💛前情提要💛
本文是传知代码平台中的相关前沿知识与技术的分享~
接下来我们即将进入一个全新的空间,对技术有一个全新的视角~
本文所涉及所有资源均在传知代码平台可获取
以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦!!!
以下内容干货满满,跟上步伐吧~
📌导航小助手📌
- 💡本章重点
- 🍞一. 概述
- 🍞二. 主要贡献
- 🍞三. 技术细节
- 🍞四. 实验结果
- 🫓总结
💡本章重点
- LLaMA 开放高效基础语言模型
🍞一. 概述
论文跳转
这篇文章介绍了一个名为LLaMA的新型基础语言模型系列,这些模型由Meta AI开发,包含从7亿到65亿参数不等的多个版本。LLaMA模型完全使用公开可用的数据集进行训练,不依赖于私有或难以获取的数据集。研究表明,通过在更多的数据上训练,而不是仅仅增加模型大小,可以在给定的计算预算下实现更好的性能。特别是,LLaMA-13B在多数基准测试中超过了GPT-3(175B参数),而65B参数版本的LLaMA与Chinchilla-70B和PaLM-540B等顶尖模型具有竞争力。
文章还讨论了LLaMA模型在不同推理预算下的性能,强调了在大规模部署语言模型时推理效率的重要性。此外,文章还详细介绍了训练方法、数据预处理、模型架构、优化器选择以及训练过程中的效率优化技术。
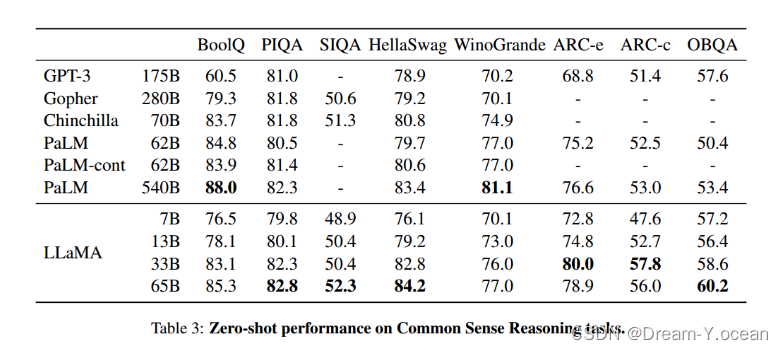
LLaMA模型在多种自然语言处理任务上的表现进行了评估,包括常识推理、闭卷问答、阅读理解、数学推理和代码生成等,并与其他大型语言模型进行了比较。结果表明,LLaMA在多数任务上展现出了强大的性能。
文章还探讨了模型可能存在的偏见、有害内容和错误信息的问题,并使用最新的基准测试来评估这些问题。此外,文章讨论了模型训练过程中的能耗和碳足迹问题,并与其它模型进行了比较。
最后,文章总结了LLaMA模型的贡献,并指出了未来工作的方向,包括进一步研究指令微调(instruction finetuning)以及发布更大模型的计划。作者希望LLaMA模型的公开发布能够推动大型语言模型的发展,并帮助解决如鲁棒性、偏见和有害内容等问题。
🍞二. 主要贡献
文章的主要贡献可以概括为以下几点:
-
LLaMA模型系列: 介绍了从7B到65B参数的一系列基础语言模型,这些模型在不同的推理预算下展现了优异的性能。
-
公开可用数据集训练: 证明了使用公开可用的数据集可以训练出与现有顶尖模型相竞争的语言模型,无需依赖私有或难以获取的数据集。
-
性能超越: 特别是LLaMA-13B在大多数基准测试中超过了参数规模更大的GPT-3(175B参数),显示了在给定计算预算下,通过在更多数据上训练较小模型可以获得更好的性能。
-
模型架构和训练方法: 文章详细介绍了对Transformer架构的改进,包括预归一化、SwiGLU激活函数和旋转嵌入(Rotary Embeddings),以及所使用的AdamW优化器和学习率调度策略。
-
效率优化: 提出了一系列训练速度优化技术,包括高效的因果多头注意力实现、激活复用和模型/序列并行化,显著提高了模型训练的效率。
-
多任务性能评估: 在多种自然语言处理任务上评估了LLaMA模型的性能,包括常识推理、闭卷问答、阅读理解、数学推理和代码生成等。
-
偏见和有害内容分析: 探讨了模型可能存在的偏见和有害内容问题,并使用最新的基准测试进行了评估。
-
环境影响考量: 讨论了模型训练过程中的能耗和碳足迹问题,并与其它模型进行了比较,强调了可持续发展的重要性。
-
开放研究社区: 作者承诺将所有LLaMA模型发布给研究社区,以促进大型语言模型的发展和研究。
-
未来工作方向: 提出了未来工作的方向,包括进一步研究指令微调以及发布更大模型的计划。
这些贡献展示了LLaMA模型在性能、效率和可访问性方面的重要进步,并为未来的研究和开发提供了新的可能性。
🍞三. 技术细节
预训练数据构成
文章中提到的LLaMA模型的训练数据构成是多样化的,主要由以下几个数据源混合组成:
-
English CommonCrawl: 占训练数据集的67%。使用了2017年至2020年的五个CommonCrawl数据转储,并通过CCNet管道进行预处理,包括数据去重、语言识别以及过滤低质量内容。
-
C4: 占15%。在探索性实验中,发现使用多样化的预处理CommonCrawl数据集可以提升性能,因此包含了公开可用的C4数据集。C4的预处理同样包含去重和语言识别步骤,主要区别在于质量过滤,这主要依赖于一些启发式规则,如标点符号的存在或网页中的单词和句子数量。
-
Github: 占4.5%。使用了在Google BigQuery上公开可用的Github数据集,并只保留了在Apache、BSD和MIT许可下的项目。通过基于行长度或字母数字字符比例的启发式规则过滤低质量文件,并使用正则表达式移除样板文件,如头部信息,并在文件级别进行去重。
-
Wikipedia: 占4.5%。添加了2022年6月至8月期间的Wikipedia转储,涵盖了使用拉丁或西里尔字母的20种语言。
-
Gutenberg 和 Books3: 占4.5%。训练数据集包括公共领域的古腾堡项目书籍和ThePile的Books3部分,ThePile是一个公开可用的用于训练大型语言模型的数据集。在书籍级别进行去重,移除内容重叠超过90%的书籍。
-
ArXiv: 占2.5%。处理arXiv Latex文件以添加科学数据到数据集中。移除了tex文件中的评论,并且展开内联定义和宏以提高论文间的一致性。
-
Stack Exchange: 占2%。包含了Stack Exchange的转储,这是一个涵盖从计算机科学到化学等多样化领域的高质量问答网站。保留了28个最大子网站的数据处理,从最高到最低对答案进行排序,并从文本中移除了HTML标签。
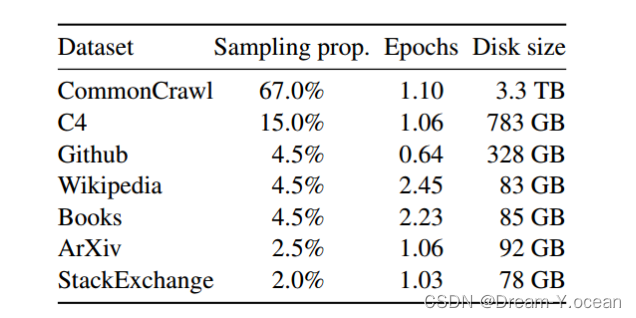
这些数据源被混合使用,并在模型训练中占据了不同的比例。文章中还提到,对于大多数训练数据,每个标记在训练中只使用一次,但对Wikipedia和Books领域的数据进行了大约两个epoch的训练。整个训练数据集在标记化后大约包含1.4T个tokens。
分词器
文章中提到的模型使用的分词器是基于字节对编码(Byte Pair Encoding, BPE)算法实现的。具体来说,使用的是SentencePiece的实现。在分词过程中,所有的数字被拆分成单独的数字,并且对于未知的UTF-8字符,会退回到字节来进行分解。这种分词方法有助于处理各种语言和符号,因为BPE是一种可以适应不同数据集的子词分词技术。
下面可以简单介绍一下BPE:
BPE(Byte-Pair Encoding)编码,就是一种根据频率切分语料的方法,能够将原始语料切分为subword,输入也不受限制,应该是字符就行。

