
🏡作者主页:点击!
🤖编程探索专栏:点击!
⏰️创作时间:2024年11月12日17点02分
点击开启你的论文编程之旅![]() https://www.aspiringcode.com/content?id=17230869054974
https://www.aspiringcode.com/content?id=17230869054974
计算机来理解你的情绪:情感计算的发展
近年来,多模态情感分析(MSA)受到越来越多的关注,多模态情感分析是一个综合了视觉、听觉等语言和非语言信息的重要研究课题。多模态机器学习涉及从多个模态的数据中学习。这是一个具有挑战性但又至关重要的研究领域,在机器人领域具有现实应用、对话系统、智能辅导系统和医疗诊断。许多多模态建模任务的核心在于从多模态中学习丰富的表示。例如,分析多媒体内容需要学习跨语言、视觉和声模态的多模态表示。虽然多模态的存在提供了额外的有价值的信息,但是当从多模态数据学习时,存在两个关键挑战需要解决:
- 模型必须学习复杂的模态内和跨模态相互作用以进行预测;
- 训练模型必须对测试期间意外丢失或有噪声的模态具有鲁棒性。
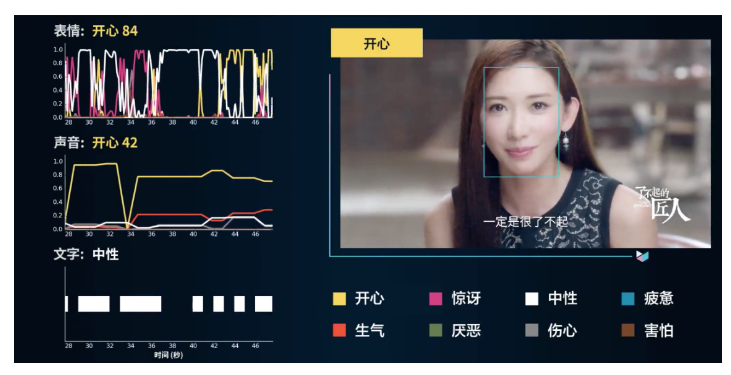
同时,繁重的工作量、紧迫的期限、不切实际的目标、延长的工作时间、工作不安全感和人际冲突等因素,导致了员工之间的紧张关系。超出一定限度的压力会对员工的工作效率、士气和积极性产生负面影响,同时还会引发各种生理和心理问题。长期的压力可能导致失眠、抑郁和心脏病。最新研究表明,长期的压力和癌症之间存在正相关。国际劳工组织在2019年宣布,“压力,过长的工作时间和疾病,导致每年近280万工人死亡,另外3.74亿人因工作受伤或生病”。
早期诊断和治疗对于减少压力对员工健康的长期影响和改善工作环境至关重要。检测抑郁症的常规方法通常由生理学家通过问卷访谈进行。但这种方法是定性的、耗时的且缺乏私密性,无法保证员工提供真实的答案,很多时候无法达到初步筛选的目的。相比之下,HRV(心率变异性)、ECG(心电图)、GSR(皮肤电反应)、血压、肌电图和EEG(脑电图)等方法是客观的,但同样缺乏私密性,而且由于这些测试能够推断私人健康信息,员工可能会对其产生抵触情绪。
因此,近年来,基于视频、音频和文本的抑郁症监测成为研究热点。基于视频的研究跟踪嘴唇、头部、心率、眨眼频率、凝视分布、瞳孔大小以及眼睛在面部各区域的运动。基于语音的方法则提取功率电平、LPCC、MPCC、倒谱系数等特征,并使用机器学习算法进行分类以检测情绪变化。基于文本的方法从文本中提取句法和语言特征,并使用机器学习分类器来检测抑郁症状。这些新方法为员工心理健康监测提供了更高效、更私密的解决方案。

我致力于对情感计算领域的经典模型进行分析、解读和总结,此外,由于现如今大多数的情感计算数据集都是基于英文语言开发的,我们计划在之后的整个系列文章中将中文数据集(SIMS, SIMSv2)应用在模型中,以开发适用于国人的情感计算分析模型,并应用在情感疾病(如抑郁症、自闭症)检测任务,为医学心理学等领域提供帮助,在未来,我也计划加入更多小众数据集,以便检测更隐匿的情感,如嫉妒、嘲讽等,使得AI可以更好的服务于社会。
【注】 我们文章中所用到的数据集,都经过重新特征提取形成新的数据集特征文件(.pkl),另外该抑郁症数据集因为涉及患者隐私,需要向数据集原创者申请,申请和下载链接都放在了我们附件中的 readme文件中,感兴趣的小伙伴可以进行下载,谢谢支持!
