- 论文题目:Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution
- 发布期刊:ECCV
- 通讯地址:麻省理工 & 清华大学
- 代码地址:https://github.com/mit-han-lab/spvnas

介绍
这篇论文的主题是如何为自驾车等应用场景设计高效的3D架构。论文提出了一个名为“稀疏点-体素卷积”(Sparse Point-Voxel Convolution, SPVConv)的3D深度学习模块,旨在在硬件资源有限的情况下提高3D感知模型对小目标(如行人和骑行者)的识别性能。传统的体素化方法由于分辨率低或过度下采样,导致模型难以识别这些小目标。SPVConv通过在标准的稀疏卷积基础上引入高分辨率的点云分支,显著提升了对细节的捕捉能力,并且计算开销很小。
为了进一步优化3D模型,论文还提出了3D神经架构搜索(3D-NAS)方法,它能够在一个多样化的设计空间中搜索出最优的3D网络架构。实验结果表明,基于SPVConv的SPVNAS模型在速度和准确性上均优于当前的最先进模型,如MinkowskiNet,在语义分割任务中提升了3.3%的mIoU,并实现了8倍的计算效率提升和3倍的推理速度加快。此外,SPVNAS还被成功应用于3D目标检测任务中,表现出了一致的性能提升。
总结来看,该论文的贡献包括:
- 设计了一个轻量级的3D卷积模块SPVConv,专门提升在硬件资源受限情况下对小目标的识别能力。
- 提出了首个用于3D场景理解的自动化机器学习框架3D-NAS,能够在给定资源约束下找到最优3D模型。
- 实验结果表明,该方法在多个数据集上的性能优于以往方法,并在语义KITTI排行榜上取得了第一名的成绩。


核心思想
SPVConv
SPVConv(Sparse Point-Voxel Convolution)的核心思想是在稀疏卷积的基础上,引入一个高分辨率的点云分支,以解决传统3D卷积方法中由于低分辨率体素化或过度下采样导致小目标识别能力不足的问题。具体来说,SPVConv通过结合稀疏体素卷积和点云卷积,实现了在保持高效计算的同时,更好地捕捉场景中的细节信息。
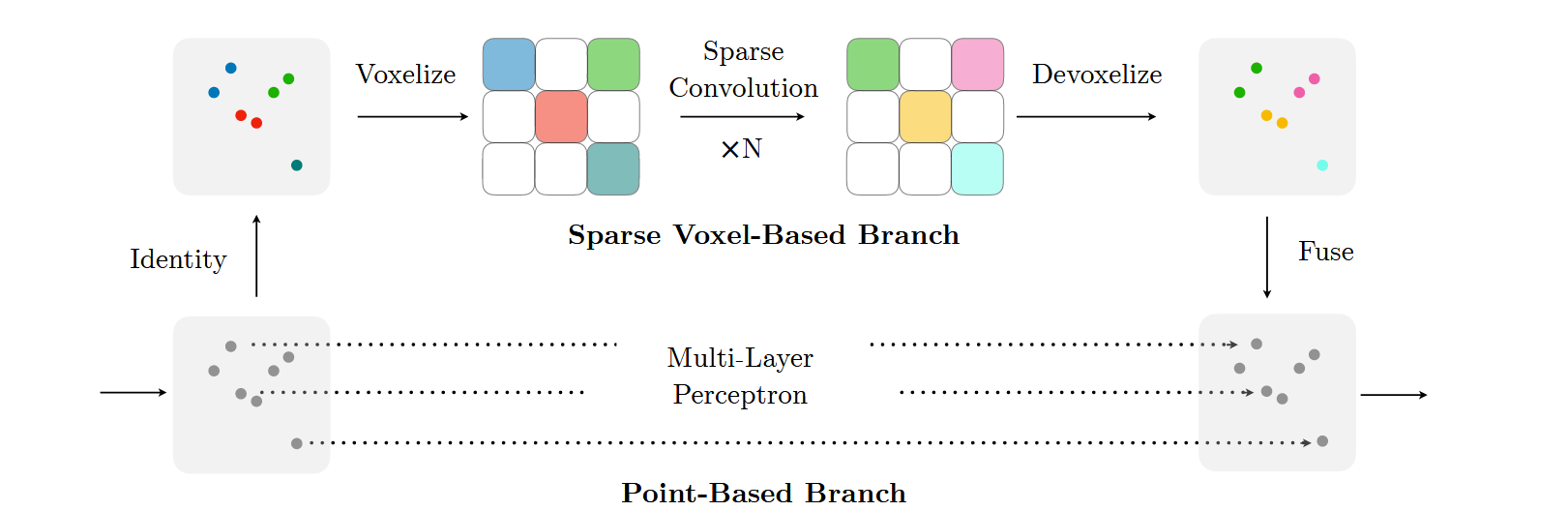
SPVConv的核心思想可以分为以下几个方面:
-
稀疏体素卷积:稀疏卷积通过只对非空体素执行卷积运算,减少了计算开销,并且能够在较大场景中保持较高的空间分辨率。稀疏卷积方法有效地利用了3D数据的稀疏性,减少了对无关区域的计算。
-
高分辨率点云分支:为了弥补稀疏卷积在处理小目标时的不足,SPVConv加入了一个点云分支。这个分支处理高分辨率的点云数据,不需要像体素化那样通过下采样来减少数据量,因此能够保留更多的细节信息,特别是针对小目标(如行人、自行车)的细节。
-
体素化和去体素化操作:SPVConv通过体素化(将点云数据转换为体素网格)和去体素化(将稀疏体素特征重新映射回点云空间)操作,在两个分支之间交换信息。这种操作成本很低,但可以让稀疏卷积和点云卷积分支共享和融合特征,从而提升整体的表现。
