需要学习的前置知识:hadoop 可参考 sheng的学习笔记-hadoop-CSDN博客
相关网址
官网:http://hive.apache.org
文档:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
https://cwiki.apache.org/confluence/display/Hive/Home
下载:http://archive.apache.org/dist/hive
Github地址:https://github.com/apache/hive
基础知识
什么是hive
Hive是基于Hadoop的一个数据仓库(Data Aarehouse,简称数仓、DW),可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。是用于存储、分析、报告的数据系统,常用作离线数据仓库
Hive的本质是:将Hive SQL转化成MapReduce程序,其灵活性和扩展性比较好,支持UDF,自定义存储格式等;适合离线数据处理。
为啥用hive
直接用mapReduce有以下难点,所以在上面包了一层hive
- 学习成本太高
- 开发周期长,复杂度高
- mapReduce对于复杂查询开发难度大
优缺点
优点:
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手);
- 避免了去写MapReduce,减少开发人员的学习成本;
- 统一的元数据管理,可与impala/spark等共享元数据;
- 易扩展(HDFS+MapReduce:可以扩展集群规模;支持自定义函数);
- 数据的离线处理;比如:日志分析,海量结构化数据离线分析
缺点:
1、延迟较高:默认MR为执行引擎,MR延迟较高。
2、不支持雾化视图:Hive支持普通视图,不支持雾化视图。Hive不能再视图上更新、插入、删除数据。
3、不适用OLTP:暂不支持列级别的数据添加、更新、删除操作。
使用场景:
-
Hive的执行延迟比较高,因此hive常用于数据分析的,对实时性要求 不高的场合;
-
Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执 行延迟比较高。
安装
windows
别试了,我最后失败了,报错创建文件失败,估计权限问题,最好弄个docker的
下载安装包
从官网下载安装包,解压安装包到(F:\workspace\arch\hive\apache-hive-3.1.3-bin),注意路径不要有空格。
设置环境变量
新增 HIVE_HOME
F:\workspace\arch\hive\apache-hive-3.1.3-bin
改一下path ;%HIVE_HOME%\bin
处理windows的bin
