📢作者: 小小明-代码实体
📢博客主页:https://blog.csdn.net/as604049322
📢欢迎点赞 👍 收藏 ⭐留言 📝 欢迎讨论!
昨天我们处理Word文档的自动编号,详见《Python解析Word文档的自动编号》
链接:https://xxmdmst.blog.csdn.net/article/details/139638262
今天我们处理一下Word文档的目录和文本框,例如:

如果我们按照传统方式读取,是无法读取目录和文本框的。
这时,我们只需要想办法目录和文本框中的P节点与普通P节点一起被读取即可。
查看其xml结构后知道,w:sdt是目录节点,文本框节点存在于p里面的v:textbox节点下。
可以写出如下代码:
from docx import Document
from docx.oxml import ns
from docx.text.paragraph import Paragraphdoc = Document('目录测试.docx')ns.nsmap.update(doc.element.nsmap)
body = doc.element.body
paragraphs = []
for p in body.xpath('w:p | w:sdt/w:sdtContent/w:p | w:p//v:textbox//w:p'):paragraphs.append(Paragraph(p, body))
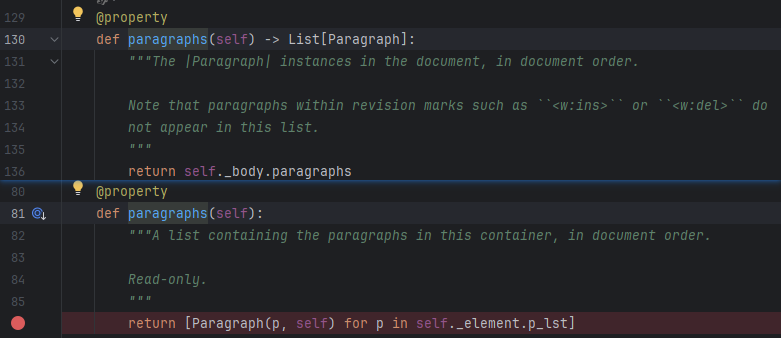
注意上面的代码使用Paragraph(p, body)封装是为了让paragraphs的结果类型与doc.paragraphs保存一致,可以看到其源码为:
如果不需要Paragraph的特殊功能,仅做基本的数据读取,也可以不封装。
然后就能将普通段落和目录内的段落以及文本框内的段落,都按顺序读取:
for paragraph in paragraphs:print(paragraph.text)
如果这时,我们需要将自动编号也读取进来,需要注意文本框内的段落是单独计数的。
最后我们将该功能整合到上次的代码中:
import refrom docx import Document
from docx.oxml.ns import qn, nsmap
from docx.text.paragraph import Paragraphclass WithNumberDocxReader:ideographTraditional = "甲乙丙丁戊己庚辛壬癸"ideographZodiac = "子丑寅卯辰巳午未申酉戌亥"def __init__(self, docx, gap_text="\t"):self.docx = Document(docx)nsmap.update(self.docx.element.nsmap)self.numId2style = self.get_style_data()self.gap_text = gap_textself.cnt = {}self.cache = {}self.result = []@propertydef texts(self):if self.result:return self.result.copy()self.clear()for paragraph in self.paragraphs:number_text = self.get_number_text(paragraph)self.result.append(number_text + paragraph.text)return self.result.copy()def clear(self):self.result.clear()self.cnt.clear()self.cache.clear()@propertydef paragraphs(self):body = self.docx.element.bodyresult = []for p in body.xpath('w:p | w:sdt/w:sdtContent/w:p | w:p//v:textbox//w:p'):result.append(Paragraph(p, body))return resultdef get_style_data(self):numbering_part = self.docx.part.numbering_part._elementabstractId2numId = {num.abstractNumId.val: num.numId for num in numbering_part.num_lst}numId2style = {}for abstractNumIdTag in numbering_part.findall(qn("w:abstractNum")):abstractNumId = abstractNumIdTag.get(qn("w:abstractNumId"))numId = abstractId2numId[int(abstractNumId)]for lvlTag in abstractNumIdTag.findall(qn("w:lvl")):ilvl = lvlTag.get(qn("w:ilvl"))style = {tag.tag[tag.tag.rfind("}") + 1:]: tag.get(qn("w:val"))for tag in lvlTag.xpath("./*[@w:val]", namespaces=nsmap)}if "numFmt" not in style:numFmtVal = lvlTag.xpath("./mc:AlternateContent/mc:Fallback/w:numFmt/@w:val",namespaces=nsmap)if numFmtVal and numFmtVal[0] == "decimal":numFmt_format = lvlTag.xpath("./mc:AlternateContent/mc:Choice/w:numFmt/@w:format",namespaces=nsmap)if numFmt_format:style["numFmt"] = "decimal" + numFmt_format[0].split(",")[0]if style.get("numFmt") == "decimalZero":style["numFmt"] = "decimal01"numId2style[(numId, int(ilvl))] = stylereturn numId2style@staticmethoddef int2upperLetter(num):result = []while num > 0:num -= 1remainder = num % 26result.append(chr(remainder + ord('A')))num //= 26return "".join(reversed(result))@staticmethoddef int2upperRoman(num):t = [(1000, 'M'), (900, 'CM'), (500, 'D'),(400, 'CD'), (100, 'C'), (90, 'XC'),(50, 'L'), (40, 'XL'), (10, 'X'),(9, 'IX'), (5, 'V'), (4, 