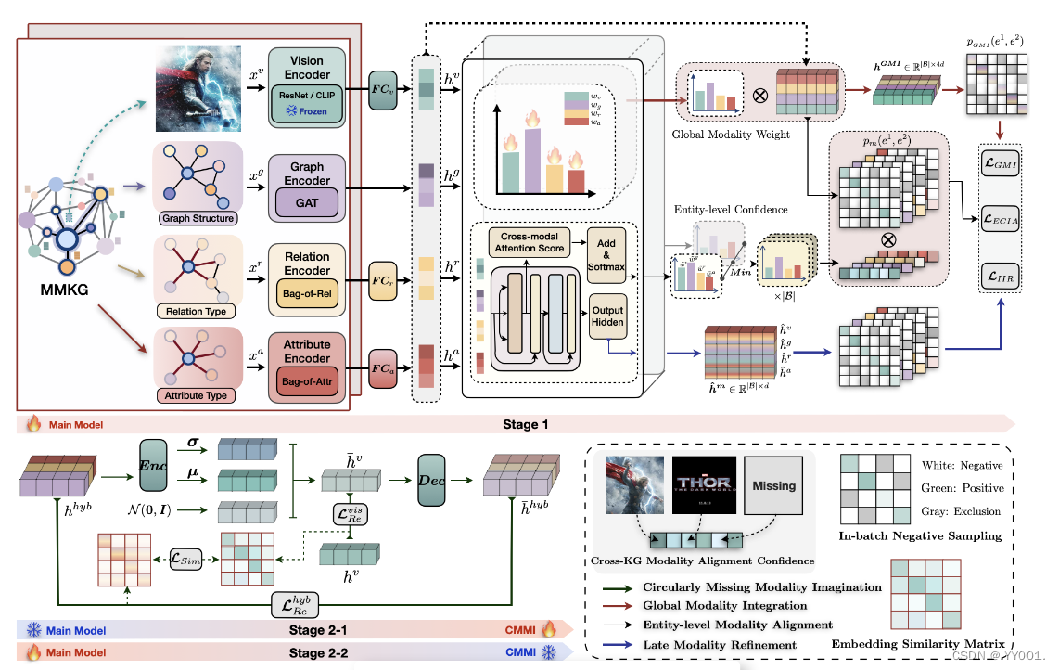
Preliminaries
MMKG为一个五元组G={E, R, A, V, T},其中E、R、A和V分别表示实体集、关系集、属性集和图像集。
T⊆E×R×E是关系三元组集。
给定两个MMKG G1 = {E1, R1, A1, V1, T1} 和 G2 = {E2, R2, A2, V2, T2},
MMEA旨在识别每个实体对(e1i,e2i),其中 e1i ∈ E1,e2i ∈ E2,且 e1i 和 e2i 对应于一个相同的现实世界实体 ei。
M = {g, r, a, v}表示为可用模态的集合
Multi-modal Knowledge Embedding
Graph Structure Embedding
![]() 表示实体 ei 的随机初始化图嵌入,其中 d 是预定的隐藏维度
表示实体 ei 的随机初始化图嵌入,其中 d 是预定的隐藏维度
![]() 对角权重矩阵,进行线性变换
对角权重矩阵,进行线性变换
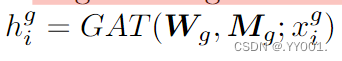 Mg表示图邻接矩阵。GAT是图注意力网络
Mg表示图邻接矩阵。GAT是图注意力网络
Relation, Attribute, and Visual Embedding
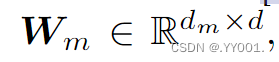
![]()

对于没有图像数据的实体,我们使用由其他可用图像的均值和标准差参数化的正态分布来生成随机图像特征[30,7,29,10]
Multi-scale Modality Hybrid
Entity-level Modality Alignment
在知识图谱对齐的过程中经常会使用一个手工对齐好的实体或关系谓词集合做为引子,我们把这个叫做种子对齐集合(seed alignments)
