以下学习笔记记录于:2024.09.25-2024.09.30
文章目录
- 阶段二 JavaSE进阶
- 第四章 集合框架
- 4-2 List系列集合
- 90 特点、特有方法
- 91 遍历方式
- 92 ArrayList集合的底层原理
- 93 LinkedList集合的底层原理、特有方法
- 94 LinkedList集合的应用场景:栈、队列
- 4-3 Set系列集合
- 95 整体特点
- 96 HashSet集合的底层原理1(哈希表)
- 97 HashSet集合的底层原理2(红黑树)
- 98 HashSet集合去重复机制
阶段二 JavaSE进阶
第四章 集合框架
4-2 List系列集合
90 特点、特有方法
ListTest1.java:
package com.itheima.hello.d3_collection_list;import java.util.ArrayList;
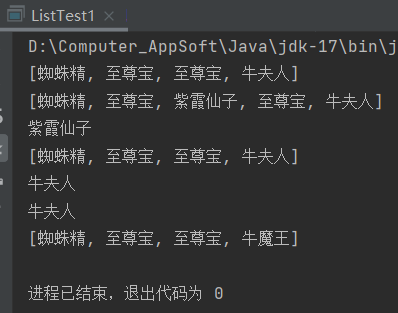
import java.util.List;public class ListTest1 {public static void main(String[] args) {// 1.创建一个ArrayList集合(有序、可重复、有索引)List<String> list = new ArrayList<>(); // 一行经典代码(多态写法)list.add("蜘蛛精");list.add("至尊宝");list.add("至尊宝");list.add("牛夫人");System.out.println(list);// 2.public void add(int index, E element):在某个索引位置插入元素。