解决“Windows环境中缺少Hive的执行文件和运行程序”的问题
Hive 的Hive_x.x.x_bin.tar.gz 高版本在windows 环境中缺少 Hive的执行文件和运行程序。
解决方法:
4.1、下载低版本Hive(apache-hive-2.0.0-src)
下载地址:http://archive.apache.org/dist/hive/hive-2.0.0/apache-hive-2.0.0-bin.tar.gz
或者网盘下载:https://pan.baidu.com/s/1exyrc51P4a_OJv2XHYudCw?pwd=yyds
并将bin文件替换到自己版本的Bin中
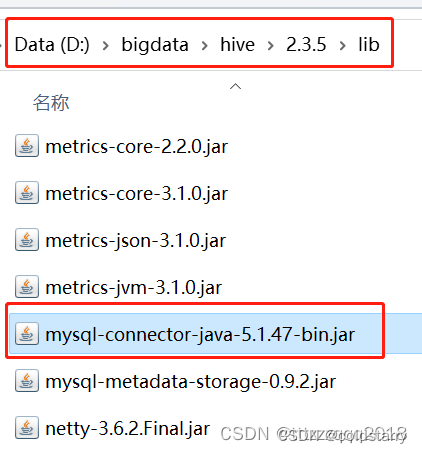
给Hive添加MySQL的jar包
下载连接MySQL的依赖jar包“mysql-connector-java-5.1.47-bin.jar”
官网下载地址:https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-5.1.47.zip
或者网盘下载:https://pan.baidu.com/s/1X6ZGyy3xNYI76nDoAjfVVA?pwd=yyds
配置文件
创建Hive配置文件(hive-site.xml、hive-env.sh、hive-log4j2.properties、hive-exec-log4j2.properties)
配置文件目录(%HIVE_HOME%\conf)有4个默认的配置文件模板拷贝成新的文件名
原文件名 拷贝后的文件名
hive-log4j.properties.template hive-log4j2.properties
hive-exec-log4j.properties.template hive-exec-log4j2.properties
hive-env.sh.template hive-env.sh
hive-default.xml.template hive-site.xml
hive-env.sh
# Set HADOOP_HOME to point to a specific hadoop install directoryHADOOP_HOME=F:\workspace\arch\hadoop\hadoop-3.4.0# Hive Configuration Directory can be controlled by:export HIVE_CONF_DIR=F:\workspace\arch\hive\apache-hive-3.1.3-bin\conf# Folder containing extra libraries required for hive compilation/execution can be controlled by:export HIVE_AUX_JARS_PATH=F:\workspace\arch\hive\apache-hive-3.1.3-bin\lib
有人这么配置的
