目录
设计思路
类的设计
模块实现
私有接口实现
共有接口的实现
实现过程的疑问
主函数
主函数实现
主函数测试
设计思路
Buffer模块是用于通信套接字的缓冲区,用于用户态的输入输出的数据缓存。
为什么需要 用户态的输入缓冲区?
-
内核与用户态的隔离:
在操作系统中,内核和用户态是分开的,TCP 协议栈工作在内核态。内核的任务是接收和分发网络数据,但是,内核并不能直接知道用户层的应用逻辑。它只是简单地将数据从网络传输层(如TCP)交给应用层。为了确保应用层能够正确处理这些数据,内核需要将接收到的数据存放在 内核缓冲区 中,然后应用程序通过系统调用(如 read() 或 recv())从内核缓冲区读取数据。 -
解决粘包与拆包问题:
用户态的输入缓冲区就是应用程序从内核缓冲区读取数据后临时存放的地方。在接收到的数据可能并不完整或者被拆分的情况下,应用程序会将这些数据缓存在用户态的缓冲区中,进一步处理。应用层代码通常会实现协议逻辑,用来判断每次读取的数据块是否完整,并且进行组装或拆分,恢复出完整的应用层报文。
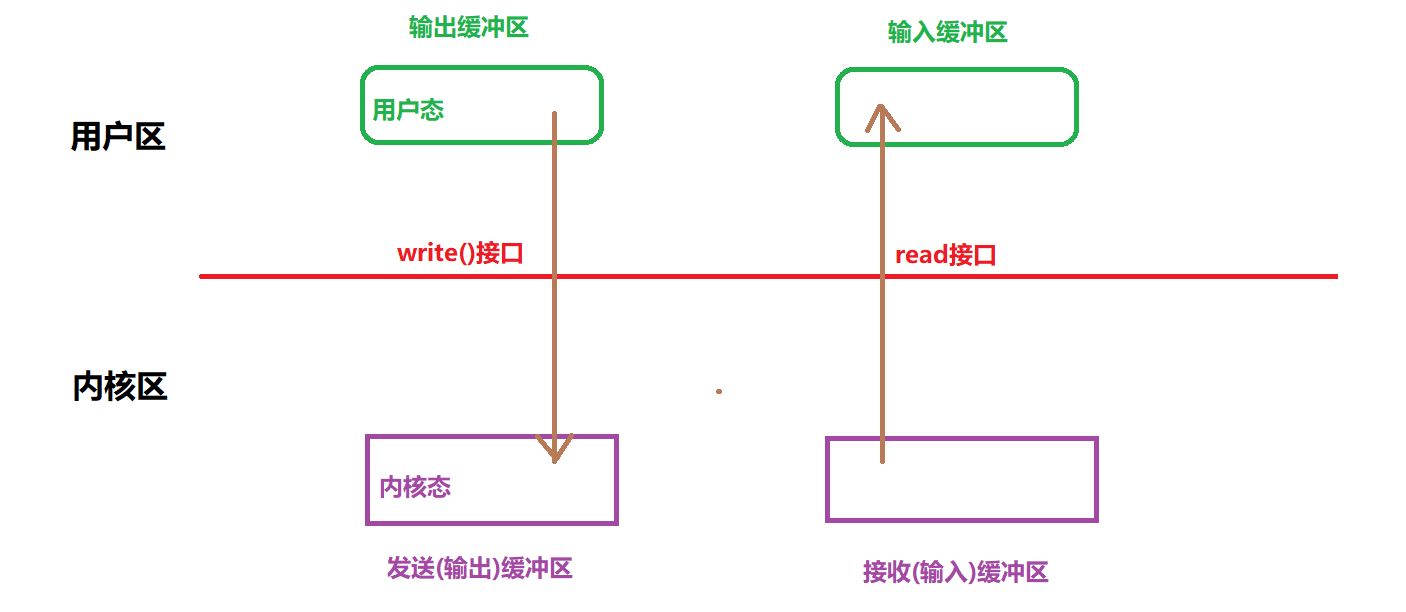
为什么需要用户态的 输出缓冲区?
