最近有小伙伴来问LLM的参数该如何设计,废话不多说来看看paper吧。首先,常见的可以进行调参的几个值有temperature,top-p和top-k。今天这篇文章是关于temperature的。
原文链接:https://arxiv.org/abs/2405.00492
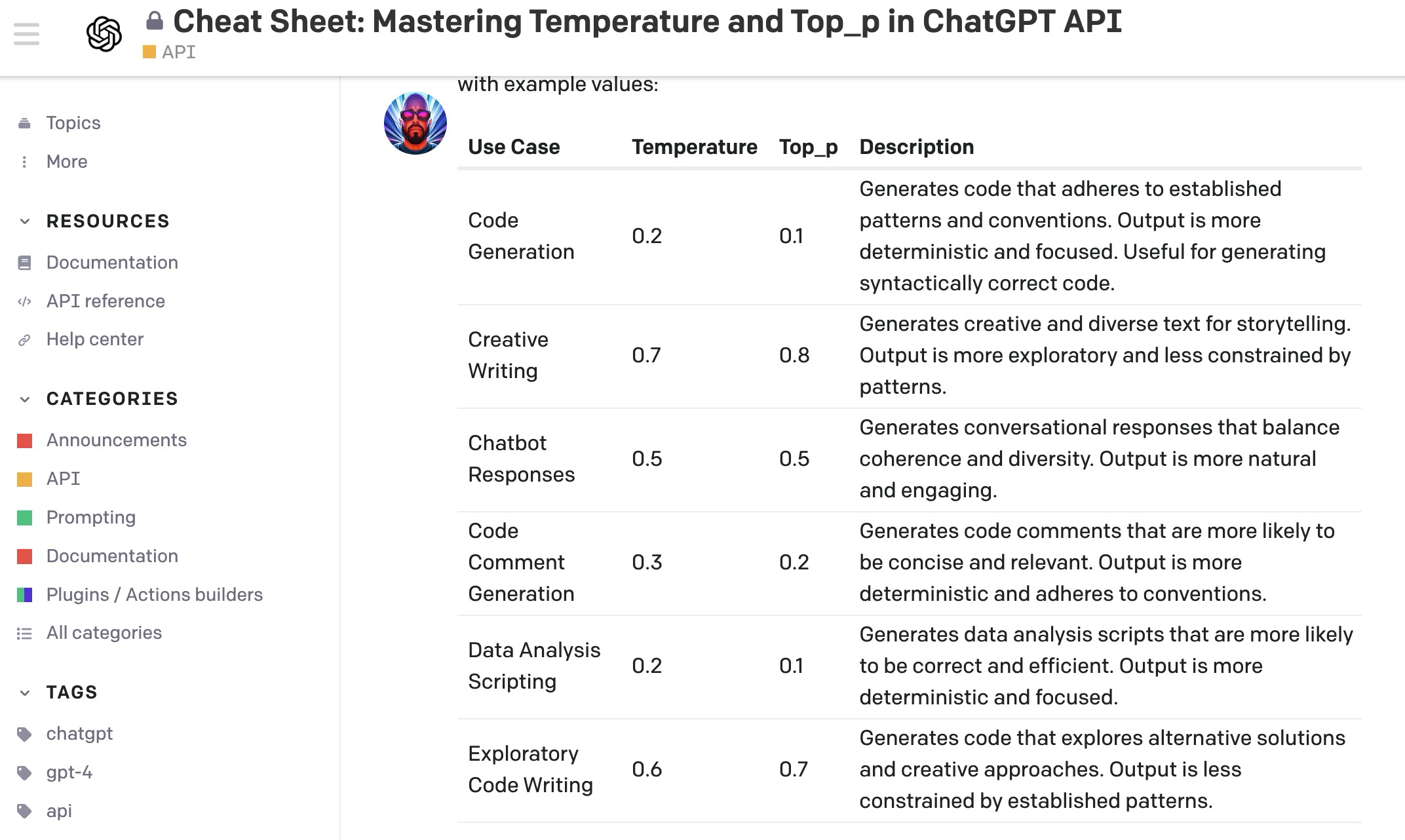
temperature如果用简单的一句话来说,就是:Controls randomness, higher values increase diversity。数值越高,输出的结果多样性越大。大家其实直接用这个标准拿去参考调整参数就行。其实大部分的人都是这么做的,我们先来看一下openai commutiy上讨论的帖子:Cheat Sheet: Mastering Temperature and Top_p in ChatGPT API - API - OpenAI Developer Forum。这个回答者,还给出了一个不同use case情况下的参数设置参考,当然具体情况还是要看实验结果的哈。
然后2024年五月出的这篇文章,研究工作比较新了,我们先来看一下文章的摘要部分给出的结论:
Here, we investigate this claim using a narrative generation task with a predetermined fixed context, model and prompt. Specifically, we present an empirical analysis of the LLM output for different temperature values using four necessary conditions for creativity