文章目录
- 1 MySQL数据库简介
- 1.1 下载phpstudy_pro链接
- 1.2 为什么学习数据库
- 1.3 常见的数据库
- 1.4 MySQL的特点
- 1.5 MySQL的核心概念
- 2 MySQL的默认库
- 2.1 information_schema
- 2.2 mysql
- 2.3 performance_schema
- 2.4 sys
- 2.5 总结
- 3 MySQL基础操作
- 3.1 登录MySQL数据库
- 3.2 MySQL创建表操作
- 3.3 常见的数据类型
- 3.4 MySQL表中的数据操作
- 3.5 MySQL表的修改
- 4 MySQL查询操作
- 4.1 基础查询
- 4.2 判断为空
- 4.3 逻辑判断
- 4.3 排序
- 4.4 限制
- 4.5 去重
- 4.6 模糊查询
- 4.7 范围查询
- 4.8 聚合函数
- 4.9 分组查询
- 4.10 表链接查询
- 4.11 UNION合并查询
1 MySQL数据库简介
1.1 下载phpstudy_pro链接
Phpstudy网盘下载
Tips:
- 也可以去官网下载其他版本的MySQL,Phpstudy_pro默认为MySQL5.7.26版本。
- 若本机已安装MySQL,还要运行Phpstudy_pro,必须将已安装的MySQL服务器终止,否则将端口冲突。
- 终止操作:打开DOS命令窗—>输入
net stop mysql80(此处的80是我已安装的MySQL版本MySQL8.0)
1.2 为什么学习数据库
所有程序的核心都是数据,而数据存储在数据库当中,因此我们要学习数据库
程序的组成:前端(负责展示数据)后端(提供和处理数据)保存数据(保存到数据库当中)
1.3 常见的数据库
关系型数据库:Oracle ,DB2,Microsoft Server ,Microsoft Access ,MYSQL
特点:所有数据库以表格的形式进行存储,并且表格和表格之间会有关联
非关系型数据库:NMongoDb ,redis ,HBase
特点:以非表格形式进行存储的数据库,比如以键值对存储的redis,比如说jison形式存储,以列表形式存储的
1.4 MySQL的特点
开源免费:MySQL 是开源软件,遵循 GPL 协议,可以免费使用
跨平台支持:支持 Windows、Linux、macOS 等多种操作系统
高性能:优化了查询处理和数据存储,支持高并发访问
易用性:提供了丰富的工具和文档,学习成本较低
可扩展性:支持分布式架构和集群部署
安全性:提供了用户权限管理、数据加密等安全功能
兼容性:支持标准 SQL 语法,兼容多种编程语言(如 PHP、Python、Java 等)
1.5 MySQL的核心概念
数据库(Database)
一个容器,用于存储表和数据;
表(Table)
由行和列组成的二维数据结构,用于存储具体数据;
行(Row)
表中的一条记录;
列(Column)
表中的一个字段,定义了数据的类型和约束;
主键(Primary Key)
唯一标识表中每一行的字段;
外键(Foreign Key)
用于建立表与表之间的关系;
索引(Index)
用于加速数据查询的数据结构
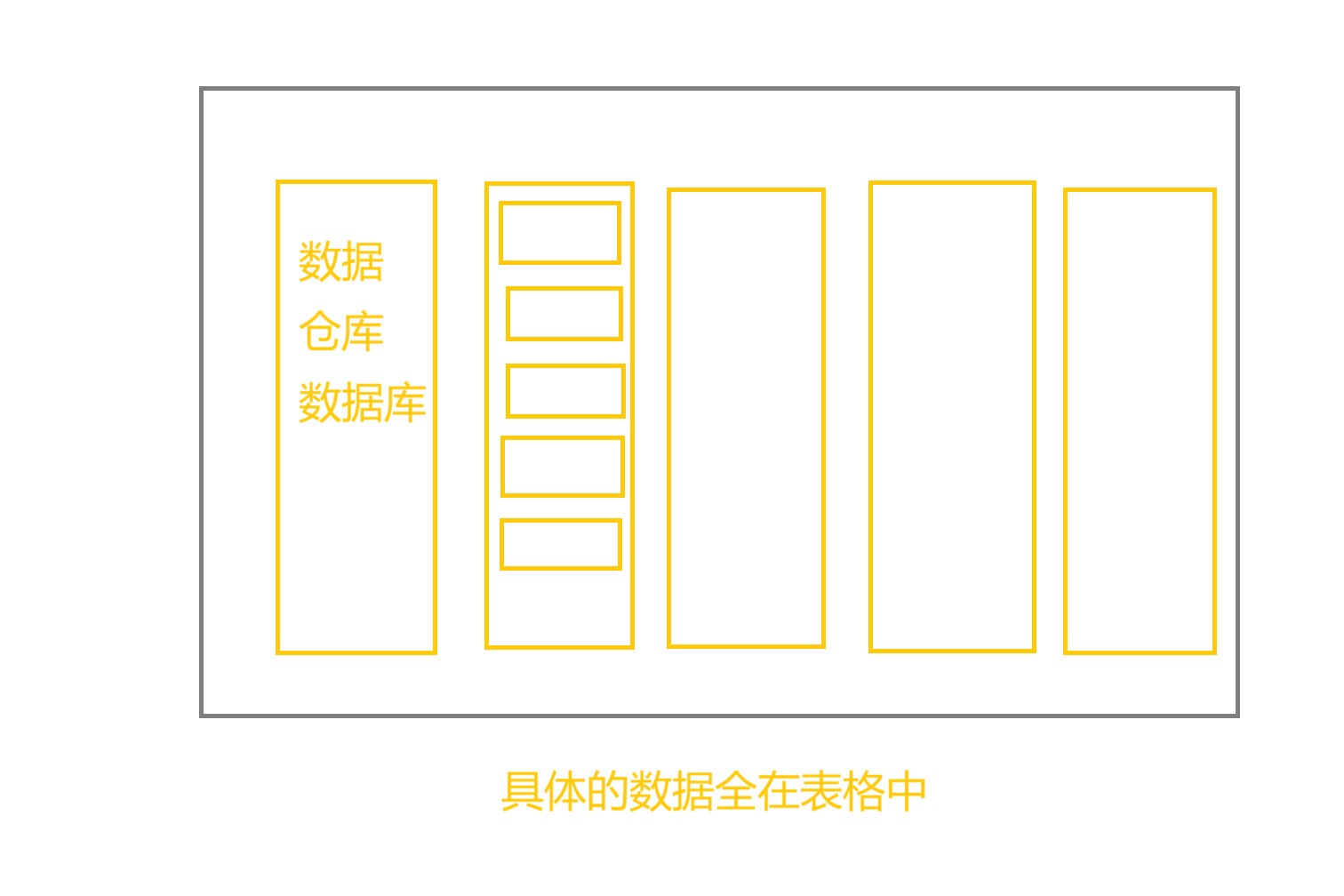
关系型数据库结构
数据都存储在mysql中的数据仓库中的数据表中
2 MySQL的默认库
2.1 information_schema
作用: 存储 MySQL 服务器的元数据信息,包括数据库、表、列、索引、权限等;
特点: 这是一个虚拟数据库,数据并不存储在磁盘上,而是通过内存动态生成只读,用户不能修改其中的数据;
常用表:
TABLES:存储所有表的信息;
COLUMNS:存储所有列的信息;
SCHEMATA:存储所有数据库的信息 ;
STATISTICS:存储索引的统计信息。
示例:
----查看所有数据库
