一、背景
在大语言模型(LLM)应用场景中,GPT-4等模型的响应生成往往需要数秒至数十秒的等待时间。传统同步请求会导致用户面对空白页面等待,体验较差。本文通过Spring WebFlux响应式编程与SSE服务器推送技术,实现类似打印机的逐字流式输出效果,同时结合LangChain4j框架进行AI能力集成,有效提升用户体验。
二、技术选型
- Spring WebFlux:基于 Reactor 的异步非阻塞 Web 框架
- SSE(Server-Sent Events):轻量级服务器推送技术
- LLM框架:LangChain4j
- 大模型 API:以 OpenAI 的 GPT-4 (实际大模型是deepseek)
- 开发工具:IntelliJ IDEA + JDK 17
三、Spring WebFlux介绍
Spring Webflux 教程 - spring 中文网
这里就不多介绍了,网上教程很多
四、整体方案
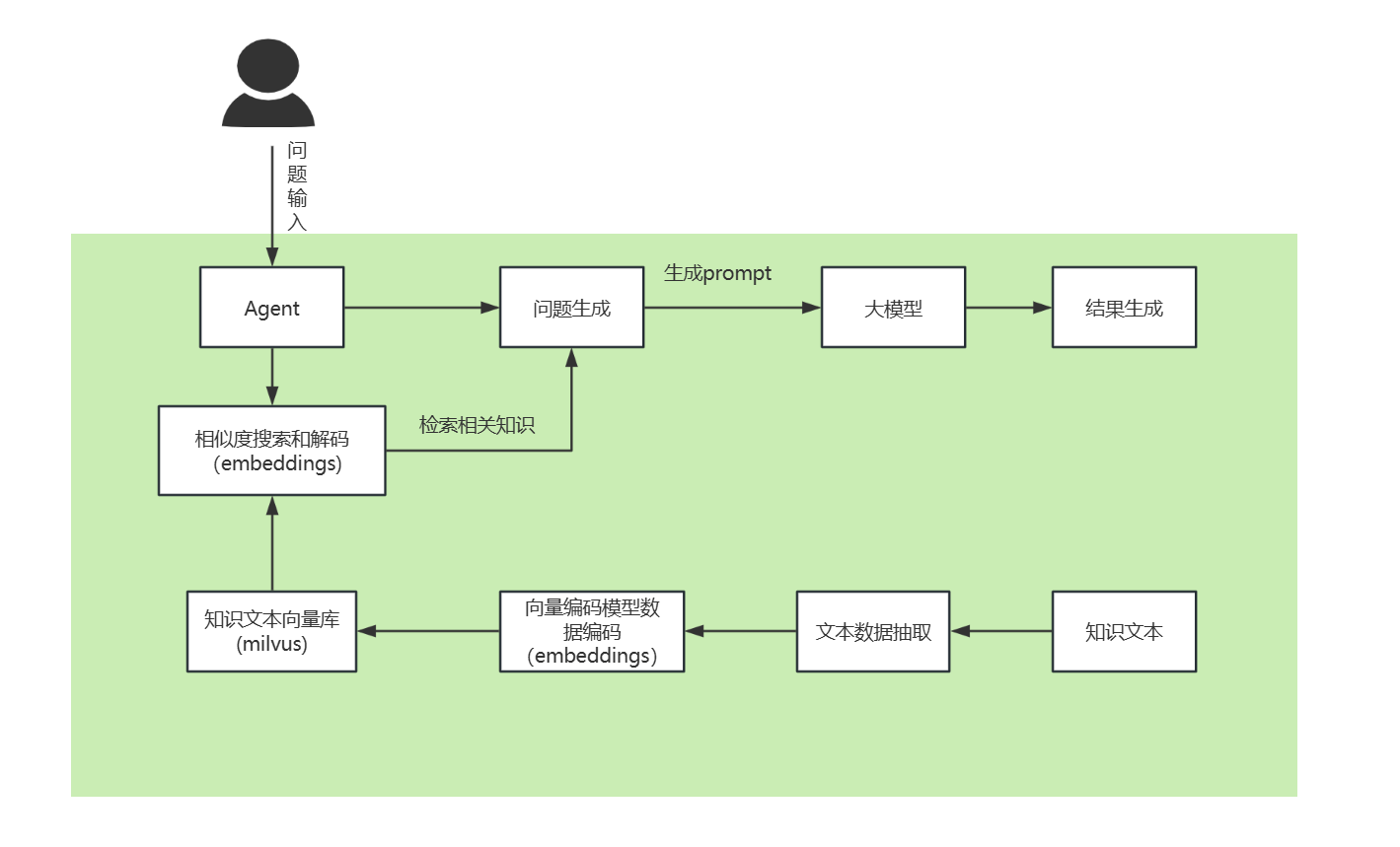
五、实现步骤
1、pom依赖
<dependency><groupId>io.milvus</groupId><artifactId>milvus-sdk-java</artifactId><version>2.5.1</version></dependency><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-milvus</artifactId><version>0.36.2</version></dependency><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-embeddings-all-minilm-l6-v2</artifactId><version>0.36.2</version></dependency><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-open-ai</artifactId><version>0.36.2</version></dependency><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-open-ai-spring-boot-starter</artifactId><version>0.36.2</version></dependency><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-reactor</artifactId><version>0.36.2</version></dependency>2、controller层
content-type= text/event-stream
@ApiOperation(value = "流式对话")
@PostMapping(value = "", produces = TEXT_EVENT_STREAM_VALUE)
public Flux<String> chat(@RequestBody @Validated ChatReq chatReq) {log.info("--流式对话 chat request: {}--", chatReq);return chatService.chat(chatReq);
}
@ApiModel(value = "对话请求")
public class ChatReq {@ApiModelProperty(value = "对话id")private Long chatId;@ApiModelProperty(value = "对话类型")private Integer type;@ApiModelProperty(value = "提问")private String question;@ApiModelProperty(value = "外部id")private List<Long> externalIds;@ApiModelProperty(value = "向量检索阈值", example = "0.5")@Min(value = 0)@Max(value = 1)private Double retrievalThreshold;@ApiModelProperty(value = "向量匹配结果数", example = "5")@Min(value = 1)private Integer topK;....}3、service层
1)主体请求