在 TCP 套接字 的数据传输中,存在以下几个挑战,特别是在数据写入过程中:
-
内核缓冲区的空间有限:
-
内核的 输出缓冲区(也就是发送缓冲区)存储了待发送的数据。如果这个缓冲区满了,我们就无法直接将数据写入套接字,这时候会遇到两种情况:
-
阻塞:如果套接字处于阻塞模式(默认模式),应用程序在写入数据时会等待直到内核的缓冲区有足够空间接收更多数据。这样会导致应用程序被阻塞,影响程序的响应性和效率。
-
写入失败:如果套接字处于非阻塞模式,当缓冲区满时,写入操作会失败,可能导致数据丢失。
-
-
-
等待缓冲区就绪:
-
套接字的写事件可能并不是随时就绪的。发送缓冲区需要有足够的空间来存放数据,否则写入操作会阻塞或失败。内核会管理缓冲区的发送过程,决定何时能够写入更多数据。
-
-
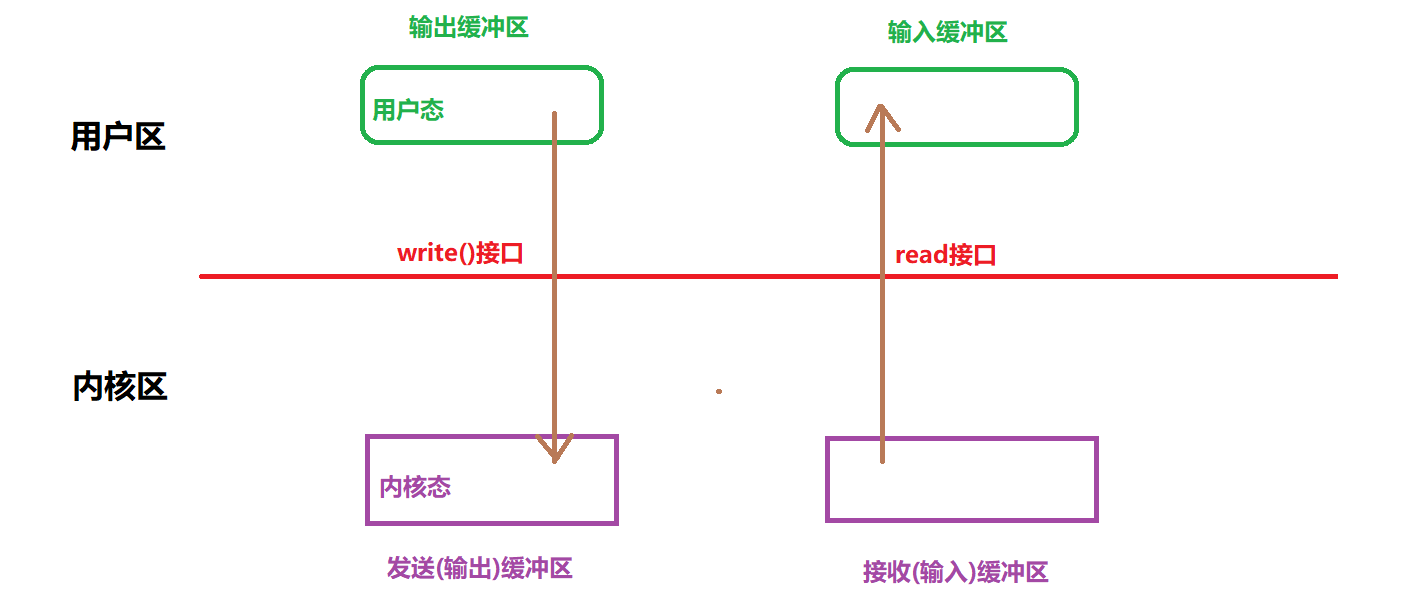
用户态缓冲区的作用:
-
用户态的输出缓冲区可以存放待发送的数据。在这种情况下,应用程序并不直接写入内核缓冲区,而是先将数据写入用户态的缓冲区。这让应用程序能够异步地积累数据,避免因为写入操作阻塞或失败而造成的性能瓶颈。
-
监听写事件:应用程序通过 I/O 多路复用技术(例如 select()、 poll()、epoll() 等)监听套接字的 可写事件,即内核缓冲区有足够的空间时,才进行实际的数据写入。这避免了直接向缓冲区写入时的阻塞或失败。
-
-
如何解决问题:
-
用户态缓冲区的作用是在数据被真正发送之前,允许程序将数据暂时存放起来,并在合适的时机将数据发送出去,避免了直接写入时的 阻塞 和 数据丢失 问题。用户态的缓冲区为程序提供了更多的 控制权 和 灵活性。
-
如何设计缓冲区呢?