SELECT * FROM information_schema.SCHEMATA;
2.2 mysql
作用: 存储 MySQL 服务器的系统信息,包括用户权限、插件、日志等;
特点: 这是一个实际的数据库,数据存储在磁盘上,包含 MySQL 的核心系统表,用于管理用户和权限;
常用表:
user:存储用户账户和全局权限;
db:存储数据库级别的权限;
tables_priv:存储表级别的权限 ;
columns_priv:存储列级别的权限 ;
plugin:存储插件信息。
示例:
----查询所有用户
SELECT User,Host FROM mysql.user;
2.3 performance_schema
作用: 存储 MySQL 服务器的性能监控数据,用于分析和优化数据库性能;
特点: 这是一个虚拟数据库,数据通过内存动态生成主要用于监控 MySQL 的运行状态;
常用表:
events_waits_current:存储当前等待事件;
events_statements_summary_by_digest:存储 SQL 语句的统计信息 ;
file_summary_by_event_name:存储文件 I/O 的统计信息。
示例:
---查询最耗时的SQL语句
SELECT * FROM
performance_schema.events_statements_summary_by_digest
ORDER BY SUM_TIMER_WAIT DESC LIMIT 10;
2.4 sys
作用: 提供一组视图和存储过程,用于简化 performance_schema 和 information_schema 的查询;
特点: 这是一个辅助数据库,基于 performance_schema 和 information_schema 提供更易用的接口,需要手动安装(MySQL 5.7 及以上版本默认包含);
常用视图:
schema_table_statistics:显示表的统计信息 ;
statement_analysis:分析 SQL 语句的性能 ;
user_summary:显示用户的活动统计信息。
示例:
---查询最活跃的用户
SELECT * FROM sys.user_summary ORDER BY total_connections DESC;
2.5 总结
information_schema:用于查询元数据
mysql:用于管理用户和权限
performance_schema:用于性能监控
sys:提供性能分析的简化接口
注意事项(不能随意修改默认的数据库)
1、information_schema 和 performance_schema 是只读的,不能修改
2、mysql 库存储了核心系统信息,修改可能导致数据库无法正常运行
3 MySQL基础操作
3.1 登录MySQL数据库
mysql超级管理员账号:root ; 密码:root(Phpstudy内置的MySQL)
进入数据库
Microsoft Windows [版本 10.0.26100.3775]
(c) Microsoft Corporation。保留所有权利。C:\Users\31245>mysql -uroot -p
PassWord:root
解析:-u后接要登录的用户;-p接用户登录密码
\p或 exit或 quit都表示退出
...\phpstudy_pro\Extensions\MySQL5.7.26\bin(数据库的路径)
show databases; #查看有哪些数据库
create database 数据库名称; #创建数据库
drop database 数据库名称; #删除数据库
use 数据库名; #进入数据库(可以在库中进行增删改查)
select database(); #查看当前在哪个库
3.2 MySQL创建表操作
show databases; #查看有哪些数据库