hive-site.xml
windows的改成这样
修改后的 hive-site.xml 下载地址:百度网盘 请输入提取码
<property><name>hive.exec.local.scratchdir</name><value>D:/bigdata/hive/2.3.5/data/scratch</value><description>Local scratch space for Hive jobs</description></property><property><name>hive.server2.logging.operation.log.location</name><value>D:/bigdata/hive/2.3.5/data/op_logs</value><description>Top level directory where operation logs are stored if logging functionality is enabled</description></property><property><name>hive.downloaded.resources.dir</name><value>D:/bigdata/hive/2.3.5/data/resources/${hive.session.id}_resources</value><description>Temporary local directory for added resources in the remote file system.</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value><description>Driver class name for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value><description>Username to use against metastore database</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value><description>password to use against metastore database</description></property><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://localhost:3307/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value><description>JDBC connect string for a JDBC metastore.To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.</description></property>
linux的改成root

启动hadoop
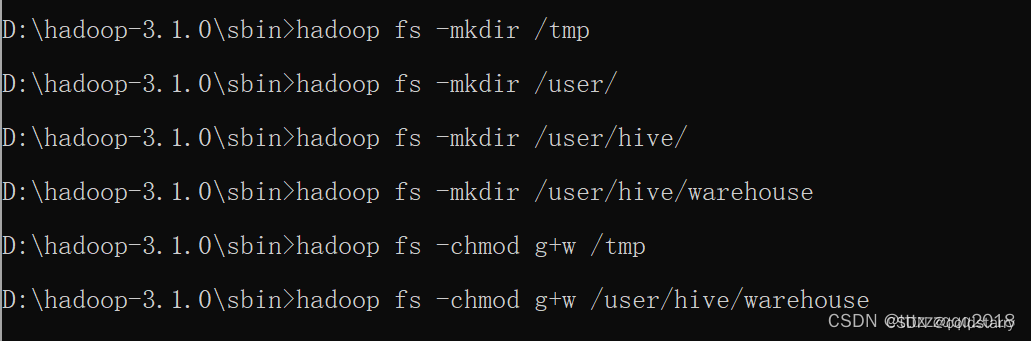
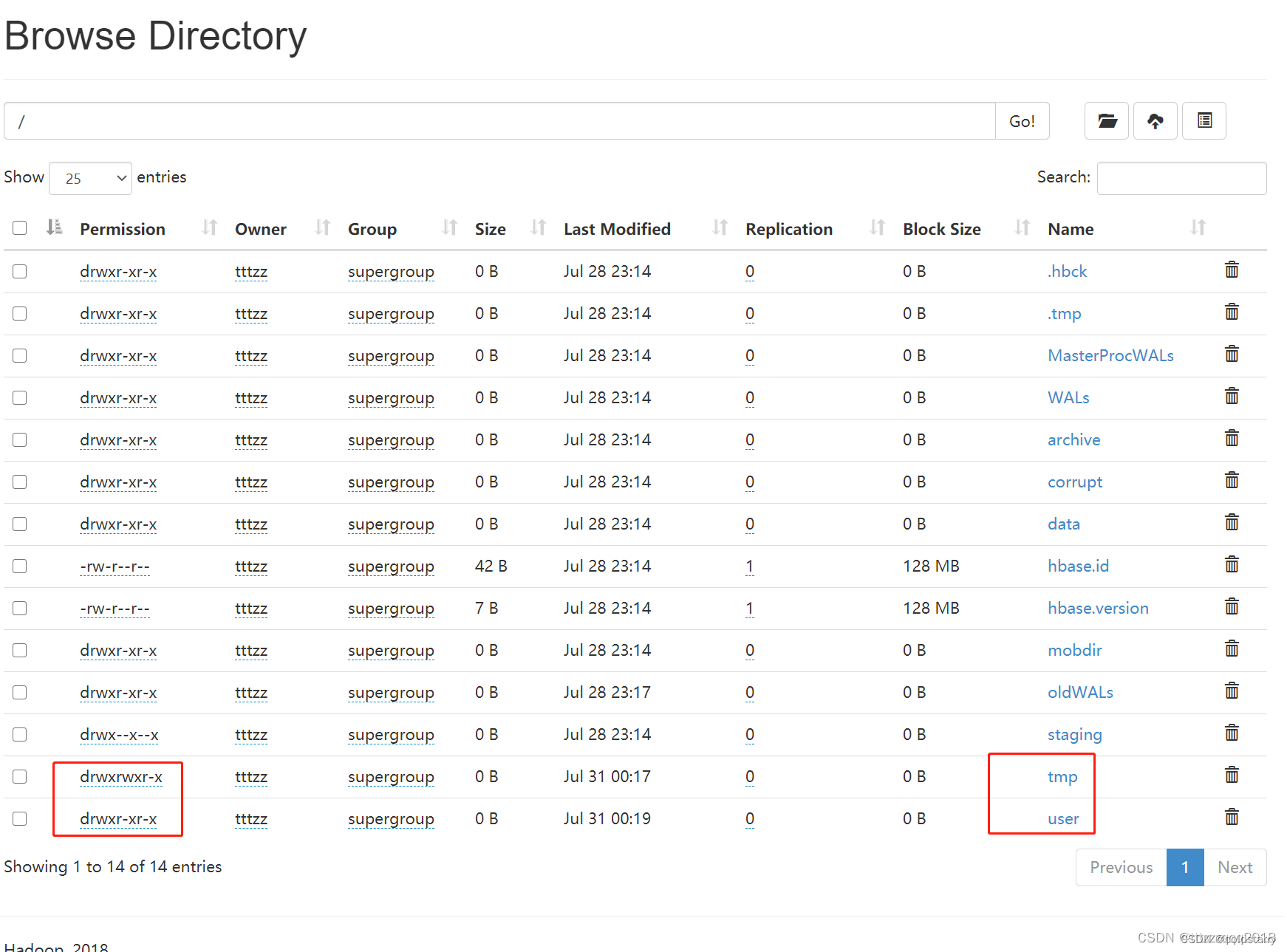
在Hadoop上创建HDFS目录并给文件夹授权(选做,可不做)
hadoop fs -mkdir /tmp
hadoop fs -mkdir /user/
hadoop fs -mkdir /user/hive/
hadoop fs -mkdir /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
启动Hive服务
在%HIVE_HOME%/bin目录下执行下面的脚本:
hive --service schematool -dbType mysql -initSchema
使用hive
数据库
创建数据库,本质是在hadoop中新增一个目录,并在mysql中增加元数据(数据库和文件的映射,数据库信息等) 。
删除数据库会在Mysql中删除对应数据,在hdfs中删除对应文件夹
默认有个default的数据库
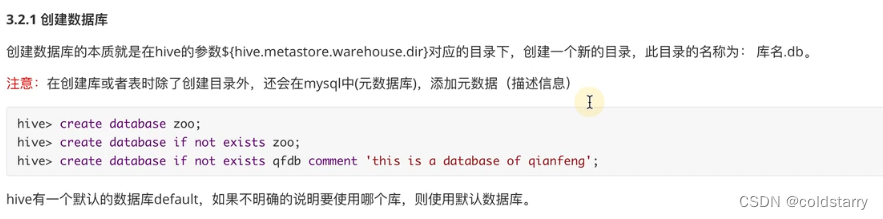
创建数据库
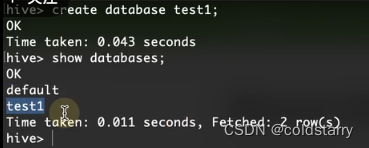
看浏览器的hive的文件路径,新增了一个test1.db的文件夹,这个数据库下新建的表都会在test1.db的文件夹内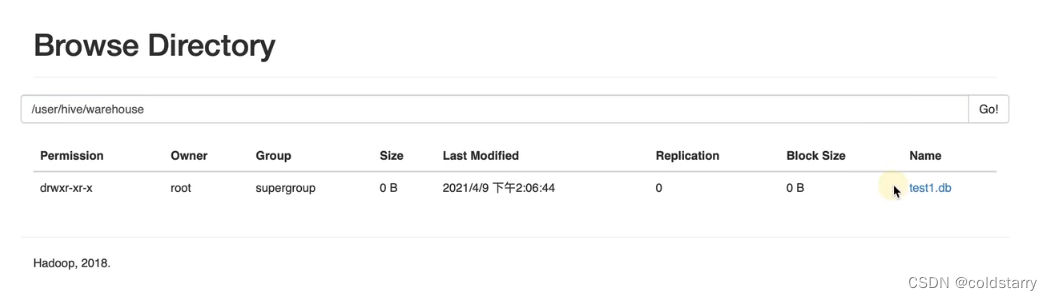
mysql记录test1数据库信息

表
创建个表,本质就是创建个目录。
不指定数据库,会创建到default数据库中,在hdfs中数据库对应文件夹创建个目录(目录名是表名),mysql进行记录映射关系和表的情况。在表名目录中的文件内容,就是这个表的数据
可以对表的字段进行增加和修改,删除

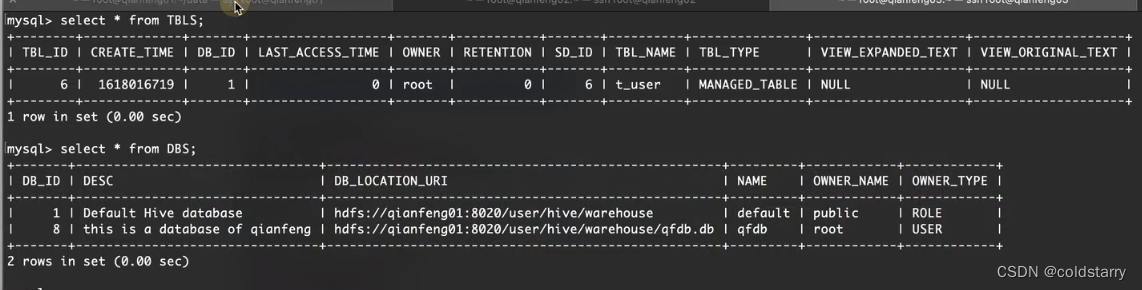
指定分割规则建表
表的实质,是hdfs的一个目录,目录中文件内容就是表的数据,文件内容可以用分隔符进行分割,比如多个字段之间的分割,多行之间的分割,在建表时可以指定分割符号,比如用逗号分割


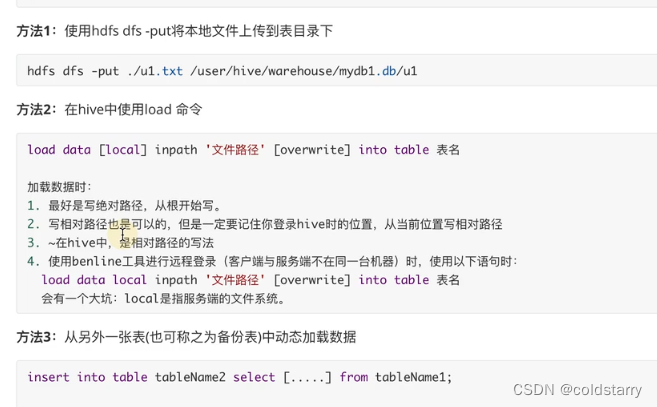
表数据导入
数据导入到表中,有3种方法
- 本地加载到hive中
- hdfs文件加载到hive中
- 用insert语句,从另一个表中加载数据
