背景
多模态大模型(Multimodal Large Language Models, MLLM)的构建过程中,模型结构、模型预测、指令微调以及偏好对齐训练是其中重要的组成部分。本次任务中,将提供一个不完整的多模态大模型结构及微调代码,请根据要求,补全过程中的关键步骤,并在提供的数据上实现简单的微调与推理。
任务1. 多模态大模型的结构与推理
1. Transformer 结构中的多头注意力(Multihead Self-Attention)
Transformer[1] 模型是现代自然语言处理的核心,也是目前主流大模型的结构基础,其核心是自注意力机制(self-attention mechanism)。
多头注意力(Multihead Self-Attention)是Transformer结构中的关键组件,通过引入多个注意力头,它能够捕捉序列中不同位置的特征和依赖关系。每个注意力头在进行线性变换后,独立地计算注意力分数,然后将结果拼接并再次投影。这样可以增强模型的表示能力,允许不同的头关注输入序列的不同部分。
在实现多头注意力时,forward函数的核心任务是计算输入序列的自注意力输出。具体步骤包括:将输入映射至多个子空间(对应多个头),计算注意力权重,通过这些权重加权求和得到注意力输出,最后将所有头的输出拼接并通过线性变换得到最终输出。
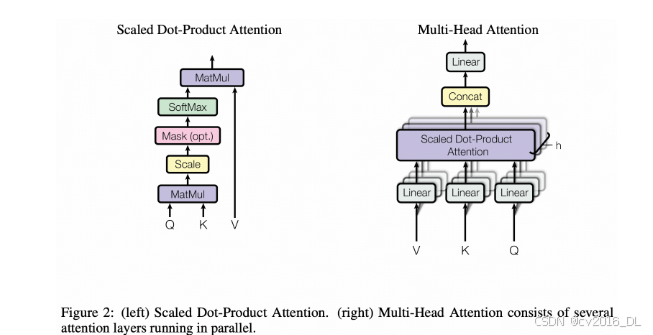
参考论文: [1] Attention is All You Need
任务描述: 请根据论文中的 attention 计算公式,完善mllm/model/llm/llm_architecture.py,补充 LLMAttention 中的 forward 计算。
class LLMAttention(nn.Module):"""Multi-headed attention from 'Attention Is All You Need' paper. Modified to use sliding window attention: Longformerand "Generating Long Sequences with Sparse Transformers"."""def __init__(self, config: LLMConfig, layer_idx: Optional[int] = None):super().__init__()self.config = configself.layer_idx = layer_idxif layer_idx is None:logger.warning_once(f"Instantiating {self.__class__.__name__} without passing `layer_idx` is not recommended and will ""to errors during the forward call, if caching is used. Please make sure to provide a `layer_idx` ""when creating this class.")self.hidden_size = config.hidden_sizeself.num_heads = config.num_attention_headsself.head_dim = self.hidden_size // self.num_headsself.num_key_value_heads = config.num_key_value_headsself.num_key_value_groups = self.num_heads // self.num_key_value_headsself.max_position_embeddings = config.max_position_embeddingsself.rope_theta = config.rope_thetaself.is_causal = Trueself.attention_dropout = config.attention_dropoutif (self.head_dim * self.num_heads) != self.hidden_size:raise ValueError(f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"f" and `num_heads`: {self.num_heads}).")self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=True)self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True)self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True)self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)self.rotary_emb = LLMRotaryEmbedding(self.head_dim,max_position_embeddings=self.max_position_embeddings,base=self.rope_theta,)def forward(self,hidden_states: torch.Tensor,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_value: Optional[Cache] = None,output_attentions: bool = False,use_cache: bool = False,**kwargs,) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:if "padding_mask" in kwargs:warnings.warn("Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`")bsz, q_len, _ = hidden_states.size()### ===> TODO: 计算多头注意力中的 Query,Key,Value## 1. 将原始 Q、K、V 进行映射## 2. 将映射后的 Q、K、V 整理为多头注意力的形状query_states = Nonekey_states = Nonevalue_states = None### <===kv_seq_len = key_states.shape[-2]if past_key_value is not None:if self.layer_idx is None:raise ValueError(f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} ""for auto-regressive decoding with k/v caching, please make sure to initialize the attention class ""with a layer index.")kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)if past_key_value is not None:cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE modelskey_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)# repeat k/v heads if n_kv_heads < n_headskey_states = repeat_kv(key_states, self.num_key_value_groups)value_states = repeat_kv(value_states, self.num_key_value_groups)### ==> TODO: 计算注意力机制中的加权权重,应用注意力掩码attn_weights = None### <===attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)### ===> TODO: 计算注意力输出取值## 1. 对 Value 值进行加权## 2. 合并多头注意力取值## 3. 将输出进行映射attn_output = None### <===if not output_attentions:attn_weights = Nonereturn attn_output, attn_weights, past_key_value参考代码:
https://github.com/wdndev/tiny-llm-zh/blob/667fd773ee786b19ad105e35885406b7fd3dae19/train/modeling_tinyllm.py#L4
参考:chttps://zhuanlan.zhihu.com/p/704324186
class TinyllmSdpaAttention(TinyllmAttention):""" 使用 torch.nn.functional.scaled_dot_product_attention 实现的注意力模块。该模块继承自 `TinyllmAttention`,因为模块的权重保持不变。唯一的变化在于前向传播过程中适应 SDPA API。Scaled Dot Product Attention (SDPA) """def forward(self,hidden_states: torch.Tensor,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_value: Optional[Cache] = None,output_attentions: bool = False,use_cache: bool = False,) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:# 当设置output_attentions=True时,由于torch.nn.functional.scaled_dot_product_attention不支持直接返回注意力权重# 因此暂时降级回用父类的手动实现方式,并发出警告提示用户未来版本的更改要求if output_attentions:# TODO: Improve this warning with e.g. `model.config.attn_implementation = "manual"` once this is implemented.logger.warning_once("Model is using SdpaAttention, but `torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to the manual attention implementation, "'but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.')return super().forward(hidden_states=hidden_states,attention_mask=attention_mask,position_ids=position_ids,past_key_value=past_key_value,output_attentions=output_attentions,use_cache=use_cache,)# 获取输入维度信息bsz, q_len, _ = hidden_states.size()# 对输入进行线性映射得到query、key、value向量query_states = self.q_proj(hidden_states)key_states = self.k_proj(hidden_states)value_states = self.v_proj(hidden_states)# 将映射后的向量调整为多头注意力所需格式query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)# 计算有效的 kv 序列长度(考虑缓存的情况)kv_seq_len = key_states.shape[-2]if past_key_value is not None:kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)# 应用旋转位置嵌入(RoPE)cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)# 如果有缓存,更新key和value状态if past_key_value is not None:cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE modelskey_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)key_states = repeat_kv(key_states, self.num_key_value_groups)value_states = repeat_kv(value_states, self.num_key_value_groups)if attention_mask is not None:if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):raise ValueError(f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}")# SDPA with memory-efficient backend is currently (torch==2.1.2) bugged with non-contiguous inputs with custom attn_mask,# Reference: https://github.com/pytorch/pytorch/issues/112577.if query_states.device.type == "cuda" and attention_mask is not None:query_states = query_states.contiguous()key_states = key_states.contiguous()value_states = value_states.contiguous()# 使用scaled_dot_product_attention进行计算attn_output = torch.nn.functional.scaled_dot_product_attention(query_states,key_states,value_states,attn_mask=attention_mask,dropout_p=self.attention_dropout if self.training else 0.0,# The q_len > 1 is necessary to match with AttentionMaskConverter.to_causal_4d that does not create a causal mask in case q_len == 1.is_causal=self.is_causal and attention_mask is None and q_len > 1,)# 还原注意力输出的形状attn_output = attn_output.transpose(1, 2).contiguous()attn_output = attn_output.view(bsz, q_len, self.hidden_size)# 将注意力输出通过最终的线性层(o_proj层)attn_output = self.o_proj(attn_output)return attn_output, None, past_key_value
2. 多模态特征融合
多模态大模型旨在处理和融合来自不同模态的信号,如文本和图像,以支持更加丰富的应用。多模态特征融合是该过程中至关重要的部分,它通过将来自不同模态的信号表征为嵌入向量(embedding),并进行拼接,从而统一处理来自不同模态的信号。
