一 关于4分的概念
1.1 db中4分的概念
分表:就是把一张表按一定的规则分解成N个具有独立存储空间的实体表。系统读写时需要根据定义好的规则得到对应的表名,然后操作它。分表是将大表水平拆分为多个较小的表,可以存储在同一个数据库实例或多个实例中,注重提高查询性能和管理方便性。
分库:分库是指在表数量不变的情况下对库进行切分。如数据库A 中存放了 user和 order两张表,分库后user表放到 database A,order表放到 database B。分库是将数据水平拆分到多个独立的数据库实例中,每个库存储部分数据,注重高扩展性和故障隔离性。
分区:就是把一张表的数据分成N个区块,在逻辑上看最终只是一张表,但底层是由N个物理区块组成的。分区并不是生成新的数据表,而是将表的数据均衡分摊到不同的硬盘,系统或是不同服务器存储介子中,实际上还是一张表。分区可以做到将表的数据均衡到不同的地方,提高数据检索的效率,降低数据库的频繁IO压力值。分区是在单个数据库实例中将大表按行拆分为多个分区,主要用于提高单实例的查询性能和管理方便性。分区不能跨越多个数据库实例,物理扩容只能在单机上扩容。
数据分片:数据库分片是一种水平扩展技术,通过把数据切分成若干部分,然后将这些部分分散存储在多个数据库服务器上。这些被切分的数据部分称为“分片”,每个分片代表整个数据集的一部分。把所有分片合起来,就构成了完整的数据集,且每条数据仅存储在一个分片中。对数据库进行分区的常见策略是基于范围、基于哈希和基于目录的分片。分片注重扩展性,通过增加分片节点来扩展系统,如通过多个服务器节点扩容。
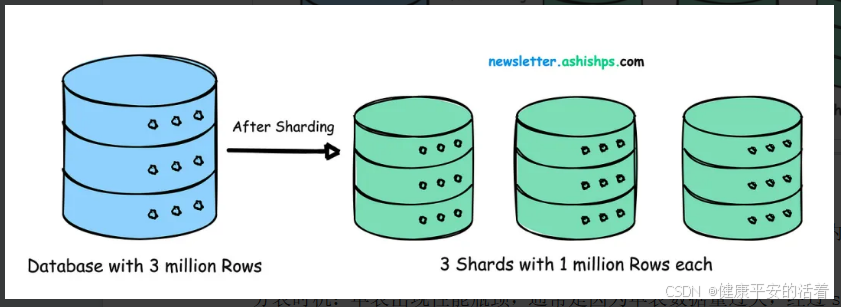
1.2 分表&分库&分区&分片的划分时机
分库时机:单库出现性能瓶颈,如磁盘空间不足,cpu压力过大,内存不足无法扩容,导致读写性能瓶颈
分表时机:单表出现性能瓶颈,通常是因为单表数据量过大,经过sql优化,还是读写性能较慢,以及涉及到当频繁插入或者联合查询时,速度变慢。可考虑分表。
分区时机:数据量大,经过sql优化,查询还是很慢,对数据的操作往往只是一部分,可考虑分区
数据分片:在分布式存储系统中,面对高流量与大数据量,需要将数据分散到多台设备。数据分片(Sharding)就是用来确定数据在多台存储设备上分布的技术。
1.3. 分区与分表的区别与联系
分区和分表的目的都是减少数据库的负担,提高表的增删改查效率。
分区只是一张表中的数据的存储位置发生改变,分表是将一张表分成多张表。
当访问量大,且表数据比较大时,两种方式可以互相配合使用。
当访问量不大,但表数据比较多时,可以只进行分区。
数据库分区、分表、分库、分片
1.4. 分区与分表的区别与联系
数据库分片通过将数据分割并分布到不同的数据库中以实现可扩展性,分区则在单个数据库内组织数据以实现高效管理和访问。两者都旨在提高数据库性能,只是实现方式不同。
尽管分片提供了一种强大的方法来处理大规模数据和高事务量,但它并不是一劳永逸的解决方案。TiDB支持自动分片的分布式SQL 数据库,提供了一个理想的解决方案。它不仅能够应对规模的缩放挑战,还能够处理分片带来的复杂性,同时在处理大量数据时保持卓越的性能。
1.5.分片的优缺点
优点:
高性能:通过将数据分布在多个节点上,分片可以显著减少任何单个服务器上的负载,从而加快查询执行速度并提高整体系统性能。
1.6.分片的策略
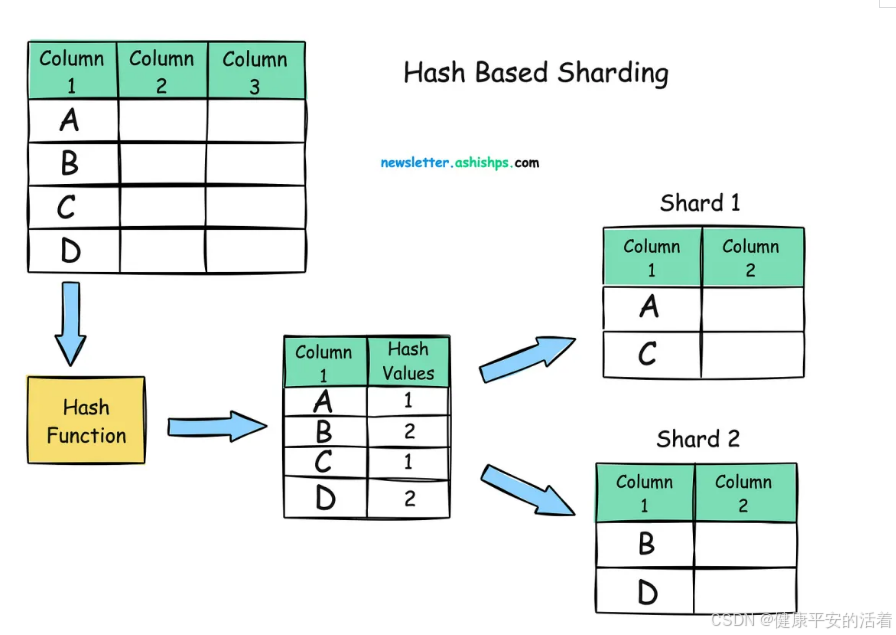
基于哈希的分片:使用哈希函数分发数据,将数据映射到特定的分片。
示例:确定用户的分片号,将用户均匀分布在 2 个分片上。 Hash(user_id) % 2
基于范围的分片:数据根据一系列值(例如日期或数字)分布。
示例:分片 1 包含 ID 从 1 到 10000 的记录,分片 2 包含 ID 从 10001 到 20000 的记录,依此类推。
基于地理位置的分片:数据根据地理位置分布。
示例:分片 1 服务于北美用户,分片 2 服务于欧洲用户,分片 3 服务于亚洲用户。基于目录的分片:维护一个查找表,将特定的键直接映射到特定的分片。

系统设计:什么是数据库分片?
https://mp.weixin.qq.com/s/lubojG2Fh_ZnV3kjDHDimQ
https://zhuanlan.zhihu.com/p/605884141
https://mp.weixin.qq.com/s/GWaHRWbVPyHYnThFfGwvYA