一、概述
这篇文章,我开始介绍第四篇情感计算经典论文模型,他是ICRL 2019的一篇多模态情感计算的论文 “LEARNING FACTORIZED MULTIMODAL REPRESENTATIONS”,其中提出的模型是MFM;
此外,原创部分为加入了抑郁症数据集以实现抑郁症检测任务,以及在SIMS数据集和SIMV2数据集上进行实验。
二、论文地址
LEARNING FACTORIZED MULTIMODAL REPRESENTATIONS
三、研究背景
多模态情感分析和抑郁症检测是一个热门的研究领域,它利用多模态信号对用户生成的视频进行情感理解和抑郁症程度判断。此外,由于存在多个异构信息源,多模态表征的学习是一个非常复杂的研究问题。虽然多模态的存在提供了额外的有价值的信息,但在从多模态数据学习时,五个核心挑战:对齐、翻译、表征、融合和共同学习。其中,表征学习处于基础性地位。
四、主要贡献
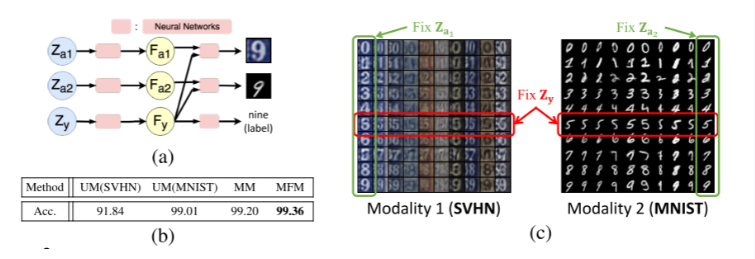
- 提出了用于多模态表征学习的多模态分解模型(MFM);
- MFM将多模态表示分解为两组独立因子:多模态区分因子和特定于模态的生成因子;
- 特定于模态的生成因子使我们能够基于因子化变量生成数据,解释缺失的模态,并对多模态学习中涉及的交互有更深入的理解。
五、模型结构和代码
1. 总体框架
如下图所示,MFM的功能可以分为两个主要阶段:Generative Network 和 Inference Network;通过两个模块组合生成整体MFM结构;多模态因子分解模型(MFM)是一种潜变量模型(a),对多模态判别因子和模态特定生成因子具有条件独立性假设。根据这些假设,提出了一个因子分解的联合分布的多峰数据。由于对这种分解分布的精确后验推理可能很难处理,我们提出了一种基于最小化多模态数据上的联合分布Wasserstein距离的近似推理算法。最后,推导出MFM目标通过近似的联合分布Wasserstein距离通过广义平均场假设。
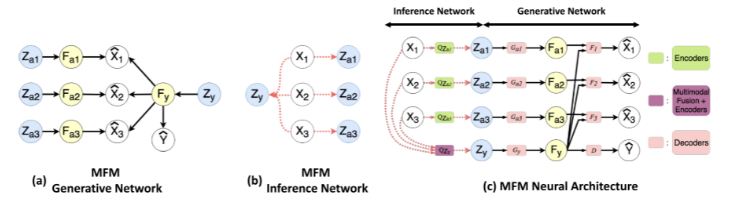
2. 因式分解多模态表示
为了将多模态表示分解为多模态判别因子和特定模态生成因子,MFM假设一个贝叶斯网络结构,如上图 a 所示。在该图模型中,因子 𝐹𝑦Fy 和 𝐹𝑎{1:𝑀}Fa{1:M} 由具有先验 𝑃𝑍PZ 的相互独立的潜变量 𝑍=[𝑍𝑦,𝑍𝑎{1:𝑀}]Z=[Zy,Za{1:M}] 生成。具体地,$Z_y% 生成多模态判别因子 𝐹𝑦Fy,并且 𝑍𝑎{1:𝑀}Za{1:M} 生成模态特定生成因子 𝐹𝑎{1:𝑀}Fa{1:M}。通过构造,𝐹𝑦Fy 有助于生成 𝑌^Y^,而 {𝐹𝑦,𝐹𝑎𝑖}{Fy,Fai} 共同有助于生成 𝑋^𝑖X^i。因此,联合分布 𝑃(𝑋^1:𝑀,𝑌^)P(X^1:M,Y^) 可以分解;