本地加载到hive中,实际就是用上传的方式,将本地文件上传到hdfs中表目录中,此处是拷贝文件
hdfs文件加载hive中,实际就是把hdfs的文件,移动到hdfs表目录中,此处是移动,原文件会没了
hive是读模式,加载时不检查数据完整性,读的时候发现数据不对,就给null值,比如给一个int类型的字段很长的数字(超过存储长度,会显示null)
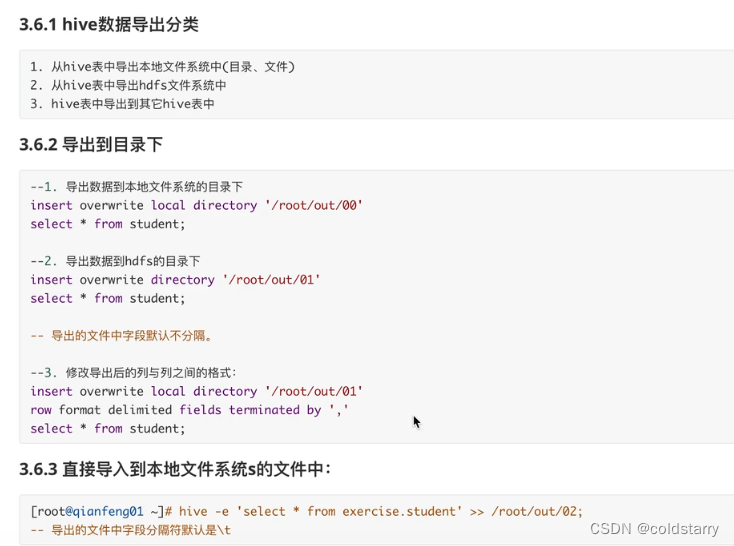
表数据导出
与导入对应,导出也分为:
- 导出到本地文件
- 导出到hdfs中
- 导出到hive其他表
实质都是对文件的移动
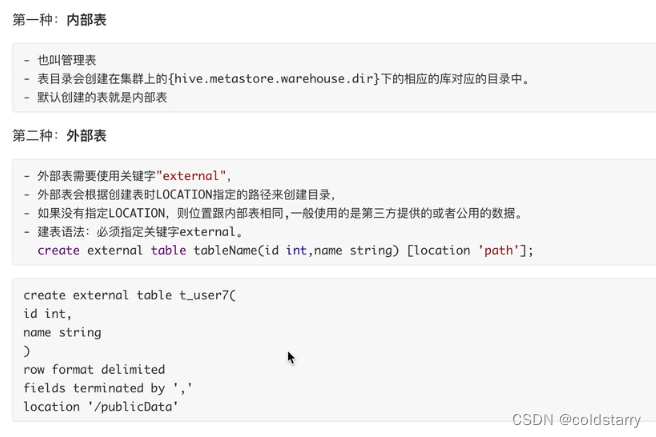
内部表和外部表
建表的时候使用关键字,可以控制是内部表还是外部表
一般使用外部表,因为外部系统源源不断把数据文件传到指定系统路径,hive读取这个系统路径(非hdfs),不需要额外动作,读取表就会有数据
内部表和外部表可以相互转换
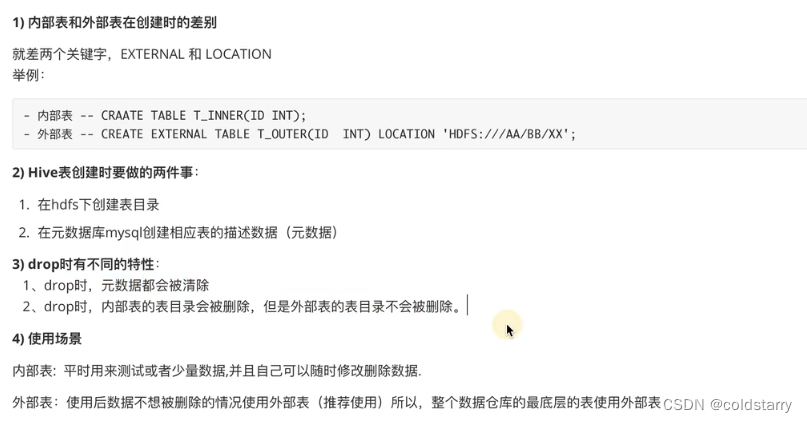
两者区别
需要注意的是,drop外部表的时候,会删除mysql内的表信息,但不会删除数据文件,因为这个文件别的系统也会用
生成数据
插入数据会触发hadoop的job,所以速度会比较慢
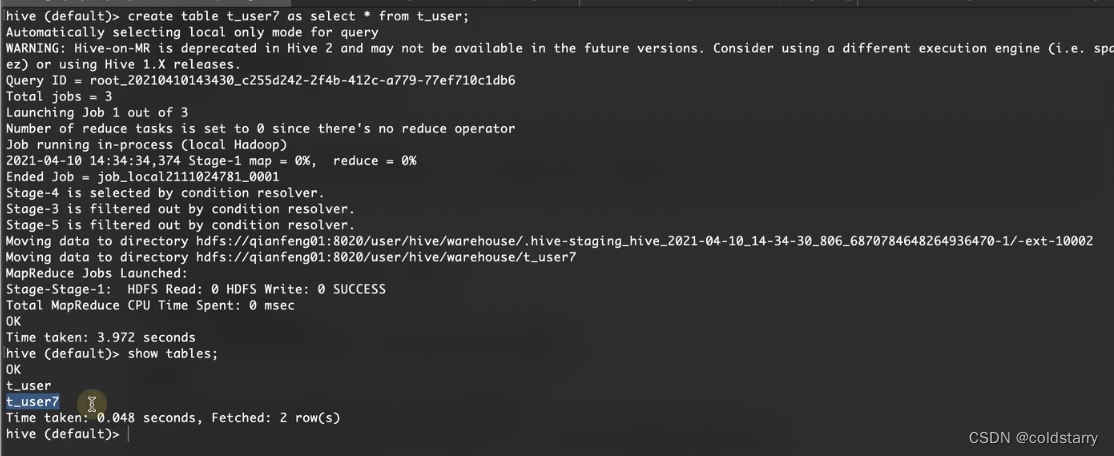
hive分区和分桶
Hive分区和分桶是优化Hive性能的两种方式,它们的区别如下:

分区
什么是分区
Hive分区是把数据按照某个属性分成不同的数据子集。
- 在Hive中,数据被存储在HDFS中,每个分区实际上对应HDFS下的一个文件夹,这个文件夹中保存了这个分区的数据。
- 因此,在Hive中使用分区,实际上是将数据按照某个属性值进行划分,然后将相同属性值的数据存储在同一个文件夹中。Hive分区的效率提升主要是因为,当进行查询操作时,只需读取与查询相关的数据分区,避免了全表扫描,节约了查询时间。
Hive分区的主要作用是:
- 提高查询效率: 使用分区对数据进行访问时,系统只需要读取和此次查询相关的分区,避免了全表扫描,从而显著提高查询效率。
- 降低存储成本: 分区可以更加方便的删除过期数据,减少不必要的存储。
如何创建分区表
在Hive中,可以使用PARTITIONED BY关键字来创建分区表。以下是创建分区表的示例:
CREATE TABLE my_table (col1 INT,col2 STRING
)
PARTITIONED BY (dt STRING, country STRING);
分桶
什么是分桶
Hive分桶是将数据划分为若干个存储文件,并规定存储文件的数量。
- Hive分桶的实现原理是将数据按照某个字段值分成若干桶,并将相同字段值的数据放到同一个桶中。在存储数据时,桶内的数据会被写入到对应数量的文件中,最终形成多个文件。