这其实没什么难的,我们只需要将 读取出来数据 或者 需要写入的数据 以字节为单位 缓存 起来就行了。
而缓冲区的功能无非就三个 : 缓存数据, 写入数据, 读取数据。
缓冲区就是一块空间,那么我们可以直接使用 vector<char> 来管理这块空间。
为什么不使用 string 申请空间呢?
因为 string 更偏向于字符串,它的接口也都是一些字符串的接口,对于我们的缓冲区的实现其实并没有多大的帮助,相反,他的一系列字符串的特性比如说以 \0 结尾,反而会影响我们的操作。 而vector<char> 的底层也是一块线性的空间,操作起来也很简单,同时我们并不需要如何考虑字符串的一些特性。
那么 Buffer 类要如何实现呢?
由于我们使用线性空间来存储数据,就意味着,数据其实在不断的读取和写入的过程中,我们读取数据的时候以及写入数据的时候,大多数情况下,读取和写入的位置都不是这块空间的起始位置。

所以,我们在设计Buffer类的时候,并不只是需要一个 vector<char> 来管理一块线性空间,还需要两个变量用于维护下一次的读位置和下一次的写位置,我们可以设计成 读偏移和写偏移。
- 那么未来在读取数据的时候,是需要通过读偏移获取读起始位置进行读取的。
- 未来在写入数据的时候,也是需要通过写偏移获取写的起始位置来进行写入。
而未来在写入的时候就注定会遇到一个问题,就是写起始位置之后的空间不够写入了,这时候应该怎么做呢?
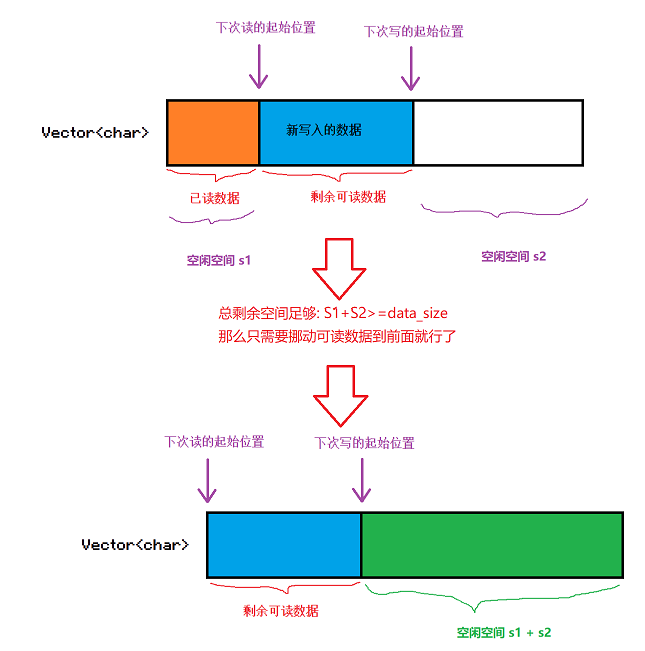
从下图中我们就可以看出来,其实空闲空间一两部分,一部分是读偏移之前的空间,另一部分才是写偏移之后的空间。
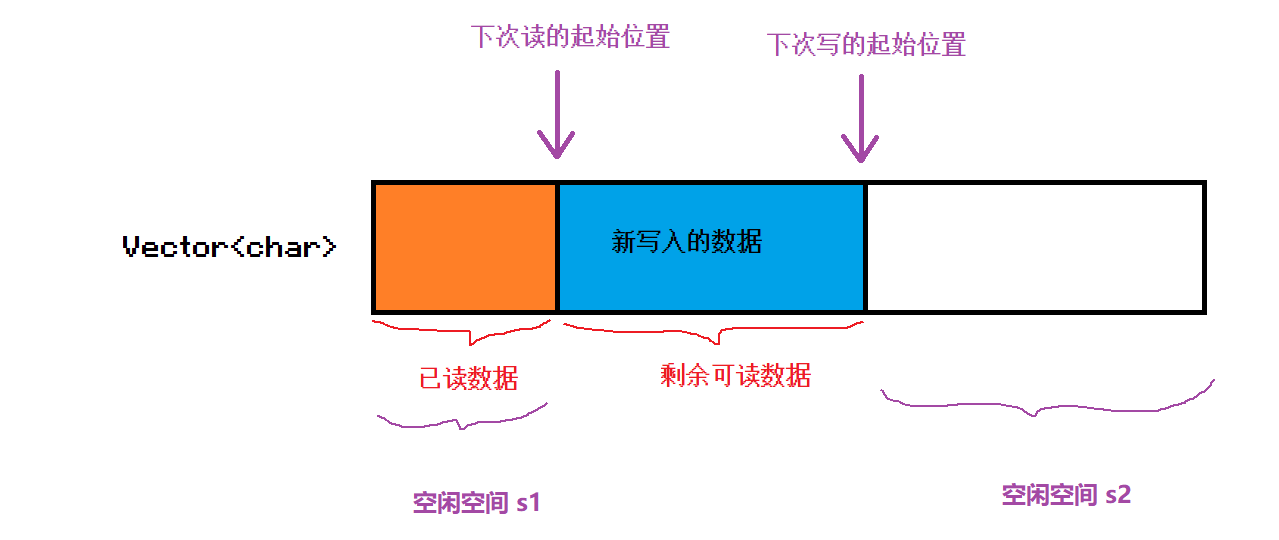
当我们进行写入的时候,如果写偏移后的空间足够,那么就直接进行写入。
如果写偏移之后的空闲空间不够,那么就需要判断,总的空闲空间是否足够。 也就是我们需要计算出总共的空闲空间。
如果总空闲空间够写入,那么我们其实并不需要进行扩容,我们只需要将可读数据部分移动到前面,把所有的剩余空间都放到后面去。
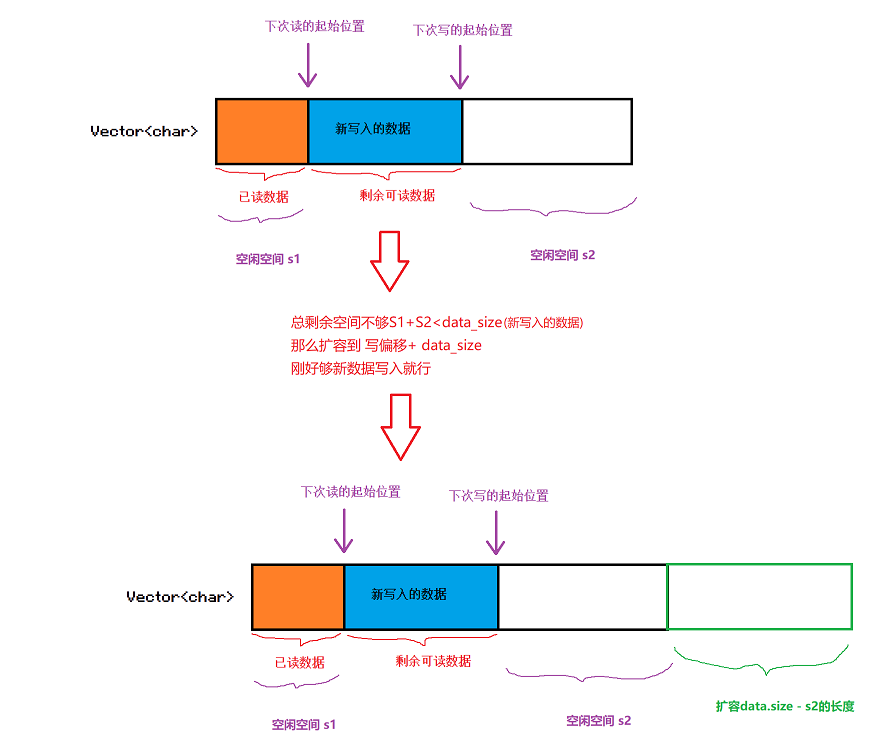
如果总空闲空间不够新数据的写入,那么这时候我们也没必要挪动数据了,直接扩容,那么扩容到多少呢? 只需要扩容到写偏移之后的空间足够写入就行了,没必要扩容太多浪费空间。
Buffer模块对外需要提供什么功能呢?其实他提供的就是各种读取和写入的接口,以及将缓冲区清空的接口。
不过为了更好的实现这些接口,我们可以再设计一些私有的接口,方便我们进行调用。
首先我们要提供读取数据和写入数据的接口,但是这种读取和写入是不进行数据删除也就是说不移动读偏移和写偏移的,严格意义上来说,这并不是真正的读和写,但是在有些场景下我们确实是需要的,就比如说我们需要判断是否足够一个报文这样的情况。
而读取和写入的时候,我们是需要获取到读起始位置和写起始位置的,那么我们也需要提供这些接口。
既然上面的接口不会移动读偏移和写偏移,那么我们也需要一些接口来移动读偏移和写偏移。
最终就是提供一些整合之后的接口,也就是读取并删除读出来的数据,以及写入数据并移动写偏移。
而读取和写入的时候,为了方便用户调用,我们也可以提供C语言的版本以及C++的版本,也就是原生的char*的版本以及string的版本。
类的设计
class Buffer
{//成员变量