create database 数据库名称; #创建数据库
drop database 数据库名称; #删库
use 数据库名; #进入数据库(可以在库中进行增删改查)
select database(); #查看当前在哪个库
show tables; --查看当前库中的所有表
create table 表名 (字段1 数据类型,字段2 数据类型,字段3 数据类型); #创建一个数据表 表格中包含字段1、字段2、字段3等字段
create table hk(id int,name varchar(20),age int); #创建表的示例,创建名为hk的表,表中包含id、name、age等字段
desc 表名; ---查看表结构
drop table 表名; --删除表
3.3 常见的数据类型
数值类型
int:整数类型,常用于存储整数;
浮点型
float:单精度浮点类型,用于存储小数值;
double:双精度浮点数类型,用于存储较高精度的小数值;
字符串类型
char:定长字符串类型,适用于存储固定长度的字符串 ;
varchar:变长字符串类型,适用于存储可变长度的字符串;
text:较长的文本字符串类型,用于存储大段文本数据;
日期与时间类型
date:日期类型,存储日期,格式为YYYY-MM-DD;
time:时间类型,存储时间,格式为HH:MM:SS;
datetime:日期时间类型,存储日期和时间,格式为YYYY-MM-DD HH:MM:SS;
timestamp:类似于DATETIME,但是会自动记录数据插入或修改时间;
布尔类型
bool / boolean:布尔类型,用于存储True或False;
二进制类型
blob:用于存储二进制数据,例如图片,音频等;
binary /varbinary:用于存储二进制数据,可以指定长度。
若要了解MySQL分类的更多类型,请访问写者以下文章:
MySQL从入门到精通之手搓数据库第二步——存储引擎及数据类型
3.4 MySQL表中的数据操作
------查询语法
select 字段 from 表名;
select 字段 from 表名 where 查询条件;
select * from qq; # * 代表所有
select * from qq where name=某某某; #查询qq表中符合条件name=某某某的所有字段
------插入语法
insert into 表名(字段1,字段2,字段3) values(添加都字段1的内容,添加都字段2的内容,添加都字段3的内容)
insert 表名 set 字段1 = 添加的内容 字段2 = 添加的内容 字段3 = 添加的内容 //在第一列不能插入字母只能数字
insert into qq (name,password,zhanghao) values(1,'123','liuxiao'); #在qq表中插入了一个名字为1密码为123账号为liuxiao的数据
------修改语法
update 表名 set 字段名 = 更改后的数据 where 条件(例如password = aa)
update qq set name = '3' where password = 'aa'; #将qq表中的password是aa的列中的name中的数据更改成了3
------删除语法
delete from 表名 where 条件;
delete from qq where zhanghao = 'xiao'; #删除了在qq表中账号列为xiao的一行数据
3.5 MySQL表的修改
//删除表格所有数据,保留表的结构
truncate table 表名;
//删除字段
alter table 表名 drop 字段名;
//改表名
alter table 旧表名 rename to 新表名;
//改字段
alter table 表名 change 旧字段名 新字段名 int(11);
//改字段类型