public Flux<String> chat(ChatReq chatReq) {// Create a Sink that will emit items to FluxSinks.Many<ApiResponse<String>> sink = Sinks.many().multicast().onBackpressureBuffer();// 用于控制数据生成逻辑的标志AtomicBoolean isCancelled = new AtomicBoolean(false);ChatStreamingResponseHandler chatStreamingResponseHandler = new ChatStreamingResponseHandler();// 判断新旧对话if (isNewChat(chatReq.getChatId())) { // 新对话,涉及业务略过chatReq.setHasHistory(false);chatModelHandle(chatReq);} else { // 旧对话// 根据chatId查询对话类型和对话历史chatReq.setHasHistory(true);chatModelHandle(chatReq);}return sink.asFlux().doOnCancel(() -> {log.info("停止流处理");isCancelled.set(true); // 设置取消标志sink.tryEmitComplete(); // 停止流});}2)构建请求参数
有会话历史,获取会话历史(请求回答和回答)
封装成ChatMessages(question存UserMessage、answer存AiMessage)
private void chatModelHandle(ChatReq chatReq){List<ChatMessage> history = new ArrayList<>();if (chatReq.getHasHistory()) {// 组装对话历史,获取question和answer分别存UserMessage和AiMessagehistory = getHistory(chatReq.getChatId());}Integer chatType = chatReq.getType();//依赖文本List<Long> externalIds = chatReq.getExternalIds();// 判断对话类型if (ChatType.NORMAL.getCode().equals(chatType)) { // 普通对话if (chatReq.getHasHistory()) {history.add(UserMessage.from(chatReq.getQuestion()));}chatStreamingResponseHandler = new ChatStreamingResponseHandler(sink, chatReq, isCancelled);ChatModelClient.getStreamingChatLanguageModel(chatReq.getTemperature()).generate(chatReq.getHasHistory() ? history : chatReq.getQuestion(), chatStreamingResponseHandler);} else if (ChatType.DOCUMENT_DB.getCode().equals(chatType)) { // 文本对话Prompt prompt = geneRagPrompt(chatReq);if (chatReq.getHasHistory()) {history.add(UserMessage.from(prompt.text()));}chatStreamingResponseHandler = new ChatStreamingResponseHandler(sink, chatReq, isCancelled);ChatModelClient.getStreamingChatLanguageModel(chatReq.getTemperature()).generate(chatReq.getHasHistory() ? history : prompt.text(), chatStreamingResponseHandler);} else {throw new BizException("功能待开发");}}3)如果有参考文本,获取参考文本
在向量库中,根据参考文本id和向量检索阈值,查看参考文本topN
private List<PPid> search(ChatReq chatReq, MilvusClientV2 client, MilvusConfig config, EmbeddingModel model) {//使用文本id进行查询TextSegment segment = TextSegment.from(chatReq.getQuestion());Embedding queryEmbedding = model.embed(segment).content();SearchResp searchResp = client.search(SearchReq.builder().collectionName(config.getCollectionName()).data(Collections.singletonList(new