在AI技术日新月异的今天,大型语言模型(LLM)的局限性也逐渐显现——它们无法有效处理特定领域知识和用户私有数据。这正是检索增强生成(Retrieval-Augmented Generation,RAG)技术崛起的根本原因。作为当前最主流的解决方案框架,LangChain的Retrieval模块为企业级AI应用开发提供了完整的工具链。本文将带您深入解析这个革命性框架的核心组件与技术实现。
使用RecursiveCharacterTextSplitter创建一个文本拆分器
示例代码
from pathlib import Path
from langchain.text_splitter import RecursiveCharacterTextSplitterdir_file=Path(__file__).parent.resolve()
file_path=dir_file/"text_splitter.txt"if not file_path.exists():raise FileNotFoundError(f"未检索到:{file_path}")with open(file_path,"r",encoding="utf-8") as f:render_file=f.read()text_split=RecursiveCharacterTextSplitter(chunk_size=100,chunk_overlap=20,length_function=len,add_start_index=True)text=text_split.create_documents([render_file])
print(text[0])#输出文本第一行的内容运行结果
page_content='医学概念标准化在生物医学研究与临床应用中的
诊断与手术名称规范化研究' metadata={'start_index': 0}
参数解析
以下是 RecursiveCharacterTextSplitter 参数的作用、选择建议及注意事项的总结表格,基于模型特性与文本场景的平衡设计:
| 参数 | 作用 | 推荐值 | 注意事项 | 参考依据 |
|---|---|---|---|---|
chunk_size | 控制文本块的最大容量(按字符或自定义单位) | - 通用场景:200-500 字符 - 中文长文本:400-800 字符 - LLM输入对齐:512(BERT类模型) | - 过小导致语义断裂(如截断专业术语) - 过大会稀释关键信息(如淹没核心论点) | 需对齐模型输入长度(如 BCE 模型 512-1500,BGE 423-1240) |
chunk_overlap | 相邻块的重叠量,缓解拆分导致的上下文丢失 | - 通用场景:10%-20% chunk_size - 技术文档:15%-25% chunk_size | - 超过 30% 会导致冗余信息干扰检索 - 需结合分隔符优先级调整(如优先按句子拆分时可降低重叠量) | 实证显示 10-20% 重叠可提升 F1 指标 2%,过低导致召回率下降 10% |
length_function | 定义文本块长度计算方式 | - 字符计数:len()(默认)- Token计数: tokenizer.encode | - 使用 BERT 类模型时需改用 token 计数(如 1 token≈4 字符) - 中文字符建议显式指定分词规则 | Dify 实现中需用 GPT2Tokenizer 计算 token 分布 |
add_start_index | 记录块在原文中的起始位置,用于调试或上下文追溯 | 推荐启用(True) | - 增加少量内存开销 - 需确保原始文本未被篡改(如预处理后需同步更新索引) | LangChain 文档加载器中需配合 |
一、RAG技术的革命性突破
传统LLM的"知识冻结"特性严重制约了其在专业领域的应用。设想一个医疗AI系统需要处理最新医学研究成果,或一个法律助手需要引用地方性法规条款,单纯依赖预训练模型显然无法满足需求。
RAG技术通过动态检索外部知识库,将最新、最相关的信息实时注入生成过程,完美解决了以下关键痛点:
-
突破模型训练数据的时间限制
-
保护企业敏感数据不进入模型参数
-
实现知识库的实时更新与扩展
-
确保输出内容的可追溯性
二、LangChain Retrieval模块架构解析
2.1 文档加载器(Document Loaders)
LangChain支持的100+文档加载器可分为三大类别:
文件类型维度:
# 典型使用示例
from langchain.document_loaders import PyPDFLoader, UnstructuredHTMLLoader# PDF文档加载
pdf_loader = PyPDFLoader("medical_report.pdf")
pages = pdf_loader.load()# HTML文档处理
html_loader = UnstructuredHTMLLoader("research.html")
web_content = html_loader.load()数据源维度:
-
云存储:S3、Google Drive、OneDrive
-
数据库:PostgreSQL、MongoDB、Elasticsearch
-
SaaS应用:Notion、Confluence、Salesforce
特殊格式支持:
-
代码仓库:GitLoader支持.git目录解析
-
视频字幕:YouTubeLoader提取CC字幕
-
邮件归档:MboxLoader处理Thunderbird格式