alter table 表名 modify 字段名 varchar(20);
若要了解更多的创建及修改表的操作,请访问写者以下文章:
MySQL从入门到精通 超详细教程之手搓数据库第三步——数据表操作
4 MySQL查询操作
select 设定查询列 from 表名 //要查询的内容,选择哪些列
where 查询条件 //指定数据表
group by 字段 //查询时需要满足的条件
order by 字段 //如何对结果进行分组
having 第二查询条件 //如何对结果进行排序
limit 行数 //限定输出的查询结果
4.1 基础查询
-- 若要在同时包含:
-- 学号id,姓名name,性别sex,生日birthday的数据表student
-- 只查询姓名列和生日列
select name,birthday from student;
4.2 判断为空
is null //为空
is not null //不为空
语法:
select 字段名 from 表名 where 字段名 is null
select 字段名 from 表名 where 字段名 is not null
//mysql中null和python的none都是空的意思
创建环境表格
create table a1 (id int , name varchar(20) ); //新建一个表格拥有id和name两个字段
insert into a1(id) values(1),(2); //往a1表格里id列插入两个数据,name列没有数据
insert into a1(id,name) values(3,'mingzi'); //往a1表格中id列插入了一条数据,name也插入了一条
//当要往表格中插入所有字段数据的时候,表格后面可以不声明要新增数据的字段
select * from a1;
可以配置以下数据进行查询练习:
create table test1(id int,name varchar(20)); //创建一个test1表格
insert into test1(id) values(1); //在test1表格中id字段插入1的信息 name字段没有
insert into test1(name) values('lihua'); //在test1表格中name字段插入lihua信息,id段没有
insert into test1 values(3,'zhang'); //在test1表格中插入了id为3,name为zhang的信息
select *from test1;//查询数据表的结构内容
select * from test1 where name is null; //查询name字段为空的信息
select * from test1 where id is null; //查询id字段为空的信息
select * from test1 where id is not null; //查询id字段不为空的信息
select * from test1 where id is not null and name is not null; //id和name字段都不为空
4.3 逻辑判断
and or not
// and 两边的条件都得满足 如果今天放假并且买到票我就回家
// or 或者,或(满足一个条件) 如果今天吃大米或者吃火锅我今天就回家
// not 取反,非
语法:
select * from 表格名 where 条件表达式 and 条件表达式;
select * from 表格名 where 条件表达式 or 条件表达式;
select * from 表格名 where not 条件表达式;
可以配置以下数据进行查询练习:
create table x1(id int,name varchar(20),age int);//创建一个x1(学院表)有id,name,age,字段