在实现多模态特征融合的过程中,常见的方式为,首先分别获取图像和文本的嵌入表示。然后,利用一个桥阶层(如 多层全连接层[1]、交叉注意力层[2] 等)将图片表示映射至文本表示空间。最后,将图片映射后的表示与文本表示进行拼接,形成最终的多模态输入信号,传递给语言大模型进行后续处理。
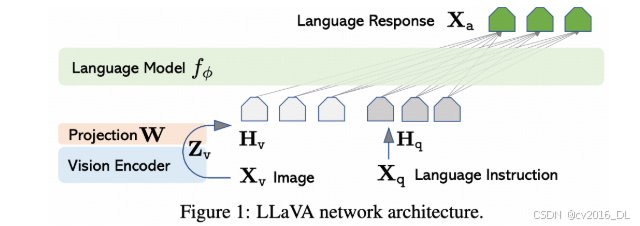
参考论文: [1] Visual Instruction Tuning
[2] Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
任务描述: 完善mllm/model/modeling_mllm.py,补充 get_vllm_embedding() 中,拼接视觉嵌入与文本嵌入的计算流程。
def get_vllm_embedding(self, data):vision_hidden_states = self.get_vision_hidden_states(data)if hasattr(self.llm.config, 'scale_emb'):vllm_embedding = self.llm.model.embed_tokens(data['input_ids']) * self.llm.config.scale_embelse:vllm_embedding = self.llm.model.embed_tokens(data['input_ids'])vision_hidden_states = [i.type(vllm_embedding.dtype) if isinstance(i, torch.Tensor) else i for i in vision_hidden_states]bs = len(data['input_ids'])### ===> 合并 vision_hidden_states 与 vllm_embedding,# 其中,vision_hidden_states 为视觉编码,当前 vllm_embedding 仅为语言模型编码for i in range(bs):pass### <===return vllm_embedding, vision_hidden_states参考代码1:
def get_vllm_embedding(self, data):if "vision_hidden_states" not in data:dtype = self.llm.qwen2.embed_tokens.weight.dtype# device = self.llm.qwen2.embed_tokens.weight.placetgt_sizes = data["tgt_sizes"]pixel_values_list = data["pixel_values"]vision_hidden_states = []all_pixel_values = []img_cnt = []for pixel_values in pixel_values_list:img_cnt.append(len(pixel_values))all_pixel_values.extend([i.flatten(stop_axis=1).transpose([1, 0]) for i in pixel_values])# exist imageif all_pixel_values:tgt_sizes = [tgt_size for tgt_size in tgt_sizes if isinstance(tgt_size, paddle.Tensor)]tgt_sizes = paddle.stack(tgt_sizes).squeeze(0).astype("int32")if self.config.batch_vision_input:max_patches = paddle.max(tgt_sizes[:, 0] * tgt_sizes[:, 1])all_pixel_values = pad_sequence(all_pixel_values, padding_value=0.0)B, L, _ = all_pixel_values.shapeall_pixel_values = all_pixel_values.transpose([0, 2, 1]).reshape([B, 3, -1, L])patch_attn_mask = paddle.zeros([B, 1, max_patches], dtype="bool")for i in range(B):patch_attn_mask[i, 0, : tgt_sizes[i][0] * tgt_sizes[i][1]] = Truevision_embedding = self.vpm(paddle.to_tensor(all_pixel_values).cast(dtype),patch_attention_mask=patch_attn_mask,tgt_sizes=tgt_sizes,).last_hidden_statevision_embedding = self.resampler(vision_embedding, tgt_sizes)else:# get vision_embedding foreachvision_embedding = []for single_tgt_size, single_pixel_values in zip(tgt_sizes, all_pixel_values):single_pixel_values = single_pixel_values.unsqueeze(0)B, L, _ = single_pixel_values.shapesingle_pixel_values = single_pixel_values.transpose([0, 2, 1]).reshape([B, 3, -1, L])single_vision_embedding = self.vpm(single_pixel_values.astype(dtype), tgt_sizes=single_tgt_size.unsqueeze(0)).last_hidden_statesingle_vision_embedding = self.resampler(single_vision_embedding, single_tgt_size.unsqueeze(0))vision_embedding.append(single_vision_embedding)vision_embedding = paddle.concat(vision_embedding, axis=0)start = 0for pixel_values in pixel_values_list:img_cnt = len(pixel_values)if img_cnt > 0:vision_hidden_states.append(vision_embedding[start : start + img_cnt])start += img_cntelse:vision_hidden_states.append([])else: # no imageif self.training:dummy_image = paddle.zeros([1, 3, 224, 224], dtype=dtype)tgt_sizes = paddle.to_tensor([[[224 // self.config.patch_size, math.ceil(224 / self.config.patch_size)]]], dtype="int32")dummy_feature = self.resampler(self.vpm(dummy_image).last_hidden_state, tgt_sizes)else:dummy_feature = []for _ in range(len(pixel_values_list)):vision_hidden_states.append(dummy_feature)else:vision_hidden_states = data["vision_hidden_states"]if hasattr(self.llm.config, "scale_emb"):vllm_embedding = self.llm.qwen2.embed_tokens(data["input_ids"]) * self.llm.config.scale_embelse:vllm_embedding = self.llm.qwen2.embed_tokens(data["input_ids"])vision_hidden_states = [i.astype(vllm_embedding.dtype) if isinstance(i, paddle.Tensor) else i for i in vision_hidden_states]bs = len(data["input_ids"])for i in range(bs):cur_vs_hs = vision_hidden_states[i]if len(cur_vs_hs) > 0:cur_vllm_emb = vllm_embedding[i]cur_image_bound = data["image_bound"][i]if len(cur_image_bound) > 0:image_indices = paddle.stack(x=[paddle.arange(start=r[0], end=r[1], dtype="int64") for r in cur_image_bound]).to(vllm_embedding.place)cur_vllm_emb.put_along_axis_(axis=0,indices=image_indices.reshape([-1, 1]).tile(repeat_times=[1, tuple(cur_vllm_emb.shape)[-1]]),values=cur_vs_hs.reshape([-1, tuple(cur_vs_hs.shape)[-1]]),)elif self.training:cur_vllm_emb += cur_vs_hs[0].mean() * 0return vllm_embedding, vision_hidden_states
参考代码2:
https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5/blob/main/modeling_minicpmv.py
def get_vllm_embedding(self, data):if 'vision_hidden_states' not in data:dtype = self.llm.model.embed_tokens.weight.dtypedevice = self.llm.model.embed_tokens.weight.devicetgt_sizes = data['tgt_sizes']pixel_values_list = data['pixel_values']vision_hidden_states = []all_pixel_values = []img_cnt = []for pixel_values in pixel_values_list:img_cnt.append(len(pixel_values))all_pixel_values.extend([i.flatten(end_dim=1).permute(1, 0) for i in pixel_values])# exist imageif all_pixel_values:tgt_sizes = torch.vstack(tgt_sizes).type(torch.int32)if self.config.batch_vision_input:max_patches = torch.max(tgt_sizes[:, 0] * tgt_sizes[:, 1])all_pixel_values = torch.nn.utils.rnn.pad_sequence(all_pixel_values, batch_first=True,padding_value=0.0)B, L, _ = all_pixel_values.shapeall_pixel_values = all_pixel_values.permute(0, 2, 1).reshape(B, 3, -1, L)patch_attn_mask = torch.zeros((B, 1, max_patches), dtype=torch.bool, device=device)for i in range(B):patch_attn_mask[i, :tgt_sizes[i][0] * tgt_sizes[i][1]] = Truevision_embedding = self.vpm(all_pixel_values.type(dtype), patch_attention_mask=patch_attn_mask).last_hidden_statevision_embedding = self.resampler(vision_embedding, tgt_sizes)else:# get vision_embedding foreachvision_embedding = []for single_tgt_size, single_pixel_values in zip(tgt_sizes, all_pixel_values):single_pixel_values = single_pixel_values.unsqueeze(0)B, L, _ = single_pixel_values.shapesingle_pixel_values = single_pixel_values.permute(0, 2, 1).reshape(B, 3, -1, L)single_vision_embedding = self.vpm(single_pixel_values.type(dtype)).last_hidden_statesingle_vision_embedding = self.resampler(single_vision_embedding, single_tgt_size.unsqueeze(0))vision_embedding.append(single_vision_embedding)vision_embedding = torch.vstack(vision_embedding)start = 0for pixel_values in pixel_values_list:img_cnt = len(pixel_values)if img_cnt > 0:vision_hidden_states.append(vision_embedding[start: start + img_cnt])start += img_cntelse:vision_hidden_states.append([])else: # no imageif self.training:dummy_image = torch.zeros((1, 3, 224, 224),device=device, dtype=dtype)tgt_sizes = torch.Tensor([[(224 // self.config.patch_size), math.ceil(224 / self.config.patch_size)]]).type(torch.int32)dummy_feature = self.resampler(self.vpm(dummy_image).last_hidden_state, tgt_sizes)else:dummy_feature = []for _ in range(len(pixel_values_list)):vision_hidden_states.append(dummy_feature)else:vision_hidden_states = data['vision_hidden_states']if hasattr(self.llm.config, 'scale_emb'):vllm_embedding = self.llm.model.embed_tokens(data['input_ids']) * self.llm.config.scale_embelse:vllm_embedding = self.llm.model.embed_tokens(data['input_ids'])vision_hidden_states = [i.type(vllm_embedding.dtype) if isinstance(i, torch.Tensor) else i for i in vision_hidden_states]bs = len(data['input_ids'])for i in range(bs):cur_vs_hs = vision_hidden_states[i]if len(cur_vs_hs) > 0:cur_vllm_emb = vllm_embedding[i]cur_image_bound = data['image_bound'][i]if len(cur_image_bound) > 0:image_indices = torch.stack([torch.arange(r[0], r[1], dtype=torch.long) for r in cur_image_bound]).to(vllm_embedding.device)cur_vllm_emb.scatter_(0, image_indices.view(-1, 1).repeat(1, cur_vllm_emb.shape[-1]),cur_vs_hs.view(-1, cur_vs_hs.shape[-1]))elif self.training:cur_vllm_emb += cur_vs_hs[0].mean() * 0return vllm_embedding, vision_hidden_states3. 多模态大模型的推理预测
