背景
之前在试着提高解题正确率,目标100%,发现外部知识不足仅依靠大模型的话比较困难。而试题人工生产成本巨大。
本质因为大模型生成内容会有幻觉特点,也就是说解答的试题正确性不太好评判,直接解答试题生产场景不太可控。
后面考虑调用OpenAI解题的时候,像xxx那样通过输出置信度来帮助判断答案的正确性 or 其他形式只要能保证LLM生成答案是可靠(程序判断)的。
目录
- RAG知识库现状
- 测评1
- 初次测评结果
- 分析与优化
- 优化后测评
- 测评2
- 测评3
RAG知识库现状
想要一定程度避免解题内容为幻觉,必须依靠外部知识(RAG知识库)。
可以考虑构建Agent Workflow用于幻觉检查,只输出依靠RAG之后有依据一定正确的 答案和解析,不确定的输出如 “当前AI Agent 没有十足把握生成正确答案…” 而判断的依据就是根据RAG、web search的知识。
-
测试数据量:RAG知识库使用ES的 qbm_rag_ques_knowledge,高中英语单选题型数据量184532。
-
知识格式:【题干】xxx,【答案】:xxx,【解析】:xxx。
测评1
随机选取100道高中英语单选测试集,使用GPT-4o-mini模型
构建Agent Workflow,优化流程,优化提示词。
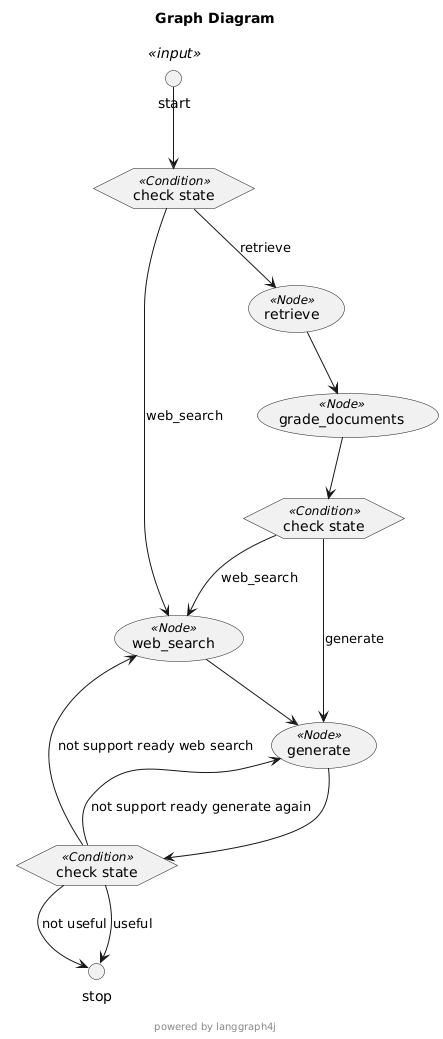
初次测评结果
test-ai-answer-result-gpt4o-mini-check-hallucination.json
幻觉检查、答案评估输出 “AI Agent暂时没有十足的把握确定答案…” 的试题有31个。
通过幻觉检查、答案确定通过的输出答案的题69个,其中错误的4个
- 2267372320546816
- 2267372320530432
- 2265225605718017
- 2238952535252993
分析与优化
经过分析BAD CASE优化点
- 优化知识库质量:知识库剔除不包含没有解析的试题 or 文档评分的时候调整提示词将该文档判断为不相关,重建courseId=28的知识库,总数据量196235,去除低质量知识后184532。
- 优化流程结点:web search的内容也需要grade_documents 和 hallucination_grade,发现网络召回的内容还是会干扰,比如只是语意相关,会干扰解题,因此取消web search节点。