例如我们的语料为最左边的那些,(2 bed 表示语料中出现了2次bed这个词)我们先按照字符级全都切分,就得到了初始的词汇字典
然后我们开始寻找出现频率最多的pair(字符对)

可以看到语料中频率最高的pair为st,此时就可以将这个pair合成一个字符,加入词汇字典里,然后继续。

然后发现未处理的pair中b 和 e这对pair是频率是最高的,此时将be加入到词汇字典中
然后会发现剩下的pair频率没有超过一次了,那么可以结束运算了
此时就得到了我们的subword字典了
此时我们的pair表就完成了,当进入一个新词时,例如best,我们就通过pair table进行字词的划分,从频率从高到低来进行划分。
首先best开始的时候分为 b e s t 四个字符
然后对着最右边的表,发现s和t可以合并为一个字符,此时就变为b e s t
继续,发现 e 和 st 可以合并,此时就变为b est
继续,发现不能并了,就结束了
但是为了我们能够方便地还原初始词,我们可以在字词后面(除了最后一个之外)加入一些特定的字符
例如我们加入@@
那么最后best就划分为 b@@ est 两部分了。
那么我们得到了字词字典,就弄个embedding来表示字词,词语切分为字词后就能够被表示出来,实验证明这种方法,即能够很好的限制字典大小,也能保证性能正常。
模型结构
文章中提到的LLaMA模型的结构基于Transformer架构,这是当前自然语言处理领域中广泛使用的模型架构之一。LLaMA模型在原始Transformer架构的基础上进行了一些改进,主要包括以下几点:
-
预归一化(Pre-normalization):为了提高训练稳定性,在每个Transformer子层的输入端进行归一化,而不是只在输出端。使用的是RMSNorm归一化函数。
-
SwiGLU激活函数:替换了传统的ReLU非线性激活函数,使用了SwiGLU激活函数来提升性能。在LLaMA模型中,激活函数的维度是2/3d。
-
旋转嵌入(Rotary Embeddings):移除了绝对位置嵌入,改为在网络的每层添加旋转位置嵌入(RoPE),这是一种改善模型对序列顺序敏感性的方法。
优化器: 使用的是AdamW优化器,设置了特定的超参数,包括学习率调度、权重衰减和梯度裁剪。
🍞四. 实验结果
🫓总结
综上,我们基本了解了“一项全新的技术啦” 🍭 ~~
恭喜你的内功又双叒叕得到了提高!!!
感谢你们的阅读😆
后续还会继续更新💓,欢迎持续关注📌哟~
💫如果有错误❌,欢迎指正呀💫
✨如果觉得收获满满,可以点点赞👍支持一下哟~✨
【传知科技 – 了解更多新知识】