
本文字数:5263;估计阅读时间:14 分钟
作者:Alexander Kuzmenkov
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发

ClickHouse 的一大优势在于其速度非常快,在很多情况下可以将硬件性能发挥到理论极限。许多独立的基准测试,如这个测试,都证实了这一点。其速度源于正确的架构选择和算法优化,并进行了一些独特的优化。在我们的网站上可以找到这些因素的概述,或者可以观看 ClickHouse 首席开发者 Alexey Milovidov 的演讲《ClickHouse 性能优化的秘密》。但这只是一个静态的“现状”。软件是一个不断变化的有机体,而 ClickHouse 的变化速度非常快——为了解释这一规模,仅在 2021 年 7 月,我们就合并了由 60 位不同作者提交的 319 个拉取请求(实时统计数据在这里)。如果没有积极维护,性能等任何特性都会在持续变化中丧失。因此,我们必须有一些流程来确保 ClickHouse 始终保持快速。
测量和比较性能
首先,我们如何知道它是否快速?我们进行了大量的基准测试,涵盖了各种类型。最基本的基准测试是一种微基准测试,这种测试不使用完整的服务器代码,而是单独测试特定的算法。我们用它们来选择某些聚合函数的最佳内部循环,或测试各种哈希表布局等。例如,当我们发现一个竞争数据库引擎使用 sum 聚合函数完成查询的速度是我们的两倍时,我们测试了几十种 sum 的实现,最终找到了性能最佳的(参见关于此的演讲,俄语)。但仅仅测试一个特定的算法并不足以说明整个查询的工作情况。我们还必须对整个查询进行端到端的测量,通常使用真实的生产数据,因为数据的特性(如值的基数和分布)对性能有很大影响。目前,我们大约有 3000 个端到端的测试查询,组织成大约 200 个测试。许多测试使用真实的数据集,例如 Yandex.Metrica 的生产数据,通过 clickhouse-obfuscator 进行混淆,如此处所述。
微基准测试通常由开发人员在编写代码时运行,但手动运行整个端到端测试套件来检查每次更改是不实际的。我们使用一个自动化系统作为持续集成检查的一部分,为每个拉取请求执行此操作。该系统测量拉取请求的代码更改是否影响性能、影响了哪些查询类型以及影响程度,如果出现性能回归,会提醒开发人员。以下是典型报告的样子。
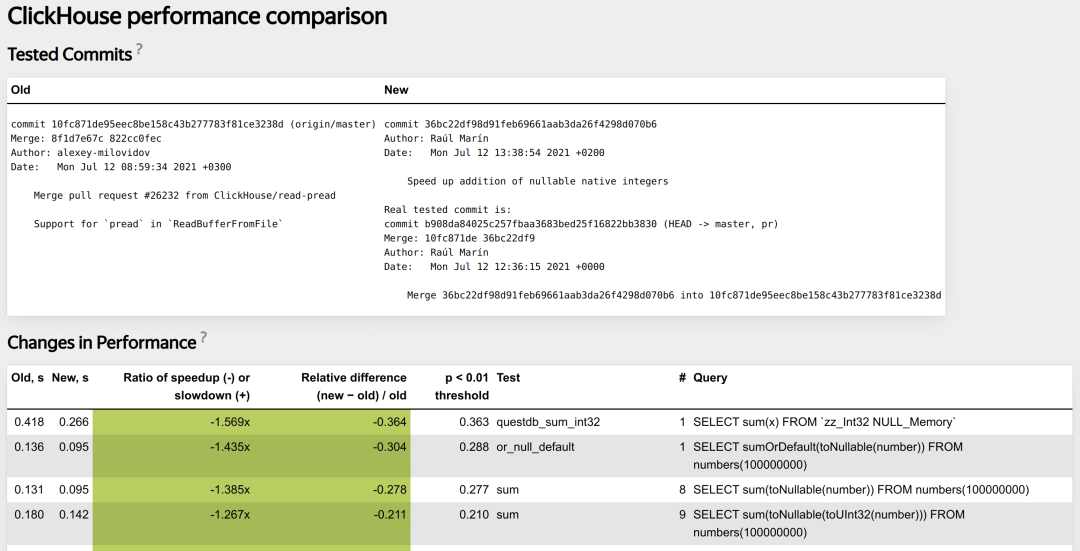
在讨论“性能变化”之前,我们首先要测量性能。单个查询最直观的度量方式是耗时。耗时容易受到随机变化的影响,因此我们必须进行多次测量并取平均值。从应用程序的角度来看,最关注的统计数据是最大值。我们希望保证在 ClickHouse 上构建的分析仪表板响应迅速。然而,由于随机因素(如突发的磁盘负载峰值或网络延迟),查询时间几乎可以无限增长,因此使用最大值是不实际的。最小值也具有参考意义,因为它代表理论上的最快速度。但如果只看最小值,我们会忽略一些查询运行缓慢的情况(例如某些缓存中的边界效应)。因此,我们折中选择中位数,它是一种对离群值敏感且稳定的统计数据。
