector
创建 Client
YOUR_API_KEY 和 YOUR_CLUSTER_ENDPOINT 可以在向量检索服务控制台查看 。
import dashvectorclient = dashvector.Client(api_key='YOUR_API_KEY',endpoint='YOUR_CLUSTER_ENDPOINT'
)
assert client
创建Collection
创建一个名称为quickstart,向量维度为4的collection。
client.create(name='quickstart', dimension=4)collection = client.get('quickstart')
assert collection
插入Doc
from dashvector import Doc# 通过dashvector.Doc对象,插入单条数据
collection.insert(Doc(id='1', vector=[0.1, 0.2, 0.3, 0.4]))# 通过dashvector.Doc对象,批量插入2条数据
collection.insert([Doc(id='2', vector=[0.2, 0.3, 0.4, 0.5], fields={'age': 20, 'name': 'zhangsan'}),Doc(id='3', vector=[0.3, 0.4, 0.5, 0.6], fields={'anykey': 'anyvalue'}) ]
)
- 这里的
fields是为了增加检索准确性,可以在检索的时候加上一些过滤条件等,具体的可以参考文档。 - 插入成功后可以在向量检索服务控制台看到我们插入的向量数据:
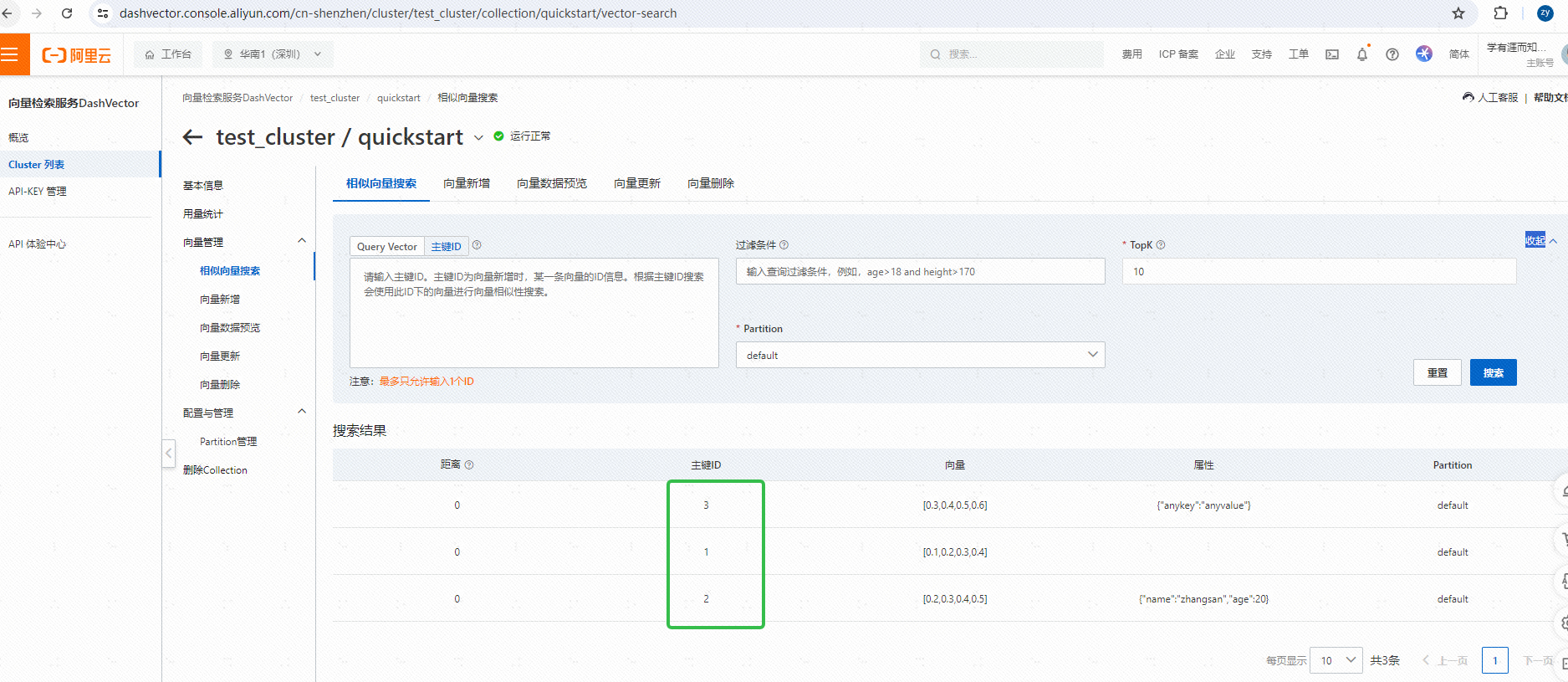
相似性检索
rets = collection.query([0.1, 0.2, 0.3, 0.4], topk=2)print(rets)# 输出如下
{"code": 0, "message": "Success", "requests_id": "24731ff6-d3b4-475a-9309-d66428b684bc", "output": [{"id": "1", "fields": {}, "score": 0.0}, {"id": "2", "fields": {"age": 20, "name": "zhangsan"}, "score": 0.0062}]}
删除Doc
# 删除1条数据
collection.delete(ids=['1'])
查看Collection统计信息
stats = collection.stats()print(stats)
删除Collection
client.delete('quickstart')
上边都是对简单的 CRUD 操作,还有一些比较高级的使用,比如说使用 Field 字段过滤,增加检索准确性,使用 分区 Partition,向量动态量化等,官方文档都写的很清晰,这里只起一个抛砖引玉的作用,如果要在生产环境中使用,还是得全面了解下官方文档。
使用 TextEmbedding 实现语义搜索
接下来我们利用 DashVector 和 Embedding API 构建一个实时的索引服务和查询。
具体的架构图如下: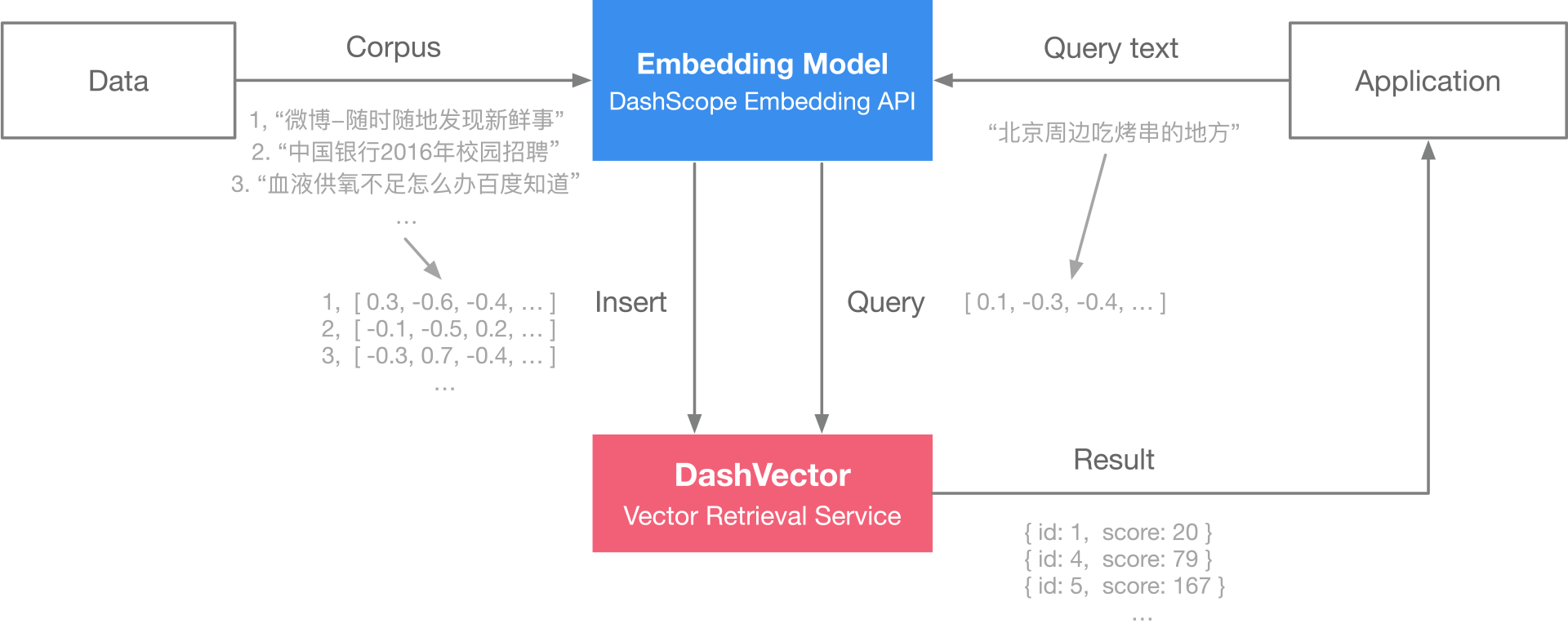
环境安装pip3 install dashvector dashscope
数据准备
git clone https://github.com/CLUEbenchmark/QBQTC.git
wc -l QBQTC/dataset/train.json