in narrative generation: novelty, typicality, cohesion, and coherence. We find that temperature is weakly correlated with novelty, and unsurprisingly, moderately correlated with incoherence, but there is no relationship with either cohesion or typicality. However, the influence of temperature on creativity is far more nuanced and weak than suggested by the “creativity parameter” claim; overall results suggest that the LLM generates slightly more novel outputs as temperatures get higher. Finally, we discuss ideas to allow more controlled LLM creativity, rather than relying on chance via changing the temperature parameter.
文章测试的实验是用固定的上下文、大语言基座模型、提示词来进行文本生成任务(叙事生成,即生成连贯有意义的故事)。作者从novelty新颖性、typicality典型性、cohesion凝聚性和coherence连贯性,这四个方面来看这个creativity的情况。结果,他们发现temperature这个参数和novelty弱相关,与不连贯性中等相关,与凝聚性和典型性无关。虽然temperature被视为creativity parameter,但是看起来并不是所谓意义上的那个creative。
首先,如果我们要去改变一个大语言模型的效果,有三个方式可以去调整,分别是训练数据(从最开始就构建或者后面进行微调),in-context learning(few-shot learning,简而言之,在prompt中添加示例),以及不同的超参数设置。Temperature是模型中的一个超参数,用于调节采样过程中的随机性,即下面这个softmax公式里的t,softmax大家都知道,是深度学习里非常常见的一个函数了,会在分类场景里,把数值给他映射到0-1的空间,如果是多分类,概率的和就是1啦。
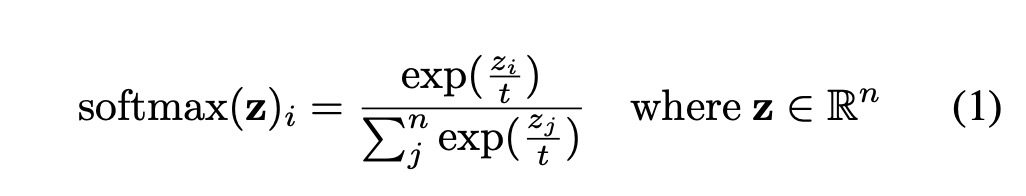
然后,咱们放到GPT模型的尾端,当我要预测下一个词的时候,我需要计算每个单词成为下一个单词的概率,然后找到最大概率的那个词,作为我的下一个单词(所有词的概率加在一起是1)。咱们回到公式,你看分母就是词所有的和,分子是当前词。这个时候咱们的temperature,t成了一个分母,温度 t>1 时,高概率的值会降低,低概率的值会增加,导致概率分布更加平坦。温度 t<1 时,高概率的值会增加,低概率的值会降低,使得分布更加陡峭。分布陡峭,指的是我很明确就知道我要选那个概率最大的词,但是如果大家都姿色平平,那我可能就需要雨露均沾,哪个都可以试试。
如果你想看Temperature变化时候的可视化,可以看看这个网站(What is Temperature in NLP?🐭 :: Luke Salamone's Blog),作者举个🌰,大家都知道GPT模型主要是从前往后,预测下一个词。如果句子是:
老鼠爱吃_____