测量性能后,我们如何确定其发生了变化?由于各种随机和系统因素,查询时间总是在漂移,数值总是变化,但关键在于这种变化是否有意义。如果我们有一个旧版本和一个新版本的服务器,它们是否会 consistently 为该查询提供不同的结果,还是只是偶然的?为此,我们需要采用某种统计方法。这些方法的核心思想是将观察值与参考分布进行比较,判断观察值是否合理地属于该分布。如果不能,则意味着补丁服务器的性能特性确实不同。
选择参考分布是性能测试的起点。一种获取参考分布的方法是建立一个数学模型。这对于简单的过程(如固定次数的掷硬币)效果很好。我们可以分析推导出正面次数符合二项分布,并在给定显著性水平下计算出其置信区间。如果观察到的正面次数不在这个区间内,可以推断硬币存在偏差。然而,从基础原理出发对查询执行进行建模过于复杂。我们最多能做的是利用硬件能力估算查询的理论最快运行速度,并努力实现这个吞吐量。
对于复杂而难以建模的过程,一种实际的选择是利用相同过程的历史数据。我们曾经为 ClickHouse 使用这种方法。对于每次提交,我们测量每个测试查询的运行时间并将其存入数据库。我们可以将补丁服务器的性能与这些历史参考值进行比较,绘制随时间变化的性能图表等。然而,这种方法的主要问题是环境引起的系统误差。例如,性能测试任务可能会在硬盘损坏的机器上运行,或者 atop 更新到会减慢内核调用速度的版本。这就是为什么我们现在采用另一种方法。
我们在同一台机器上同时运行参考版本和测试版本的服务器进程,逐一在每个服务器上运行测试查询。这样可以消除大部分系统误差,因为两个服务器受到的环境影响相同。然后我们比较参考服务器和测试服务器的结果,判断它们是否一致。比较两个样本的分布本身就是一个非常有趣的问题。我们使用非参数 bootstrap 方法构建中位数查询运行时间差异的随机分布。该方法在 [1] 中有详细描述,他们用它来研究改变肥料配方对番茄产量的影响。ClickHouse 和番茄差别不大,只是我们检查的是代码变更对性能的影响。
这种方法最终得出一个阈值 T:即使没有变化时,我们观察到的旧服务器和新服务器之间中位数查询运行时间的最大差异。然后,我们有一个基于这个阈值 T 和测量的中位数差异 D 的简单决策协议:
-
abs(D) <= T — 变化在统计上不显著,
-
abs(D) <= 5% — 变化太小,不重要,
-
abs(T) >= 10% — 测试查询的运行时间方差过大,导致灵敏度低,
-
最后,abs(D) >= T 且 abs(D) >= 5% — 存在统计上显著且重要的变化。
最有趣的是不稳定的查询(3)。即使在相同版本的服务器上,运行时间也显著变化,这意味着我们无法检测到性能变化,因为这些变化会被噪音掩盖。这类查询最难调试,因为没有直接的方法比较“好”服务器和“坏”服务器。这个话题值得另写一篇文章,我们将在下一篇文章中探讨。现在,让我们考虑理想情况(4)。这是系统旨在捕捉的实际且显著的性能变化。接下来我们该怎么做?