由于对 𝑍Z 的积分,方程1中的精确后验推断在解析上可能是不可行的。因此,我们求助于使用近似推断分布 𝑄(𝑍∣𝑋1:𝑀,𝑌)Q(Z∣X1:M,Y),其详细内容见以下小节。结果,MFM 可以被视为一种自编码结构,包含编码器(推断模块)和解码器(生成模块)(上图(c))。𝑄(.∣.)Q(.∣.) 的编码器模块使我们能够轻松地从近似后验中抽样 𝑍Z。解码器模块根据方程1和图(a)所给出的 𝑃(𝑋^1:𝑀,𝑌^∣𝑍)P(X^1:M,Y^∣Z) 的因子分解进行参数化。
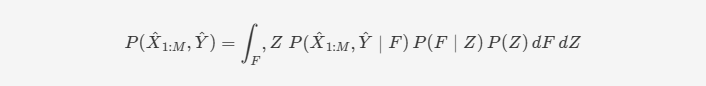
3. 多模数据联合分布Wasserstein距离的最小化
在自编码结构中,常用的近似推断方法有变分自编码器(VAEs)和Wasserstein自编码器(WAEs)。前者优化证据下界目标(ELBO),后者则推导出Wasserstein距离的原始形式的近似。我们选择后者,因为它同时在潜在因子的解缠和样本生成质量上优于其对应方法。然而,WAEs设计用于单模态数据,并没有考虑生成多模态数据的潜在变量上的分解分布。因此,我们提出了一个变体,以处理多模态数据上的分解联合分布。
如Kingma & Welling(2013)所建议的那样,我们在编码器和解码器中采用了非线性映射的设计(即神经网络架构)(上图(c))。对于编码器 𝑄(𝑍∣𝑋1:𝑀,𝑌)Q(Z∣X1:M,Y),我们学习了一个确定性映射 𝑄𝑒𝑛𝑐:𝑋1:𝑀,𝑌→𝑍Qenc:X1:M,Y→Z。对于解码器,我们将潜在变量的生成过程定义为 𝐺𝑦:𝑍𝑦→𝐹𝑦Gy:Zy→Fy, 𝐺𝑎1:𝑀:𝑍𝑎1:𝑀→𝐹𝑎1:𝑀Ga1:M:Za1:M→Fa1:M, 𝐷:𝐹𝑦→𝑌^D:Fy→Y^,和 𝐹1:𝑀:𝐹𝑦,𝐹𝑎1:𝑀→𝑋^1:𝑀F1:M:Fy,Fa1:M→X^1:M,其中 𝐺𝑦,𝐺𝑎1:𝑀,𝐷Gy,Ga1:M,D 和 𝐹1:𝑀F1:M 是由神经网络参数化的确定性函数。
令 𝑊𝑐(𝑃𝑋1:𝑀,𝑌,𝑃𝑋^1:𝑀,𝑌^)Wc(PX1:M,Y,PX^1:M,Y^) 表示在成本函数𝑐𝑋𝑖cXi 和 𝑐𝑌cY 下的多模态数据上的联合分布Wasserstein距离。我们选择平方成本𝑐(𝑎,𝑏)=∥𝑎−𝑏∥22c(a,b)=∥a−b∥22,从而使我们能够最小化2-Wasserstein距离。成本函数不仅可以定义在静态数据上,还可以定义在时间序列数据上,例如文本、音频和视频。例如,给定时间序列数据 𝑋=[𝑋1,𝑋2,⋯,𝑋𝑇]X=[X1,X2,⋯,XT] 和 𝑋^=[𝑋^1,𝑋^2,⋯,𝑋^𝑇]X^=[X^1,X^2,⋯,X^T],我们定义 𝑐(𝑋,𝑋^)=∑𝑡=1𝑇∥𝑋𝑡−𝑋^𝑡∥22c(X,X^)=∑t=1T∥Xt−X^t∥22。
4. 缺失模式的替代推理