那么下一个词,可以是蛋糕、糖果、芝士、饼干等等等。
作者展现了随着temperature变化,不同词语对应概率分布的变化。
从:鼠鼠🐭就爱🧀
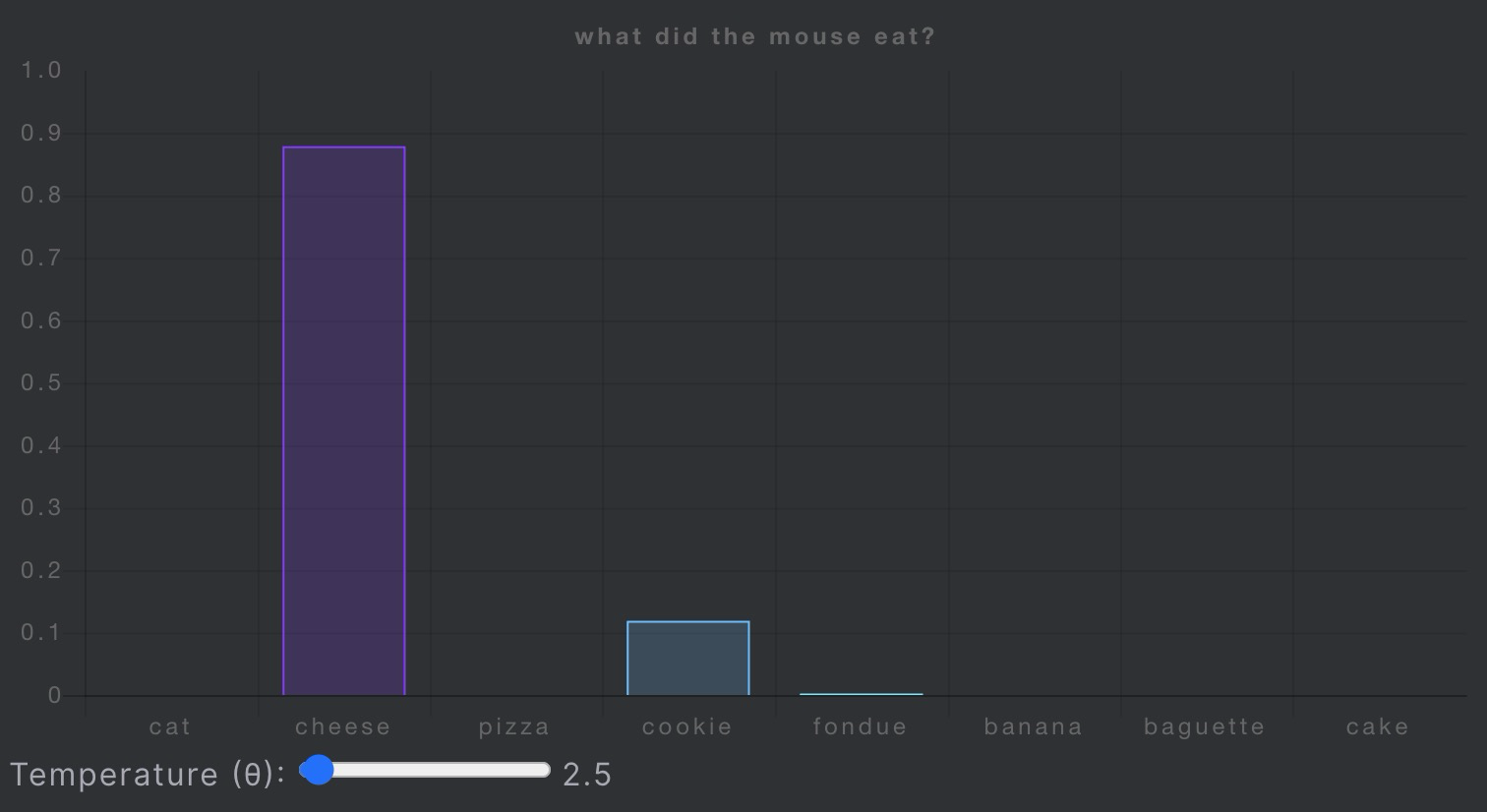
到:鼠鼠🐭我呀,雨露均沾。
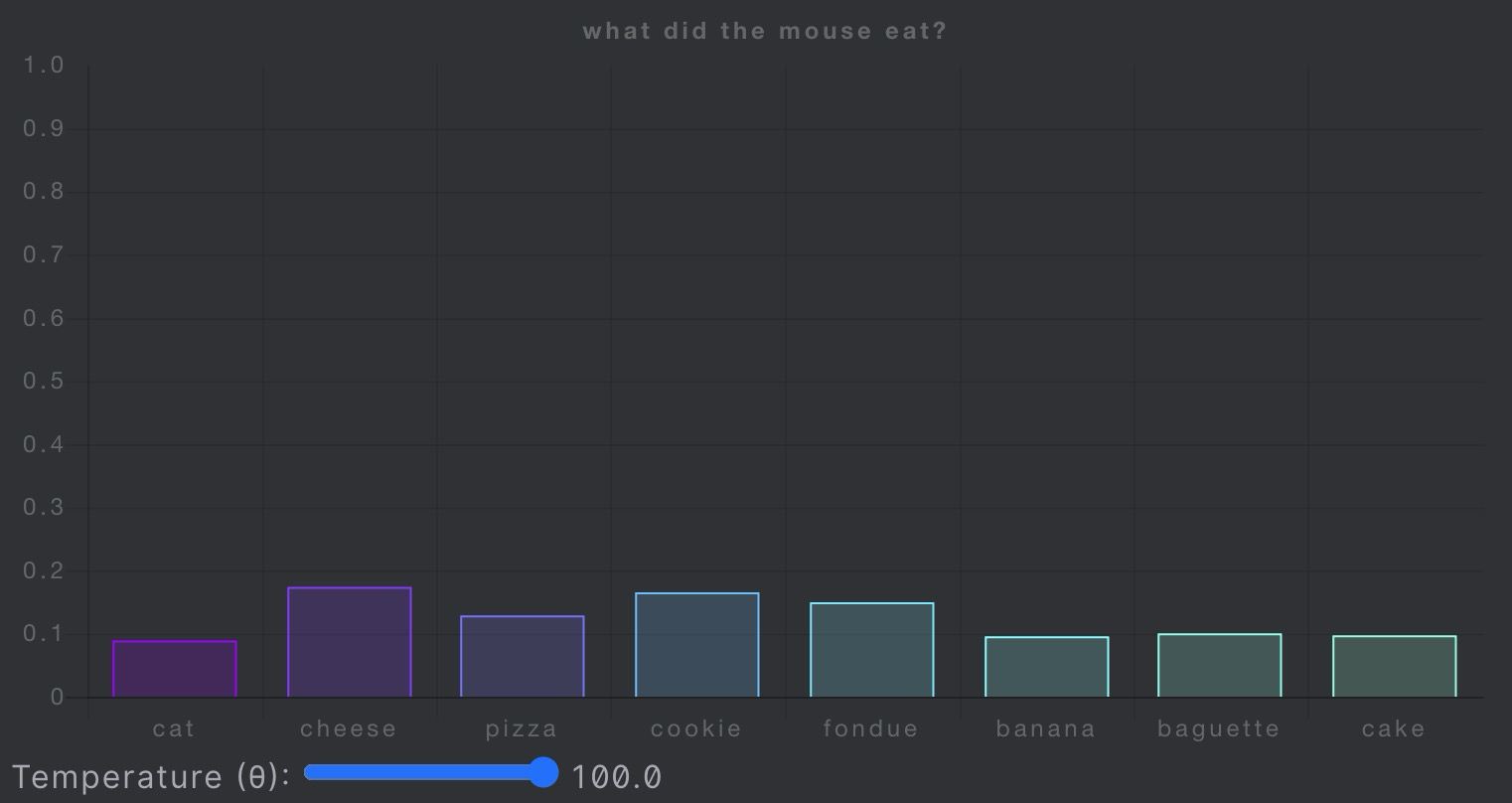
看完了temperature的公式和变化时候的情况,我们再次回到文章,作者找到两种理论来解释t变化时候实际带来的改变:
The method for evaluation we propose in this paper is inspired by two theories of cognitive categorisation, namely prototype theory (Rosch 1973) and exemplar theory (Medin and Schaffer 1978). These two theories are often contrasted, but have much overlap. The key difference is that in exemplar theory, categorisation of new stimuli is not compared against a single prototype object, but against multiple exemplars of the category. A prototype is considered something that is derived from presented stimuli, where an exemplar is one of the previous stimuli.
