2024年2月1日,面壁智能与清华大学自然语言处理实验室共同开源MiniCPM系列端侧大模型,主体语言模型MiniCPM-2B仅有24亿(2.4B)的非词嵌入参数量,总计2.7B参数量。
经过SFT后,MiniCPM-2B在公开综合性评测集上与Mistral-7B表现相近(中文、数学和代码能力更优),整体性能超越Llama2-13B、MPT-30B、Falcon-40B等模型。
经过DPO后,MiniCPM-2B在当前最接近用户体感的评测集MTBench上也超越了Llama2-70B-Chat、Vicuna-33B、Mistral-7B-Instruct-v0.1、Zephyr-7B-alpha等众多代表性开源大模型。
环境准备
安装Ascend CANN Toolkit和Kernels
安装方法请参考安装教程(https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/80RC2alpha002/quickstart/quickstart/quickstart_18_0004.html)或使用以下命令。
# 请替换URL为CANN版本和设备型号对应的URL
# 安装CANN Toolkit
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C17SPC701/Ascend-cann-toolkit_8.0.RC1.alpha001_linux-"$(uname -i)".run
bash Ascend-cann-toolkit_8.0.RC1.alpha001_linux-"$(uname -i)".run --install # 安装CANN Kernels
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C17SPC701/Ascend-cann-kernels-910b_8.0.RC1.alpha001_linux.run
bash Ascend-cann-kernels-910b_8.0.RC1.alpha001_linux.run --install # 设置环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh 安装openMind Library以及openMind Hub Client
- 安装 openMind Hub 客户端
pip install openmind_hub - 安装 openMind Library,并安装 PyTorch框架及其依赖。
pip install openmind[pt]
更详细的安装信息请参考魔乐社区官方的环境安装(https://modelers.cn/docs/zh/community/environment_installation.html)章节。
安装****LLaMa Factory
`git clone https://github.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory pip install -e ".[torch-npu,metrics]"`模型链接和下载
MiniCPM-2B模型系列由社区开发者在魔乐社区贡献,包括:
-
MiniCPM-2B-sft-bf16:https://modelers.cn/models/AI-Research/MiniCPM-2B-sft-bf16
-
MiniCPM-2B-dpo-bf16:https://modelers.cn/models/AI-Research/MiniCPM-2B-dpo-bf16
-
MiniCPM-2B-128k:https://modelers.cn/models/AI-Research/MiniCPM-2B-128k
-
MiniCPM-MoE-8x2B:https://modelers.cn/models/AI-Research/MiniCPM-MoE-8x2B
-
MiniCPM-1B-sft-bf16:https://modelers.cn/models/AI-Research/MiniCPM-1B-sft-bf16
通过Git从魔乐社区下载模型的repo,以MiniCPM-2B-sft-bf16为例:
# 首先保证已安装git-lfs(https://git-lfs.com)
git lfs install
git clone https://modelers.cn/AI-Research/MiniCPM-2B-sft-bf16.git 模型推理
用户可以使用openMind Library或者LLaMa Factory进行模型推理,以MiniCPM-2B-sft-bf16为例,具体如下:
- 使用openMind Library进行模型推理
新建推理脚本inference_minicpm_2b_sft_bf16.py,推理脚本内容为:
from openmind import AutoModelForCausalLM, AutoTokenizer
import torch
torch.manual_seed(0) # 若模型已下载,可替换成模型本地路径