- 重排序:取消莱文斯坦算法第二次重拍,因为不一定要求是题干相似的题。
- 优化RAG召回:增加另外的召回思路,之前使用的是单独MLT,现在加入选项内容关键字搜索,如果MLT召回内容经过评分后不相关,就进行第二次关键字召回。
- …
优化后的流程节点
1、取消web search节点:web search搜索大概率是语意相关的,召回试题的概率不是很大,语意相关的知识意义不大。
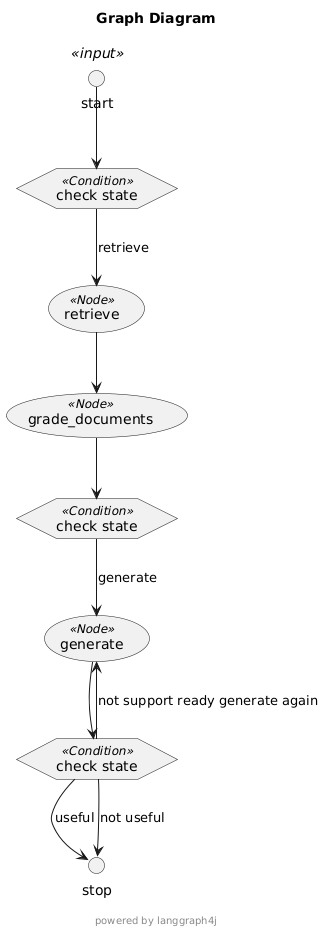
取消了web search 并修改为更严格的提示词,通过幻觉检查的数量急剧减少。
2、加另外一种关键字召回
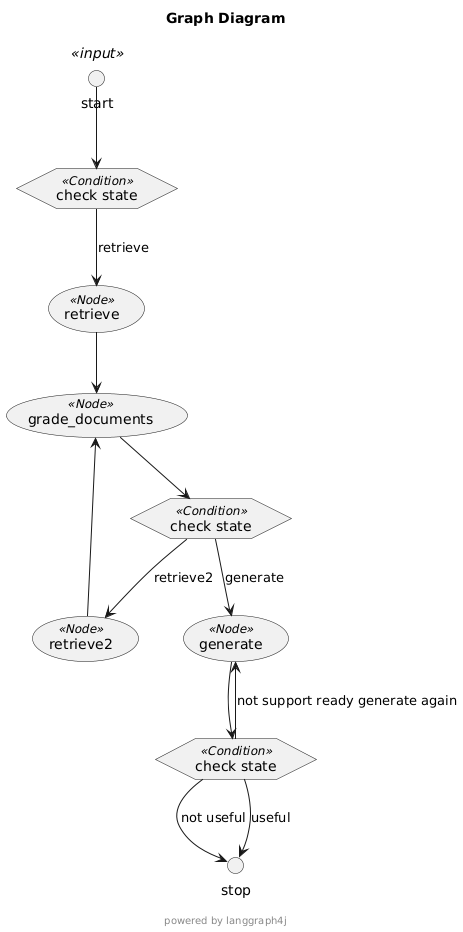
3、优化无用流程:后发现如果召回的知识被判断为不相关,直接结束就行,不在generate生成答案解析,节省token和时间。
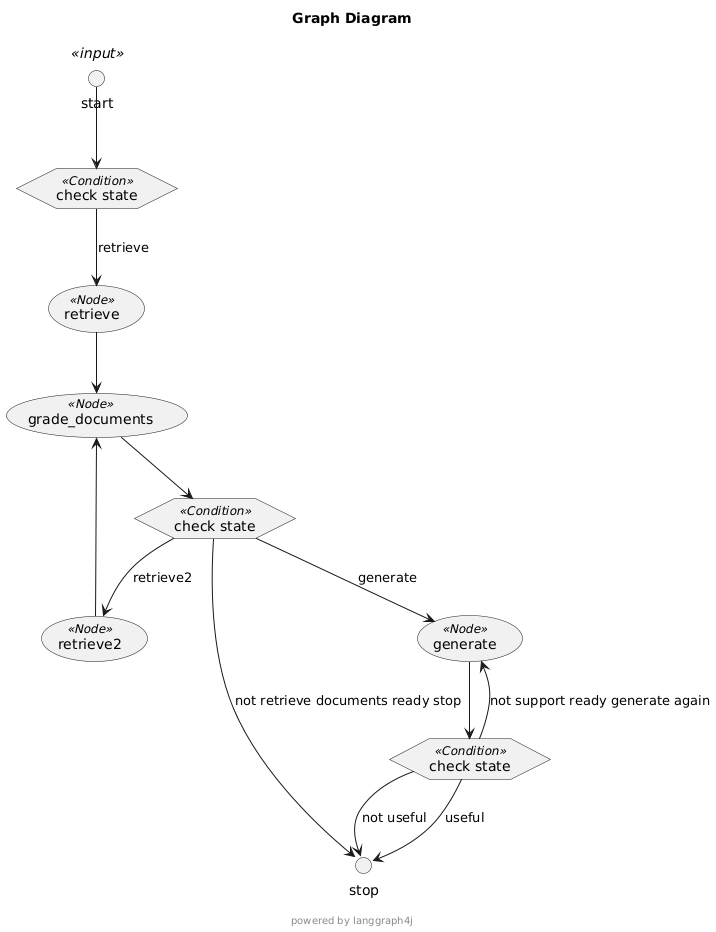
优化后再次测评
[test-ai-answer-result-gpt4o-mini-check-hallucination-without-websearch(4).json]
幻觉检查通过的13道试题,均解答正确
测评2
随机选取200道高中英语单选测试集,使用GPT-4o-mini模型
Agent workflow使用下面的
[test-ai-answer-result-gpt4o-mini-check-hallucination-without-websearch(5).json]
幻觉检查通过的18道试题,均解答正确
测评3
随机选取100道高中英语单选测试集,使用GPT-4o-mini模型
Agent workflow使用下面的
[test-ai-answer-result-gpt4o-mini-check-hallucination-without-websearch(6).json]
幻觉检查通过3道题,均解答正确。
Agent幻觉检查流程
以2270753096671232为例子,说明整个解题流程
当前节点 :retrieve,节点数据:
{"maxRetrieveCount": 2,"kpointIds": [