FloatVec(queryEmbedding.vector()))).filter(String.format("ARRAY_CONTAINS(documentIdList, %s)", chatReq.getExternalIds())).topK(chatReq.getTopK() == null ? config.getTopK() : chatReq.getTopK()).outputFields(Arrays.asList("pid", "documentId")).build());// 过滤掉分数低于阈值的结果List<SearchResp.SearchResult> searchResults = searchResp.getSearchResults().get(0);Double minScore = chatReq.getRetrievalThreshold() == null ? config.getMinScore() : chatReq.getRetrievalThreshold();return searchResults.stream().filter(item -> item.getScore() >= minScore).sorted((item1, item2) -> Double.compare(item2.getScore(), item1.getScore())).map(item -> new PPid((Long) item.getEntity().get("documentId"),(Long) item.getEntity().get("pid"))).toList();}获取参考文本id后,获取文本,再封装请求模版
private Prompt genePrompt(String context) {...
}4)连接大模型客户端
public static StreamingChatLanguageModel getStreamingChatLanguageModel() {ChatModelConfig config = ChatConfig.getInstance().getChatModelConfig();return OpenAiStreamingChatModel.builder().baseUrl(config.getBaseUrl()).modelName(config.getModelName()).apiKey(config.getApiKey()).maxTokens(config.getMaxTokens()).timeout(Duration.ofSeconds(config.getTimeout())).build();
}5)大模型输出处理
@Slf4j
@Data
@NoArgsConstructor
public class ChatStreamingResponseHandler implements StreamingResponseHandler<AiMessage> {private Sinks.Many<ApiResponse<String>> sink;private ChatReq chatReq;private AtomicBoolean isCancelled;public ChatStreamingResponseHandler(Sinks.Many<ApiResponse<String>> sink, ChatReq chatReq, AtomicBoolean isCancelled) {this.sink = sink;this.chatReq = chatReq;this.isCancelled = isCancelled;}@Overridepublic void onNext(String answer) {//取消不输出if (isCancelled.get()) {return;}sink.tryEmitNext(BaseController.success(answer));}@Overridepublic void onComplete(Response<AiMessage> response) {if (!isCancelled.get()) {sink.tryEmitNext("结束标识");sink.tryEmitComplete();}// 业务处理}@Overridepublic void onError(Throwable error) {if (!isCancelled.get()) {sink.tryEmitError(error);}// 业务处理}}
六、效果呈现

七、结尾
上面简要列一下实现步骤,可以留言深入讨论。
有许多体验还需要完善,以参考豆包举例
1、实现手动停止响应
2、刷新或者页面关闭自动停止流式输出,重连后流式输出继续
3、将多个Token打包发送,减少SSE帧数量