path = 'AI-Research/MiniCPM-2B-sft-bf16'
tokenizer = AutoTokenizer.from_pretrained(path)
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map='npu', trust_remote_code=True) responds, history = model.chat(tokenizer, "山东省最高的山是哪座山, 它比黄山高还是矮?差距多少?", temperature=0.8, top_p=0.8)
print(responds)
执行推理脚本:
python inference_minicpm_2b_sft_bf16.py
推理结果如下:

- 使用LLaMa Factory与模型交互
在LLaMa Factory路径下新建examples/inference/minicpm_2b_sft_bf16.yaml推理配置文件,文件内容为:
model_name_or_path: xxx # 当前仅支持本地加载,填写MiniCPM-2B-sft-bf16本地权重路径
template: cpm
使用以下命令与模型进行交互:
llamafactory-cli chat examples/inference/minicpm_2b_sft_bf16.yaml
交互结果如下:

模型微调
我们使用单张昇腾NPU,基于LLaMa Factory框架,采用blossom-math-v2数据集对MiniCPM-2B-sft-bf16进行全参微调,让模型能够根据用户输入的数学问题计算得到正常答案。
数据集
blossom-math-v2是基于Math32和GSM8K衍生而来的中英文数学对话数据集,适用于数学问题微调。该数据集大小为10K,每条数据代表一个完整的题目及答案,包含id、input、output、answer和dataset五个字段,具体如下:
-
id:字符串,代表原始数据集中的题目id,与dataset字段结合可确定唯一题目。
-
input:字符串,代表问题。
-
output:字符串,代表gpt-3.5-turbo-0613生成的答案。
-
answer:字符串,代表正确答案。
-
dataset:字符串,代表原始数据集。
以下是示例:
{ "id": "5", "input": "小刚的体重是28.4千克,小强的体重是小刚的1.4倍,小强的体重=多少千克?", "output": "小强的体重=小刚的体重 × 1.4 = 28.4千克 × 1.4 = 39.76千克", "answer": "39.76", "dataset": "Math23K"
}, - 下载blossom-math-v2数据集
感谢社区开发者在魔乐社区贡献的blossom-math-v2数据集,使用Git将数据集下载至本地。
git lfs install
git clone https://modelers.cn/AI-Research/blossom-math-v2.git
- 数据预处理
下载完成后,我们进行数据预处理:
1、将blossom-math-v2-10k.jsonl文件数据处理成alpaca数据格式,把answer字段拼接到output字段之后,使得模型在微调结束后能够在回答结尾输出正确答案。
2、将blossom-math-v2-10k.jsonl拆分为训练集和验证集,其中,训练集大小为9K,验证集大小为1K。
创建preprocess_blossom_math_v2.py脚本,脚本内容具体如下:
import json
import argparse
import os
import stat
import random DEFAULT_FLAGS = os.O_WRONLY | os.O_CREAT
DEFAULT_MODES = stat.S_IWUSR | stat.S_IRUSR def parse_args(): parse = argparse.ArgumentParser() parse.add_argument("--data_path", type=str) parse.add_argument("--save_path", type=str) args = parse.parse_args() return args def read_data(data_path): data = [] with open(data_path, "r", encoding="utf-8") as f: lines = f.readlines() for line in lines: data.append(json.loads(line)) return data def train_dev_split(data, dev_ratio=0.1, shuffle=True, seed=42): if shuffle: random.seed(seed) random.shuffle(data) dev_num = int(len(data) * dev_ratio) train_data = data[dev_num:] dev_data = data[:dev_num] return train_data, dev_data def convert_to_alpaca_format(data): results = [] for sample in data: example = {} example["instruction"] = sample["input"] example["output"] = sample["output"] + "\nAnswer:" + sample["answer"] results.append(example) return results def save_data(data, save_path, save_file_name): with os.fdopen(os.open(os.path.join(save_path, save_file_name), DEFAULT_FLAGS, DEFAULT_MODES), "w", encoding="utf-8") as f: json.dump(data, f, indent=4, ensure_ascii=False) if __name__ == "__main__": args = parse_args() data = read_data(args.data_path) data = convert_to_alpaca_format(data) train_data, dev_data = train_dev_split(data) save_data(train_data, args.save_path, "blossom-math-v2-train.json") save_data(dev_data, args.save_path, "blossom-math-v2-dev.json") 通过以下命令执行脚本,将数据预处理的结果在当前路径下分别存为blossom-math-v2-train.json和blossom-math-v2-dev.json。
# xxx为blossom-math-v2-10k.jsonl文件路径
python preprocess_blossom_math_v2.py --data_path xxx --save_path ./
修改LLaMa Factory下的data/dataset_info.json文件,添加数据集描述:
"blossom_math_v2_train": { "file_name": "xxx", // 填写预处理完成的blossom-math-v2-train.json文件路径 "columns": { "prompt": "instruction", "response": "output" }
},
"blossom_math_v2_dev": { "file_name": "xxx", // 填写预处理完成的blossom-math-v2-dev.json文件路径 "columns": { "prompt": "instruction", "response": "output" }
},
以上为整个数据预处理流程,在配置文件中使用dataset: blossom_math_v2_train, blossom_math_v2_dev配置即可在微调中使用blossom-math-v2数据集。
微调
在LLaMa Factory路径下新建examples/train_full/minicpm_2b_full_sft.yaml微调配置文件,微调配置文件如下:
### model
model_name_or_path: xxx # 当前仅支持本地加载,填写MiniCPM-2B-sft-bf16本地权重路径 ### method
stage: sft
do_train: true
finetuning_type: full ### dataset
dataset: blossom_math_v2_train
template: cpm
cutoff_len: 256
overwrite_cache: true
preprocessing_num_workers: 16 ### output
output_dir: saves/minicpm_2b_sft_bf16/full/sft
logging_steps: 10
save_strategy: epoch
plot_loss: true
overwrite_output_dir: true ### train
per_device_train_batch_size: 16
gradient_accumulation_steps: 1
learning_rate: 3.0e-5
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
通过下面的命令启动微调:
export ASCEND_RT_VISIBLE_DEVICES=0
llamafactory-cli train examples/train_full/minicpm_2b_full_sft.yaml
微调可视化
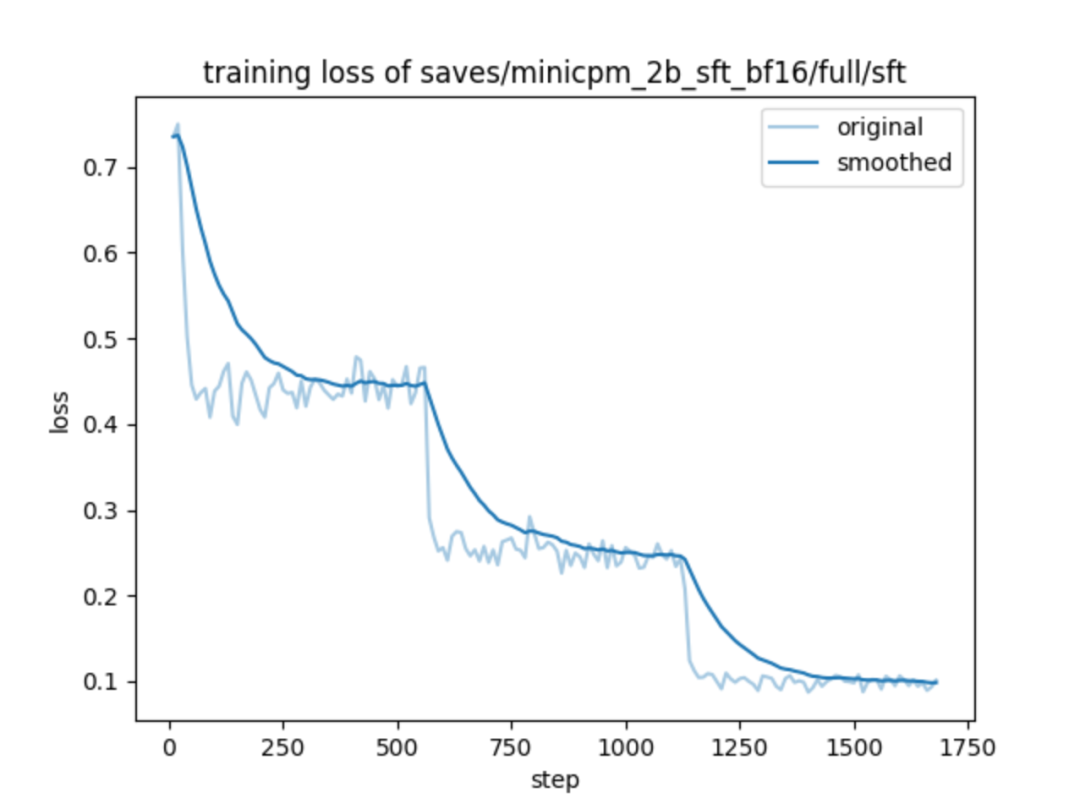
微调结果
评估
