前言
最近在使用spring boot + websocket + xterm.js 给 k8s pod做了个在线的 web 终端,发现websocket的类核心方法,用的都是ByteBuffer传递数据,如下:
@OnMessagepublic void onMessage(Session session, ByteBuffer byteBuffer) {//xxxxx}
以前只知道 NIO 里面大量用到了 ByteBuffer ,并没有仔细了解过,这次特意学习了一下,因为JDK自带的ByteBuffer 可以切换读写两种模式加上内置很多方法组合使用,有很多约定俗成的用法,稍不注意就有可能踩坑,这也是为什么Netty里面又基于 ByteBuffer 重新封装了ByteBuf类,就是因为 JDK 自带的太难用了
UML 图概览
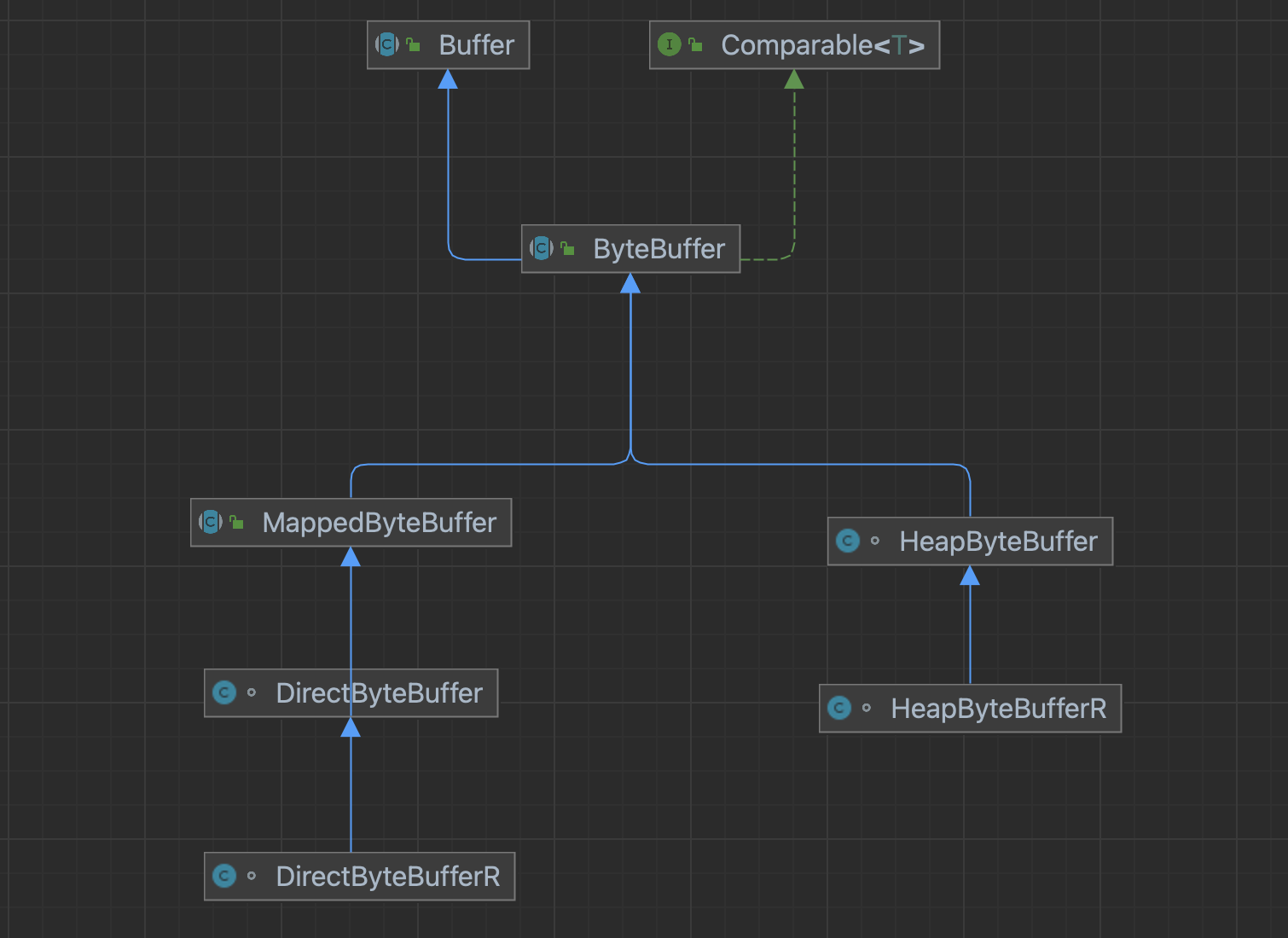
解释:
Buffer 抽象类是所有 ByteBuffer 类的父类,其子类还有8种基本类型的IntBuffer,LongBuffer等,这不是我们这次的重点,我们这次主要关注 ByteBuffer 子类,如上图所示。
Buffer抽象类几个字段:
- capacity:这个很好理解,它规定了整个 Buffer 的容量,具体可以容纳多少个元素。capacity 指针之前的元素均是 Buffer 可操作的空间。
- position:用于指向 Buffer 中下一个可操作性的元素,初始值为 0。在 Buffer 的写模式下,position 指针用于指向下一个可写位置。在读模式下,position 指针指向下一个可读位置。
- limit:表示 Buffer 可操作元素的上限。什么意思呢?比如在 Buffer 的写模式下,可写元素的上限就是 Buffer 的整体容量也就是 capacity ,capacity - 1 即为 Buffer 最后一个可写位置。在读模式下,Buffer 中可读元素的上限即为上一次 Buffer 在写模式下最后一个写入元素的位置。也就是上一次写模式中的 position。
- mark:用于标记 Buffer 当前 position 的位置
// Invariants: mark <= position <= limit <= capacityprivate int mark = -1; // 搭配 reset 使用private int position = 0; // 写模式下指向下一次写的位置,读模式下是当前要读数据的位置private int limit; private int capacity;// Used only by direct buffers// NOTE: hoisted here for speed in JNI GetDirectBufferAddresslong address;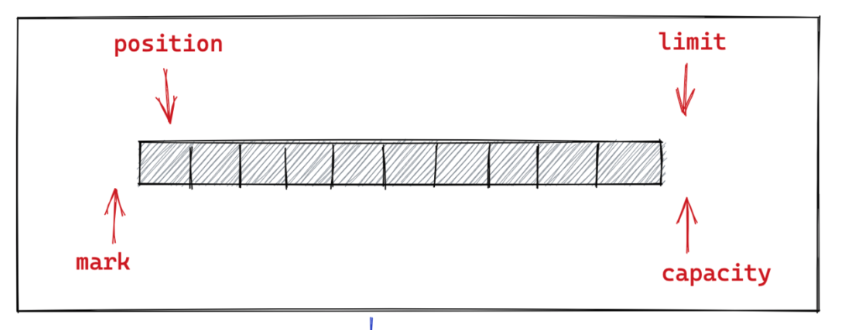
MappedByteBuffer : 映射 JVM 堆外内存,也就是这部分内存由 linux 内核管理,其中可映射文件,也可也直接在操作堆上分配空间。最常用的是:DirectByteBuffer ,DirectByteBufferR 代表只读视图
HeapByteBuffer : 在 JVM 堆内分配内存,HeapByteBufferR 代表只读视图
常用方法
put
这个比较简单,就是向 ByteBuffer 里面放入数据,例子如下:
public static void putData(){//默认声明出来的是写模式ByteBuffer buffer = ByteBuffer.allocate(16);buffer.put(new byte[]{'s','h'});System.out.println(buffer);//java.nio.HeapByteBuffer[pos=2 lim=16 cap=16]}get
这个就要注意了,在没有切换成读模式下直接get是有问题的,除非指定 index 读
public static void getData(){ByteBuffer buffer = ByteBuffer.allocate(16);buffer.put(new byte[]{'s','h'});System.out.println(buffer);System.out.println(buffer.position());System.out.println(buffer.get()); // 输出 0//在没有切换读模式下,get方法获取的是写 pos的值,也就是pos=2,所以读取不正确System.out.println(buffer.get(0)); // 输出 s}
此外,get方法也会使得 pos ++,所以几次get之后,在写数据就会出现空间空了几次:
public static void getData2(){ByteBuffer buffer = ByteBuffer.allocate(16);buffer.put(new byte[]{'s','h'});System.out.println(buffer);System.out.println(buffer.get()); // 输出 0System.out.println(buffer); // get 方法会导致pos指针++System.out.println(buffer.get()); // 输出 0System.out.println(buffer); // get 方法会导致pos指针++System.out.println(buffer.get()); // 输出 0System.out.println(buffer); // get 方法会导致pos指针++//在没有切换读模式下,get方法获取的是写 pos的值,也就是pos=2,所以读取不真确//java.nio.HeapByteBuffer[pos=2 lim=16 cap=16]//0//java.nio.HeapByteBuffer[pos=3 lim=16 cap=16]//0//java.nio.HeapByteBuffer[pos=4 lim=16 cap=16]//0//java.nio.HeapByteBuffer[pos=5 lim=16 cap=16]//buffer.put(new byte[]{'e'});System.out.println(buffer);//最终内存结果//[115, 104, 0, 0, 0, 101, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]}获取最后一位数据:
public static void getData3(){ByteBuffer buffer = ByteBuffer.allocate(16);buffer.put(new byte[]{'s','h'});System.out.println(buffer);System.out.println(buffer.get()); // 输出 0System.out.println(buffer); // get 方法会导致pos指针++System.out.println(buffer.get()); // 输出 0System.out.println(buffer); // get 方法会导致pos指针++System.out.println(buffer.get()); // 输出 0System.out.println(buffer); // get 方法会导致pos指针++//在没有切换读模式下,get方法获取的是写 pos的值,也就是pos=2,所以读取不真确//java.nio.HeapByteBuffer[pos=2 lim=16 cap=16]//0//java.nio.HeapByteBuffer[pos=3 lim=16 cap=16]//0//java.nio.HeapByteBuffer[pos=4 lim=16 cap=16]//0//java.nio.HeapByteBuffer[pos=5 lim=16 cap=16]//buffer.put(new byte[]{'e'});System.out.println(buffer);buffer.put(new byte[]{'\n'});//最终内存结果//[115, 104, 0, 0, 0, 101, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]// 使用getIndex获取最后一位数据, 并且不会导致pos++// 回车,ASCII码13
// 换行,ASCII码10
// 空格,ASCII码32// 输出10System.out.println(buffer.get(buffer.position()-1));}flip
切换成读模式:limit和pos的值会自动适配变化,需要注意的是即使切换到读模式,你仍然可以写因为这不是强制的,但如果你切换成读模式后立马写数据,会覆盖掉第一位数据
public static void flip(){ByteBuffer buffer = ByteBuffer.allocate(16);buffer.put(new byte[]{'t', 'o','m'});System.out.println(buffer);// java.nio.HeapByteBuffer[pos=3 lim=16 cap=16]buffer.flip();System.out.println(buffer); // java.nio.HeapByteBuffer[pos=0 lim=3 cap=16]System.out.println((char)buffer.get());System.out.println((char)buffer.get());System.out.println(buffer);// java.nio.HeapByteBuffer[pos=2 lim=3 cap=16]buffer.put(new byte[]{'e'});System.out.println(buffer);//}