private:std::vector<char> _buf; //缓冲区空间uint64_t _readerIndex; //读偏移量uint64_t _writerIndex; //写偏移量//成员函数 - 内部实现
private:char* Begin(); //迭代器的起始位置char* ReadPosition() //获取读的起始位置char* WritePosition(); //获取写的起始位置uint64_t FrontReadSize() const; //获取读偏移之前的空闲空间uint64_t BehindWriteSize() const; //获取写偏移之后的空闲空间uint64_t TotalFreeSize() const; //获取总的空闲空间void MoveReadIndex();//移动读偏移void MoveWriteIndex();//移动写偏移void EnsureWriteSize();//用来移动数据以及扩容,保证写空间足够char* FindCRLF();//查找换行符\n
public:uint64_t ReadSize() const; //获取可读数据的大小void Read(); //读取数据void Write(); //写入数据void ReadAndPop(); //读取数据并且更新读偏移void WriteAndPush(); //写入数据并且更新写偏移std::string ReadAsString(); //读取数据,返回stringvoid WriteAsString(); //写入数据std::string ReadAsStringAndPop(); //读取数据,返回string,并移动读偏移void WriteAsStringAndPush(); //写入数据,返回string,并移动写偏移std::string GetLine(); //获取一行的数据std::string GetLineAndPop(); //获取一行的数据并且更新读偏移量void Clear(); //清除缓冲区的数据
};模块实现
私有接口实现
//成员函数 - 内部实现
private: char* Begin() //迭代器的起始位置{return &(*_buffer.begin()); } char* ReadPosition()//获取读的起始位置{return Begin() + _readerIndex;} char* WritePosition() //获取写的起始位置{return Begin() + _writerIndex;}uint64_t FrontReadSize() const //获取读偏移之前的空闲空间{return _writerIndex - _readerIndex;}uint64_t BehindWriteSize() const //获取写偏移之后的空闲空间{return _buffer.size() - _writerIndex;}uint64_t TotalFreeSize() const //获取总的空闲空间{return _readerIndex + BehindWriteSize();}void MoveReadIndex(size_t len)//移动读偏移{assert(ReadSize() >= len);_readerIndex = _readerIndex + len;}void MoveWritelndex(size_t len)//移动写偏移{assert(BehindWriteSize() >= len);_writerIndex = _writerIndex + len;}void EnsureWriteSize(size_t len)//用来移动数据以及扩容,保证写空间足够{if (BehindWriteSize() >= len){return;}if (TotalFreeSize() >= len){uint64_t readsize = ReadSize();std::copy(ReadPosition(), ReadPosition() + len, Begin());_readerIndex = 0;_writerIndex = readsize;}else{_buffer.resize(_buffer.size() + len);}}char* FindCRLF(){char* pos = (char*)memchr(ReadPosition(), '\n', ReadSize());return pos;}共有接口的实现
//成员函数 - 外部实现
public:Buffer():_buffer(1024),_readerIndex(0),_writerIndex(0){}uint64_t ReadSize() //获取可读数据的大小{return _writerIndex - _readerIndex;}void Read(void* buf, size_t len) //读取数据,不改变读偏移量{assert(ReadSize() >= len);std::copy(ReadPosition(), ReadPosition() + len, (char*)buf);}void Write(const void* data, size_t len) //写入数据,不改变写偏移量{EnsureWriteSize(len);std::copy((const char*)data, (const char*)data + len, WritePosition()); //因为void*没有步长的概念 所以要强转成char*类型的}void ReadAndPop(void* buf, size_t len) //读取数据并且更新读偏移{Read(buf, len);MoveReadIndex(len);}void WriteAndPush(const void* data, size_t len) //写入数据并且更新写偏移{Write(data, len);MoveWritelndex(len);}std::string ReadAsString(size_t len){assert(ReadSize() >= len); // 确保可读取数据的大小大于等于 lenstd::string ret;ret.resize(len); // 调整字符串大小Read(&ret[0], len); // 将数据拷贝到字符串中return ret;}void WriteAsString(const string &data) //写入数据{Write(data.c_str(), data.size()); //这里的return它只是告诉编译器,当前函数已经执行完毕,可以退出并返回控制权给调用者。