-
特征融合:稀疏体素分支和高分辨率点云分支的特征在每一层进行融合。稀疏卷积为场景提供全局上下文信息,而点云分支则为小目标和边缘区域提供细粒度的特征表示。两者的融合使得模型在保持全局感知能力的同时,增强了对细节的捕捉能力。
通过这种稀疏体素和高分辨率点云相结合的方式,SPVConv不仅减少了计算负担,而且提高了对细节的识别能力,特别是对于复杂场景中的小目标。
3D-NAS
3D-NAS(3D Neural Architecture Search)的核心思想是通过自动化的神经架构搜索(NAS)技术,针对3D场景理解任务找到最优的网络架构,从而在满足特定资源约束的条件下,最大化3D模型的性能。与手工设计网络相比,3D-NAS能够高效搜索并优化模型,使其在计算资源受限的环境中(例如自驾车系统的低功耗需求)保持高准确性和低延迟。
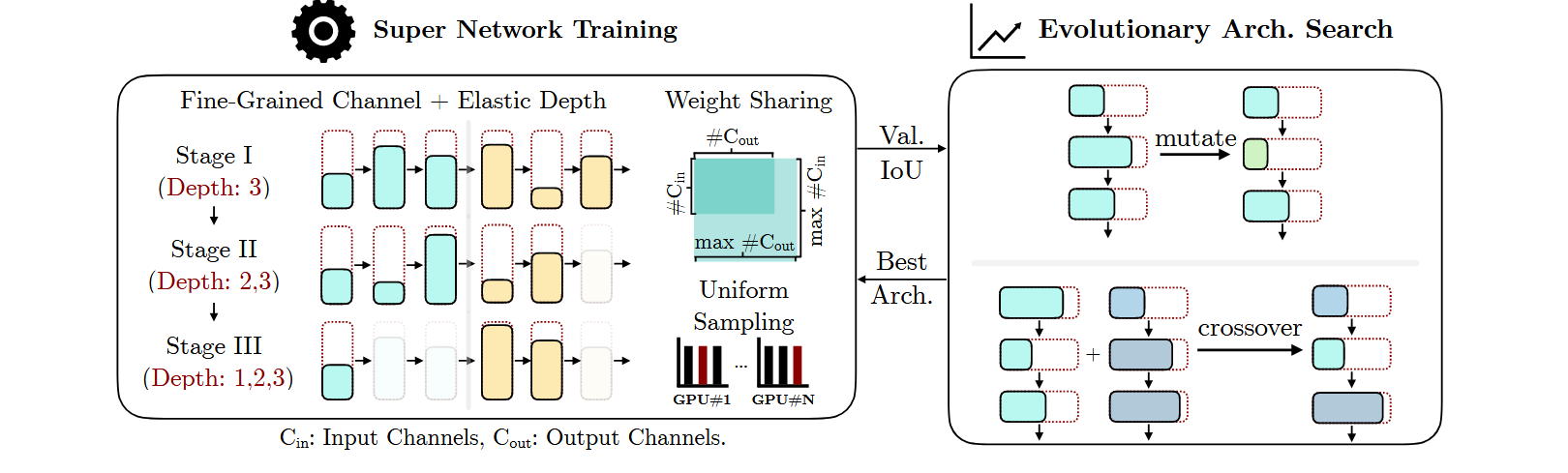
3D-NAS的核心思想可以总结为以下几个关键点:
1. 定义搜索空间
3D-NAS首先定义了一个灵活的网络架构搜索空间,包括网络层的通道数量、网络深度等设计参数。这些参数控制着每一层的卷积通道数和模型的深浅,从而允许搜索算法在一个多样化的架构空间中寻找最佳配置。
- 细粒度的通道数选择:不同于传统NAS中对通道数的粗粒度调整(如只提供2-3个选项),3D-NAS提供了更多通道数的选项,从而增加了架构的多样性。
- 弹性的网络深度:3D-NAS允许搜索不同的网络深度,这可以通过调整每个阶段使用的卷积层数量来实现。这种弹性网络深度有助于平衡模型的计算量和性能。
2. 超网络训练和权重共享
为了降低搜索过程中重复训练不同架构的成本,3D-NAS采用了超网络(super network)训练的方式。超网络包含了所有候选网络的架构,在训练过程中每个子网络共享权重。这样,经过一次超网络的训练后,可以直接从中提取不同的子网络并进行评估,无需从头开始训练每个网络。
- 权重共享:通过在超网络中共享不同架构的权重,所有候选模型都能从同一组权重中获益,极大地减少了训练时间。
- 随机采样:每次训练迭代中,随机采样一个子网络进行优化,以确保整个搜索空间中的所有模型都能被充分训练。
3. 渐进式深度缩减(Progressive Depth Shrinking)
在搜索过程中,深度较大的网络架构往往因为被采样到的概率较小而训练不足。为了解决这一问题,3D-NAS采用了渐进式深度缩减策略。训练过程被分为多个阶段,每个阶段允许的网络深度逐渐增加,从而确保深层次的网络架构有更多的训练机会。
4. 进化搜索算法
在搜索阶段,3D-NAS使用进化算法来找到满足特定计算资源约束(如计算量、延迟等)的最优网络架构。进化算法通过模拟自然选择,基于候选网络的性能(如在验证集上的准确性)逐步优化架构:
- 种群初始化:从搜索空间中随机选择若干个初始架构作为种群。
- 适应度评估:对种群中的所有架构进行评估,根据性能选择最优的个体。