多模态学习的一个关键挑战是处理缺失的模态。一个优秀的多模态模型应该能够在给定观测模态的情况下推断缺失的模态,并且仅基于观测模态进行预测。为了实现这一目标,MFM的推断过程可以通过使用代理推断网络来轻松地适应,代理推断网络在给定观测模态的情况下重建缺失模态。形式上,设 ΦΦ 表示代理推断网络。在给定观测模态 𝑋2:𝑀X2:M的情况下,生成缺失模态 𝑋^1X^1 的过程可以公式化如下:
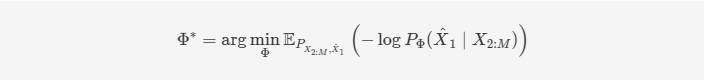
与第上一节类似,我们在 𝑄Φ(⋅∣⋅)QΦ(⋅∣⋅) 中使用确定性映射,𝑄Φ(𝑍𝑦∣⋅)QΦ(Zy∣⋅) 也用于预测 𝑃Φ(𝑌^∣𝑋2:𝑀)PΦ(Y^∣X2:M) ,即:
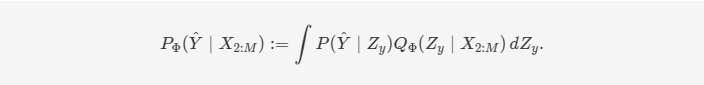
上述公式表明,在存在缺失模态的情况下,我们只需要推断潜在的编码,而不是整个模态。
六、数据集介绍
1. CMU-MOSI: CMU-MOSI数据集是MSA研究中流行的基准数据集。该数据集是YouTube独白的集合,演讲者在其中表达他们对电影等主题的看法。MOSI共有93个视频,跨越89个远距离扬声器,包含2198个主观话语视频片段。这些话语被手动注释为[-3,3]之间的连续意见评分,其中-3/+3表示强烈的消极/积极情绪。
2. CMU-MOSEI: CMU-MOSEI数据集是对MOSI的改进,具有更多的话语数量,样本,扬声器和主题的更大多样性。该数据集包含23453个带注释的视频片段(话语),来自5000个视频,1000个不同的扬声器和250个不同的主题
3. AVEC2019: AVEC2019 DDS数据集是从患者临床访谈的视听记录中获得的。访谈由虚拟代理进行,以排除人为干扰。与上述两个数据集不同的是,AVEC2019中的每种模态都提供了几种不同的特征。例如,声学模态包括MFCC、eGeMaps以及由VGG和DenseNet提取的深度特征。在之前的研究中,发现MFCC和AU姿势分别是声学和视觉模态中两个最具鉴别力的特征。因此,为了简单和高效的目的,我们只使用MFCC和AU姿势特征来检测抑郁症。数据集用区间[0,24]内的PHQ-8评分进行注释,PHQ-8评分越大,抑郁倾向越严重。该基准数据集中有163个训练样本、56个验证样本和56个测试样本。
4. SIMS/SIMSV2: CH-SIMS数据集[35]是一个中文多模态情感分析数据集,为每种模态提供了详细的标注。该数据集包括2281个精选视频片段,这些片段来自各种电影、电视剧和综艺节目,每个样本都被赋予了情感分数,范围从-1(极度负面)到1(极度正面)
七、性能展示
- 在情感计算任务中,可以看到 MFM 模型性能超越其他模型,证明了其有效性;
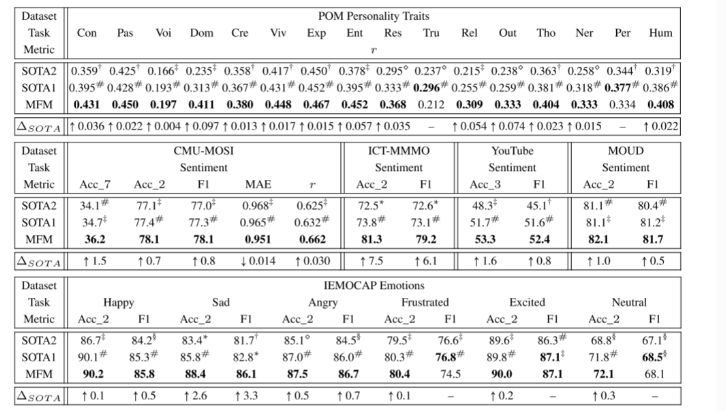
- 抑郁症检测任务,以下是 MFM 模型在抑郁症数据集AVEC2019中的表现:
| Model | CCC | MAE |