}std::string ReadAsStringAndPop(size_t len) //读取数据,返回string,并移动读偏移{assert(ReadSize() >= len);string ret = ReadAsString(len);MoveReadIndex(len);return ret;}void WriteAsStringAndPush(const string &data) //写入数据,返回string,并移动写偏移{WriteAsString(data);MoveWritelndex(data.size());}std::string GetLine() //获取一行的数据{char* pos = FindCRLF();if (pos == nullptr){return "";}return ReadAsString(pos - ReadPosition() + 1);}std::string GetLineAndPop() //获取一行的数据并且更新读偏移量{string str = GetLine();MoveReadIndex(str.size());return str;}void Clear() //清除缓冲区的数据{_buffer.clear();_readerIndex = 0;_writerIndex = 0;}实现过程的疑问
read和write要传入缓冲区?它们难道不知道吗?
为啥要传入这个缓冲区,是不是在实际应用中 不同的线程都会有一个缓冲区 而不是所有的线程都放在一个缓冲区里面?比如说A和B聊天 他俩有一个缓冲区 C和D聊天 他俩有一个缓冲区

copy函数的用法
std::copy(input_iterator_start, input_iterator_end, output_iterator);
- input_iterator_start:源范围的起始位置(通常是源容器或数组的 begin())。
- input_iterator_end:源范围的结束位置(通常是源容器或数组的 end())。
- output_iterator:目标范围的起始位置(目标容器的 begin())。
获取一行的返回类型为啥是string?
因为是要获取一行的字符串 所以要用string。不能用int char等
read/write是需要提供一个用户级缓冲区的
然后把数据到用户级缓冲区 或者把 用户级缓冲区的数据写入到内部中
为什么要先保存可读数据的大小

memchr函数的用法
void* memchr(const void* ptr, int value, size_t num);
参数说明:
-
ptr: 指向内存块的指针,表示要搜索的内存区域。 -
value: 要查找的字符(以int类型传递),它会被转换为unsigned char类型进行比较。通常是一个字符或者一个字节值。 -
num: 要搜索的字节数,指定了从ptr开始的内存区域的大小。
返回值:
-
如果找到指定的字符,
memchr()返回一个指向该字符在内存块中第一次出现位置的指针。 -
如果未找到指定的字符,
memchr()返回NULL。
void WriteAsString(const string &data) 为啥带引用,并且不带len呢?

void WriteAsString(const string &data)这里的返回类型为啥是void而不是string类型呢?