覆盖写例子:
// 切换读模式public static void flip2(){ByteBuffer buffer = ByteBuffer.allocate(16);buffer.put(new byte[]{'t', 'o','m'});System.out.println(buffer);// java.nio.HeapByteBuffer[pos=3 lim=16 cap=16]buffer.flip();System.out.println(buffer); // java.nio.HeapByteBuffer[pos=0 lim=3 cap=16]buffer.put(new byte[]{'e'});System.out.println(buffer); // java.nio.HeapByteBuffer[pos=1 lim=3 cap=16]System.out.println((char)buffer.get(0)); //写的数据覆盖了第一个t}rewind
读模式下重置数据,从头开始读:
public static void rewind(){ByteBuffer buffer = ByteBuffer.allocate(16);buffer.put(new byte[]{'t', 'o'});buffer.flip();System.out.println((char)buffer.get()); // tSystem.out.println((char)buffer.get()); // o// 从头开始读buffer.rewind();System.out.println((char)buffer.get()); // tSystem.out.println((char)buffer.get()); // o}mark & reset
mark标记当前位置,继续读写后,然后reset可以重置到mark的位置,实现原理很简单就是用mark字段备份了原来pos的值:
public static void markResetRead(){ByteBuffer buffer = ByteBuffer.allocate(16);buffer.put(new byte[]{'t', 'o', 'm', 'c','a','t'});System.out.println(buffer);buffer.flip();System.out.println((char) buffer.get()); // tSystem.out.println((char) buffer.get()); // o// 控记住当前的 positionbuffer.mark();System.out.println((char) buffer.get()); // mSystem.out.println((char) buffer.get()); // cbuffer.reset();System.out.println((char) buffer.get()); // mSystem.out.println((char) buffer.get()); // c}写模式也可以:
public static void markResetWrite(){ByteBuffer buffer = ByteBuffer.allocate(16);buffer.mark();buffer.put(new byte[]{'a'});buffer.put(new byte[]{'b'});// 控记住当前的 positionSystem.out.println((char) buffer.get(0)); // aSystem.out.println((char) buffer.get(1)); // bbuffer.reset();buffer.put(new byte[]{'c'});buffer.put(new byte[]{'d'});System.out.println((char) buffer.get(0)); // cSystem.out.println((char) buffer.get(1)); // d}clear
重置写模式,注意这个并没有删除旧数据,只是把pos位置置0:
// 从头开始写覆盖数据public static void clear(){ByteBuffer buffer = ByteBuffer.allocate(16);buffer.put(new byte[]{'a', 'b', 'c', 'd'});System.out.println(buffer);//java.nio.HeapByteBuffer[pos=4 lim=16 cap=16]buffer.clear();System.out.println(buffer);//java.nio.HeapByteBuffer[pos=0 lim=16 cap=16]}
compact
compact方法,主要是用来解决clear方法切换写模式后,总是从头开始的问题,因为切换为读的时候,大部分情况下可能只读一部分数据,然后就要切写模式,直接掉clear方法会覆盖掉一部分未读的数据,所以这个时候需要使用compact方法,将没读的部分移动到前面,然后将pos重置到下一个可覆盖写的地方
public static void compact(){ByteBuffer buffer = ByteBuffer.allocate(16);buffer.put("hadoop".getBytes(StandardCharsets.UTF_8));System.out.println(buffer);//java.nio.HeapByteBuffer[pos=6 lim=16 cap=16]// 切换到读模式buffer.flip();String v=StandardCharsets.UTF_8.decode(buffer).toString();System.out.println(v);//hadoopbuffer.rewind(); //重置读System.out.println((char) buffer.get()); // hSystem.out.println(buffer);//java.nio.HeapByteBuffer[pos=1 lim=6 cap=16]// 数据读了一部分,这个时候使用clear切换写模式,会覆盖掉没读部分,所以得使用 compat 将没读过的数据, 移到 buffer 的首部buffer.compact(); // 此时 buffer 的数据就会变成 adooppSystem.out.println(buffer);// java.nio.HeapByteBuffer[pos=5 lim=16 cap=16]buffer.rewind();String v1=StandardCharsets.UTF_8.decode(buffer).toString();System.out.println(v1);//adoopp}hasRemaining
判断 pos 位置是否小于 limit,也就是是否达到buffer的上限
public static void remaining(){ByteBuffer buffer = ByteBuffer.allocate(2);buffer.put(new byte[]{'b'});System.out.println(buffer.hasRemaining()); //truebuffer.put(new byte[]{'c'}); System.out.println(buffer.hasRemaining()); //false // check position < limit;}remaining
写模式下,判断剩余容量还有多少:
public static void remaining(){ByteBuffer buffer = ByteBuffer.allocate(10);buffer.put(new byte[]{'b'});buffer.put(new byte[]{'c'});System.out.println(buffer.remaining()); // 8}其他方法:
isReadOnly: 判断是否是只读Buffer
isDirect: 是否从对外分配的内存空间
duplicate:
clone 原生 ByteBuffer。它们的 offset,mark,position,limit,capacity 变量的值全部是一样的,这里需要注意虽然值是一样的,但是它们各自之间是相互独立的。用于对同一字节数组做不同的逻辑时候需要
slice:
调用 slice() 方法创建出来的 ByteBuffer 视图内容是从原生 ByteBufer 的当前位置 position 开始一直到 limit 之间的数据。也就是说通过 slice() 方法创建出来的视图里边的数据是原生 ByteBuffer 中还未处理的数据部分,共享原生的数据,访问时需要带上 offset
总结
Java 中的 ByteBuffer 是 java.nio 包中的核心类之一,属于 New I/O (NIO) 框架。它提供了用于操作字节数据的丰富方法,ByteBuffer 在需要高效 I/O 操作的应用程序中非常有用,特别是在网络编程、文件 I/O、内存映射文件、以及其他需要直接操作字节数据的场景中。使用 ByteBuffer 可以带来更好的性能和灵活性。