训练结束后,通过LLaMa Factory使用微调完成的权重在blossom-math-v2-dev.json数据集上进行推理。在LLaMa Factory路径下新建examples/train_full/minicpm_2b_predict.yaml推理配置文件,配置文件内容如下:
### model
model_name_or_path: saves/minicpm_2b_sft_bf16/full/sft/checkpoint-1689/ ### method
stage: sft
do_predict: true
finetuning_type: full ### dataset
eval_dataset: blossom_math_v2_dev
template: cpm
cutoff_len: 256
overwrite_cache: true
preprocessing_num_workers: 16 ### output
output_dir: saves/minicpm_2b_sft_bf16/full/predict
overwrite_output_dir: true ### eval
per_device_eval_batch_size: 64
predict_with_generate: true 通过下面的命令启动评估:
export ASCEND_RT_VISIBLE_DEVICES=0
llamafactory-cli train examples/train_full/minicpm_2b_predict.yaml
推理结果将会生成在saves/minicpm_2b_sft_bf16/full/predict路径下。其中,generated_predictions.jsonl将每条推理结果都保存为json,prompt、laebl和predict三个字段分别表示输入、真实标签、预测标签。
经过微调,模型会把计算结果在末尾输出。可以通过简单的正则表达式将其提取出来,并计算模型推理的正确率。新建脚本calc_acc.py,具体内容如下:
import argparse
import json
import re def parse_args(): parse = argparse.ArgumentParser() parse.add_argument("--data_path", type=str) args = parse.parse_args() return args def read_data(data_path): data = [] with open(data_path, "r", encoding="utf-8") as f: lines = f.readlines() for line in lines: data.append(json.loads(line)) return data def calc_acc(data): total_num = len(data) pattern = re.compile(r'[0-9]*$') correct_num = 0 for i in range(total_num): label = pattern.search(data[i]["label"]).group() predict = pattern.search(data[i]["predict"]).group() if predict == label: correct_num += 1 acc = round(correct_num / total_num, 2) * 100 print(f"Acc: {acc}%") if __name__ == "__main__": args = parse_args() data = read_data(args.data_path) calc_acc(data) 通过以下命令执行脚本:
# xxx为generated_predictions.jsonl文件路径
python calc_acc.py --data_path xxx 推理
修改LLaMa Factory路径下examples/inference/minicpm_2b_sft_bf16.yaml推理配置文件,配置文件内容改为:
model_name_or_path: saves/minicpm_2b_sft_bf16/full/sft/checkpoint-1689
template: cpm 通过下面的命令启动推理:
llamafactory-cli chat examples/inference/minicpm_2b_sft_bf16.yaml 训练前推理结果为:
- 问题:当Paul看电影时,他在跑步机上跑步。他可以在12分钟内跑完一英里。他看两部电影,每部电影平均长度为1.5小时。他跑了多少英里?

训练后推理结果为:
- 问题1:当Paul看电影时,他在跑步机上跑步。他可以在12分钟内跑完一英里。他看两部电影,每部电影平均长度为1.5小时。他跑了多少英里?

- 问题2:一个平行四边形的面积是64平方厘米,底是16厘米,高=多少厘米.

如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。