insert into x1 values(1,'liu',18); //插入一天id=1 name=liu age=18的数据//插入所有数据 不用写字段
insert into x1 values(2,'zhangshan',19);
insert into x1 values(3,'lisi',20);
insert into x1 values(4,'zhang',45);
insert into x1 values(5,'wang',30);
insert into x1 values(6,'wei',16);
insert into x1 values(7,'youyou',8);
insert into x1 values(8,'anquan',60);
select * from test1;//创建完成 查看表格数据
//查询表中大于等于16到小于等于25的 and
select * from x1 where age>=16 and age<=20;
//查询表中年龄小于18或者大于25的 or
select * from x1 where age<18 or age>25;
//使用not查询小于20的
select * from x1 where not age>20;
4.3 排序
order by 排序列名 //根据....排序,默认排序
order by 排序列名 desc //根据....排序,倒叙
-- 语法:
select 字段名 from 表格名 order by 字段名; // 正序
select 字段名 from 表格名 order by 字段名 desc; //倒叙
select * from x1 order by age; //将x1数据表中按age(年龄)从小到大排序
select * from x1 order by age desc; //将x1数据表中按age(年龄)从大到小排序
4.4 限制
limit //关键字 限制从数据库检索数据行数
limit x //展示x行数据(从第一条开始,包括第一条)
limit x,y //展示x行(从0开始数)开始的y行数据
-- 语法:
select 字段名 from 表格名 limit x; //查询某个表格中的数据,只查询x行
select 字段名 from 表格名 limit x,y;
select * from x1 limit 1; //查询x1表格中的第一行数据
select * from x1 limit 3; //查询x1表格中的前3行数据
select * from x1 limit 0,5; //查询x1表格中的第0行到第5行(在数据库中第一行是0)
select * from x1 limit 4,2; //查询x1表格中的从第4行开始的后两行
4.5 去重
distinct //去重关键字,写在select之后,被查询内容前
-- 语法:
select distinct 字段名 from 表格名;
select distinct * from x1; //在x1表中查询数据,去除重复掉的
4.6 模糊查询
like //关键词
% //匹配任意多个
_ //匹配一个字符
-- 语法:
select 字段名 from 表格名 where 字段名 like 模糊查询条件(%/_);
select name from x1 where name like 'li%';
//模糊查询x1表中的name字段li开头后边任意个字符的数据
select name from x1 where name like 'li_';
//模糊查询x1表中的name字段li开头的后边一个字符的数据
4.7 范围查询
in //在....(范围)里面
between ..and... //在..与...之间
-- 语法:
//在x1表中查询age字段16-21字段的信息 in方法
select 字段名 from 表格名 where 字段 in (条件)