- 变异和交叉:通过变异和交叉操作生成新的架构,逐步进化出性能更好的网络。
5. 基于资源约束的搜索
3D-NAS通过进化搜索,在给定的资源约束(如计算量和延迟)下,自动找到最优架构。由于3D卷积网络的计算复杂性不仅取决于输入大小,还受输入稀疏性的影响,3D-NAS采用了精确的计算估计方法,确保搜索到的网络满足预设的资源限制。
核心代码实现讲解
SPVCNN 是一种结合了体素(Voxel)和点云(Point Cloud)的 3D 神经网络架构,旨在高效处理稀疏的 3D 点云数据。其设计灵感和实现与 SPVConv 的核心思想紧密相关。SPVConv 通过稀疏卷积和点云卷积相结合,提升对大规模 3D 场景中细节和小物体的捕捉能力,同时在计算资源有限的情况下保证计算效率。下面将结合 SPVCNN 的代码结构,详细解析与 SPVConv 核心思想的关联。
SPVCNN 通过体素卷积(Voxel-based convolution)和点云卷积(Point-based convolution)相结合的方式,在稀疏点云数据中平衡全局上下文信息和局部细节捕捉。
1. 稀疏卷积与体素化操作
在 SPVCNN 中,大量操作使用稀疏卷积来处理体素化后的点云数据。首先,输入数据被转换成体素网格形式,然后通过稀疏卷积网络进行处理。这种设计通过 BasicConvolutionBlock 和 ResidualBlock 来实现卷积操作:
class BasicConvolutionBlock(nn.Module):def __init__(self, inc, outc, ks=3, stride=1, dilation=1):super().__init__()self.net = nn.Sequential(spnn.Conv3d(inc, outc, kernel_size=ks, dilation=dilation, stride=stride),spnn.BatchNorm(outc),spnn.ReLU(True),)def forward(self, x):out = self.net(x)return out
Conv3d 和 BatchNorm 用于处理稀疏体素数据,并通过稀疏卷积在局部区域进行有效的特征提取。卷积核大小、步长和膨胀率可以调整,以适应不同尺度的体素数据。这与 SPVConv 中通过稀疏卷积处理体素的思想一致。
2. 点云卷积和特征转换
在 SPVCNN 中,体素卷积后的数据通过点云卷积进行处理,以保留高分辨率细节。这种操作通过 voxel_to_point 和 point_to_voxel 函数将体素数据和点云数据相互转换:
z0 = voxel_to_point(x0, z, nearest=False)
z1 = voxel_to_point(x4, z0)
z2 = voxel_to_point(y2, z1)
这些函数将体素特征转换回点云形式,允许点云卷积分支处理局部区域的高分辨率信息。通过 point_transforms 模块,可以进一步提取和转换点云特征:
self.point_transforms = nn.ModuleList([nn.Sequential(nn.Linear(cs[0], cs[4]),nn.BatchNorm1d(cs[4]),nn.ReLU(True),),...
])
这种设计与 SPVConv 的点云分支相匹配,确保在稀疏卷积处理的同时,仍然可以通过高分辨率的点云特征捕捉细节,特别是小物体的特征。
3. 多尺度特征融合
SPVCNN 中通过编码和解码的结构,将多尺度特征进行融合。编码部分(stage1 到 stage4)通过逐步下采样体素数据来捕捉更大的上下文信息;解码部分(up1 到 up4)通过上采样将特征恢复到高分辨率并结合不同层次的特征进行融合:
y1 = self.up1[0](y1)
y1 = torchsparse.cat([y1, x3]) # 将上采样后的特征与编码阶段的特征结合
y1 = self.up1[1](y1)
解码过程中,使用 BasicDeconvolutionBlock 来执行反卷积(即上采样)操作,确保高分辨率的特征在最终输出中得以恢复和利用。这与 SPVConv 中通过稀疏卷积捕捉全局上下文,并通过点云分支捕捉局部细节的思想是一致的。
4. 跳跃连接(Skip Connections)与残差块(Residual Block)
残差块(ResidualBlock)在网络中通过跳跃连接(skip connections)将输入特征与输出特征相加,使得深层网络能够保留浅层网络的特征,这一设计能够缓解梯度消失问题,确保深层网络的有效训练:
class ResidualBlock(nn.Module):def __init__(self, inc, outc, ks=3, stride=1, dilation=1):super().__init__()self.net = nn.Sequential(spnn.Conv3d(inc, outc, kernel_size=ks, dilation=dilation, stride=stride),spnn.BatchNorm(outc),spnn.ReLU(True),spnn.Conv3d(outc, outc, kernel_size=ks, dilation=dilation, stride=1),spnn.BatchNorm(outc),)if inc == outc and stride == 1:self.downsample = nn.Identity() # 如果输入输出通道一致,则直接传递else:self.downsample = nn.Sequential(spnn.Conv3d(inc, outc, kernel_size=1, dilation=1, stride=stride),spnn.BatchNorm(outc),)self.relu = spnn.ReLU(True)
残差结构的使用,确保了深度卷积网络在训练时的稳定性,同时也让不同层次的特征得以保留和融合,体现了多尺度特征融合的思想。