数据集中的训练集(train.json)其格式为 json:
{"id": 0, "query": "小孩咳嗽感冒", "title": "小孩感冒过后久咳嗽该吃什么药育儿问答宝宝树", "label": "1"
}
我们将从这个数据集中提取title,方便后续进行embedding并构建检索服务。
import jsondef prepare_data(path, size):with open(path, 'r', encoding='utf-8') as f:batch_docs = []for line in f:batch_docs.append(json.loads(line.strip()))if len(batch_docs) == size:yield batch_docs[:]batch_docs.clear()if batch_docs:yield batch_docs
通过 DashScope 生成 Embedding 向量
import dashscope
from dashscope import TextEmbedding# 需要使用自己的api-key替换示例中的 your-dashscope-api-key
dashscope.api_key='{your-dashscope-api-key}'def generate_embeddings(text):rsp = TextEmbedding.call(model=TextEmbedding.Models.text_embedding_v1,input=text)embeddings = [record['embedding'] for record in rsp.output['embeddings']]return embeddings if isinstance(text, list) else embeddings[0]# 查看下embedding向量的维数,后面使用 DashVector 检索服务时会用到,目前是1536
print(len(generate_embeddings('hello')))
- 需要使用自己的api-key替换示例中的 your-dashscope-api-key
通过 DashVector 构建检索:向量入库
DashVector 向量检索服务上的数据以集合(Collection)为单位存储,写入向量之前,我们首先需要先创建一个集合来管理数据集。创建集合的时候,需要指定向量维度,这里的每一个输入文本经过DashScope上的text_embedding_v1模型产生的向量,维度统一均为1536。
DashVector 除了提供向量检索服务外,还提供倒排过滤功能 和 scheme free 功能。所以我们为了演示方便,可以写入数据时,可以将title内容写入 DashVector 以便召回。写入数据还需要指定 id,我们可以直接使用 QBQTC 中id。
from dashvector import Client, Doc# 初始化 DashVector client
client = Client(api_key='{your-dashvector-api-key}',endpoint='{your-dashvector-cluster-endpoint}'
)# 指定集合名称和向量维度
rsp = client.create('sample', 1536)
assert rspcollection = client.get('sample')
assert collectionbatch_size = 10
