双目视觉中的动态畸变矫正是一种实时修正图像因镜头畸变导致的几何形变的过程,其核心是通过数学模型和硬件加速技术实现像素的重新映射与插值。以下是具体过程的分步解析:
1. 畸变模型与参数加载
动态畸变矫正的前提是已知相机的内参矩阵(包含焦距、主点坐标等)和畸变系数(如径向畸变系数 k1,k2,k3 和切向畸变系数 p1,p2)。这些参数通常通过标定(如张正友标定法)预先计算并存储在系统中。在动态处理时,这些参数被加载至硬件(如FPGA)中,用于实时计算畸变校正的映射关系。
2. 像素坐标映射与重新排列
矫正的核心是像素的重新映射,即通过数学模型将畸变图像中的像素坐标 (xp,yp)(x_p, y_p)(xp,yp) 反向映射到原始无畸变图像中的坐标 (xs,ys)(x_s, y_s)(xs,ys)。具体步骤包括:
- 畸变反向变换:利用畸变模型公式(如径向畸变公式 xcorrected= x(1 + k_1 r^2 + k_2 r^4 + k_3 r^6),其中r 为像素到主点的距离),计算每个像素在原始图像中的对应位置。
- 坐标格式处理:映射坐标的小数部分以定点数(如Q12.20格式)存储,便于后续插值计算。
3. 像素数据读取与缓存
在实时处理中,图像数据以像素流形式传输至FPGA,并通过高速缓存(如Ultra RAM)进行存储。由于双目相机通常采用YUV422格式,需将8位数据扩展对齐至72位带宽,以适应硬件存储要求。这一步骤确保了后续插值计算的高效数据访问。
4. 双线性插值计算
由于映射坐标可能非整数,需通过插值算法从相邻像素的灰度值中计算目标像素的最终值。双线性插值是常用方法,具体过程如下:
-
邻近像素选取:根据映射坐标的整数部分 (m,n),读取周围四个像素点 (m,n)、(m+1,n)、(m,n+1)、(m+1,n+1) 的值。
-
插值计算:在x和y方向分别进行线性插值,最终结合小数部分权重计算目标像素的灰度值。公式表示为:
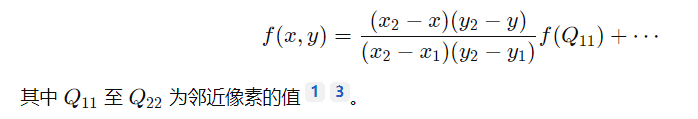
5. 输出矫正后的图像
通过流水线处理,FPGA在每个时钟周期完成一个像素的映射和插值计算,最终输出矫正后的YUV三通道视频流。这一过程实现了高分辨率双目图像的实时动态矫正,满足机器人导航、三维重建等场景的需求。
关键技术与创新点
- 硬件加速:FPGA的并行计算能力和流水线设计确保了高分辨率图像的实时处理。
- 像素重新排列:通过坐标映射和插值实现像素的几何位置修正,而非简单的像素复制或移动。
- 动态适应性:支持上位机实时更新畸变参数,适应不同镜头或环境变化。
总结
动态畸变矫正通过数学模型反向映射像素坐标,并结合插值算法重新排列像素灰度值,最终消除镜头畸变对图像几何精度的影响。这一过程在FPGA等硬件平台上高效实现,兼顾了实时性与计算精度。
在双目视觉系统中,利用左右图像的信息互补性优化动态畸变矫正中的像素重新排列是可行的,其核心思想是通过立体匹配、视差约束和跨视角插值等策略,提升校正精度与鲁棒性。以下是具体分析及优化设想:
1. 基于立体匹配的畸变参数联合优化
问题背景
- 传统单目畸变矫正依赖标定参数,但实际场景中动态变化(如温度漂移、机械振动)可能导致参数偏移。
- 左右相机因安装角度差异,同一物理点的畸变表现可能不同。
优化方法
- 双目联合标定:在标定阶段引入立体约束,优化左右相机畸变参数的一致性。例如,通过共视特征点的重投影误差最小化,联合优化k1,k2,p1,p2。
- 在线参数修正:实时提取左右图像的匹配特征点(如SIFT、ORB),利用三角化后的3D点反推畸变参数误差,动态更新校正模型。
技术优势
- 减少单目标定参数误差累积,提升双目系统的整体几何一致性。
- 适应环境变化(如车载相机因温度导致的镜头形变)。
2. 视差约束下的插值优化
问题背景
- 单目插值依赖局部像素邻域,但在遮挡或弱纹理区域易出现模糊。
- 左右图像的视差信息可提供几何先验,辅助缺失区域的像素预测。
优化方法
- 视差引导插值:
- 稀疏视差估计:在畸变矫正前,快速提取左右图像的稀疏匹配点对,计算初始视差图。
- 插值权重修正:对于畸变矫正中的待插值像素,结合其视差值调整邻域权重。例如,若左图某区域因畸变遮挡,利用右图对应视差区域的像素补充插值源。
- 遮挡区域补偿:通过左右图像视差范围预测遮挡边界,优先使用非遮挡侧图像的像素进行插值。
技术优势
- 减少弱纹理或遮挡区域的插值误差,提升校正后图像的立体匹配可靠性。
- 避免单目插值导致的边缘模糊(如棋盘格标定板的角点变形)。
3. 跨视角像素融合与置信度加权
问题背景
- 左右图像因视角差异,同一场景区域的畸变程度可能不同(如广角镜头边缘畸变更严重)。
- 单目校正可能无法充分利用对侧图像的未畸变信息。
优化方法
- 多尺度像素融合:
- 畸变置信度评估:根据像素坐标与主点的距离
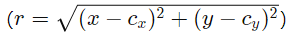 ,计算左/右图像中各像素的畸变置信度权重(如w=e^−r^2/σ)。
,计算左/右图像中各像素的畸变置信度权重(如w=e^−r^2/σ)。 - 跨视角加权插值:对左右图像校正后的对应像素进行加权融合,畸变严重的像素赋予较低权重,反之亦然。
- 畸变置信度评估:根据像素坐标与主点的距离
- 自适应融合策略:在FPGA中设计并行流水线,实时计算左右像素的权重并输出融合结果。
技术优势
- 抑制单目图像的高畸变区域噪声,提升整体图像质量。
- 适用于大基线双目系统(如无人机避障),其中左右图像互补性更强。
4. 动态立体校正与深度一致性约束
问题背景
- 传统方法先独立矫正左右图像,再进行立体匹配,但分步处理可能引入累积误差。
- 校正后的图像需满足共面极线约束,以简化立体匹配。
优化方法
- 闭环立体校正:
- 迭代优化:在校正过程中引入深度一致性约束,即左右图像校正后对应的匹配点应满足极线约束和深度平滑性。
- 重投影误差最小化:通过非线性优化(如Levenberg-Marquardt算法)联合优化畸变参数和像素映射关系。
- 硬件加速设计:在FPGA中实现视差与校正参数的并行迭代计算,满足实时性要求。
技术优势
- 打破“先矫正后匹配”的传统流程,减少分步误差。
- 提升校正后图像的立体匹配效率和深度图精度。
5. 基于深度学习的跨视角补全
问题背景
- 传统方法依赖几何模型,难以处理复杂畸变或极端遮挡。
- 深度学习在图像补全和跨视角生成中表现出色。
优化方法
- 端到端网络设计:
- 输入:原始畸变的左右图像 + 标定参数(内参、畸变系数)。
- 输出:校正后的左右图像 + 置信度掩模。
- 网络结构:采用Siamese双分支网络,共享权重提取特征,通过交叉注意力机制融合左右图像信息。
- 训练策略:
- 合成数据:渲染带有不同畸变参数的虚拟双目图像对。
- 损失函数:结合像素级L1损失、结构相似性(SSIM)和极线约束损失。
技术优势
- 自适应复杂畸变模式,无需显式数学模型。
- 在GPU上可实现实时推理,适合嵌入式平台部署。
总结与挑战
- 优势:通过立体信息互补,可显著提升动态畸变矫正的鲁棒性,尤其在边缘畸变、遮挡和弱纹理区域。
- 挑战:
- 计算复杂度:需平衡算法精度与实时性,尤其在资源受限的嵌入式平台。
- 标定依赖:深度学习方法仍需要精确的标定参数作为输入。
- 遮挡处理:极端遮挡可能导致信息不可恢复,需结合时序信息或传感器融合。
- 未来方向:结合传统几何方法与深度学习,设计轻量级自适应校正框架,实现高精度与低延迟的平衡。
在双目视觉系统中,左右图像因视角差异存在互补的视野信息(左图包含右图未覆盖的区域,反之亦然)。通过跨视角信息融合与几何约束,可有效扩展场景覆盖范围并提升图像完整性。以下是具体优化方案及实现路径:
1. 基于深度图的遮挡区域检测与补偿
核心思路
利用视差生成的深度图定位遮挡区域(即单侧可见的区域),并通过投影变换从对侧图像中提取对应像素填补空缺。
实现步骤
- 立体校正与视差计算:
- 对原始左右图像进行动态畸变矫正,确保极线对齐。