select * from x1 where age in (16,17,18,19,20);
//在x1表格中查询age字段16-21的信息 and方法
select 字段名 from 表格名 where 字段 between 条件1 and 条件2;
select * from x1 where age between 16 and 21;
4.8 聚合函数
count(列名) //统计所有行数
sum(列名) //求和
avg(列名) //平均值
max(列名) //最大值
min(列名) //最小值
-- 语法:
select 聚合函数(字段) from 表格;
select count(*) from x1; //用count函数统计一共有12行数
select sum(age) from x1; //用sum函数求和age字段和是298
select avg(age) from x1; //用avg函数求age字段平均值24.8333
select max(age) from x1; //用max函数显示age最大的值是50岁
select min(age) from x1; //用min函数显示age最小值是3岁
4.9 分组查询
group by 字段名 //根据 ....字段进行分组
having //用于在进行完分组后对查询数据进行再次筛选 ,类似与where
-- 语法:
select 字段,行统计 from 表格名 group by 字段名;
select 字段,行统计 from 表格名 group by 字段名 having 筛选条件;
create table x2(name varchar(20),course int,grade int); //创建一个学员成绩表
insert into x2 values(202501, 1, 99); //插入数据....
select course from x2 group by course; //在x2表中按course分组
select course,count(*) from x2 group by course; //在x2表中统计course分组中分别有多少条数据
select course,grade from x2; //查询course和grade数据
select course,grade from x2 group by course,grade; //进行简单的分组从小到大
select course,grade,count(*) from x2 group by course,grade; //简单的分组后每个数据显示多少条
select course,grade,count(*) from x2 group by course,grade having grade>80;
//对数据进行分组并且显示出来数据大于80的信息
4.10 表链接查询
表连接查询是在关系型数据库中用于联合多个表以检索相关的数据的一种查询方式
通过将共同字段进行匹配,将多个表中的数据进行关联,从中获得数据。
语法:
1.内连接(INNER JOIN) //INNER可以省略
内连接返回两个或多个表中的匹配行
语法:
select 列名 from 表1 INNER JOIN 表2 ON 表1.字段 = 表2.字段;
2.左连接(LEET JOIN)
左连接返回左表中的所有行,以及右表中与左表匹配的行
语法:
select 列名 from 表1 left join 表2 ON 表1.字段 = 表2.字段;
3.右连接(RIGHT JOIN)
右连接返回右表中的所有行,以及左表中与右表匹配的行
语法:
select 列名 from 表1 right join 表2 ON 表1.字段 = 表2.字段;
可以配置以下数据进行查询练习:
//创建两张表格:
//第一张:
//表格名称:a1 含有id,name列