- Hive分桶主要是为了提高分布式查询的效率。它能够通过将数据划分为若干数据块来将大量数据分发到多个节点,使得数据均衡分布到多个机器上处理。这样分发到不同节点的数据可以在本地进行处理,避免了数据的传输和网络带宽的浪费,同时提高了查询效率。
分桶的主要作用是:
- 数据聚合: 分桶可以使得数据被分成较小的存储单元,提高了数据统计和聚合的效率。
- 均衡负载: 数据经过分桶后更容易实现均衡负载,数据可以分发到多个节点中,提高了查询效率。
如何创建分桶表
在Hive中,可以使用CLUSTERED BY和SORTED BY关键字来创建分桶表。以下是创建分桶表的示例
CREATE TABLE my_bucketed_table (col1 INT,col2 STRING
)
CLUSTERED BY (col1) INTO 4 BUCKETS
SORTED BY (col2);
上述示例中,my_bucketed_table表按照col1列进行分桶,分为4个桶,并按照col2列进行排序
分区和分桶对比
综上所述,分区和分桶的区别在于其提供的性能优化方向不同。分区适用于对于数据常常进行的聚合查询数据分析,而分桶适用于对于数据的均衡负载、高效聚合等方面的性能优化。当数据量较大、查询效率比较低时,使用分区和分桶可以有效优化性能。分区主要关注数据的分区和存储,而分桶则重点考虑数据的分布以及查询效率。
hive原理
架构图
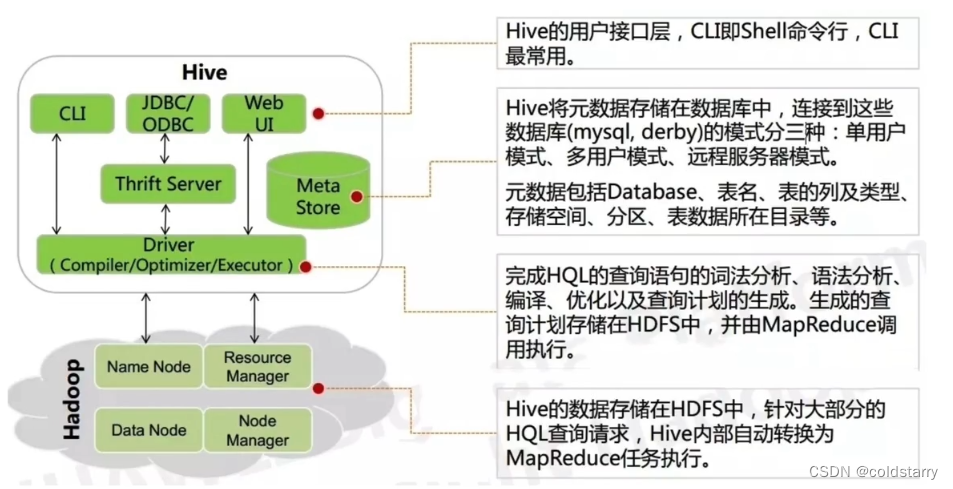

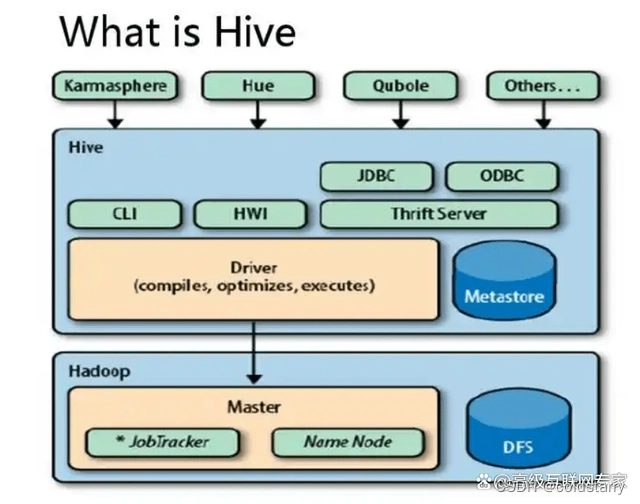
上面的图比较丑,加一个图,但组件是干啥的,看上个图
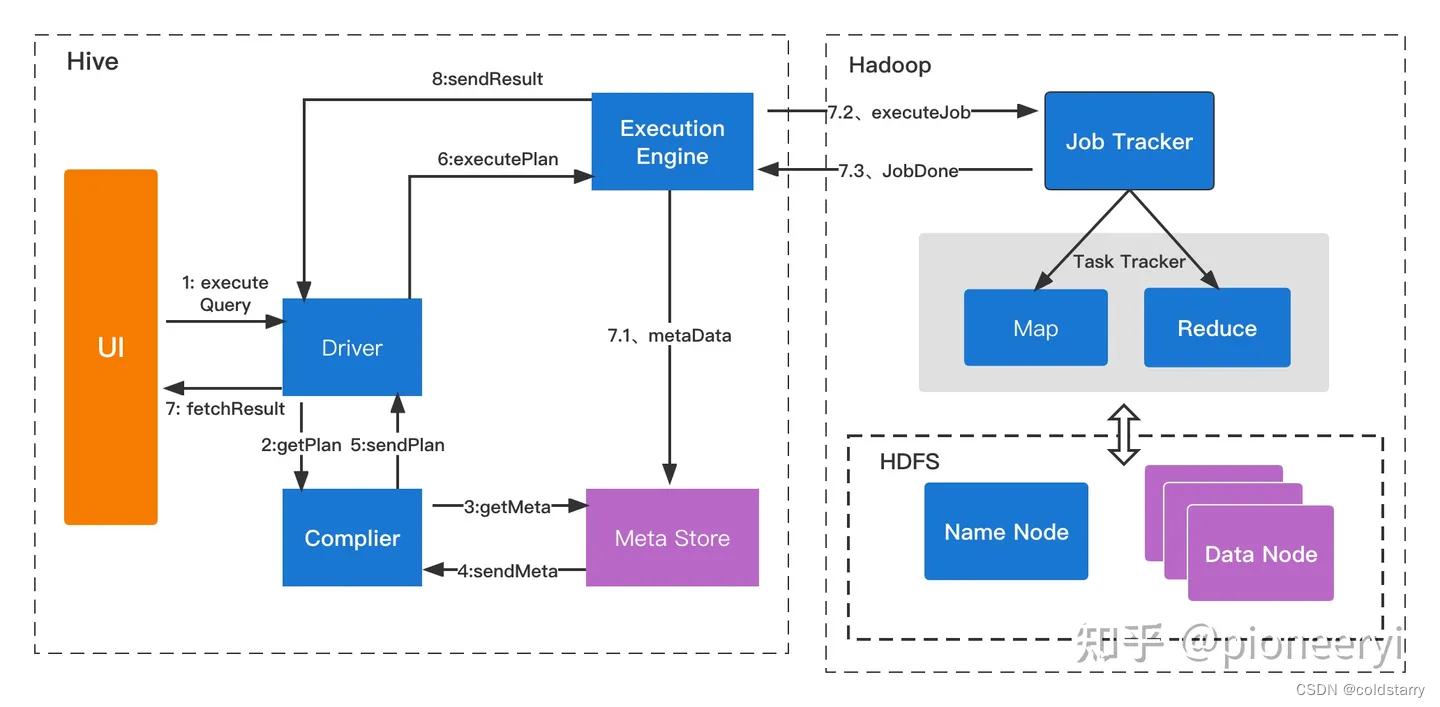
工作原理
序列化和反序列化
定义
1,序列化是对象转化为字节序列的过程;把内存数据转换成文件,insert就是序列化
2,反序列化是字节码恢复为对象的过程;把文件内容转换成内存数据,select就是反序列化
建表语句
用建表语句说明序列化,想要序列化,可以用以下语句建表
create table t1(
id int,
name string
)
row format delimited
fields terminated by ','
;0,7369,SMITH,CLERK,7902,1980-12-17,800,null,20序列化要求制定换行策略和字段间分割策略,即:用什么策略区分是2行数据,用什么策略区分是2个字段的值(而不是一个字段的值)
序列化策略
row format: 用于指定使用什么策略做解析
delimited : 表示使用 org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe 进行行的内容解析,如果不写,默认的就是LazySimpleSerDe这个策略