list.add(2, "紫霞仙子");System.out.println(list);// 3.public E remove(int index):根据索引删除元素,返回被删除元素System.out.println(list.remove(2));System.out.println(list);// 4.public E get(int index):返回集合中指定位置的元素。System.out.println(list.get(3));// 5.public E set(int index, E element):修改索引位置处的元素,修改成功后,会返回原来的数据System.out.println(list.set(3, "牛魔王"));System.out.println(list);}
}
运行结果:
91 遍历方式

ListTest2.java:
package com.itheima.hello.d3_collection_list;import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;public class ListTest2 {public static void main(String[] args) {List<String> list = new ArrayList<>(); // 一行经典代码(多态写法)list.add("蜘蛛精");list.add("至尊宝");list.add("至尊宝");list.add("牛夫人");// 1、for循环【list.fori + 回车】for (int i = 0; i < list.size(); i++) {System.out.println(list.get(i));}System.out.println("---------------");// 2、迭代器Iterator<String> it = list.iterator();while (it.hasNext()){System.out.println(it.next());}System.out.println("---------------");// 3、增强for循环(foreach遍历)【list.for + 回车】for (String s : list) {System.out.println(s);}System.out.println("---------------");// 4、JDK 1.8开始之后的Lambda表达式list.forEach(s -> System.out.println(s));}
}
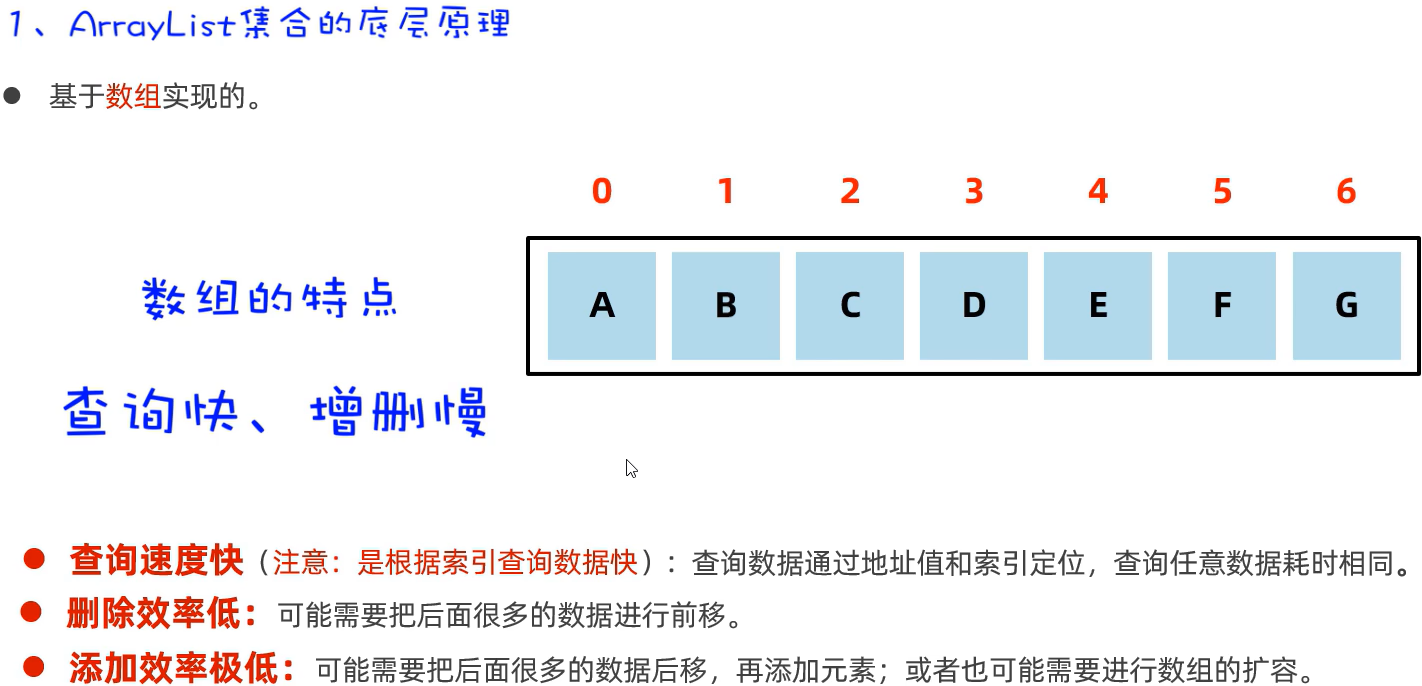
92 ArrayList集合的底层原理
ArrayList集合和LinkedList集合底层采用的**数据结构(存储、组织数据的方式)**不同,应用场景不同


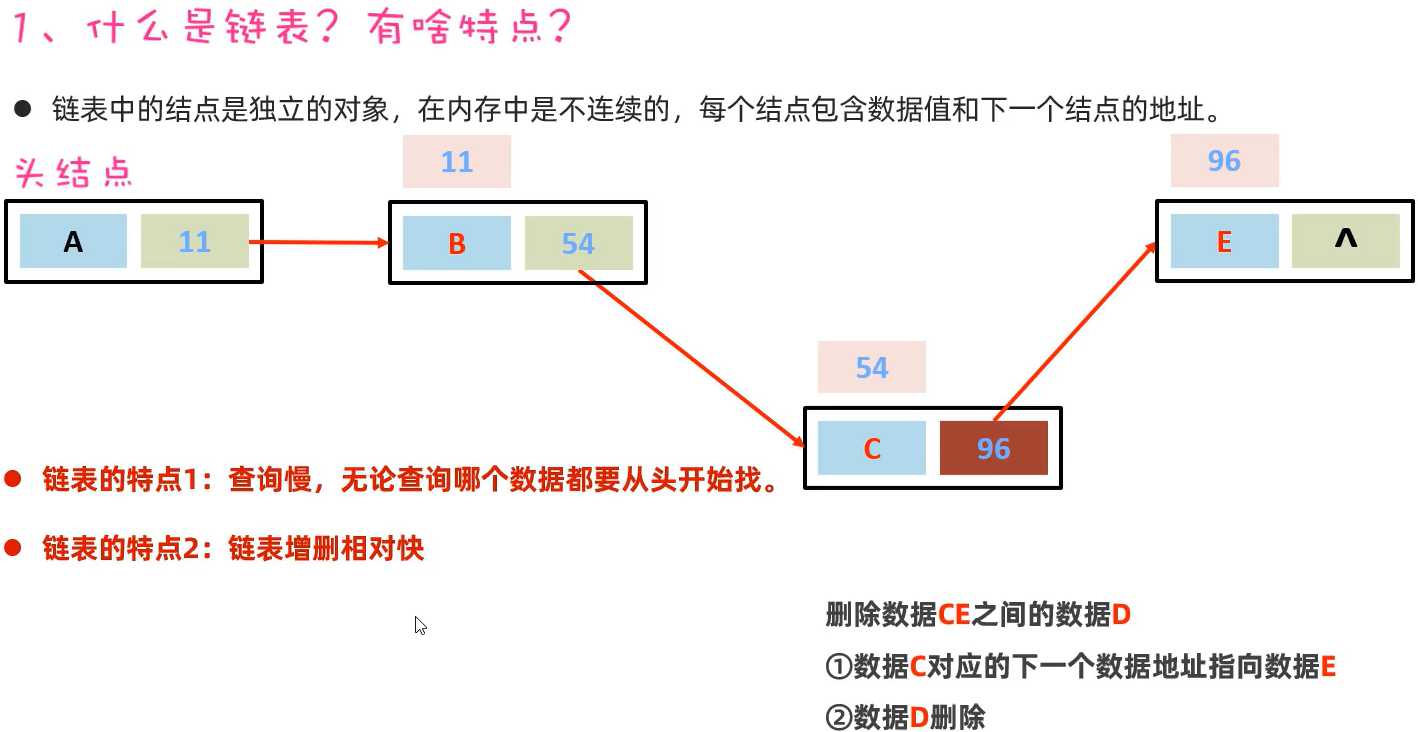
93 LinkedList集合的底层原理、特有方法
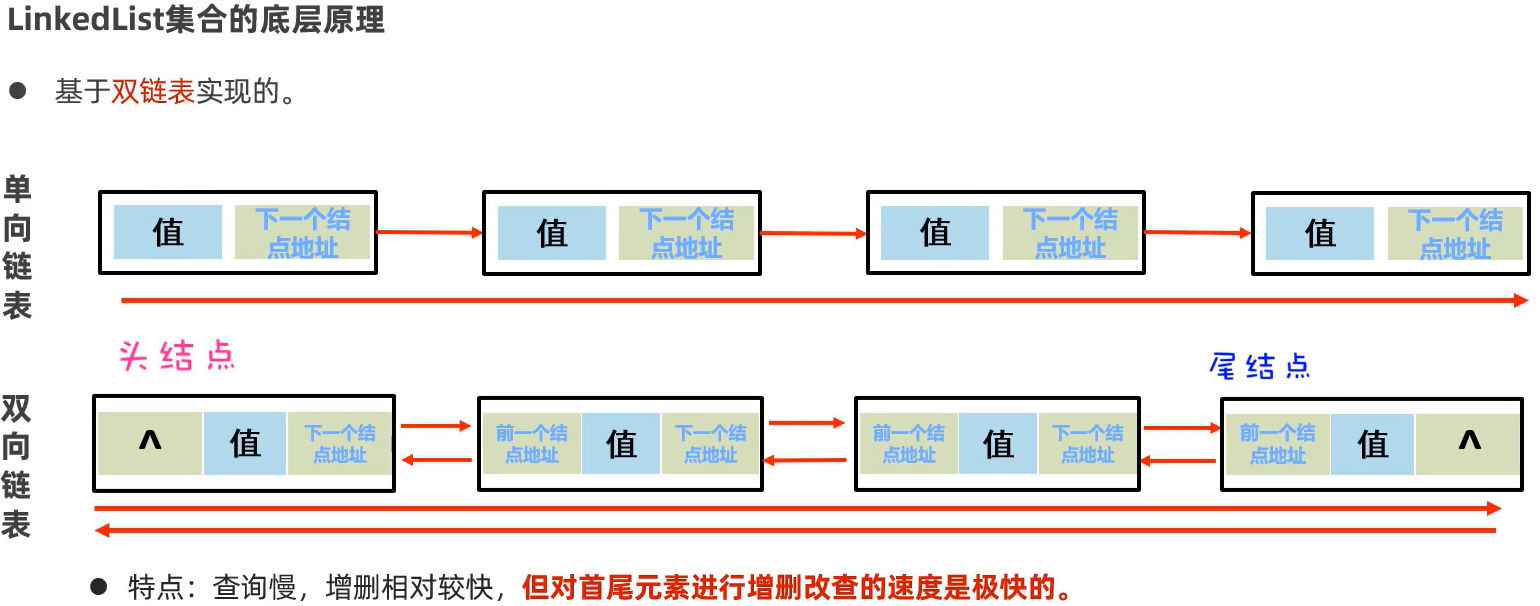

94 LinkedList集合的应用场景:栈、队列
LinkedList集合的应用场景之一:可以用来设计队列(先进先出,后进后出),只在首尾增删元素。
LinkedList集合的应用场景之一:可以用来设计栈(后进先出,先进后出),只在首部增删元素。——> 压/进栈push,弹/出栈pop
