缓存三大问题
缓存穿透
缓存穿透是指用户查询的数据在缓存和数据库中都不存在,导致每次请求都会直接落到数据库上,增加数据库负载。

解决方案
1)参数校验
一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
2)缓存无效 key
如果缓存和数据库都查不到某个 key 的数据就写一个到 Redis 中去并设置过期时间,具体命令如下:SET key value EX 10086 。这种方式仅能解决请求的 key 变化不频繁的情况。
3)布隆过滤器
把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
4)接口限流
根据用户或者 IP 对接口进行限流,对于异常频繁的访问行为,还可以采取黑名单机制,例如将异常 IP 列入黑名单。
缓存击穿
缓存击穿是指热点数据在缓存过期后,大量请求同时查询该数据,导致请求直接落到数据库上,瞬间对数据库造成巨大压力。
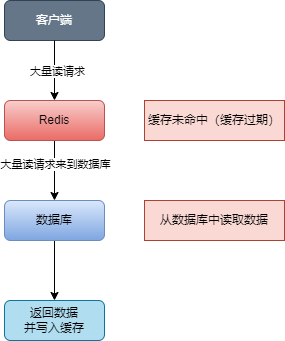
解决方案
-
针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
-
查询缓存过期后,先获取互斥锁,然后再将数据库中的数据写入到缓存中,保证只有一个请求会落到数据库上,减少数据库的压力。
-
缓存中添加一个逻辑过期字段,如果查询到缓存过期,先获取互斥锁,然后开启一个新线程重构缓存过期时间,其他线程如果获取互斥锁失败,直接返回过期数据,从而减少到达数据库的请求。
缓存雪崩
缓存在同一时间大面积的失效(可能是Redis宕机或缓存大面积过期),导致大量的请求都直接落到了数据库上,对数据库造成了巨大的压力。
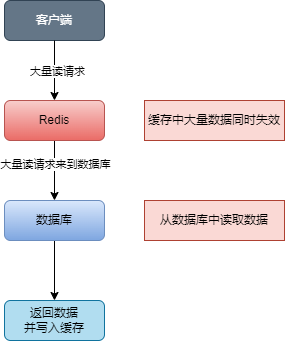
解决方案
1)针对 Redis 服务不可用的情况:
- 集群部署: 采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
- 限流与降级:对请求进行限流,防止大量请求同时落到数据库上。同时,在缓存不可用时,可以返回默认值或进行降级处理。
- 使用多级缓存架构:结合本地缓存和分布式缓存,减少对分布式缓存的直接依赖。在缓存失效时,首先查询本地缓存,如果没有,再查询分布式缓存。
2)针对热点缓存失效的情况:
- 设置随机的过期时间,在设定的基础上添加一个随机值,避免大量缓存同时失效。
- 缓存永不失效(不太推荐,实用性太差)。
- 缓存预热,在系统启动或者缓存失效前,通过后台任务将常用的数据加载到缓存中,防止缓存刚启动时产生大量数据库请求。
实现缓存预热
常见的缓存预热方式有两种:
- 使用定时任务,比如 xxl-job,来定时触发缓存预热的逻辑,将数据库中的热点数据查询出来并存入缓存中。
- 使用消息队列,比如 Kafka,来异步地进行缓存预热,将数据库中的热点数据的主键或者 ID 发送到消息队列中,然后由缓存服务消费消息队列中的数据,根据主键或者 ID 查询数据库并更新缓存。
数据一致性问题
什么情况下会出现数据一致性问题?