区分字段策略
一个类用于从上面读到的记录中切分出一个一个的字段(根据指定字符作为分隔符,区分行数据和列数据)
fields terminated by: 表示用什么字符进行字段之间的分隔
lines terminated by: 表示用什么字符进行行之间的分隔
序列化是Hive----->Hadoop, 反序列化是hadoop------>Hive 。本质的区别是数据存储的形式不同
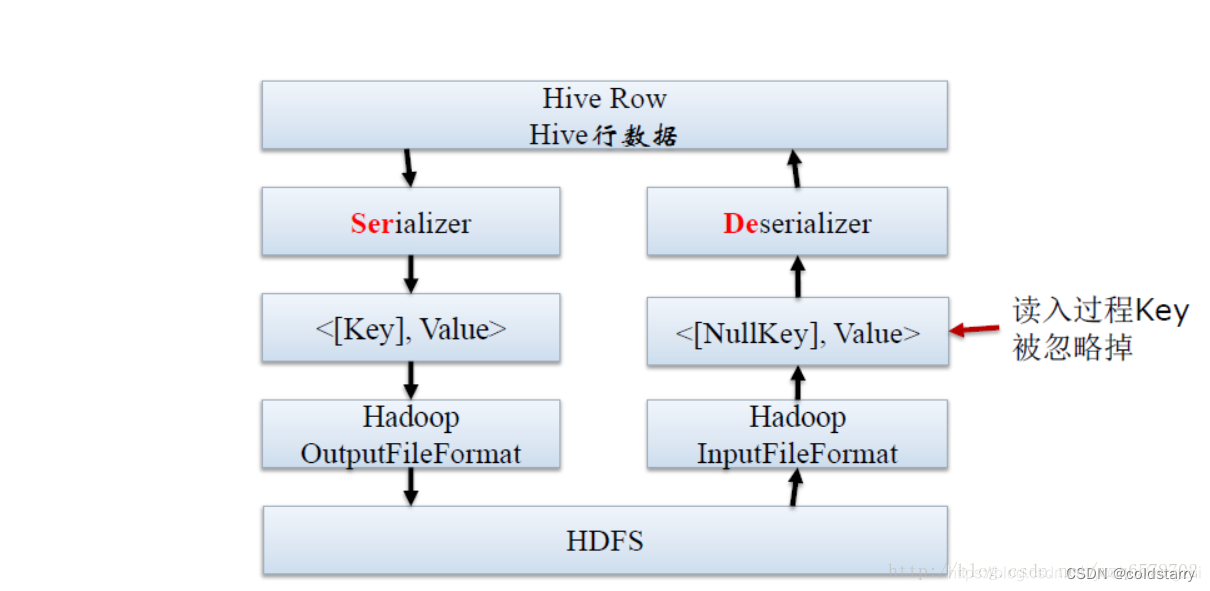
Serde
定义
- SerDe是“Serializer and Deserializer”的简称。
- Hive使用SerDe(和FileFormat)来读/写表的Row对象。
- HDFS文件-> InputFileFormat -> <key,value> -> Deserializer -> Row对象
- Row对象->Serializer -> <key,value> -> OutputFileFormat -> HDFS文件
注意,“key”部分在读取时会被忽略,而在写入时始终是常数。基本上Row对象存储在“值”中。
注意,org.apache.hadoop.hive.serde是一个过时的SerDe库。使用最新版本的org.apache.hadoop.hive.serde2。
默认策略
如果不指明,默认的策略是LazySimpleSerDe
支持的策略:

自定义序列化
-
RegexSerDe(正则化)
CREATE TABLE apachelog (host STRING,identity STRING,user STRING,time STRING,request STRING,status STRING,size STRING,referer STRING,agent STRING) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ("input.regex" = "([^]*) ([^]*) ([^]*) (-|\\[^\\]*\\]) ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\".*\") ([^ \"]*|\".*\"))?" ) STORED AS TEXTFILE; -
JsonSerDe
ADD JAR /usr/lib/hive-hcatalog/lib/hive-hcatalog-core.jar;CREATE TABLE my_table(a string, b bigint, ...) ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' STORED AS TEXTFILE; -