package com.itheima.hello.d3_collection_list;import java.util.LinkedList;public class ListTest3 {public static void main(String[] args) {// 1、创建一个队列LinkedList<String> queue = new LinkedList<>(); // 此处不要使用多态写法,因为针对首尾的操作只在LinkedList中有// 入队queue.addLast("第1位客人");queue.addLast("第2位客人");queue.addLast("第3位客人");queue.addLast("第4位客人");System.out.println(queue);// 出队System.out.println(queue.removeFirst());System.out.println(queue.removeFirst());System.out.println(queue);System.out.println("-------------------");// 1、创建一个栈LinkedList<String> stack = new LinkedList<>(); // 此处不要使用多态写法,因为针对首部的操作只在LinkedList中有// 进栈(push)stack.addFirst("第1颗子弹");stack.addFirst("第2颗子弹");stack.addFirst("第3颗子弹");stack.addFirst("第4颗子弹");
// stack.push("第4颗子弹");System.out.println(stack);// 出栈(pop)System.out.println(stack.removeFirst());System.out.println(stack.removeFirst());
// System.out.println(stack.pop());System.out.println(stack);}
}
运行结果:
4-3 Set系列集合
95 整体特点
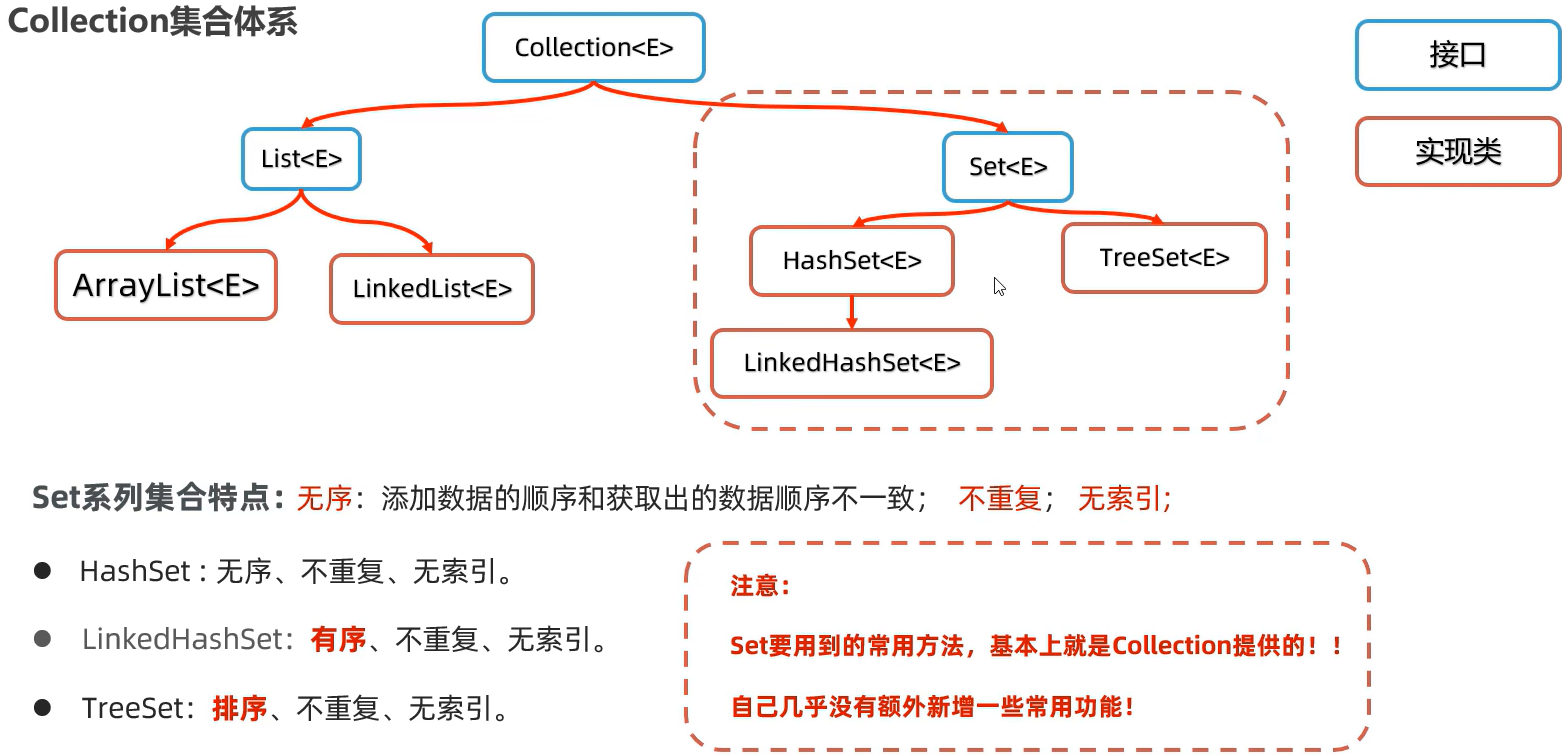
SetTest1.java:
package com.itheima.hello.d4_collection_set;import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Set;
import java.util.TreeSet;public class SetTest1 {public static void main(String[] args) {// 1、创建一个Set集合的对象
// Set<Integer> set = new HashSet<>(); // 创建了一个HashSet(无序 -> 这里的无序只会无序一次,之后都会固定、不重复、无索引)的集合对象。 一行经典代码。 输出[888, 777, 666, 555]
// Set<Integer> set = new LinkedHashSet<>(); // (有序、不重复、无索引) 输出[666, 555, 888, 777]Set<Integer> set = new TreeSet<>(); // (排序 -> 默认升序、不重复、无索引) 输出[555, 666, 777, 888]set.add(666);set.add(666);set.add(555);set.add(888);set.add(888);set.add(777);set.add(777);System.out.println(set);}