在多模态大模型的推理过程中,模型需要接收和处理文本与图像输入,并采用自回归解码(autoregressive decoding)的形式输出回复。这涉及多个关键步骤,包括输入预处理、模型推理和输出后处理。
输入预处理的过程包括:将对话输入转换为与模型训练阶段一致的模板格式,以确保输入的有效性,同时,将转换后的文本对应到相应的单词ID上;对于图像输入,可能需要对图片进行分块(slice)、调整大小(resize)等操作,以适合视觉编码器的输入要求。在实现中,transformers 库提供了 tokenizer 类,可以便捷地实现输入文本的形式转换,同时利用自定义的 processor 类将图像和文本处理为模型计算时所需的输入格式。
在推理阶段,模型将会根据已有输入和已经产生的输出文本依次循环生成下一个token,并在达到生成结束条件(stopping criteria)时停止输出,通常的结束条件是生成了特定停止符(EOS token),或达到最大输出长度限制。Huggingface transformers 库中集成了这一生成过程,可以使用模型的 generate() 方法便捷地控制模型的生成行为。原始的模型输出是一串与文本对应的ID序列,为了得到最终的文本,还需要对生成的输出文本进行解码,并去除相应的特殊符号,如 EOS 标记。
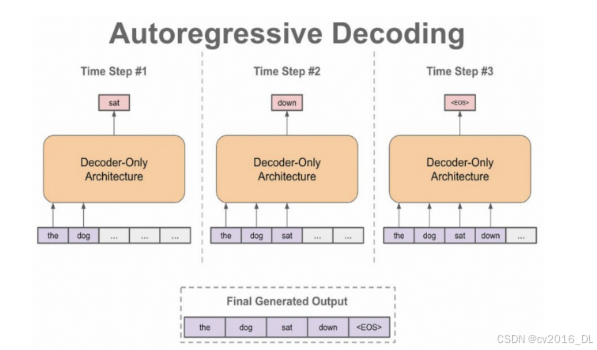
参考资料: Transformers库 generate 方法,Transformers库 Tokenizer
任务描述:
- 完善 eval/model_eval.py,补充
MLLMEvalModel类中的prepare_chat_inputs(),对推理时的输入数据进行预处理; - 完善 mllm/model/modeling_mllm.py,补充模型推理函数
generate()及其相关函数
问题1:
def prepare_chat_inputs(self, tokenizer, system_prompt, msgs_list, images_list):### ===> TODO:# 将输入文本转换为预处理函数所需的格式# Rule:# 1. 输入图片的位置应该替换为 (<image>./</image>) 字符串# 2. 使用 tokenizer 将输入文本转换为模型所需的输入格式,并进行分词(tokenize)# 提示:使用 tokenizer.apply_chat_template 进行输入文本格式转换prompts_lists = []input_images_lists = []### <===return prompts_lists, input_images_lists参考代码:
问题1:
https://huggingface.co/katuni4ka/tiny-random-minicpmv-2_6/resolve/main/modeling_minicpmv.py?download=true
https://huggingface.co/openbmb/MiniCPM-o-2_6/blob/main/modeling_minicpmo.py
def prepare_chat_inputs(self, tokenizer, system_prompt, msgs_list, images_list):### ===> TODO:# 将输入文本转换为预处理函数所需的格式# Rule:# 1. 输入图片的位置应该替换为 (<image>./</image>) 字符串# 2. 使用 tokenizer 将输入文本转换为模型所需的输入格式,并进行分词(tokenize)# 提示:使用 tokenizer.apply_chat_template 进行输入文本格式转换prompts_lists = []input_images_lists = []for image, msgs in zip(images_list, msgs_list):if isinstance(msgs, str):msgs = json.loads(msgs)copy_msgs = deepcopy(msgs)assert len(msgs) > 0, "msgs is empty"assert sampling or not stream, "if use stream mode, make sure sampling=True"if image is not None and isinstance(copy_msgs[0]["content"], str):copy_msgs[0]["content"] = [image, copy_msgs[0]["content"]]images = []for i, msg in enumerate(copy_msgs):role = msg["role"]content = msg["content"]assert role in ["user", "assistant"]if i == 0:assert role == "user", "The role of first msg should be user"if isinstance(content, str):content = [content]cur_msgs = []for c in content:if isinstance(c, Image.Image):images.append(c)cur_msgs.append("(<image>./</image>)")elif isinstance(c, str):cur_msgs.append(c)msg["content"] = "\n".join(cur_msgs)if system_prompt:sys_msg = {"role": "system", "content": system_prompt}copy_msgs = [sys_msg] + copy_msgsprompts_lists.append(processor.tokenizer.apply_chat_template(copy_msgs, tokenize=False, add_generation_prompt=True))input_images_lists.append(images)### <===return prompts_lists, input_images_lists问题2:
def generate(self,input_ids=None,pixel_values=None,tgt_sizes=None,image_bound=None,attention_mask=None,tokenizer=None,vision_hidden_states=None,return_vision_hidden_states=False,stream=False,decode_text=False,**kwargs):assert input_ids is not Noneassert len(input_ids) == len(pixel_values)model_inputs = {"input_ids": input_ids,"image_bound": image_bound,}if vision_hidden_states is None:model_inputs["pixel_values"] = pixel_valuesmodel_inputs['tgt_sizes'] = tgt_sizeselse:model_inputs["vision_hidden_states"] = vision_hidden_states### ===> TODO: 实现多模态大模型的 generation,注意不要计算模型参数的梯度。# 1. 获取模型视觉信号# 2. 实现 self._decode(),返回解码后的文本result = None### <===if return_vision_hidden_states:return result, vision_hidden_statesreturn result参考代码1:
def generate(self,input_ids=None,pixel_values=None,tgt_sizes=None,image_bound=None,attention_mask=None,tokenizer=None,vision_hidden_states=None,return_vision_hidden_states=False,stream=False,decode_text=False,**kwargs):assert input_ids is not Noneassert len(input_ids) == len(pixel_values)model_inputs = {"input_ids": input_ids, "image_bound": image_bound}if vision_hidden_states is None:model_inputs["pixel_values"] = pixel_valuesmodel_inputs["tgt_sizes"] = tgt_sizeselse:model_inputs["vision_hidden_states"] = vision_hidden_stateswith paddle.no_grad():model_inputs["inputs_embeds"], vision_hidden_states = self.get_vllm_embedding(model_inputs)if stream:result = self._decode_stream(model_inputs["inputs_embeds"], tokenizer, **kwargs)else:result = self._decode(model_inputs["inputs_embeds"], tokenizer, attention_mask, decode_text=decode_text, **kwargs)if return_vision_hidden_states:return result, vision_hidden_statesreturn result
参考代码2:
https://huggingface.co/openbmb/MiniCPM-V-2_6-int4/blob/main/modeling_minicpmv.py
def generate(self,input_ids=None,pixel_values=None,tgt_sizes=None,image_bound=None,attention_mask=None,tokenizer=None,vision_hidden_states=None,return_vision_hidden_states=False,stream=False,decode_text=False,**kwargs):assert input_ids is not Noneassert len(input_ids) == len(pixel_values)model_inputs = {"input_ids": input_ids,"image_bound": image_bound,}if vision_hidden_states is None:model_inputs["pixel_values"] = pixel_valuesmodel_inputs['tgt_sizes'] = tgt_sizeselse:model_inputs["vision_hidden_states"] = vision_hidden_stateswith torch.inference_mode():(model_inputs["inputs_embeds"],vision_hidden_states,) = self.get_vllm_embedding(model_inputs)if stream:result = self._decode_stream(model_inputs["inputs_embeds"], tokenizer, **kwargs)else:result = self._decode(model_inputs["inputs_embeds"], tokenizer, attention_mask, decode_text=decode_text, **kwargs)if return_vision_hidden_states:return result, vision_hidden_statesreturn result4. 多模态大模型推理效果验证
多模态大模型的实际效果评价需要通过在不同类型的测试集上进行评测来获得,其中一个重要的评测方面是多模态大模型回复中的“幻觉”程度。“幻觉”是指多模态大模型在回答用户输入的问题时产生的与图片不符的回复,模型的幻觉问题也极大地影响了模型的实际应用。
为了评估模型的幻觉水平,一个常用的指标是 CHAIR 指标。这一指标通过计算模型在图片详细描述中,幻觉物体占全部物体提及中的比例,来表征模型的幻觉情况。$CHAIR$ 指标有两个计算方式,其一是回复级别幻觉率 CHAIRs,这一指标计算所有描述条目中,存在幻觉物体的条目所占的比例;其二是物体级别幻觉率 CHAIRi,这一指标计算所有描述条目中,幻觉物体占全部物体提及的比例。

参考论文: [1] Object Hallucination in Image Captioning
任务描述:
- 使用编写好的 eval/model_eval.py 代码,在objhal_bench.jsonl 数据上进行推理,并运行 eval/eval_chair.py 计算 CHAIR 得分。
- 控制模型进行随机解码(sampling decoding)、贪婪解码(greedy search)以及束搜索解码(beam search),观察总结不同解码策略下的模型输出特性。
要求: 模型的 CHAIR 得分应当接近 CHAIRs = 32.7, CHAIRi = 8.5, Recall = 61.7, Len = 126
参考代码:可以参考其他网站上的代码:
https://github.com/xing0047/cca-llava/blob/5611a9e0a3f9714b7e2904a0f518be7a982e7d7f/llava/eval/eval_chair.py#L4
Hallucination-Attribution
https://github.com/TianyunYoung/Hallucination-Attribution/blob/841fc1b4f2c1e079d5aad13d8420408e7d4c0dbd/LLaVA/eval_scripts/eval_utils/eval_chair.py#L4
- eval_chair.py
'''
Copied from: https://github.com/LisaAnne/Hallucination/blob/master/utils/chair.pyModified by: Maxlinn1. adapt calculation of CHAIR-i and CHAIR-s for Python3, supports for both json and jsonl file input.