| Baseline | 0.111 | 6.37 |
| EF | 0.34 | – |
| Bert-CNN & Gated-CNN | 0.403 | 6.11 |
| Multi-scale Temporal Dilated CNN | 0.430 | 4.39 |
| MFM | 0.432 | 4.35 |
八、复现过程
在下载附件并准备好数据集并调试代码后,进行下面的步骤,附件已经调通并修改,可直接正常运行;
1. 下载多模态情感分析集成包
pip install MMSA2. 进行训练
$ python -m MMSA -d mosi/dosei/avec -m mmim -s 1111 -s 1112九、运行过程
1.训练过程

2.最终结果
![]()
总结
1. 适用场景
- 社交媒体情感分析: MFM模型适用于分析社交媒体平台上用户的多模态数据,包括文本、图像和音频,从而深入理解用户的情感倾向、态度和情绪变化。例如,可以用于监测社交媒体上的舆情、分析用户对特定事件或产品的反应等。
- 情感驱动的内容推荐: 在内容推荐系统中,MFM模型可以根据用户的多模态数据,如观看历史、社交互动、文字评论等,推荐符合用户情感和兴趣的个性化内容,提升用户体验和内容吸引力。
- 智能健康监测: MFM模型在智能健康监测领域具有潜力,可以通过分析用户的语音情绪、面部表情和文字记录来监测心理健康状态,包括抑郁倾向和情绪波动,为个体提供早期干预和支持。
- 教育和人机交互: 在教育领域,MFM模型可以用于情感教育和个性化学习支持。通过分析学生的情感表达和反馈,提供定制化的学习体验和情感指导,增强教育效果和学习动机。
2. 项目特点
- 多模态融合: MFM模型能够有效整合文本、图像和音频等多种数据源,充分利用不同模态之间的关联性和信息丰富度,提升情感分析的全面性和准确性。
- 情感感知和表达建模: 通过先进的深度学习技术,MFM模型能够深入学习和模拟情感感知与表达过程,实现对复杂情感信息的准确捕捉和高效表示。
- 自适应学习和个性化: MFM模型具备自适应学习能力,可以根据具体任务和用户需求调整情感建模策略,实现个性化的情感分析和反馈。
- 跨领域应用能力: 由于其多模态分析的通用性和灵活性,MFM模型不仅适用于社交媒体分析和智能健康监测,还能应用于广告推荐、产品评价和人机交互等多个领域。
综上所述,MFM模型在多模态情感分析和智能应用领域展现出广泛的适用性和高效的技术特点,为实际应用场景提供了强大的分析和决策支持能力
成功的路上没有捷径,只有不断的努力与坚持。如果你和我一样,坚信努力会带来回报,请关注我,点个赞,一起迎接更加美好的明天!你的支持是我继续前行的动力!"
"每一次创作都是一次学习的过程,文章中若有不足之处,还请大家多多包容。你的关注和点赞是对我最大的支持,也欢迎大家提出宝贵的意见和建议,让我不断进步。"
神秘泣男子