}
96 HashSet集合的底层原理1(哈希表)

SetTest2.java:
package com.itheima.hello.d4_collection_set;public class SetTest2 {public static void main(String[] args) {Student s1 = new Student("蜘蛛精", 25, 169.5);Student s2 = new Student("紫霞仙子", 18, 165.0);System.out.println(s1.hashCode());System.out.println(s1.hashCode()); // 同一对象的Hash值相同System.out.println(s2.hashCode()); // 不同对象的Hash值一般不相同(小概率相同)String str1 = new String("abc");String str2 = new String("acD");System.out.println(str1.hashCode());System.out.println(str2.hashCode());}
}
运行结果:



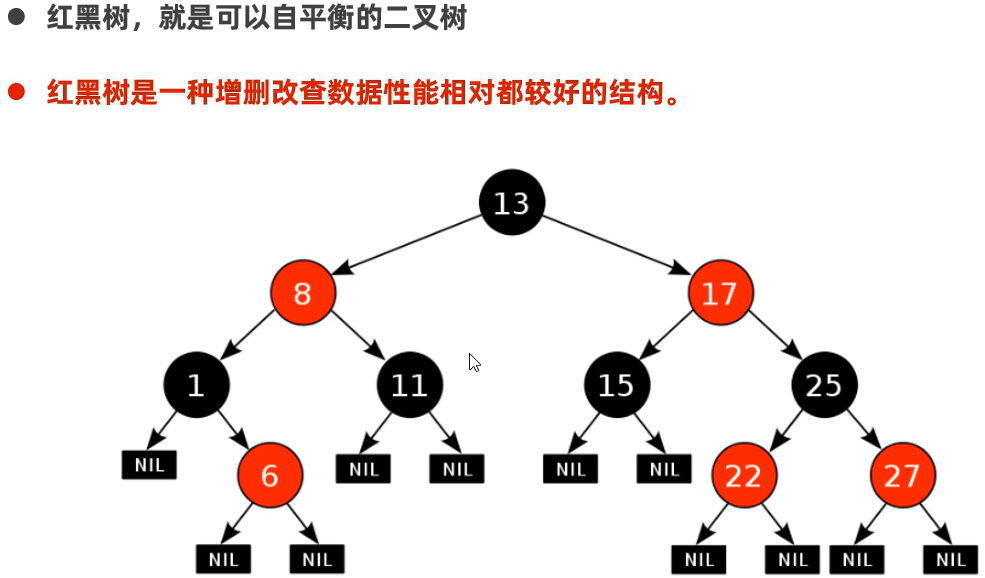
97 HashSet集合的底层原理2(红黑树)
1、如果数组快占满了,会出什么问题?怎么解决?
链表会过长,导致查询性能降低。解决方法:扩容,以“创建一个默认长度16的数组,默认加载因子为0.75”为例,若所存数据超过了16*0.75=12则会扩成原数组的两倍,再将这些数据按算法(哈希值对数组长度求余)重新存入新数组中。
2、若扩容后其链表长度过长又该怎么解决?