for docs in list(prepare_data('QBQTC/dataset/train.json', batch_size)):# 批量 embeddingembeddings = generate_embeddings([doc['title'] for doc in docs])# 批量写入数据rsp = collection.insert([Doc(id=str(doc['id']), vector=embedding, fields={"title": doc['title']}) for doc, embedding in zip(docs, embeddings)])assert rsp
语义检索:向量查询
在把QBQTC训练数据集里的title内容都写到DashVector服务上的集合里后,就可以进行快速的向量检索,实现“语义搜索”的能力。继续上面代码的例子,假如我们要搜索有多少和’应届生 招聘’相关的title内容,可以通过在DashVector上去查询’应届生 招聘’,即可迅速获取与该查询语义相近的内容,以及对应内容与输入之间的相似指数。
# 基于向量检索的语义搜索
rsp = collection.query(generate_embeddings('应届生 招聘'), output_fields=['title'])for doc in rsp.output:print(f"id: {doc.id}, title: {doc.fields['title']}, score: {doc.score}")
完整代码
import jsonimport dashscope
from dashscope import TextEmbedding
from dashvector import Client, Docdef prepare_data(path, size):with open(path, 'r', encoding='utf-8') as f:batch_docs = []for line in f:batch_docs.append(json.loads(line.strip()))if len(batch_docs) == size:yield batch_docs[:]batch_docs.clear()if batch_docs:yield batch_docsdef init_vector_collections(api_key, endpoint):client = Client(api_key=api_key,endpoint=endpoint)# 指定集合名称和向量维度client.create('sample', 1536)collection = client.get('sample')return collectiondef generate_embeddings(text):rsp = TextEmbedding.call(model=TextEmbedding.Models.text_embedding_v1,input=text)embeddings = [record['embedding'] for record in rsp.output['embeddings']]return embeddings if isinstance(text, list) else embeddings[0]# 查看下embedding向量的维数,后面使用 DashVector 检索服务时会用到,目前是1536
# print(len(generate_embeddings('hello')))def write_embeddings(path, collection):batch_size = 10for docs in list(prepare_data(path, batch_size)):# 批量 embeddingembeddings = generate_embeddings([doc['title'] for doc in docs])# 批量写入数据rsp = collection.insert([Doc(id=str(doc['id']), vector=embedding, fields={"title": doc['title']})for doc, embedding in zip(docs, embeddings)])assert rspdef query(query_str, output_field, collection):# 基于向量检索的语义搜索rsp = collection.query(generate_embeddings(query_str), output_fields=[output_field])for doc in rsp.output:print(f"id: {doc.id}, title: {doc.fields['title']}, score: {doc.score}")if __name__ == '__main__':# 下边的 api key 和 endpoint 需要替换为自己的dashscope.api_key = ''vector_api_key = ''vector_endpoint = ''path = 'train.json'collection = init_vector_collections(vector_api_key, vector_endpoint)# write_embeddings(path, collection)query('应届生 招聘', 'title', collection)
查询结果如下:
id: 301, title: 2015四大之路给自己最完美的交代-普华永道pwc2021校园招聘-应届生求职招聘论坛, score: 0.5732
id: 285, title: 关于实习生考研请假的实施意见试行-河南省中医院, score: 0.5834
id: 427, title: 2013年高考就业率高的专业建筑学专业高考热门专业专业解读中国教育在线, score: 0.6353
id: 295, title: 太原理工大学研究生院, score: 0.6492
id: 134, title: 昆山人才网昆山人力资源网-昆山人才网昆山政府旗下唯一官方招聘网昆山人才市场昆山人力资源市场主办, score: 0.6622
id: 202, title: 国家公务员报考条件-搜狗百科, score: 0.6672
id: 435, title: 西南财经大学继续网络教育学院门户网站, score: 0.6685
id: 52, title: 2014年1月教师要涨工资了峡山区吧百度贴吧, score: 0.6891
id: 193, title: directsalesjobsinhongkong-sep2020jobsdb, score: 0.7003
id: 280, title: 机场副总经理竞聘报告副总经理竞聘述职竞聘稿副总经理兼总经济师竞聘-fanwenqcn, score: 0.7054
总结
如何将数据分块,然后向量化嵌入向量数据库中,是 LLM 能够成功预测下一个 token 的关键,本文简单介绍了阿里云向量数据库 DashVector 的使用,并且使用一个具体的案例,将整个流程给串起来,关于 DashVector 还有很多高级功能这里并没有使用,读者可以 自行探索使用以下。
后续我会结合阿里云的通义千问大模型和 DashVector 打造一个专业的知识库,以及如何使用多模态嵌入和大模型交互的场景实战。