CSVSerDe
CREATE TABLE my_table(a string, b string, ...) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ("separatorChar" = "\t","quoteChar" = "'","escapeChar" = "\\" ) STORED AS TEXTFILE;
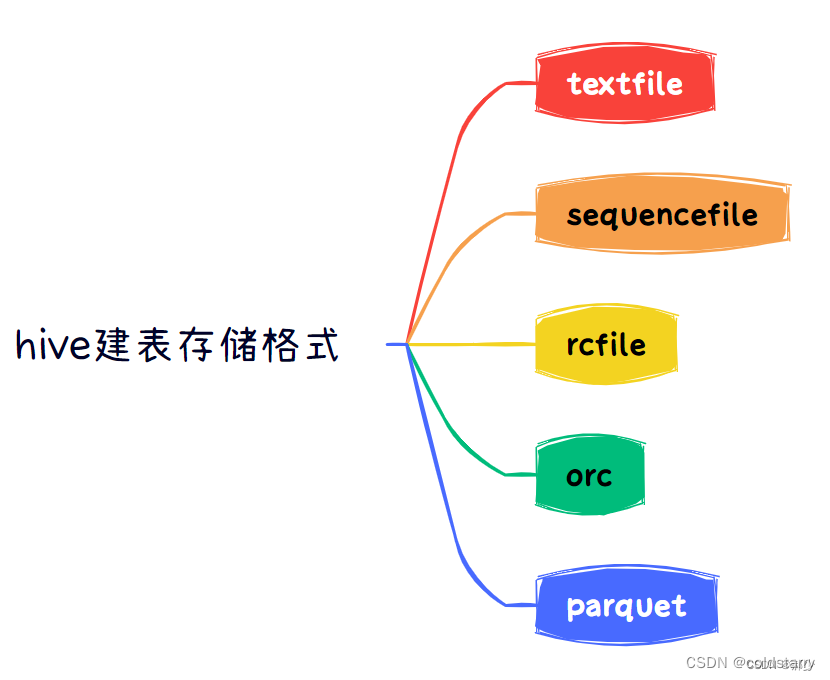
存储格式
一般情况下hive在创建表时默认的存储格式是textfile,hive常用的存储格式有五种,textfile、sequencefile、rcfile、orc、parquet。
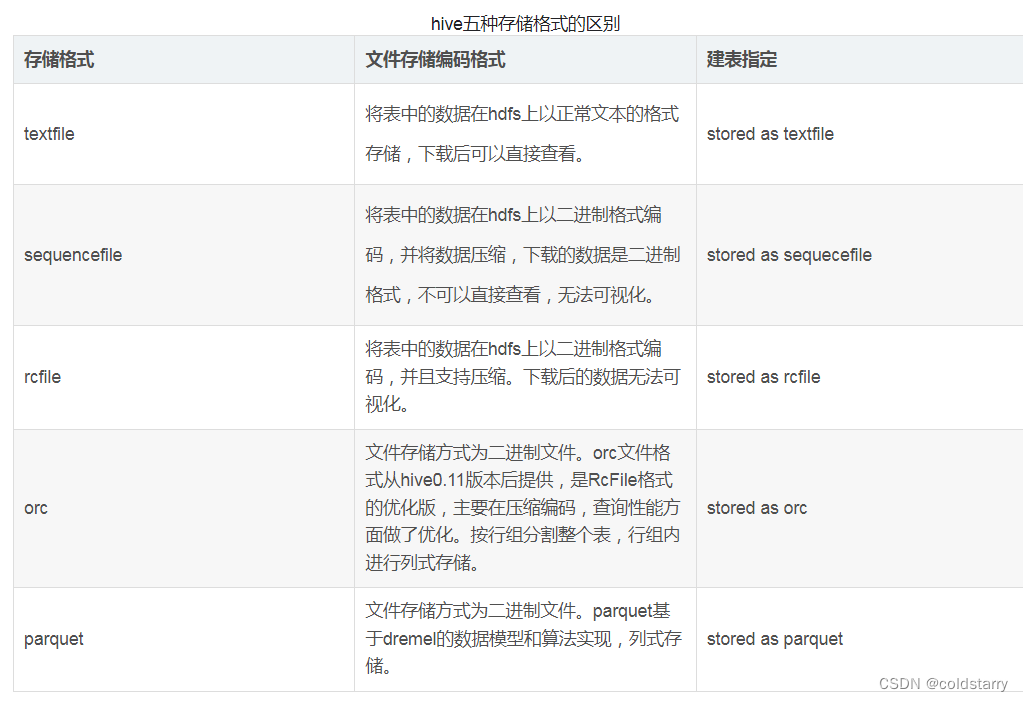
textfile利弊:
- 基于行存,每一行就是一条记录。
- 可以使用任意的分隔符进行分割。
- 无压缩,造成存储空间大。
sequencefile利弊:
- 基于行存储。
- sequencefile存储格有压缩,存储空间小,有利于优化磁盘和I/O性能。
- 同时支持文件切割分片,提供了三种压缩方式:none,record,block(块级别压缩效率跟高).默认是record(记录)。
rcfile利弊:
- 行列混合的存储格式,基于列存储。
- 因为基于列存储,列值重复多,所以压缩效率高。
- 磁盘存储空间小,io小。
orc利弊:
- 具有很高的压缩比,且可切分;由于压缩比高,在查询时输入的数据量小,使用的task减少,所以提升了数据查询速度和处理性能。每个task只输出单个文件,减少了namenode的负载压力。
- 在ORC文件中会对每一个字段建立一个轻量级的索引,如:row group index、bloom filter index等,可以用于where条件过滤。
- 查询速度比rcfile快;支持复杂的数据类型;
- 无法可视化展示数据;读写时需要消耗额外的CPU资源用于压缩和解压缩,但消耗较少;
- 对schema演化支持较差;
parquet利弊:
- 具有高效压缩和编码,是使用时有更少的IO取出所需数据,速度比ORC快,其他方面类似于ORC。
- 不支持update和ACID。
- 不支持可视化展示数据。
参考文章
02 Hive - Hive的架构与工作原理_哔哩哔哩_bilibili
如何通俗地理解Hive的工作原理? - 知乎
快速了解下Hive基本原理 - 知乎
Windows下安装Hive(包安装成功)_windows安装hive-CSDN博客
百度安全验证
https://www.cnblogs.com/halberd-lee/p/12990357.html
https://download.csdn.net/blog/column/9122766/126776080