因为缓存的操作和数据库的操作是存在一定的时间差的。而且这两个操作是没办法保证原子性的,也就是说,是有可能一个操作成功,一个操作失败的。所以,这就必然会存在不一致的情况。
写写并发问题
先写数据库,再写缓存的情况。
| W | W |
|---|---|
| 写数据库,更新成20 | |
| 写数据库,更新成10 | |
| 写缓存,更新成10 | |
| 写缓存,更新成20**(数据不一致)** |
先写缓存,再写数据库的情况。
| W | W |
|---|---|
| 写缓存,更新成20 | |
| 写缓存,更新成10 | |
| 写数据库,更新成10 | |
| 写数据库,更新成20**(数据不一致)** |
读写并发问题
| W | R |
|---|---|
| 读缓存,缓存中没有数据 | |
| 读数据库,数据库中数据为10 | |
| 写数据库,更新成20 | |
| 写缓存,更新成10**(数据不一致)** |
如何解决数据一致性问题
1.删除缓存还是更新缓存
- 更新缓存更加复杂: 在缓存中,当数据不仅仅是简单的字符串(如JSON串或map类型),更新缓存变得更为复杂和易出错。例如,扣减库存时,需要从缓存中取出整个订单模型,反序列化后修改库存字段,再序列化并更新回缓存。相比之下,直接删除缓存再重建的策略更为简洁。
- 更新缓存更容易出现数据不一致: 在“写写并发”的场景中,如果同时更新缓存和数据库,很容易会出现因为并发的问题导致数据不一致的情况。但是,如果是做缓存的删除的话,在写写并发的情况下,缓存中的数据都是要被清除的,所以就不会出现数据不一致的问题。
- 删除缓存会出现Cache miss问题: 在删除缓存后的下一次查询会无法命中缓存,要查询一下数据库。这种cache miss在某种程度上可能会导致缓存击穿,也就是刚好缓存被删除之后,同一个Key有大量的请求过来,导致缓存被击穿,大量请求访问到数据库。但是,通过加锁的方式是可以比较方便的解决缓存击穿的问题的。
2.先删缓存还是先更新数据库(推荐先更新数据库)
- 先删缓存
好处: 缓存删除之后,就不存在数据不一致的问题了。
坏处: 由于读写并发问题(当缓存不存在数据时,读线程读取数据库后需要写入缓存),先删缓存刚好可以让读线程读不到缓存,会加大这种可能性的发生。此外,缓存被删除后,更容易出现缓存击穿的问题。(此处引出缓存三大问题)
- 先更新数据库
好处: 缓存删除失败的概率比较低,除非是网络问题或者缓存服务器宕机。先更新数据库,确保数据是最新的,即使缓存删除失败,数据出现短暂的不一致,在下次查询缓存时如果缓存过期,就会更新缓存,使得数据一致。(此处引出延迟双删,因为如果第一次缓存删除失败了,下一次查询时缓存没过期,就会查询到旧数据导致数据不一致)
坏处: 由于整个过程不是一个原子操作。一旦删除缓存失败,就会导致数据库中的数据已经更新,但是缓存还是旧数据,产生数据不一致。
延迟双删策略
@service
public class Productservice {@Autowiredprivate stringRedisTemplate redisTemplate;// 定义阻塞队列private final BlockingQueuexstring> cacheDeletionQueue = new LinkedBlockingQueue<>();public void updateProduct(Product product) {//第一次删除缓存deletecache(product.getId());// 更新数据库updateProductInDB(product);// 第二次删除缓存,将缓存key存入阻塞队列cacheDeletionQueue.add(product.getId());}// 时间到后,从阻塞队列中取出key,删除缓存@scheduled(fixedDelay =100)public void delayedcacheDeletion(){String productId = cacheDeletionQueue.poll();if(productId != null) {deletecache(productId); //删除缓存} }
}
为什么是
删除缓存-->更新数据库-->删除缓存这个顺序?
- 防止读取到旧缓存数据:
- 先更新数据库,再删除缓存:假设先更新数据库再删除缓存,在删除缓存之前,可能有其他并发请求读取到旧的缓存数据。这些请求可能会在删除缓存之后将旧数据重新写入缓存,从而导致数据不一致。
- 先删除缓存,再更新数据库:通过在更新数据库之前删除缓存,可以确保即使有并发请求,它们也会读取数据库的最新数据(因为缓存已被删除),从而写入新的缓存数据。
- 处理并发请求带来的数据不一致:
- 不做处理:在更新数据库之前,可能有其他并发请求读取了旧的数据库数据。这些请求可能会在更新数据库之后重新写入缓存,从而导致数据不一致。
- 延迟删除缓存:延迟一段时间后再次删除缓存,确保缓存中不会存有旧数据。
写入新的缓存数据。
- 处理并发请求带来的数据不一致:
- 不做处理:在更新数据库之前,可能有其他并发请求读取了旧的数据库数据。这些请求可能会在更新数据库之后重新写入缓存,从而导致数据不一致。
- 延迟删除缓存:延迟一段时间后再次删除缓存,确保缓存中不会存有旧数据。