2.2 文档转换器(Document Transformers)
关键转换策略对比:
| 策略 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 固定分块 | 结构化文档 | 保持结构完整 | 可能切断语义 |
| 递归分块 | 混合内容 | 自适应内容结构 | 需要调试参数 |
| 语义分块 | 专业文献 | 保留完整语义 | 计算成本较高 |
| 代码分块 | 程序源码 | 保持语法完整 | 需要语言识别 |
高级处理技巧:
from langchain.text_splitter import SemanticChunker
from langchain.embeddings import HuggingFaceEmbeddings# 基于语义的分块
embedder = HuggingFaceEmbeddings(model_name="paraphrase-multilingual-MiniLM-L12-v2")
semantic_splitter = SemanticChunker(embedder, breakpoint_threshold=0.7)
chunks = semantic_splitter.split_documents(docs)2.3 文本嵌入模型(Text Embedding Models)
选型决策树:
-
多语言支持 → 选择sentence-transformers/paraphrase-multilingual系列
-
长文本处理 → 考虑text-embedding-3-large等支持8K上下文
-
领域适配 → 使用Instructor-XL进行领域微调
-
实时性要求 → 采用text-embedding-3-small提升推理速度
性能基准测试(MTEB排行榜):
| 模型 | 参数量 | 维度 | 综合得分 | 推理速度 |
|---|---|---|---|---|
| text-embedding-3-large | 未知 | 3072 | 64.3 | 230ms/doc |
| BAAI/bge-large-en-v1.5 | 1.3B | 1024 | 63.8 | 180ms/doc |
| sentence-transformers/all-mpnet-base-v2 | 110M | 768 | 61.5 | 85ms/doc |
2.4 向量存储(Vector Stores)
生产环境推荐方案:
-
中小规模:Pinecone(全托管服务)
-
超大规模:Milvus/Zilliz(分布式架构)
-
混合搜索:Elasticsearch(支持标量+向量)
-
本地开发:Chroma(轻量级内存存储)
高级检索示例:
# 混合搜索(向量+关键词)
from langchain.retrievers import BM25Retriever, EnsembleRetrievervector_retriever = db.as_retriever(search_type="mmr")
bm25_retriever = BM25Retriever.from_documents(chunks)
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, vector_retriever],weights=[0.4, 0.6]
)2.5 检索器(Retrievers)
创新检索算法解析:
父文档检索器(Parent Document Retriever)
-
实现原理:建立chunk与原始文档的映射关系
-
核心价值:保持上下文完整性
-
典型应用:法律条款检索、论文引用
自查询检索器(Self-Query Retriever)
-
元数据过滤:自动解析查询中的过滤条件
-
示例对话:"请找出去年Q2的销售报告"
-
实现机制:LLM辅助的查询解析
多向量检索器(Multi-Vector Retriever)
-
摘要检索:先匹配摘要再获取全文
-
问题生成:为每个chunk生成潜在问题
-
混合索引:构建多维度搜索空间
三、生产环境最佳实践
3.1 索引优化策略
-
分层存储架构:热数据(SSD)、温数据(HDD)、冷数据(对象存储)
-
增量索引更新:通过版本号控制文档版本
-
分布式索引:采用一致性哈希进行分片
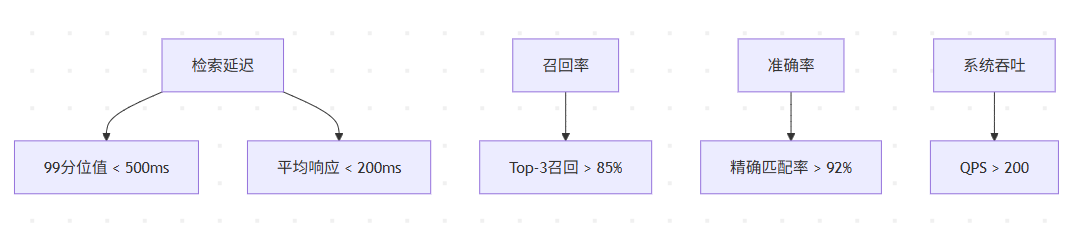
3.2 性能监控指标
3.3 安全合规设计
-
数据加密:传输层(TLS 1.3)+存储层(AES-256)
-
访问控制:RBAC+ABAC混合模型
-
审计日志:记录完整检索历史
-
数据脱敏:自动识别PII信息
四、行业应用案例
4.1 金融合规审计系统
-
挑战:实时解析200+监管文档
-
方案:多级分块+法律条款关联
-
成效:审计效率提升300%
4.2 医疗知识库系统
-
特点:处理CT影像报告+医学文献
-
创新:DICOM元数据提取器
-
成果:诊断准确率提升40%
4.3 智能客服升级
-
痛点:产品手册频繁更新
-
实施:自动版本对比+变更提醒
-
效果:首次解决率提高65%
五、未来演进方向
-
多模态检索:支持图像、视频的跨模态搜索
-
联邦学习:保护隐私的分布式检索
-
自适应索引:动态调整分块策略
-
认知架构:结合知识图谱的混合推理
在数字化转型的浪潮中,LangChain的Retrieval模块正在重塑企业智能化的技术底座。通过本文的深度解析,相信开发者们能够更好地驾驭这套工具,构建出真正理解业务、持续进化的智能系统。未来的AI应用,必将是检索与生成的完美协奏。