这里为啥要返回ret
std::string ReadAsStringAndPop(size_t len) //读取数据,返回string,并移动读偏移{assert(ReadSize() >= len);string ret = ReadAsString(len);MoveReadLndex(len);return ret;}
我的错误写法
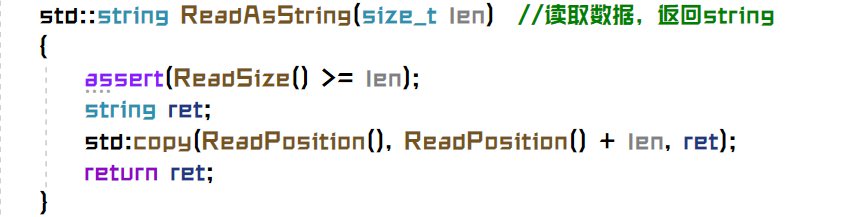

正确写法
string ReadAsString(uint64_t len)
{assert(len <= ReadAbleSize()); // 确保要读取的数据量小于等于可读数据的大小string str; // 创建一个空的字符串str.resize(len); // 调整字符串大小,以适应读取的数据// 不能使用 s_tr(),因为是 const,无法修改// 要传起始地址就要找到第一个字符取地址Read(&str[0], len); // 从缓冲区读取数据到字符串的内存中return str; // 返回读取的数据作为字符串
}

主函数
主函数实现
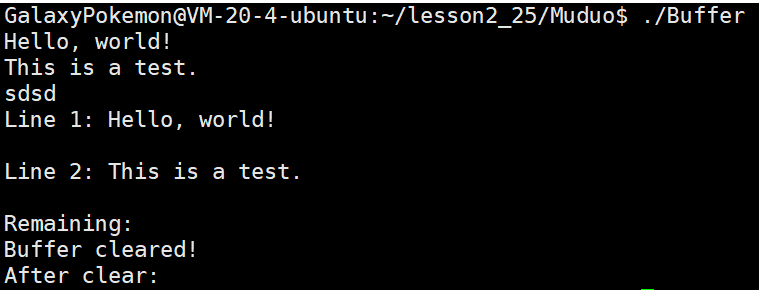
#include "Buffer.hpp"
#include <vector>
#include <iostream>
#include <string>int main() {// 创建一个 Buffer 实例Buffer buffer;// 写入数据std::string data = "Hello, world!\nThis is a test.\nsdsd";buffer.WriteAndPush(data.c_str(), data.size()); // 写入数据//读取全部数据 不更新读偏移量char bf[1024] = {0}; buffer.Read(bf,buffer.ReadSize());std::cout << bf << std::endl;// 读取并输出一行数据std::string line1 = buffer.GetLineAndPop(); // 获取第一行并更新读偏移std::cout << "Line 1: " << line1 << std::endl;// 再次读取并输出另一行数据std::string line2 = buffer.GetLineAndPop(); // 获取第二行并更新读偏移std::cout << "Line 2: " << line2 << std::endl;// 尝试读取并输出剩余数据std::string remaining = buffer.GetLineAndPop();std::cout << "Remaining: " << remaining << std::endl;// 清除缓冲区buffer.Clear();std::cout << "Buffer cleared!" << std::endl;// 检查清空后的缓冲区内容std::string afterClear = buffer.GetLineAndPop();std::cout << "After clear: " << afterClear << std::endl; // 应该是空字符串return 0;
}
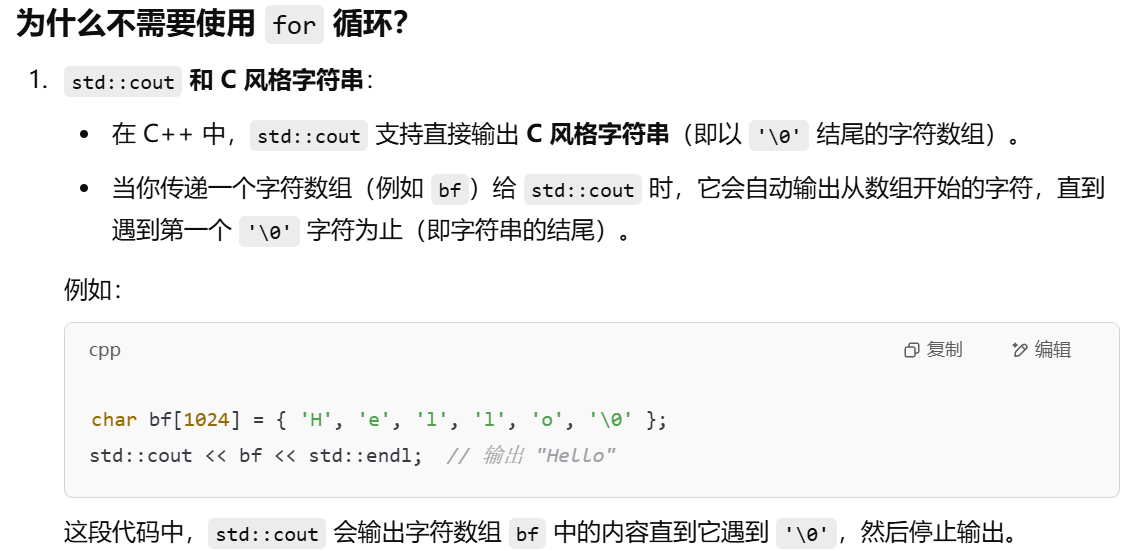
std::cout << bf << std::endl; 这里不用循环打印吗?
主函数测试