'IV'), (1, 'I')]roman_num = ''i = 0while num > 0:val, syb = t[i]for _ in range(num // val):roman_num += sybnum -= vali += 1return roman_num@staticmethoddef int2cardinalText(num):if not isinstance(num, int) or num < 0 or num > 999999999:raise ValueError("Invalid number: must be a positive integer within four digits")base = ["Zero", "One", "Two", "Three", "Four", "Five", "Six","Seven", "Eight", "Nine", "Ten", "Eleven", "Twelve", "Thirteen", "Fourteen","Fifteen", "Sixteen", "Seventeen", "Eighteen", "Nineteen"]tens = ["", "", "Twenty", "Thirty", "Fourty","Fifty", "Sixty", "Seventy", "Eighty", "Ninety"]thousands = ["", "Thousand", "Million", "Billion"]def two_digits(n):if n < 20:return base[n]ten, unit = divmod(n, 10)if unit == 0:return f"{tens[ten]}"else:return f"{tens[ten]}-{base[unit]}"def three_digits(n):hundred, rest = divmod(n, 100)if hundred == 0:return two_digits(rest)result = f"{base[hundred]} hundred "if rest > 0:result += two_digits(rest)return result.strip()if num < 99:return two_digits(num)chunks = []while num > 0:num, remainder = divmod(num, 1000)chunks.append(remainder)words = []for i in range(len(chunks) - 1, -1, -1):if chunks[i] == 0:continuechunk_word = three_digits(chunks[i])if thousands[i]:chunk_word += f" {thousands[i]}"words.append(chunk_word)words = " ".join(words).lower()return words[0].upper() + words[1:]@staticmethoddef int2ordinalText(num):if not isinstance(num, int) or num < 0 or num > 999999:raise ValueError("Invalid number: must be a positive integer within four digits")base = ["Zero", "One", "Two", "Three", "Four", "Five", "Six","Seven", "Eight", "Nine", "Ten", "Eleven", "Twelve", "Thirteen", "Fourteen","Fifteen", "Sixteen", "Seventeen", "Eighteen", "Nineteen"]baseth = ['Zeroth', 'First', 'Second', 'Third', 'Fourth', 'Fifth', 'Sixth', 'Seventh','Eighth', 'Ninth', 'Tenth', 'Eleventh', 'Twelfth', 'Thirteenth', 'Fourteenth','Fifteenth', 'Sixteenth', 'Seventeenth', 'Eighteenth', 'Nineteenth', 'Twentieth']tens = ["", "", "Twenty", "Thirty", "Fourty","Fifty", "Sixty", "Seventy", "Eighty", "Ninety"]tensth = ["", "", "Twentieth", "Thirtieth", "Fortieth","Fiftieth", "Sixtieth", "Seventieth", "Eightieth", "Ninetieth"]def two_digits(n):if n <= 20:return baseth[n]ten, unit = divmod(n, 10)result = tensth[ten]if unit != 0:result = f"{tens[ten]}-{baseth[unit]}"return resultthousand, num = divmod(num, 1000)result = []if thousand > 0:if num == 0:return f"{WithNumberDocxReader.int2cardinalText(thousand)} thousandth"result.append(f"{WithNumberDocxReader.int2cardinalText(thousand)} thousand")hundred, num = divmod(num, 100)if hundred > 0:if num == 0:result.append(f"{base[hundred]} hundredth")return " ".join(result)result.append(f"{base[hundred]} hundred")result.append(two_digits(num))result = " ".join(result).lower()return result[0].upper() + result[1:]@staticmethoddef int2Chinese(num, ch_num, units):if not (0 <= num <= 99999999):raise ValueError("仅支持小于一亿以内的正整数")def int2Chinese_in(num, ch_num, units):if not (0 <= num <= 9999):raise ValueError("仅支持小于一万以内的正整数")result = [ch_num[int(i)] + unit for i, unit in zip(reversed(str(num).zfill(4)), units)]result = "".join(reversed(result))zero_char = ch_num[0]result = re.sub(f"(?:{zero_char}[{units}])+", zero_char, result)result = result.rstrip(units[0])if result != zero_char:result = result.rstrip(zero_char)if result.lstrip(zero_char).startswith("一十"):result = result.replace("一", "")return resultif num < 10000:result = int2Chinese_in(num, ch_num, units)else:left = num // 10000right = num % 10000result = int2Chinese_in(left, ch_num, units) + "万" + int2Chinese_in(right, ch_num, units)if result != ch_num[0]:result = result.strip(ch_num[0])return result@staticmethoddef int2ChineseCounting(num):return WithNumberDocxReader.int2Chinese(num, ch_num='〇一二三四五六七八九', units='个十百千')@staticmethoddef int2ChineseLegalSimplified(num):return WithNumberDocxReader.int2Chinese(num, ch_num='零壹贰叁肆伍陆柒捌玖', units='个拾佰仟')def get_number_text(self, paragraph):numpr = paragraph._element.pPr.numPr# paragraph.getparent().tagif numpr is None or numpr.numId.val == 0:return ""numId = numpr.numId.valilvl = numpr.ilvl.valstyle = self.numId2style[(numId, ilvl)]numFmt: str = style.get("numFmt")lvlText = style.get("lvlText")isTxbxContent = paragraph._element.getparent().tag.endswith("txbxContent")pos_key = (numId, ilvl, isTxbxContent)if pos_key in self.cnt:self.cnt[pos_key] += 1else:self.cnt[pos_key] = int(style["start"])pos = self.cnt[pos_key]num_text = str(pos)if numFmt.startswith('decimal'):num_text = num_text.zfill(numFmt.count("0") + 1)elif numFmt == 'upperRoman':num_text = self.int2upperRoman(pos)elif numFmt == 'lowerRoman':num_text = self.int2upperRoman(pos).lower()elif numFmt == 'upperLetter':num_text = self.int2upperLetter(pos)elif numFmt == 'lowerLetter':num_text = self.int2upperLetter(pos).lower()elif numFmt == 'ordinal':num_text = f"{pos}{'th' if 11 <= pos <= 13 else {1: 'st', 2: 'nd', 3: 'rd'}.get(pos % 10, 'th')}"elif numFmt == 'cardinalText':num_text = self.int2cardinalText(pos)elif numFmt == 'ordinalText':num_text = self.int2ordinalText(pos)elif numFmt == 'ideographTraditional':if 1 <= pos <= 10:num_text = self.ideographTraditional[pos - 1]elif numFmt == 'ideographZodiac':if 1 <= pos <= 12:num_text = self.ideographZodiac[pos - 1]elif numFmt == 'chineseCounting':num_text = self.int2ChineseCounting(pos)elif numFmt == 'chineseLegalSimplified':num_text = self.int2ChineseLegalSimplified(pos)elif numFmt == 'decimalEnclosedCircleChinese':passself.cache[pos_key] = num_textfor i in range(0, ilvl + 1):lvlText = lvlText.replace(f'%{i + 1}', self.cache.get((numId, i, isTxbxContent), ""))suff_text = {"space": " ", "nothing": ""}.get(style.get("suff"), self.gap_text)lvlText += suff_textreturn lvlText
测试一下:
if __name__ == '__main__':doc = WithNumberDocxReader(r"目录测试.docx", "")for text in doc.texts:print(text)
结果顺利正确打印:
35.甲公司为增值税一般纳税人,委托外单位加工一批应交消费税的商品,以银行存款支付 加工费200万元、增值税税额26万元、消费税税额30万元(由受托方代收代缴),该批 商品收回后将直接用于销售。甲公司支付上述相关款项时,应编制的会计分录是( )。
A. 借:委托加工物资 256
贷:银行存款 256
B.借:委托加工物资 230
应交税费——应交增值税(进项税额) 26
贷:银行存款 256
C. 借:委托加工物资 200
应交税费 应交增值税(进项税额) 26
——应交消费税 30
贷:银行存款 256
D. 借:委托加工物资 256
贷:银行存款 200
应交税费——应交增值税(销项税额) 26
——应交消费税 30
A.已确认销售收入但尚未发出商品
B.结转完工入库产品成本
C.已收到材料但尚未收到发票账单
D.已收到发票账单并付款但尚未收到材料36.下列各项中,不会引起企业期末存货账面价值发生变动的是( )。A.已确认销售收入但尚未发出商品
B.结转完工入库产品成本
C.已收到材料但尚未收到发票账单
D.已收到发票账单并付款但尚未收到材料以上是文本框的内容。再次编号:
E.已确认销售收入但尚未发出商品
F.结转完工入库产品成本
G.已收到材料但尚未收到发票账单
H.已收到发票账单并付款但尚未收到材料