如何改进PointNet++
在改进 PointNet++ 时,结合 SPVConv 的思想,可以提升对局部细节和全局上下文的捕捉能力,特别是在处理稀疏点云数据和小物体时具有优势。SPVConv 提供了稀疏卷积与点云卷积结合的策略,这可以有效增强 PointNet++ 对空间结构的理解。
稀疏卷积与多尺度特征融合
改进思路:
PointNet++ 使用的多尺度特征聚合(MSA)在局部区域进行聚类和特征提取时,忽略了点云数据的稀疏性和局部细节。在每个局部区域内使用 SPVConv,可以通过稀疏卷积操作有效地捕捉局部几何结构,同时结合 PointNet++ 原有的特征聚合方式。
改进方案:
- 在 PointNet++ 的每个 Set Abstraction(SA)层 中,首先对局部点云数据进行稀疏体素化,将局部点云映射到体素网格。
- 然后,通过 SPVConv 对体素数据进行稀疏卷积处理,提取更具全局和局部信息的特征。
- 结合稀疏卷积的特征,再通过 PointNet++ 的聚类和池化操作,进一步提取局部的几何特征。
优点:
- SPVConv 可以利用稀疏数据结构提高计算效率,同时通过卷积核捕捉局部几何信息,从而增强 PointNet++ 对局部点云的特征提取能力。
- 这种改进可以提升对小物体和稀疏点云的感知能力。
全局上下文信息的融合
改进思路:
PointNet++ 的特征聚合方法主要依赖于逐层聚集的局部信息,缺乏全局上下文的融合能力。SPVConv 可以在多尺度体素化的基础上引入全局上下文感知机制,增强模型对场景级别特征的理解。
改进方案:
- 在 PointNet++ 的 Global Feature Aggregation(全局特征聚合)层 中,使用 SPVConv 对整个场景进行体素化,然后通过稀疏卷积捕捉全局特征。
- 该全局特征可以与 PointNet++ 的局部特征进行融合,通过跳跃连接或残差连接的方式,将全局上下文信息引入到局部特征中。
优点:
- 这种方式能够有效结合局部细节与全局上下文,弥补 PointNet++ 在全局场景理解上的不足。
- 特别适合处理大型点云数据集,如自动驾驶中的场景点云。
高效点云分支的融合
改进思路:
PointNet++ 逐点处理点云的方式较为耗时,尤其在高分辨率点云数据上计算代价较高。引入 SPVConv 的点云卷积分支,可以通过稀疏卷积降低计算复杂度,同时在局部范围内保留高分辨率的点云信息。
改进方案:
- 将 SPVConv 的稀疏卷积和高分辨率点云分支引入 PointNet++ 中。对于每个点云片段(clustered region),先通过体素卷积获取稀疏特征,再通过点云分支进行高分辨率处理。
- 最后,将稀疏卷积特征和点云特征在每个局部片段上进行融合,以增强模型的细节捕捉能力,同时降低计算开销。
优点:
- 稀疏卷积分支提升了对局部结构的理解,而点云分支保留了细节信息,计算效率显著提高。
- 适用于大规模、高分辨率的点云数据。