- 通过半全局匹配(SGM)或深度学习模型(如PSMNet)生成高精度视差图。
- 遮挡区域检测:
- 根据视差图判断左右图像中的无效区域(如视差值为0或超出合理范围的像素)。
- 标记左图遮挡区域为MLM_LML,右图遮挡区域为MRM_RMR。
- 跨视角投影填补:
- 对于左图遮挡区域MLM_LML中的像素(x,y) (x, y) (x,y),根据深度图计算其3D坐标,并投影至右图坐标系,获取右图对应像素值填充。
- 右图遮挡区域MRM_RMR同理,利用左图信息反向填补。
技术优势
- 几何精确性高,填补区域与场景结构一致。
- 适用于静态或慢动态场景。
硬件实现
- FPGA中设计视差计算与投影变换的并行流水线,利用深度图的稀疏性减少计算量。
2. 多视角图像拼接与动态融合
核心思路
将左右图像的扩展视野部分拼接为全景图,并通过动态加权融合消除接缝。
实现步骤
- 特征匹配与变换矩阵估计:
- 提取左右图像非重叠区域的SIFT或ORB特征点。
- 计算单应性矩阵HHH,将右图非重叠部分变换到左图坐标系。
- 重叠区域动态融合:
-
在拼接重叠区域,根据像素距离拼接边界的权重进行线性混合:
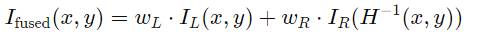
其中权重wL+wR=1,边界处wL从1渐变至0。
-
- 非重叠区域直接拼接:
- 左图非重叠部分直接保留,右图变换后填补空白区域。
技术优势
- 显著扩展有效视野,适用于广角或鱼眼镜头的双目系统。
- 实时性高,适合FPGA流水线处理。
挑战与改进
- 动态场景模糊:通过光流估计对齐时序帧,减少运动伪影。
- 光照差异:在融合前进行直方图匹配或颜色校正。
3. 生成对抗网络(GAN)的跨视角补全
核心思路
利用深度学习模型,根据单侧图像生成对侧缺失区域的合理内容,并结合几何约束提升生成真实性。
实现步骤
- 网络架构设计:
- 推理优化:
- 在GPU上训练模型,部署时通过TensorRT量化至FPGA,实现低延迟推理。

技术优势
- 可生成复杂纹理和结构,适用于极端遮挡或动态物体。
- 端到端优化,无需显式几何计算。
局限性
- 依赖大量标注数据,需合成带遮挡的双目数据集。
- 硬件资源消耗较高,需权衡模型规模与实时性。
4. 动态视角合成与虚拟视点生成
核心思路
基于左右图像及深度图,合成中间虚拟视角图像,覆盖原始视野之外的区域。
实现步骤
- 深度图引导的视图合成:
- 对左图ILI_LIL和右图IRI_RIR分别反向投影至3D空间,生成点云。
- 选择虚拟视点位置(如基线中点),将点云重投影至该视点,生成合成图像IVI_VIV。
- 空洞填补与滤波:
- 检测合成图像中的空洞(无投影来源的像素),使用邻域插值或非局部均值滤波填补。
- 多视图融合:
- 将原始左右图与合成虚拟视图拼接,形成超宽视野图像。
技术优势
- 生成超出物理相机基线的视野范围。
- 适用于自由视点视频生成等应用。
硬件优化
- FPGA中实现点云投影与空洞填补的并行计算,利用深度图的空间连续性加速处理。
5. 实时混合处理框架
系统架构
- 预处理层:
- FPGA完成动态畸变矫正与立体校正。
- 核心处理层:
- 并行执行视差计算(SGM)、遮挡检测与跨视角填补。
- 轻量级GAN模型填补复杂遮挡区域。
- 后处理层:
- 多波段融合消除拼接接缝,输出扩展视野图像。
资源分配
- 视差计算:占用FPGA的DSP单元,优化为8x8并行窗口处理。
- GAN推理:通过固化模型至FPGA的BRAM,利用流水线化卷积加速。
总结与展望
通过几何约束、深度学习与硬件加速的结合,可高效利用双目图像的互补视野信息,显著提升场景覆盖范围与细节完整性。未来方向包括:
- 自适应融合策略:根据场景动态调整填补算法(几何方法优先于静态区域,GAN优先于动态遮挡)。
- 传感器融合:结合IMU数据预测相机运动,优化动态场景下的填补效果。
- 边缘计算优化:设计低功耗FPGA架构,支持4K分辨率实时处理。