2. integrate synonyms.txt to make the script standalone.
3. remove machine-translation based metrics BLEU-n, CIDEr, ROGUE
4. add new metric Recall, which represents the node words(i.e. lemmas of objects) coverage overall.
5. add pickle cache mechanism to make it fast for repetitive evaluations.
'''import os
import sys
import nltk
import json
# from pattern.en import singularize
from nltk.corpus import wordnet
from nltk.stem import WordNetLemmatizer
import argparse
import tqdm
import pickle
from collections import defaultdict# copied from: https://github.com/LisaAnne/Hallucination/blob/master/data/synonyms.txt
synonyms_txt = '''
person, girl, boy, man, woman, kid, child, chef, baker, people, adult, rider, children, baby, worker, passenger, sister, biker, policeman, cop, officer, lady, cowboy, bride, groom, male, female, guy, traveler, mother, father, gentleman, pitcher, player, skier, snowboarder, skater, skateboarder, person, woman, guy, foreigner, child, gentleman, caller, offender, coworker, trespasser, patient, politician, soldier, grandchild, serviceman, walker, drinker, doctor, bicyclist, thief, buyer, teenager, student, camper, driver, solider, hunter, shopper, villager
bicycle, bike, bicycle, bike, unicycle, minibike, trike
car, automobile, van, minivan, sedan, suv, hatchback, cab, jeep, coupe, taxicab, limo, taxi
motorcycle, scooter, motor bike, motor cycle, motorbike, scooter, moped
airplane, jetliner, plane, air plane, monoplane, aircraft, jet, jetliner, airbus, biplane, seaplane
bus, minibus, trolley
train, locomotive, tramway, caboose
truck, pickup, lorry, hauler, firetruck
boat, ship, liner, sailboat, motorboat, dinghy, powerboat, speedboat, canoe, skiff, yacht, kayak, catamaran, pontoon, houseboat, vessel, rowboat, trawler, ferryboat, watercraft, tugboat, schooner, barge, ferry, sailboard, paddleboat, lifeboat, freighter, steamboat, riverboat, battleship, steamship
traffic light, street light, traffic signal, stop light, streetlight, stoplight
fire hydrant, hydrant
stop sign
parking meter
bench, pew
bird, ostrich, owl, seagull, goose, duck, parakeet, falcon, robin, pelican, waterfowl, heron, hummingbird, mallard, finch, pigeon, sparrow, seabird, osprey, blackbird, fowl, shorebird, woodpecker, egret, chickadee, quail, bluebird, kingfisher, buzzard, willet, gull, swan, bluejay, flamingo, cormorant, parrot, loon, gosling, waterbird, pheasant, rooster, sandpiper, crow, raven, turkey, oriole, cowbird, warbler, magpie, peacock, cockatiel, lorikeet, puffin, vulture, condor, macaw, peafowl, cockatoo, songbird
cat, kitten, feline, tabby
dog, puppy, beagle, pup, chihuahua, schnauzer, dachshund, rottweiler, canine, pitbull, collie, pug, terrier, poodle, labrador, doggie, doberman, mutt, doggy, spaniel, bulldog, sheepdog, weimaraner, corgi, cocker, greyhound, retriever, brindle, hound, whippet, husky
horse, colt, pony, racehorse, stallion, equine, mare, foal, palomino, mustang, clydesdale, bronc, bronco
sheep, lamb, ram, lamb, goat, ewe
cow, cattle, oxen, ox, calf, cattle, holstein, heifer, buffalo, bull, zebu, bison
elephant
bear, panda
zebra
giraffe
backpack, knapsack
umbrella
handbag, wallet, purse, briefcase
tie, bow, bow tie
suitcase, suit case, luggage
frisbee
skis, ski
snowboard
sports ball, ball
kite
baseball bat
baseball glove
skateboard
surfboard, longboard, skimboard, shortboard, wakeboard
tennis racket, racket
bottle
wine glass
cup
fork
knife, pocketknife, knive
spoon
bowl, container
banana
apple
sandwich, burger, sub, cheeseburger, hamburger
orange
broccoli
carrot
hot dog
pizza
donut, doughnut, bagel
cake, cheesecake, cupcake, shortcake, coffeecake, pancake
chair, seat, stool
couch, sofa, recliner, futon, loveseat, settee, chesterfield
potted plant, houseplant
bed
dining table, table, desk
toilet, urinal, commode, toilet, lavatory, potty
tv, monitor, televison, television
laptop, computer, notebook, netbook, lenovo, macbook, laptop computer
mouse
remote
keyboard
cell phone, mobile phone, phone, cellphone, telephone, phon, smartphone, iPhone
microwave
oven, stovetop, stove, stove top oven
toaster
sink
refrigerator, fridge, fridge, freezer
book
clock
vase
scissors
teddy bear, teddybear
hair drier, hairdryer
toothbrush
'''def combine_coco_captions(annotation_path):if not os.path.exists('%s/captions_%s2014.json' %(annotation_path, 'val')):raise Exception("Please download MSCOCO caption annotations for val set")if not os.path.exists('%s/captions_%s2014.json' %(annotation_path, 'train')):raise Exception("Please download MSCOCO caption annotations for train set")val_caps = json.load(open('%s/captions_%s2014.json' %(annotation_path, 'val')))train_caps = json.load(open('%s/captions_%s2014.json' %(annotation_path, 'train')))all_caps = {'info': train_caps['info'],'licenses': train_caps['licenses'],'images': val_caps['images'] + train_caps['images'],'annotations': val_caps['annotations'] + train_caps['annotations']}return all_caps def combine_coco_instances(annotation_path):if not os.path.exists('%s/instances_%s2014.json' %(annotation_path, 'val')):raise Exception("Please download MSCOCO instance annotations for val set")if not os.path.exists('%s/instances_%s2014.json' %(annotation_path, 'train')):raise Exception("Please download MSCOCO instance annotations for train set")val_instances = json.load(open('%s/instances_%s2014.json' %(annotation_path, 'val')))train_instances = json.load(open('%s/instances_%s2014.json' %(annotation_path, 'train')))all_instances = {'info': train_instances['info'],'licenses': train_instances['licenses'],'type': train_instances['licenses'],'categories': train_instances['categories'],'images': train_instances['images'] + val_instances['images'],'annotations': val_instances['annotations'] + train_instances['annotations']}return all_instances class CHAIR(object):def __init__(self, coco_path):self.imid_to_objects = defaultdict(list) # later become a dict of setsself.coco_path = coco_path#read in synonymssynonyms = synonyms_txt.splitlines()synonyms = [s.strip().split(', ') for s in synonyms]self.mscoco_objects = [] #mscoco objects and *all* synonymsself.inverse_synonym_dict = {}for synonym in synonyms:self.mscoco_objects.extend(synonym)for s in synonym:self.inverse_synonym_dict[s] = synonym[0]#Some hard coded rules for implementing CHAIR metrics on MSCOCO#common 'double words' in MSCOCO that should be treated as a single wordcoco_double_words = ['motor bike', 'motor cycle', 'air plane', 'traffic light', 'street light', 'traffic signal', 'stop light', 'fire hydrant', 'stop sign', 'parking meter', 'suit case', 'sports ball', 'baseball bat', 'baseball glove', 'tennis racket', 'wine glass', 'hot dog', 'cell phone', 'mobile phone', 'teddy bear', 'hair drier', 'potted plant', 'bow tie', 'laptop computer', 'stove top oven', 'hot dog', 'teddy bear', 'home plate', 'train track']#Hard code some rules for special cases in MSCOCO#qualifiers like 'baby' or 'adult' animal will lead to a false fire for the MSCOCO object 'person'. 'baby bird' --> 'bird'.animal_words = ['bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'animal', 'cub']#qualifiers like 'passenger' vehicle will lead to a false fire for the MSCOCO object 'person'. 'passenger jet' --> 'jet'.vehicle_words = ['jet', 'train']#double_word_dict will map double words to the word they should be treated as in our analysisself.double_word_dict = {}for double_word in coco_double_words:self.double_word_dict[double_word] = double_wordfor animal_word in animal_words:self.double_word_dict['baby %s' %animal_word] = animal_wordself.double_word_dict['adult %s' %animal_word] = animal_wordfor vehicle_word in vehicle_words:self.double_word_dict['passenger %s' %vehicle_word] = vehicle_wordself.double_word_dict['bow tie'] = 'tie'self.double_word_dict['toilet seat'] = 'toilet'self.double_word_dict['wine glas'] = 'wine glass'self.get_annotations()def _load_generated_captions_into_evaluator(self, cap_file, image_id_key, caption_key):'''Meant to save time so imid_to_objects does not always need to be recomputed.'''#Read in captions self.caps, self.eval_imids = load_generated_captions(cap_file, image_id_key, caption_key)assert len(self.caps) == len(self.eval_imids)def get_wordnet_pos(self, tag):if tag.startswith('J'):return wordnet.ADJelif tag.startswith('V'):return wordnet.VERBelif tag.startswith('N'):return wordnet.NOUNelif tag.startswith('R'):return wordnet.ADVelse:return Nonedef caption_to_words(self, caption):'''Input: captionOutput: MSCOCO words in the caption'''#standard preprocessingwords = nltk.word_tokenize(caption.lower())tagged_sent = nltk.pos_tag(words)lemmas_sent = []wnl = WordNetLemmatizer()for tag in tagged_sent:wordnet_pos = self.get_wordnet_pos(tag[1]) or wordnet.NOUNlemmas_sent.append(wnl.lemmatize(tag[0], pos=wordnet_pos))# words = [singularize(w) for w in words]words = lemmas_sent#replace double wordsi = 0double_words = []idxs = []while i < len(words):idxs.append(i) double_word = ' '.join(words[i:i+2])if double_word in self.double_word_dict: double_words.append(self.double_word_dict[double_word])i += 2else:double_words.append(words[i])i += 1words = double_words#toilet seat is not chair (sentences like "the seat of the toilet" will fire for "chair" if we do not include this line)if ('toilet' in words) & ('seat' in words): words = [word for word in words if word != 'seat']#get synonyms for all words in the captionidxs = [idxs[idx] for idx, word in enumerate(words) \if word in set(self.mscoco_objects)]words = [word for word in words if word in set(self.mscoco_objects)]node_words = []for word in words:node_words.append(self.inverse_synonym_dict[word])#return all the MSCOCO objects in the captionreturn words, node_words, idxs, double_wordsdef get_annotations_from_segments(self):'''Add objects taken from MSCOCO segmentation masks'''coco_segments = combine_coco_instances(self.coco_path )segment_annotations = coco_segments['annotations']#make dict linking object name to idsid_to_name = {} #dict with id to synsets for cat in coco_segments['categories']:id_to_name[cat['id']] = cat['name']for i, annotation in enumerate(segment_annotations):sys.stdout.write("\rGetting annotations for %d/%d segmentation masks" %(i, len(segment_annotations)))imid = annotation['image_id']node_word = self.inverse_synonym_dict[id_to_name[annotation['category_id']]]self.imid_to_objects[imid].append(node_word)print("\n")def get_annotations_from_captions(self):'''Add objects taken from MSCOCO ground truth captions '''coco_caps = combine_coco_captions(self.coco_path)caption_annotations = coco_caps['annotations']for i, annotation in enumerate(caption_annotations):sys.stdout.write('\rGetting annotations for %d/%d ground truth captions' %(i, len(coco_caps['annotations'])))imid = annotation['image_id']_, node_words, _, _ = self.caption_to_words(annotation['caption'])# note here is update, so call get_annotations_from_segments firstself.imid_to_objects[imid].extend(node_words)print("\n")def get_annotations(self):'''Get annotations from both segmentation and captions. Need both annotation types for CHAIR metric.'''self.get_annotations_from_segments() self.get_annotations_from_captions()# deduplicatefor imid in self.imid_to_objects:self.imid_to_objects[imid] = set(self.imid_to_objects[imid])def compute_chair(self, cap_file, image_id_key, caption_key):'''Given ground truth objects and generated captions, determine which sentences have hallucinated words.'''self._load_generated_captions_into_evaluator(cap_file, image_id_key, caption_key)imid_to_objects = self.imid_to_objectscaps = self.capseval_imids = self.eval_imidsnum_caps = 0.num_hallucinated_caps = 0.hallucinated_word_count = 0.coco_word_count = 0.len_caps = 0.# :add:num_recall_gt_objects = 0.num_gt_objects = 0.output = {'sentences': []} for i in tqdm.trange(len(caps)):cap :str = caps[i]imid :int = eval_imids[i]#get all words in the caption, as well as corresponding node word# pos = cap.rfind('.')# cap = cap[:pos+1]words, node_words, idxs, raw_words = self.caption_to_words(cap) gt_objects = imid_to_objects[imid]cap_dict = {'image_id': imid, 'caption': cap,'mscoco_hallucinated_words': [],'mscoco_gt_words': list(gt_objects),'mscoco_generated_words': list(node_words),'hallucination_idxs': [], 'words': raw_words }# :add:cap_dict['metrics'] = {'CHAIRs': 0,'CHAIRi': 0,'Recall': 0,'Len': 0,}#count hallucinated wordscoco_word_count += len(node_words) hallucinated = False# addrecall_gt_objects = set()for word, node_word, idx in zip(words, node_words, idxs):if node_word not in gt_objects:hallucinated_word_count += 1 cap_dict['mscoco_hallucinated_words'].append((word, node_word))cap_dict['hallucination_idxs'].append(idx)hallucinated = Trueelse:recall_gt_objects.add(node_word)#count hallucinated capsnum_caps += 1len_caps += len(raw_words)if hallucinated:num_hallucinated_caps += 1# addnum_gt_objects += len(gt_objects)num_recall_gt_objects += len(recall_gt_objects)cap_dict['metrics']['CHAIRs'] = int(hallucinated)cap_dict['metrics']['CHAIRi'] = 0.cap_dict['metrics']['Recall'] = 0.cap_dict['metrics']['Len'] = 0.if len(words) > 0:cap_dict['metrics']['CHAIRi'] = len(cap_dict['mscoco_hallucinated_words'])/float(len(words))# addif len(gt_objects) > 0:cap_dict['metrics']['Recall'] = len(recall_gt_objects) / len(gt_objects)output['sentences'].append(cap_dict)chair_s = (num_hallucinated_caps/num_caps)chair_i = (hallucinated_word_count/coco_word_count)# addrecall = num_recall_gt_objects / num_gt_objectsavg_len = (0.01*len_caps/num_caps)output['overall_metrics'] = {'CHAIRs': chair_s,'CHAIRi': chair_i,'Recall': recall,'Len': avg_len,}return output def load_generated_captions(cap_file, image_id_key:str, caption_key:str):#Read in captions # it should be list of dictext = os.path.splitext(cap_file)[-1]if ext == '.json':caps = json.load(open(cap_file))elif ext == '.jsonl':caps = [json.loads(s) for s in open(cap_file)]else:raise ValueError(f'Unspported extension {ext} for cap_file: {cap_file}')# list of intimids = [obj[image_id_key] for obj in caps]# list of strcaps = [obj[caption_key] for obj in caps]return caps, imidsdef save_hallucinated_words(cap_file, cap_dict): with open(cap_file, 'w') as f:json.dump(cap_dict, f, indent=2, ensure_ascii=False)def print_metrics(hallucination_cap_dict, quiet=False):sentence_metrics = hallucination_cap_dict['overall_metrics']for k, v in sentence_metrics.items():k_str = str(k).ljust(10)v_str = f'{v * 100:.01f}'print(k_str, v_str, sep=': ')if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument("--cap_file", type=str, default='',help="path towards json or jsonl saving image ids and their captions in list of dict.")parser.add_argument("--image_id_key", type=str, default="image_id",help="in each dict of cap_file, which key stores image id of coco.")parser.add_argument("--caption_key", type=str, default="caption",help="in each dict of cap_file, which key stores caption of the image.")parser.add_argument("--cache", type=str, default="chair.pkl",help="pre inited CHAIR evaluator object, for fast loading.")parser.add_argument("--coco_path", type=str, default='coco_annotations',help="only use for regenerating CHAIR evaluator object, will be ignored if uses cached evaluator.")parser.add_argument("--save_path", type=str, default="",help="saving CHAIR evaluate and results to json, useful for debugging the caption model.")args = parser.parse_args()if args.cache and os.path.exists(args.cache):evaluator = pickle.load(open(args.cache, 'rb'))print(f"loaded evaluator from cache: {args.cache}")else:print(f"cache not setted or not exist yet, building from scratch...")evaluator = CHAIR(args.coco_path)pickle.dump(evaluator, open(args.cache, 'wb'))print(f"cached evaluator to: {args.cache}")cap_dict = evaluator.compute_chair(args.cap_file, args.image_id_key, args.caption_key) print_metrics(cap_dict)if args.save_path:save_hallucinated_words(args.save_path, cap_dict)任务2. 多模态大模型的指令微调(Supervised Finetuning, SFT)
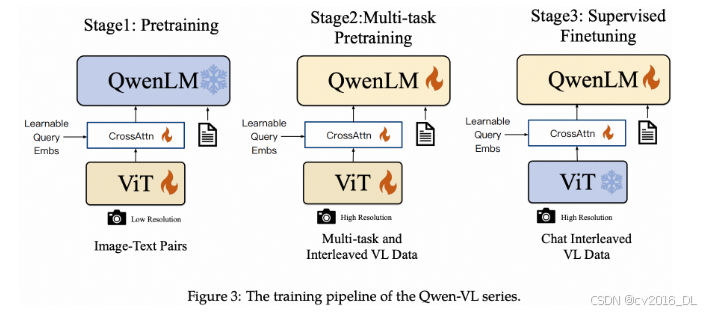
多模态大模型的能力需要通过训练获得。目前,主要的训练流程可以划分为三个阶段:1. 预训练(Pretraining)阶段;2. 多任务预训练(Multi-task Pretraining);2. 监督微调阶段(Supervised Finetuning)。
预训练阶段,使用海量的图像-文本对数据进行模型训练,增强多模态大模型的图像编码能力,并将图像与文本表示统一至相同的空间。
多任务预训练阶段,使用图文交错数据、已有的简单视觉问答数据进行训练,进一步提升模型的知识。
监督微调阶段,使用高质量的图像对话数据进行训练,增强模型在细节描述、指令理解、对话以及复杂推理的能力。
参考论文: [1] Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
1. 指令微调数据集
为了对模型进行训练,首先需要建立数据集,对原始的输入数据进行处理,以获得模型训练所需要的数据格式。其中涉及的操作与模型推理阶段类似,需要对输入文本格式进行转换,并对图像进行预先处理。
在PyTorch中,Dataset类提供了灵活的接口来定义和处理自定义数据集。通过继承Dataset类,可以实现指令微调所需的数据集,其功能应该包括执行必要的预处理操作,并将数据整理为模型可接受的输入格式。
参考资料: Pytorch Dataset
任务描述: 在 mllm/train/datasets.py 中,编写 SupervisedDataset,读取训练数据并处理为训练所需格式。
class SupervisedDataset(Dataset):"""Dataset for supervised fine-tuning."""### ===> TODO: 实现监督微调数据集,能够预处理数据为训练所需格式# 图片可以通过 images_dict = { "<image>" : Image.open(self.raw_data[i]["image"]).convert("RGB") } 获取# 调用时应该返回一下信息:# ret = dict(# input_ids = ,# position_ids = ,# labels = ,# attention_mask = ,# pixel_values = ,# tgt_sizes = ,# image_bound = ,# )def __init__(self,raw_data,transform,tokenizer,slice_config,patch_size=14,query_nums=64,batch_vision=False,max_length=2048,):super(SupervisedDataset, self).__init__()self.raw_data = raw_dataself.tokenizer = tokenizerself.transform = transformself.slice_config = slice_configself.patch_size = patch_sizeself.query_nums=query_numsself.batch_vision = batch_visionself.max_length = max_length### <===
参考代码:
https://github.com/OpenBMB/MiniCPM-o/blob/main/finetune/dataset.py
class SupervisedDataset(Dataset):"""Dataset for supervised fine-tuning."""def __init__(self,raw_data,transform,tokenizer,slice_config,llm_type="minicpm",patch_size=14,query_nums=64,batch_vision=False,max_length=2048,):super(SupervisedDataset, self).__init__()self.raw_data = raw_dataself.tokenizer = tokenizerself.transform = transformself.slice_config = slice_configself.llm_type = llm_typeself.patch_size = patch_sizeself.query_nums=query_numsself.batch_vision = batch_visionself.max_length = max_lengthdef __len__(self):return len(self.raw_data)def __getitem__(self, i) -> Dict[str, torch.Tensor]:try:if isinstance(self.raw_data[i]["image"], str):images_dict = { "<image>" : Image.open(self.raw_data[i]["image"]).convert("RGB") }elif isinstance(self.raw_data[i]["image"], Dict):### for multi-images input, the template for every image is <image_xx>, such as <image_00>, <image_01>images_dict = {img_name : Image.open(img_path).convert("RGB") for img_name, img_path in self.raw_data[i]["image"].items()}ret = preprocess(images_dict,self.raw_data[i]["conversations"],self.tokenizer,self.transform,query_nums=self.query_nums,slice_config=self.slice_config,llm_type=self.llm_type,patch_size=self.patch_size,batch_vision=self.batch_vision,max_length=self.max_length)ret = dict(input_ids=ret["input_ids"],position_ids=ret["position_ids"],labels=ret["target"],attention_mask=torch.ones_like(ret["input_ids"], dtype=torch.bool),pixel_values=ret["pixel_values"],tgt_sizes=ret["tgt_sizes"],image_bound=ret["image_bound"],)except:logger.error(f"data fetch error")return self.__getitem__(random.randint(0, len(self)))return ret2. 训练数据预处理
在模型训练中,批处理(batch processing)是提高计算效率的关键。由于输入数据长度各异,需通过填充(padding)技术使每个批次中的数据条目等长。填充时使用特定的填充标记(padding token)将短于最大长度的序列扩展,而对于超过模型最大输入长度的序列,则进行截断。通常,这一批处理过程在data_collator()函数中实现。
在实现data_collator()时需要注意,对长度不足的条目进行填充时,填充标记对输入信息的理解没有帮助,因此不应该对其进行注意力的计算。为此,应当为输入和输出数据创建相应的注意力遮罩(attention mask),以忽略填充部分的注意力计算。
任务描述: 在 mllm/train/preprocess.py,补充 data_collator()。
def data_collator(examples, padding_value=0, max_length=2048):### ===> TODO: 将多个样本整理为一个批次def trim_and_pad(seq, batch_first, padding_value):## 1. 截取并保留 max_length 以内的文本## 2. 对保留文本进行填充(padding),可以使用 pytorch 库函数return 0input_ids = Noneposition_ids = Nonetargets = Noneattention_mask = Noneimage_bound = Nonetgt_sizes = Nonepixel_values = Nonereturn {"input_ids": input_ids,"position_ids": position_ids,"labels": targets,"attention_mask": attention_mask,"image_bound": image_bound,"tgt_sizes": tgt_sizes,"pixel_values": pixel_values,}### <===参考代码:
https://github.com/OpenBMB/MiniCPM-o/blob/main/finetune/dataset.py
def data_collator(examples, padding_value=0, max_length=2048):def trim_and_pad(seq, batch_first, padding_value):return pad_sequence([s[:max_length] for s in seq], batch_first=True, padding_value=padding_value)input_ids = trim_and_pad([example["input_ids"] for example in examples],batch_first=True,padding_value=padding_value,)position_ids = trim_and_pad([example["position_ids"] for example in examples],batch_first=True,padding_value=padding_value,)targets = trim_and_pad([example["labels"] for example in examples],batch_first=True,padding_value=-100,)attention_mask = trim_and_pad([example["attention_mask"] for example in examples],batch_first=True,padding_value=padding_value,)pixel_values = [example["pixel_values"] for example in examples]image_bound = [example["image_bound"] for example in examples]tgt_sizes = [example["tgt_sizes"] for example in examples]return {"input_ids": input_ids,"position_ids": position_ids,"labels": targets,"attention_mask": attention_mask,"image_bound": image_bound,"tgt_sizes": tgt_sizes,"pixel_values": pixel_values,}
3. 指令微调损失函数
多模态大模型的指令微调与语言模型的指令微调过程类似,采用自回归损失(autoregressive loss)作为模型优化的目标。该优化目标希望模型最大化训练数据中的回复序列的预测概率。由于输入文本和图像不需要进行预测,因此不参与损失计算,损失仅在输出文本上计算。

任务描述: 在 mllm/train/trainer.py 中,补充 SFTTrainer 中的 compute_loss() 函数。
### Trainer for SFT
class SFTTrainer(Trainer):def compute_loss(self, model, inputs, return_outputs=False):if "labels" in inputs:labels = inputs.pop("labels")else:labels = Noneif not self.args.use_lora:outputs = self.model(data = inputs, use_cache=False)else:with self.model._enable_peft_forward_hooks(**inputs):outputs = self.model.base_model(data = inputs, use_cache=False)if labels is not None:### ===> TODO: 实现监督微调损失函数计算# 注意检查当前位置的 logits 对应的目标输出是否为下一个tokenloss = None### <===else:if isinstance(outputs, dict) and "loss" not in outputs:raise ValueError("The model did not return a loss from the inputs, only the following keys: "f"{','.join(outputs.keys())}. For reference, the inputs it received are {','.join(inputs.keys())}.")# We don't use .loss here since the model may return tuples instead of ModelOutput.loss = outputs["loss"] if isinstance(outputs, dict) else outputs[0]return (loss, outputs) if return_outputs else loss参考代码:
https://github.com/huggingface/trl/blob/main/trl/trainer/sft_trainer.py
https://github.com/OpenBMB/MiniCPM-o/blob/main/finetune/trainer.py
class CPMTrainer(Trainer):def compute_loss(self, model, inputs, return_outputs=False):if "labels" in inputs:labels = inputs.pop("labels")else:labels = Noneif not self.args.use_lora:outputs = self.model(data = inputs, use_cache=False)else:with self.model._enable_peft_forward_hooks(**inputs):outputs = self.model.base_model(data = inputs, use_cache=False)if labels is not None:# Flatten the tokensloss_fct = nn.CrossEntropyLoss()logits = outputs.logits.view(-1,self.model.config.vocab_size).contiguous()labels = labels.view(-1).long().contiguous()# Enable model parallelismlabels = labels.to(logits.device)loss = loss_fct(logits, labels)else:if isinstance(outputs, dict) and "loss" not in outputs:raise ValueError("The model did not return a loss from the inputs, only the following keys: "f"{','.join(outputs.keys())}. For reference, the inputs it received are {','.join(inputs.keys())}.")# We don't use .loss here since the model may return tuples instead of ModelOutput.loss = outputs["loss"] if isinstance(outputs, dict) else outputs[0]return (loss, outputs) if return_outputs else loss4. 指令微调训练
在训练模型的过程中,通过使用训练集和测试集,监控训练和验证过程中的损失变化,可以评估模型的学习效果。
对于不同的训练参数设置,模型可能出现欠拟合(训练损失与测试损失下降均不明显)、过拟合(训练损失下降明显,但测试损失反而上升)的现象。优化训练过程中的超参数,如学习率(learning_rate)、批大小(batch_size)、梯度累积步数(gradient_accumulation_step)等,有助于提升模型在测试集上的性能。
任务描述:
- 使用 data/train.json 为训练集,data/test.json 为测试集,进行模型训练,监控模型训练集、验证集 loss 变化曲线
- 调整训练过程超参数,如 learning_rate,batch_size,gradient_accumulation_step等,优化模型在测试集上的 loss 表现
要求: 模型训练后,在测试集上的损失值需 低于0.11,编写代码评测此时模型在测试集上的回答正确率
参考代码:
不涉及代码,需要训练调参。
5. 视觉定位能力增强
视觉定位(Visual Grounding, VG)[1] 的目标是给定针对图像中的对象的自然语言描述,获得该对象在图像中的坐标框。形式化地,给定一个图像I和一句自然语言问句Q,其中问句是对N个名字短语
![]()
的位置的询问,视觉定位任务的目标是预测N个名词短语在图像上所对应的位置坐标框
![]() 其中
其中![]() 是表示位置框的左上角和右下角(有些做法中也采用中心点坐标和宽、高值)的浮点数像素坐标值。
是表示位置框的左上角和右下角(有些做法中也采用中心点坐标和宽、高值)的浮点数像素坐标值。

任务描述:
- 基于 Shikra中提供的 VG 相关数据集(FlickrDataset、RECDataset等),仿照 data/train.json 构造用于 VG 功能的指令微调数据,补充完整 data/prepare_grounding.py
- 基于构造的用于 VG 功能的数据微调模型,使模型能够实现 VG 功能,补充完整 finetune_grounding.sh和mllm/train/datasets_grounding.py
- 用一个 case 测试模型的 VG 功能,实现输入关于目标对象的询问输出对象对应的坐标框(可以使用上述例子中的图像,也可以自选一张训练集中为出现过的图像)
- 参照 Qwen-VL 的指标计算方式,在 RefCOCO 的三个子集:val、test-A、test-B,RefCOCO+的三个子集:val test-A、test-B,和 RefCOCOg 的两个子集:val-u、test-u 上计算模型的准确率,补充完整 eval/grounding_eval.py
参考论文:
[1] KOSMOS-2: Grounding Multimodal Large Language Models to the World,
[2] Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
data/prepare_grounding.py
class RECDataset():def __init__(self, filename="",template_file="",image_folders={'images/VG_100K': '','images2/VG_100K_2':''},version = 'vg',total = None,ratio = None,shuffle = False,):self.datafile = filenameself.templates = json.load(open(template_file))self.image_dirs = image_foldersself.version = versionself.total = totalself.ratio = ratioself.shuffle = shuffledef get_template(self,):return nprdm.choice(self.templates, 1)[0]def build(self, return_dict=None, dict_key="key"):### ==> TODO: 实现Referring Expression Comprehension数据集result = []### <===return result参考代码:
任务3. 多模态大模型的偏好对齐训练
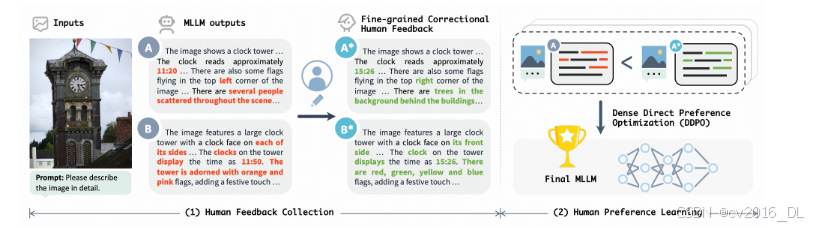
大模型的偏好对齐训练通过结合人类的反馈来优化模型的行为,使其生成的内容更加符合人类的期望和需求。在监督微调阶段,模型仅仅对“正例”进行模仿学习,缺少“负例”来抑制有害输出。在偏好对齐训练阶段,通过收集一系列的正负样本对,对模型的输出进行双向的监督,从而更有效的控制模型的输出。
在偏好对齐训练中,最为经典的算法是 RLHF[1] 算法。该方法首先使用正负样本对训练一个打分模型(reward model),再利用打分模型给出的得分,对大模型的回复进行优化,优化目标是提升大模型回复在打分模型评判下的得分,同时不要与原始的模型参数相差太远。但上述方法存在训练不稳定,不易优化的缺点,一个更简便的算法是 DPO[2] 算法,简化了 RLHF 算法中的两阶段训练过程。
在多模态大模型的构建中,可以利用偏好对齐算法来提升模型在回复上的可信度,降低模型幻觉[3]。
参考论文: [1] Training language models to follow instructions with human feedback,
[2] Direct Preference Optimization: Your Language Model is Secretly a Reward Model,
[3] RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback
1. 偏好数据对数概率(log probability)计算
为了计算偏好对齐训练中的损失值,需要得到模型在正样本与负样本上的输出概率值,形式化地表示为 π(y|x),也即模型在每条训练数据输入 x 下,输出文本 y 的概率值。
任务描述: 在 mllm/train/inference_logp.py 中,实现函数 get_batch_logps()。
def get_batch_logps(logits: torch.FloatTensor, labels: torch.LongTensor, tokenizer, return_per_token_logp=False, return_all=False) -> torch.FloatTensor:"""Compute the log probabilities of the given labels under the given logits.Args:logits: Logits of the model (unnormalized). Shape: (batch_size, sequence_length, vocab_size)labels: Labels for which to compute the log probabilities. Label tokens with a value of -100 are ignored. Shape: (batch_size, sequence_length)Returns:A tensor of shape (batch_size,) containing the average/sum log probabilities of the given labels under the given logits."""### ===> TODO: 实现 logp 计算# per_token_logps: 每个位置的logp取值# log_prob: 完整回复的 logp 之和# average_log_prob: 完整回复中每个词 logp 的平均值## 注意:## 计算时注意logits与label对应关系是否正确,当前位置logits应该以后一个词为目标## 只有输出部分应该被计算再内per_token_logps = Nonelog_prob = Noneaverage_log_prob = None### <===assert per_token_logps.shape == labels.shape, f"per_token_logps.shape={per_token_logps.shape}, labels.shape={labels.shape}"if return_per_token_logp:return per_token_logpsif return_all:return per_token_logps, log_prob, average_log_probreturn log_prob, average_log_prob参考代码1:
https://github.com/thunlp/Muffin/blob/85d72b4b04035b6b1cf4168814739ae9e5e6e1dc/muffin/eval/muffin_inference_logp.py#L81
def get_batch_logps(logits: torch.FloatTensor, labels: torch.LongTensor, return_per_token_logp=False, return_all=False) -> torch.FloatTensor:"""Compute the log probabilities of the given labels under the given logits.Args:logits: Logits of the model (unnormalized). Shape: (batch_size, sequence_length, vocab_size)labels: Labels for which to compute the log probabilities. Label tokens with a value of -100 are ignored. Shape: (batch_size, sequence_length)Returns:A tensor of shape (batch_size,) containing the average/sum log probabilities of the given labels under the given logits."""assert logits.shape[:-1] == labels.shapelabels = labels[:, 1:].clone()logits = logits[:, :-1, :]loss_mask = (labels != -100)# dummy token; we'll ignore the losses on these tokens laterlabels[labels == -100] = 0per_token_logps = torch.gather(logits.log_softmax(-1), dim=2,index=labels.unsqueeze(2)).squeeze(2)log_prob = (per_token_logps * loss_mask).sum(-1)average_log_prob = log_prob / loss_mask.sum(-1)# print(per_token_logps.shape, labels.shape)if return_per_token_logp:return per_token_logpsif return_all:return per_token_logps, log_prob, average_log_probreturn log_prob, average_log_prob参考代码2:
https://github.com/findalexli/mllm-dpo/blob/67f651cea8464ebce8d8497069499fa919f9cfda/llava/train/llava_trainer.py#L301
def get_batch_logps(logits: torch.FloatTensor, labels: torch.LongTensor, return_per_token_logp=False, return_all=False) -> torch.FloatTensor:"""Compute the log probabilities of the given labels under the given logits.Args:logits: Logits of the model (unnormalized). Shape: (batch_size, sequence_length, vocab_size)labels: Labels for which to compute the log probabilities. Label tokens with a value of -100 are ignored. Shape: (batch_size, sequence_length)Returns:A tensor of shape (batch_size,) containing the average/sum log probabilities of the given labels under the given logits."""assert logits.shape[:-1] == labels.shapelabels = labels[:, 1:].clone()logits = logits[:, :-1, :]loss_mask = (labels != -100)# dummy token; we'll ignore the losses on these tokens laterlabels[labels == -100] = 0per_token_logps = torch.gather(logits.log_softmax(-1), dim=2,index=labels.unsqueeze(2)).squeeze(2)log_prob = (per_token_logps * loss_mask).sum(-1)average_log_prob = log_prob / loss_mask.sum(-1)# print(per_token_logps.shape, labels.shape)if return_per_token_logp:return per_token_logpsif return_all:return per_token_logps, log_prob, average_log_probreturn log_prob, average_log_prob2. 偏好优化损失函数
在 DPO 优化算法提出后,产生了不同的优化目标改进方式(如[1]、[2]等),以提升偏好对齐训练的效果。其中一种改进后的损失函数计算公式如下:
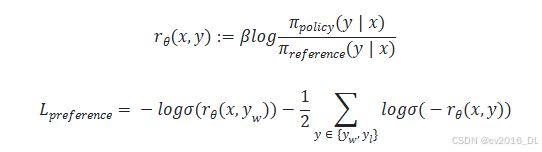

参考论文:
[1] Noise Contrastive Alignment of Language Models with Explicit Rewards
[2] KTO: Model Alignment as Prospect Theoretic Optimization
任务描述: 在 mllm/train/trainer.py 中,根据上述损失函数实现 PreferenceTrainer 中的 compute_loss() 及其相关函数。
def preference_loss(self,beta,policy_chosen_logps: torch.FloatTensor,policy_rejected_logps: torch.FloatTensor,reference_chosen_logps: torch.FloatTensor,reference_rejected_logps: torch.FloatTensor,) -> Tuple[torch.FloatTensor, torch.FloatTensor, torch.FloatTensor]:### ===> TODO: 实现偏好对齐训练 Loss 计算losses = Nonechosen_rewards = Nonerejected_rewards = Nonereturn losses, chosen_rewards.detach(), rejected_rewards.detach()### <===参考代码:
https://github.com/eric-mitchell/direct-preference-optimization/blob/main/trainers.py
def preference_loss(policy_chosen_logps: torch.FloatTensor,policy_rejected_logps: torch.FloatTensor,reference_chosen_logps: torch.FloatTensor,reference_rejected_logps: torch.FloatTensor,beta: float,label_smoothing: float = 0.0,ipo: bool = False,reference_free: bool = False) -> Tuple[torch.FloatTensor, torch.FloatTensor, torch.FloatTensor]:"""Compute the DPO loss for a batch of policy and reference model log probabilities.Args:policy_chosen_logps: Log probabilities of the policy model for the chosen responses. Shape: (batch_size,)policy_rejected_logps: Log probabilities of the policy model for the rejected responses. Shape: (batch_size,)reference_chosen_logps: Log probabilities of the reference model for the chosen responses. Shape: (batch_size,)reference_rejected_logps: Log probabilities of the reference model for the rejected responses. Shape: (batch_size,)beta: Temperature parameter for the DPO loss, typically something in the range of 0.1 to 0.5. We ignore the reference model as beta -> 0.label_smoothing: conservativeness for DPO loss, which assumes that preferences are noisy (flipped with probability label_smoothing)ipo: If True, use the IPO loss instead of the DPO loss.reference_free: If True, we ignore the _provided_ reference model and implicitly use a reference model that assigns equal probability to all responses.Returns:A tuple of three tensors: (losses, chosen_rewards, rejected_rewards).The losses tensor contains the DPO loss for each example in the batch.The chosen_rewards and rejected_rewards tensors contain the rewards for the chosen and rejected responses, respectively."""pi_logratios = policy_chosen_logps - policy_rejected_logpsref_logratios = reference_chosen_logps - reference_rejected_logpsif reference_free:ref_logratios = 0logits = pi_logratios - ref_logratios # also known as h_{\pi_\theta}^{y_w,y_l}if ipo:losses = (logits - 1/(2 * beta)) ** 2 # Eq. 17 of https://arxiv.org/pdf/2310.12036v2.pdfelse:# Eq. 3 https://ericmitchell.ai/cdpo.pdf; label_smoothing=0 gives original DPO (Eq. 7 of https://arxiv.org/pdf/2305.18290.pdf)losses = -F.logsigmoid(beta * logits) * (1 - label_smoothing) - F.logsigmoid(-beta * logits) * label_smoothingchosen_rewards = beta * (policy_chosen_logps - reference_chosen_logps).detach()rejected_rewards = beta * (policy_rejected_logps - reference_rejected_logps).detach()return losses, chosen_rewards, rejected_rewards参考2:
https://github.com/huggingface/trl/blob/main/trl/trainer/dpo_trainer.py
3. 偏好对齐训练
偏好对齐训练中,损失函数与模型输出的奖励值均可以提现模型优化的效果。在优化过程中,我们希望模型输出的损失值减小,正样本上的奖励值增加,负样本上的奖励值减小。
偏好对齐训练的效果同样受到超参数设置的影响。除了通用的超参数,如 学习率、批大小、梯度累计 以外,在偏好对齐训练中还存在一个新的超参数 β,这个参数控制了模型偏离原始模型参数的程度。
任务描述:
- 使用 preference_train.json 为训练集,进行模型训练,监控模型训练的 loss 变化、reward 变化;
- 使用 objhal_bench.jsonl 为测试集,在训练前后的模型上进行推理,并计算 CHAIR 指标;
- 调整训练过程超参数,如 偏好对齐超参数 beta,以及其他通用超参数,优化模型在测试集上的 CHAIR 指标表现。
要求: 训练后模型的 CHAIR 指标应满足 CHAIRs < 29.5, CHAIRi < 7.8
参考代码:
不涉及,需要训练调参
数据下载与环境配置
1. 数据下载
-
下载地址:https://drive.google.com/drive/folders/1j2kw_UZZq1JXfZI644RGNZzbLIB7bTT5?usp=sharing
-
内容:
chair_300.pkl: CHAIR 评测GT数据flash_attn-2.3.4+cu118torch2.1cxx11abiFALSE-cp310-cp310-linux_x86_64.whl: flash-attention 库 wheel 文件nltk_data.tar.gz: CHAIR评测中所需 nltk 库数据。下载后解压到/home/user目录下objhal_bench.jsonl: 幻觉评测集preference_train.json: 偏好对齐训练数据sft_images.tar.gz:data/train.json及data/test.json中涉及的图片数据。下载后,请将其解压在data/目录下,并将解压后的文件夹重命名为images
2. 模型下载
- 下载地址:https://huggingface.co/HaoyeZhang/MLLM_Excercise_Model
3. 环境配置
# 使用 anaconda 新建虚拟环境 conda create -n MiniCPM-V python=3.10 -y conda activate MiniCPM-V# 安装环境依赖库 pip install -r requirements.txt# 安装训练所需的 flash-attention-2 库 pip install flash_attn-2.3.4+cu118torch2.1cxx11abiFALSE-cp310-cp310-linux_x86_64.whl