//创建的语法:
create table a1(id int primary key,name varchar(10));
//插入四条数据
insert into a1(id,name) values(4105001,'张三');
insert into a1(id,name) values(4105002,'李四');
insert into a1(id,name) values(4105003,'小明');
insert into a1(id,name) values(4105004,'小张');
//创建完成可以查看数据的结果
select * from a1;
//创建第二张表格:
auto_increment //自己增长,可以不往这个字段里边插入数据,他会自己增长
c_id //字段做为外键,用来关联上一张表格中的主要字段(非空,且唯一的)
//表格名称a2 含a_id msg(爱好) c_id(外键链接列)
//创建表格的语法:
create table a2(a_id int primary key auto_increment, msg varchar(100),c_id int,foreign key(c_id) references a1(id));
insert into a2(msg,c_id) values('湖南汉族喜欢吃辣椒',4105001);
insert into a2(msg,c_id) values('广西壮族喜欢吃粉',4105002);
insert into a2(msg,c_id) values('河南汉族喜欢吃大米',4105003);
insert into a2(msg,c_id) values('内蒙古蒙古族喜欢吃羊肉',4105004);
//右连接操作插入:
insert into a2(msg,c_id) values('北京汉族喜欢喝豆汁',4105005);
实践
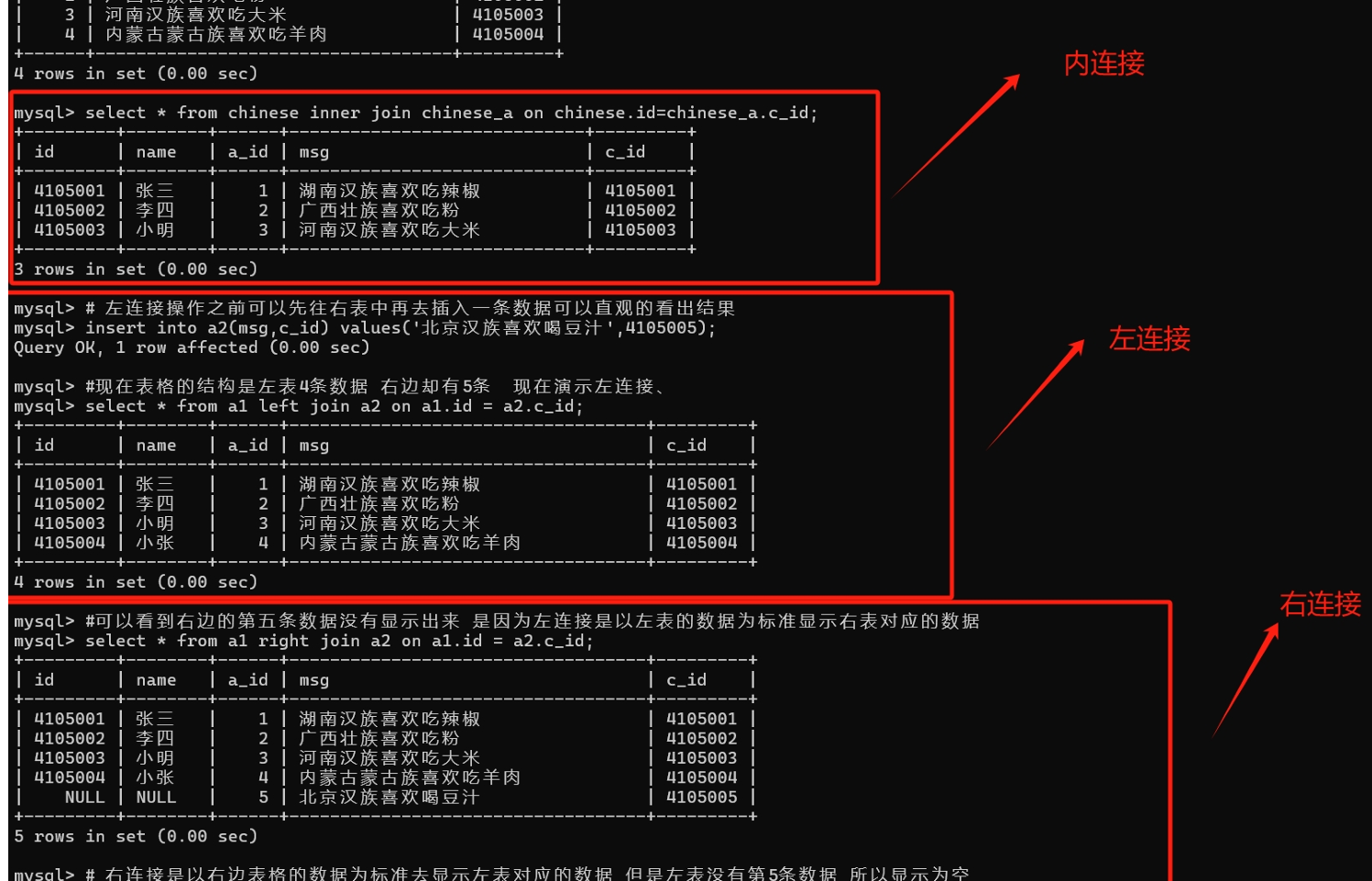
//内连接:
//把a1表中的id字段和a2中的c_id字段进行了内连接,显示出了两张表格全部的数据
select * from a1 inner join a2 on a1.id = ca2.c_id;//左连接:以左边的表格数据标准与右边表格去匹配显示连接后的数据
select 列名 from 表1 left join 表2 ON 表1.字段 = 表2.字段; //语法
select * from a1 left join a2 on a1.id = a2.c_id;//右连接:以右边的表格数据标准与左边表格去匹配显示连接后的数据
select 列名 from 表1 right join 表2 ON 表1.字段 = 表2.字段; //语法
select * from a1 right join a2 on a1.id = a2.c_id;
4.11 UNION合并查询
UNION是一种合并两个或多个select语句结果集的操作符。
--语法:
select 列1,列2,列3,.... from 表1 union select 列1,列2,列3,... from 表2
--实践:
//查询a1表中的name字段和a2表中的msg字段合并在一起查询
select name from a1 union select msg from a2;
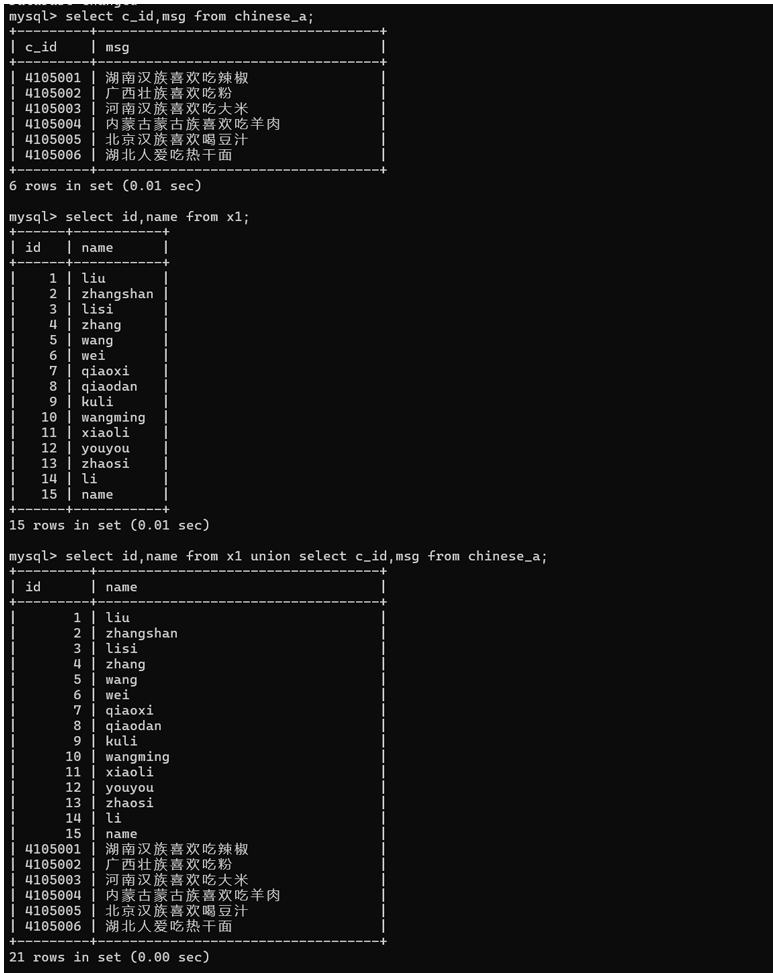
//也可以去查询两张毫无关联的表
select c_id,msg from chinese_a; //查询表列数据
select id,name from x1; //查询表列数据
//合并一起查询
select id,name from x1 union select c_id,msg from chinese_a;
本文内容源于好课优选教育网络安全培训后的笔记整理!