。。。
Conceptual spaces also play an important role in Boden’s framework of creativity (Boden 1992). She uses a metaphor, a map of the mind, to describe exploratory creativ- ity and that novelty and value can be found venturing into unknown regions. To be more precise, the typicality of an object relates to how well it fits with the exemplars or the prototype, while novelty could be viewed as how much the category changes or expands as a new stimulus is presented. This implies similarly that if temperature is indeed the cre- ativity parameter, then it should allow access to different slices of the probability distribution or other regions in the embedding space.
大致意思,我觉得就是temperature改变的时候,虽然说是变得更加creative,出现的词更多样化,但是出现的这些词依旧属于某个类别。以大家熟悉的思维地图为例,新颖性可以看作是当新的刺激出现,地图类别变化或扩展的程度,如果temperature是创造性参数,改变了以后应该可以允许访问,概率分布不同或者embedding空间里的其他区域。这里的embedding space,我们可以把它想成是LLM在学习了大量的文本以后,大量参数组成的高纬🧀空间。有了这样的一个大致理论方向后,作者开始做实验。
任务非常简单,写故事,作者的prompt是

作者测试了7个不同temperature参数,写了100个故事:

OK,然后就是重要的测评环节!!!!
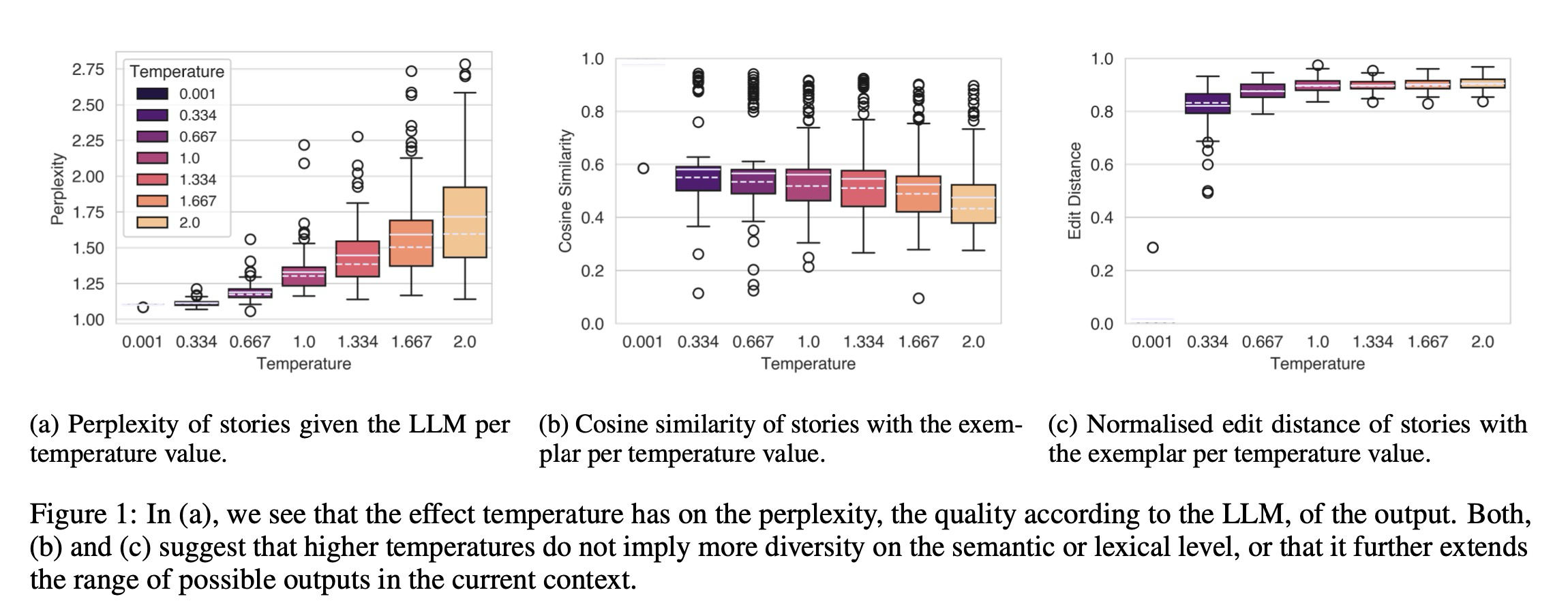
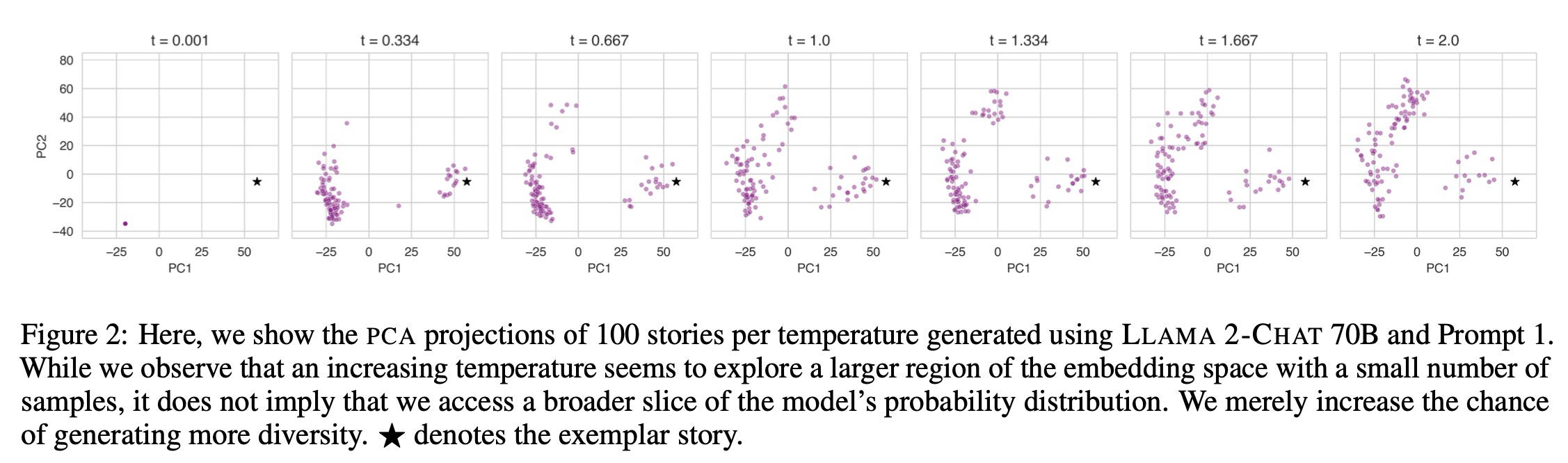
作者分别用故事的困惑度、生成的故事和典范故事之间的cosine相似度以及标准化的编辑距离,这三个指标来进行分析。作者还做PCA,用主成分分析,将生成的故事投射到二维空间。
除了指标和相关的可视化,必不能少的human evaluation。测评实验参与者会将每个故事与样本进行比较,然后评判新颖性、典型性、故事的凝聚和连贯性。
具体实验分析部分,大家去看文章哈,anyway,最后作者的结论就是,这个temperature参数看起来不太能就直接拿来调整以改变creative的程度。当然,作者最后给出的如何更creative的建议,看起来更像是🤌🤌🤌建设性的那种,比如咱们可以搞点benchmark for creativity,咱们可以整一些为特定目的来设计的解码策略,就是在decoding的时候直接为了creative而creative。通过prompt设计来最大程度调整LLM的表现。
最后的最后,hmmm,难道这就是在发现屡次调参失败后,dis参数的一篇文章🤣。