理解变化背后的原因
代码性能分析通常从使用分析器开始。在 Linux 上,你可以使用 perf,这是一种采样分析器,周期性地收集进程的堆栈跟踪,让你看到程序花费时间最多的地方。在 ClickHouse 中,我们有一个内置的采样分析器,它将结果保存到系统表中,因此不需要外部工具。可以按照文档说明通过传递设置来为所有查询或特定查询启用它。默认情况下是启用的,因此如果你使用的是最新版本的 ClickHouse,你已经拥有了生产服务器负载的综合分析。为了可视化这些数据,我们可以使用一个常用脚本来生成火焰图:
clickhouse-client -q "SELECTarrayStringConcat(arrayMap(x -> concat(splitByChar('/', addressToLine(x))[-1],'#', demangle(addressToSymbol(x))),trace),';') AS stack,count(*) AS samples
FROM system.trace_log
WHERE trace_type = 'Real'
AND query_id = '4aac5305-b27f-4a5a-91c3-61c0cf52ec2a'
GROUP BY trace" \
| flamegraph.pl作为一个例子,让我们看一下之前提到的测试运行。这个拉取请求旨在加速可为空整数类型的 sum 聚合函数。我们来看一下测试“sum”的查询 #8:SELECT sum(toNullable(number)) FROM numbers(100000000)。测试系统报告其性能提高了 38.5%,并为其生成了一个差异火焰图,显示了各个函数的相对时间分布。我们可以看到计算 sum 的函数 DB::AggregateFunctionSumData::addManyNotNull<unsigned long>的执行时间减少了 15%。
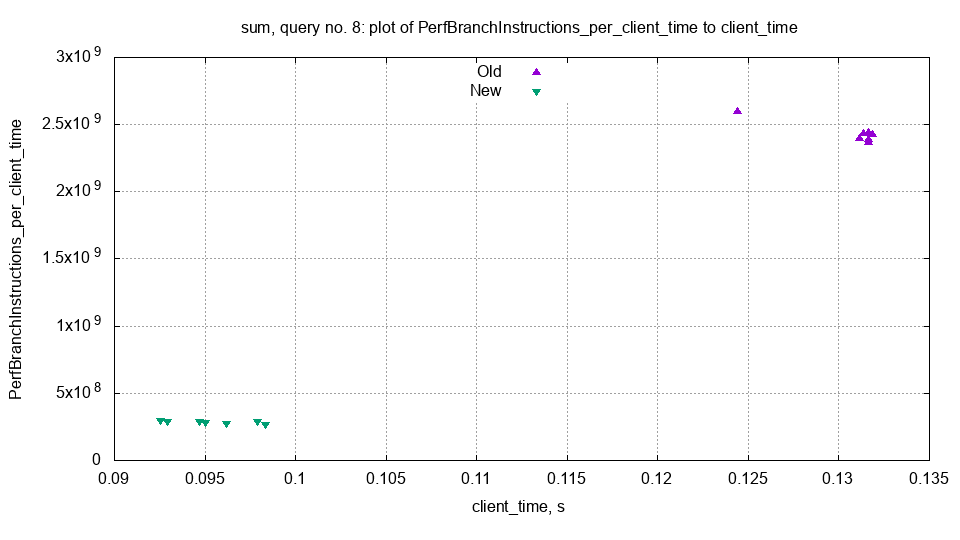
为了进一步了解性能变化的原因,我们可以检查旧服务器和新服务器之间各种查询指标的变化。这包括 system.query_log.ProfileEvents 中的所有指标,如 SelectedRows 和 RealTimeMicroseconds。ClickHouse 还使用 Linux 的 perf_event_open API 跟踪硬件 CPU 指标,例如分支或缓存未命中的次数。下载测试输出归档文件后,我们可以用一个简单的脚本生成这些指标的统计数据和图表。
该图显示了旧服务器和新服务器每秒执行的分支指令数量。我们可以看到分支指令的数量显著减少,这可能解释了性能差异。这个拉取请求删除了一些 if 语句并用乘法替换,因此这一解释是合理的。
虽然并行比较能有效减少系统误差,但历史数据在发现性能回归的引入点或调查不稳定的测试查询时仍然非常有价值。这就是为什么我们将所有测试结果保存到 ClickHouse 数据库中。让我们再看一下 sum 测试的查询 #8。我们可以通过在实时 ClickHouse CI 数据库中运行以下 SQL 查询来构建性能变化的历史记录。打开链接并运行查询,查看结果。测试历史中共有三次显著的性能变化。最近的一次是我们提到的 PR 带来的加速。第二次加速与完全切换到 clang 11 有关。有趣的是,还有一个 PR 引入了一次小幅减速,该 PR 原本是为了加速。