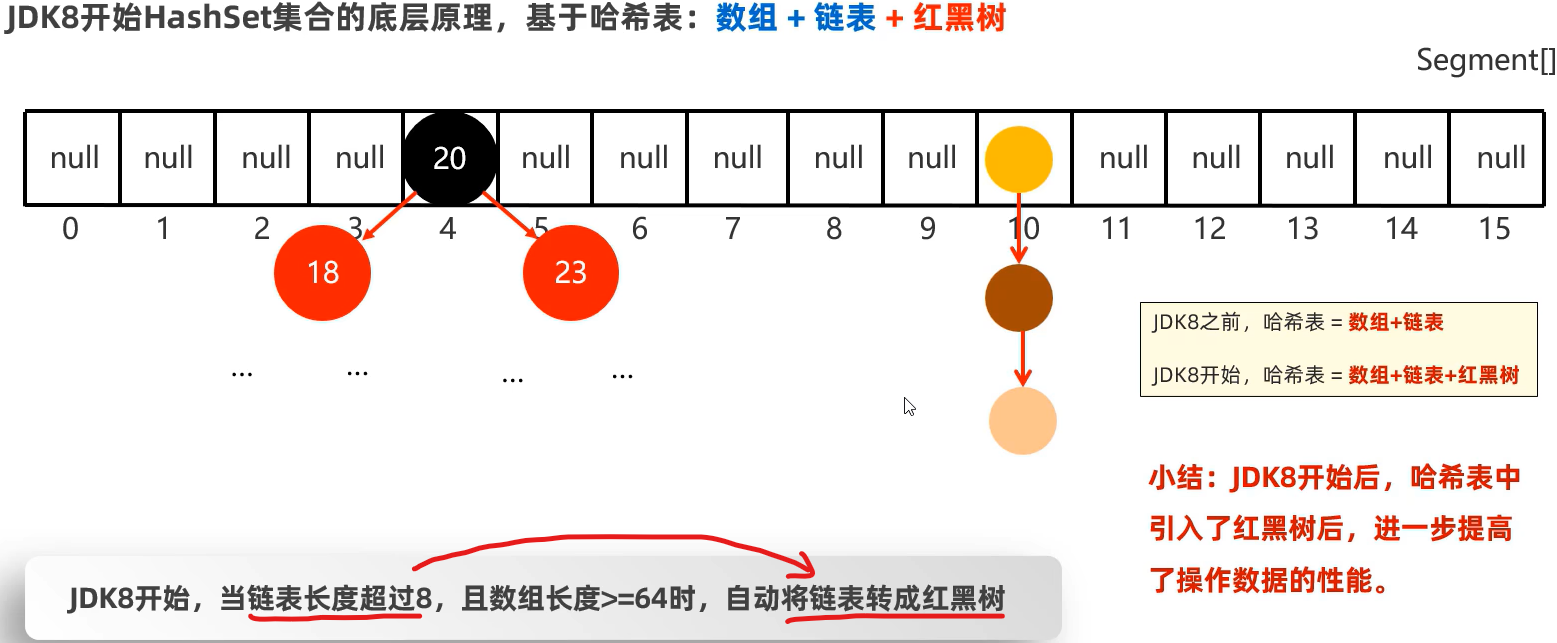
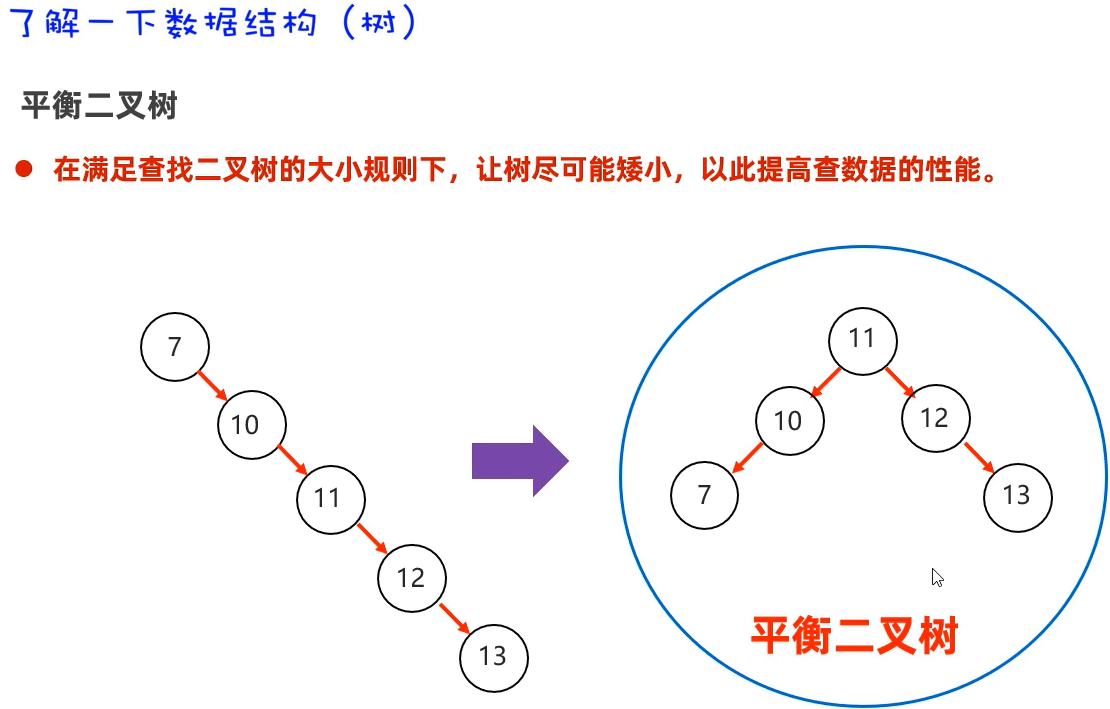
在Java中对于平衡二叉树使用较多:
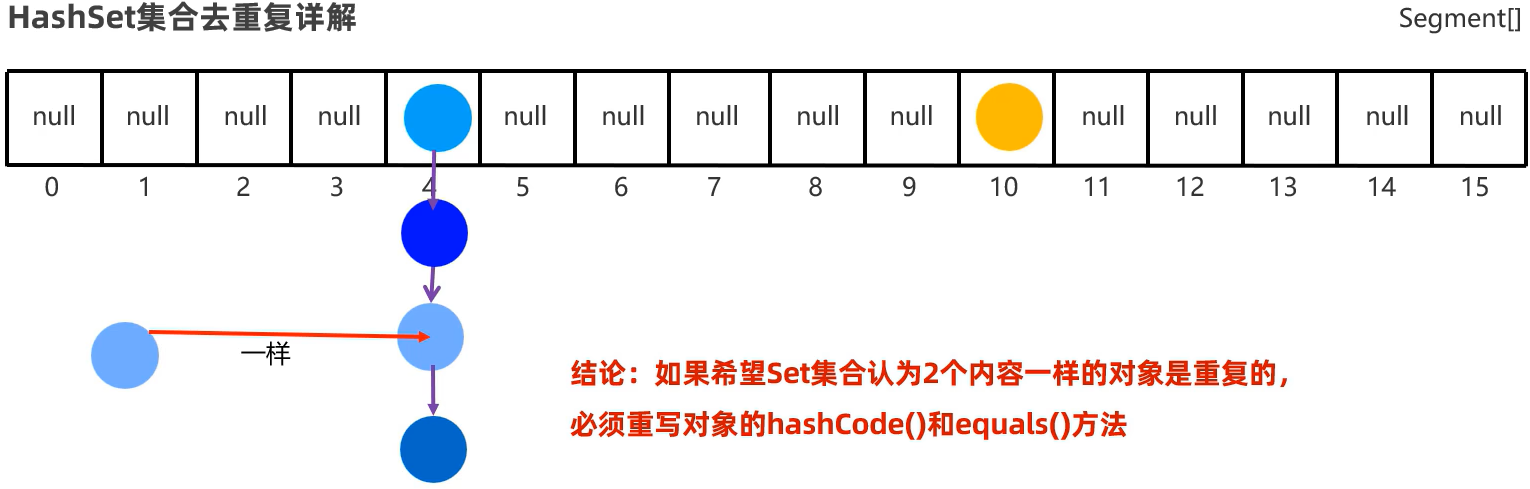
98 HashSet集合去重复机制

- 解决方式:重写hashCode()和equals()方法。
Student.java:
package com.itheima.hello.d4_collection_set;import java.util.Objects;public class Student {private String name;private int age;private double height;public Student() {}public Student(String name, int age, double height) {this.name = name;this.age = age;this.height = height;}// 只要两个对象内容一样就返回true@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age && Double.compare(student.height, height) == 0 && Objects.equals(name, student.name);}// 只要两个对象内容一样,返回的哈希值就是一样的@Overridepublic int hashCode() {return Objects.hash(name, age, height);}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public double getHeight() {return height;}public void setHeight(double height) {this.height = height;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +", height=" + height +'}';}
}
SetTest3.java:
package com.itheima.hello.d4_collection_set;import java.util.HashSet;
import java.util.Set;public class SetTest3 {public static void main(String[] args) {Set<Student> students = new HashSet<>();Student s1 = new Student("蜘蛛精", 25, 169.5);Student s2 = new Student("紫霞仙子", 18, 165.0);Student s3 = new Student("紫霞仙子", 18, 165.0);System.out.println(s2.hashCode());System.out.println(s3.hashCode());Student s4 = new Student("牛魔王", 230, 190.8);students.add(s1);students.add(s2);students.add(s3);students.add(s4);System.out.println(students);}
}
运行结果:
