很开心,SwanLab已经与多模态LLM强化学习后训练框架EasyR1完成官方集成。
在最新的EasyR1版本中,可以使用SwanLab进行实验跟踪与曲线可视化,并将LLM中间生成的内容直观的记录与管理起来。接下来让我介绍一下如何使用。

目录
EasyR1介绍
环境安装
训练Qwen2.5-7b数学模型
训练Qwen2.5-VL-7b多模态模型
每轮评估时记录生成文本
写在最后
EasyR1生态开源项目
相关资料
EasyR1介绍

EasyR1 是基于veRL的一个高效、可扩展、多模态强化学习LLM训练框架,由LLaMA Factory作者 hiyouga 打造,很很短的时间内获得了1.8k Star。
EasyR1 受益于 veRL 的 HybridEngine 和 vLLM 0.7 的 SPMD mode,并适配了 Qwen2.5-VL 模型,在多模态几何题任务 Geometry3k 上通过 30 个 batch 的 GRPO 训练,即可提升 5% 验证集准确率。
EasyR1 目前已经被很多优秀的项目采用,如MMR1、Vision-R1、Seg-Zero、MetaSpatial、Temporal-R1等。
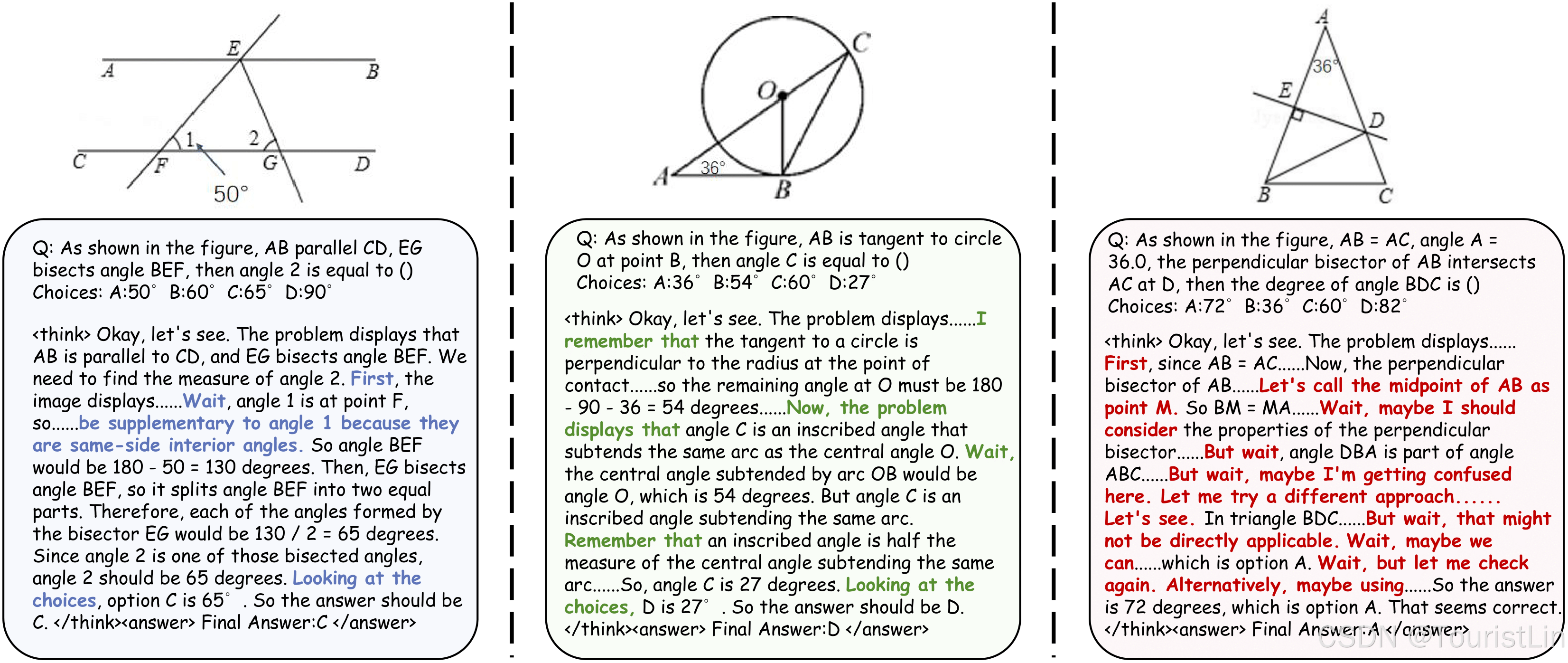
目前EasyR1支持的模型包括 语言模型(Llama3/Qwen2/Qwen2.5)、视觉语言模型(Qwen2/Qwen2.5-VL)、蒸馏模型(DeepSeek-R1-distill)等,支持GRPO、Reinforce++、ReMax、RLOO算法,以及Padding-free training 、Resuming from checkpoint 和 Wandb & SwanLab & Mlflow & Tensorboard tracking在内的训练配置。
总结来说,EasyR1让以往上手复杂、资源消耗巨大的LLM多模态强化学习后训练,变得低门槛和高性能!

关于EasyR1的更多信息可参考下面的链接:
EasyR1 GitHub仓库链接: https://github.com/hiyouga/EasyR1
HybridFlow论文地址: https://arxiv.org/pdf/2409.19256v2
这次SwanLab与EasyR1完成了官方集成,现在你可以使用EasyR1快速进行多模态大模型强化学习训练,同时使用SwanLab进行实验跟踪与可视化。
接下来我将介绍如何在EasyR1中开启SwanLab。
环境安装
运行EasyR1的环境要求:
-
Python: Version >= 3.9
-
transformers>=4.49.0
-
flash-attn>=2.4.3
-
vllm>=0.7.3
硬件要求:

准备工作-安装环境:
git clone https://github.com/hiyouga/EasyR1.git
cd EasyR1
pip install -e .
pip install swanlab训练Qwen2.5-7b数学模型
在 EasyR1 目录下,执行下面的命令,即可使用GRPO训练Qwen2.5-7b数学模型,并使用SwanLab进行跟踪与可视化:
bash examples/run_qwen2_5_7b_math_swanlab.sh当然,这里我们可以剖析一下,由于EasyR1是原始 veRL 项目的一个干净分叉,所以继承了veRL与SwanLab的集成。所以这里我们来看run_qwen2_5_7b_math_swanlab.sh文件:
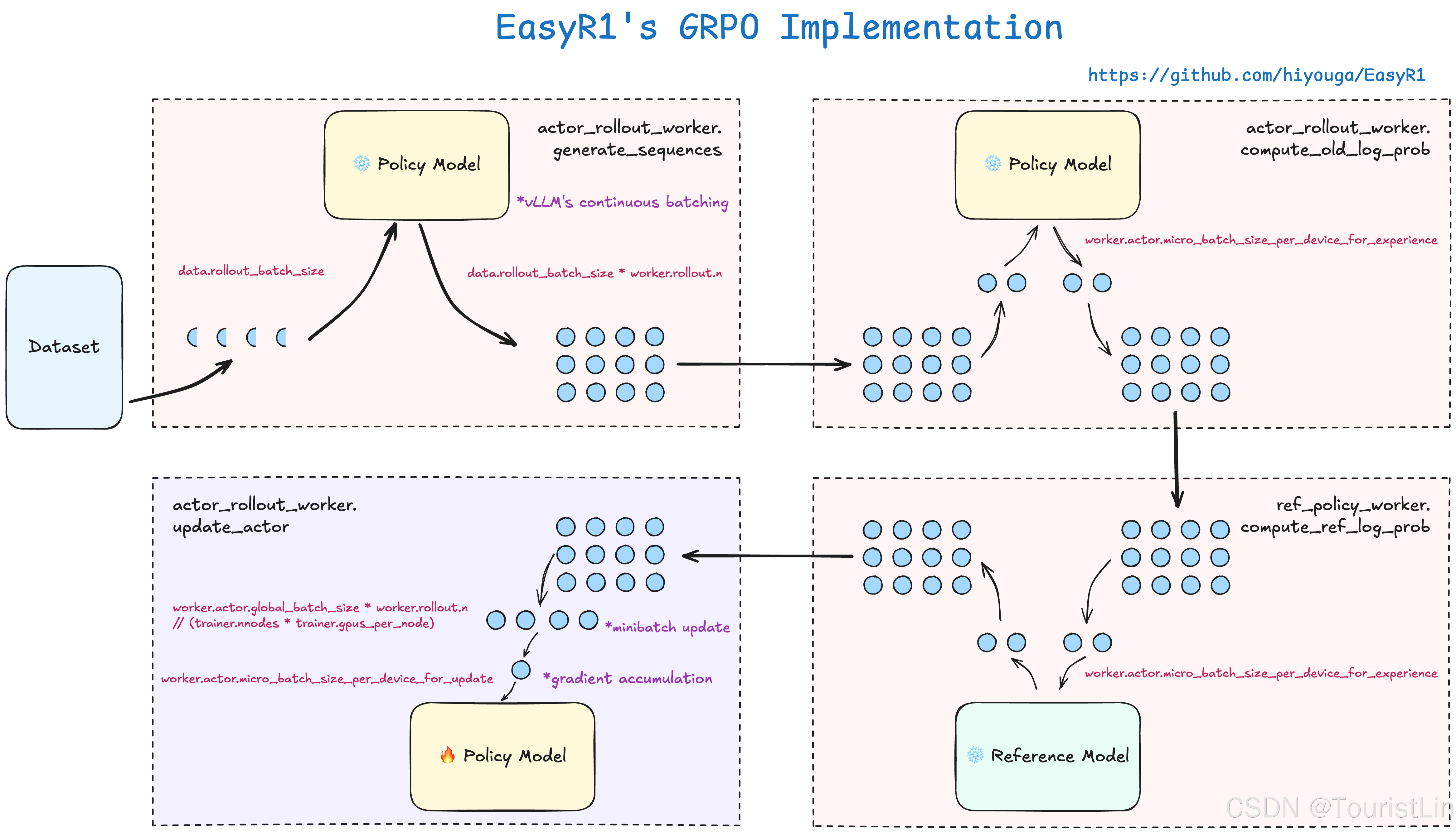
set -xexport VLLM_ATTENTION_BACKEND=XFORMERSMODEL_PATH=Qwen/Qwen2.5-7B-Instruct # replace it with your local file pathpython3 -m verl.trainer.main \config=examples/grpo_example.yaml \worker.actor.model.model_path=${MODEL_PATH} \trainer.logger=['console','swanlab'] \trainer.n_gpus_per_node=4只需要在python3 -m verl.trainer.main参数中加入一行trainer.logger=['console','swanlab'],即可使用SwanLab进行跟踪与可视化。
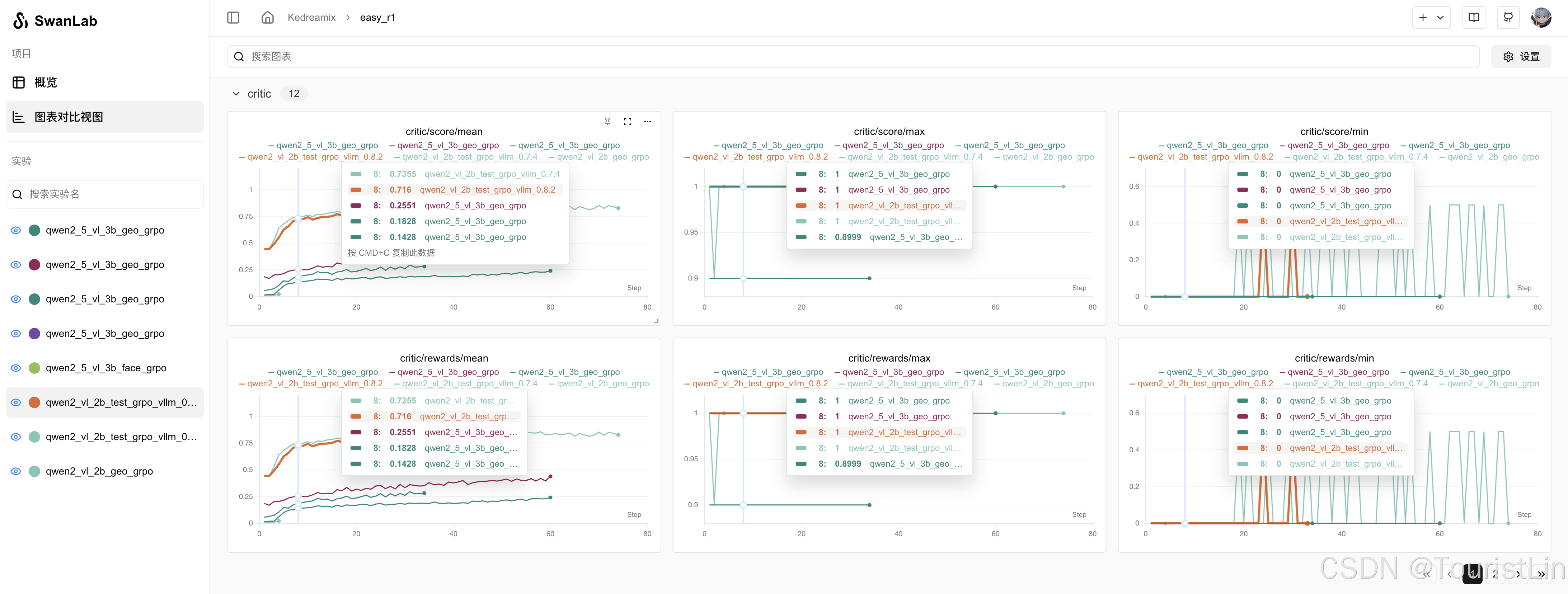
运行上面的命令,就可以在SwanLab官网上查看训练日志啦:

PS:
如果你还没有登录SwanLab,那么运行时会出现下面的提示:

选择1、2则为使用云端跟踪模式,选择后根据引导输入官网的API Key即可实现在线跟踪。可以在线查看训练跟踪结果。选择3则不上传训练数据,采用离线跟踪。
当然,你也可以通过环境变量的方式登陆或者设置跟踪模式:
export SWANLAB_API_KEY=<你的登陆API> # 设置在线跟踪模式API
export SWANLAB_LOG_DIR=<设置本地日志存储路径> # 设置本地日志存储路径
export SWANLAB_MODE=<设置SwanLab的运行模式> # 包含四种模式:cloud云端跟踪模式(默认)、cloud-only仅云端跟踪本地不保存文件、local本地跟踪模式、disabled完全不记录用于debug完成登陆后会显示如下信息:

然后就可以愉快的跟踪实验啦!

训练Qwen2.5-VL-7b多模态模型
在EasyR1目录下,执行下面的命令,即可使用GRPO训练Qwen2.5-VL-7b多模态模型,并使用SwanLab进行跟踪与可视化:
bash examples/run_qwen2_5_vl_7b_geo_swanlab.sh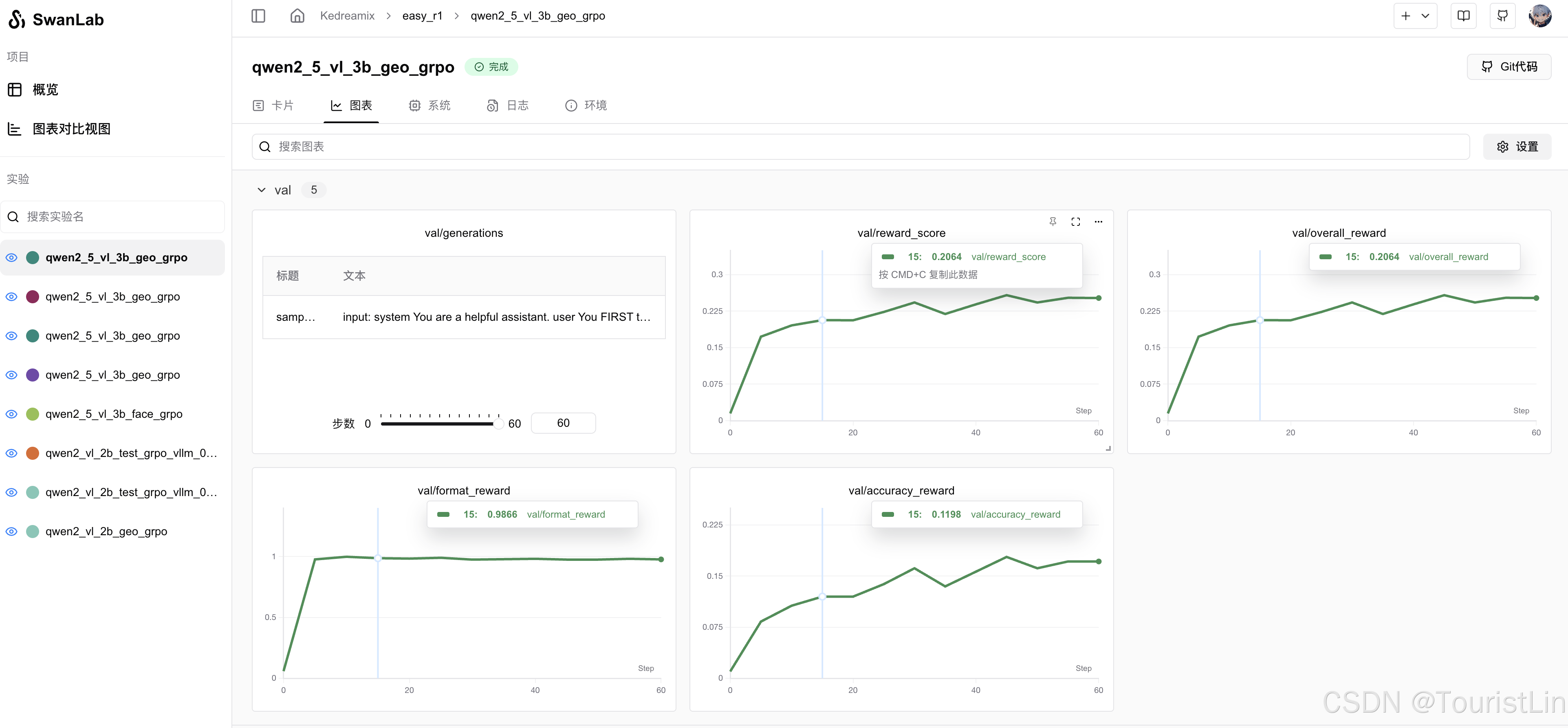
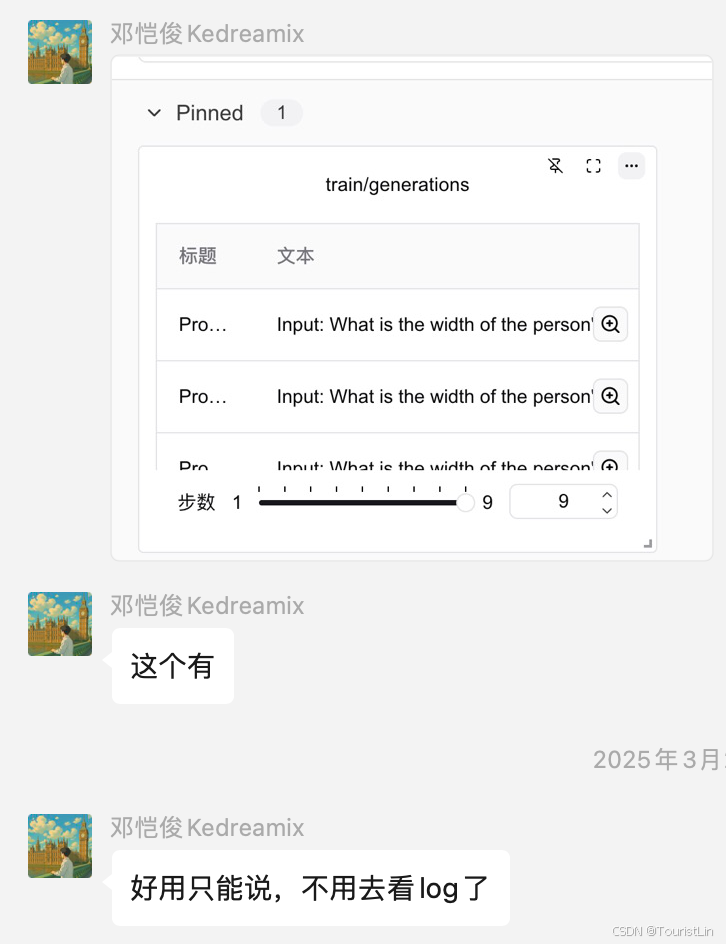
每轮评估时记录生成文本
如果你希望在每轮评估(val)时将生成的文本记录到SwanLab中,只需在命令行中增加一行val_generations_to_log=1即可:
python3 -m verl.trainer.main \config=examples/grpo_example.yaml \worker.actor.model.model_path=${MODEL_PATH} \trainer.logger=['console','swanlab'] \trainer.n_gpus_per_node=4 \val_generations_to_log=1设计这个功能的初衷便是能让研究者方便地观察大模型在训练过程中的生成文本,高效判断本次训练的质量。也很开心得到了一些开发者的好评。
写在最后
SwanLab团队致力于打造全球领先的人工智能研发工具链,为AI训练师与研究者服务。
感谢 hiyouga 向社区开源了如此出色的多模态LLM强化学习框架,并祝贺取得了十足的国际影响力。希望SwanLab未来能与更多做工具的小伙伴合作,打造优质的训练体验。
EasyR1生态开源项目
也欢迎大家关注下面的开源项目:

相关资料
-
EasyR1:https://github.com/hiyouga/EasyR1
-
veRL:https://github.com/volcengine/verl
-
SwanLab:https://github.com/SwanHubX/SwanLab
-
SwanLab与EasyR1集成文档:https://docs.swanlab.cn/guide_cloud/integration/integration-easyr1.html
-
SwanLab与EasyR1集成Demo链接:https://swanlab.cn/@Kedreamix/easy_r1/runs/wzezd8q36bb6dlza6wtpc/chart
-
理解GRPO算法:https://huggingface.co/docs/trl/v0.15.2/en/grpo_trainer