可用性考虑
无论内部工作原理如何,测试系统必须在开发过程中实际可用。首先,误报率应尽可能低。误报的调查成本很高,如果误报频繁发生,开发人员会认为测试不可靠,并倾向于忽略真实的正报。测试还必须提供简洁的报告,使问题一目了然。在这方面我们并未完全成功。这个测试有更多的失败模式,而不仅仅是功能测试,更糟糕的是,这些失败有些是定量的,而不是二元的。许多复杂性是本质上的,我们试图通过提供良好的文档并从报告页面直接链接到相关部分来缓解这一问题。另一个重要的是,用户必须能够在事后调查有问题的查询,而不必再次在本地运行。这就是为什么我们尝试将所有的指标和中间结果以易于操作的纯文本格式导出。
从组织上来说,很难防止系统陷入只显示绿色检查标志而不提供任何见解的状态。我喜欢用“挖掘绿色检查标志”这个比喻,类似于加密货币。我们的上一个系统正是这样做的。它使用越来越复杂的启发式方法来防止误报,如果结果不理想,它会多次重启自身等等。最终,它浪费了大量的处理能力,而没有提供服务器性能的真实图景。如果你想确定性能是否有变化,你必须手动重新检查。这种糟糕的状态是开发激励机制不当的结果——大多数时候,开发人员只想合并他们的拉取请求,不希望被一些晦涩的测试失败所困扰。编写好的性能测试查询也并不总是简单的。不是任何查询都可以——它必须具有可预测的性能,不能太快也不能太慢,实际测量一些内容等等。在收集了更多精确的统计数据后,我们发现数百个测试查询没有测量任何有意义的内容,例如它们在不同运行之间的结果差异高达 100%。另一个问题是性能经常以统计上显著的方式变化(真正的正报),但没有相关的代码变化(例如由于可执行文件布局的随机差异)。鉴于所有这些困难,工作性能测试系统必然会给开发过程带来显著的摩擦。大多数“显而易见”的方法来消除这种摩擦最终都归结为“挖掘绿色检查标志”。
在实现方面,我们的系统很特别,因为它不依赖知名的统计包,而是大量使用 clickhouse-local,这个工具将 ClickHouse SQL 查询处理器变成了一个命令行工具。用 ClickHouse SQL 进行所有计算帮助我们发现了 clickhouse-local 的一些 bug 和可用性问题。性能测试继续作为一个重型 SQL 测试工作,有时会发现复杂联接等方面的新引入的 bug。查询分析器在性能测试中始终启用,这发现了我们 fork 的 libunwind 中的 bug。为了运行测试查询,我们使用了第三方 Python 驱动程序。这是我们在 CI 中唯一使用该驱动程序的地方,它还帮助我们发现了本地协议处理中的一些 bug。一个不太光彩的事实是,支架由大量的 bash 组成,但这至少让我们相信在 CI 中运行 shellcheck 非常有帮助。
这就是 ClickHouse 性能测试系统概述的全部内容。请继续关注下一篇文章,我们将讨论性能测试失败中最棘手的一种情况——不稳定的查询运行时间。
参考:
-
Box, Hunter, Hunter, 2005. Statistics for experimenters, p. 78: A Randomized Design Used in the Comparison of Standard and Modified Fertilizer Mixtures for Tomato Plants.
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求