produce客户端完整架构图如下所示:
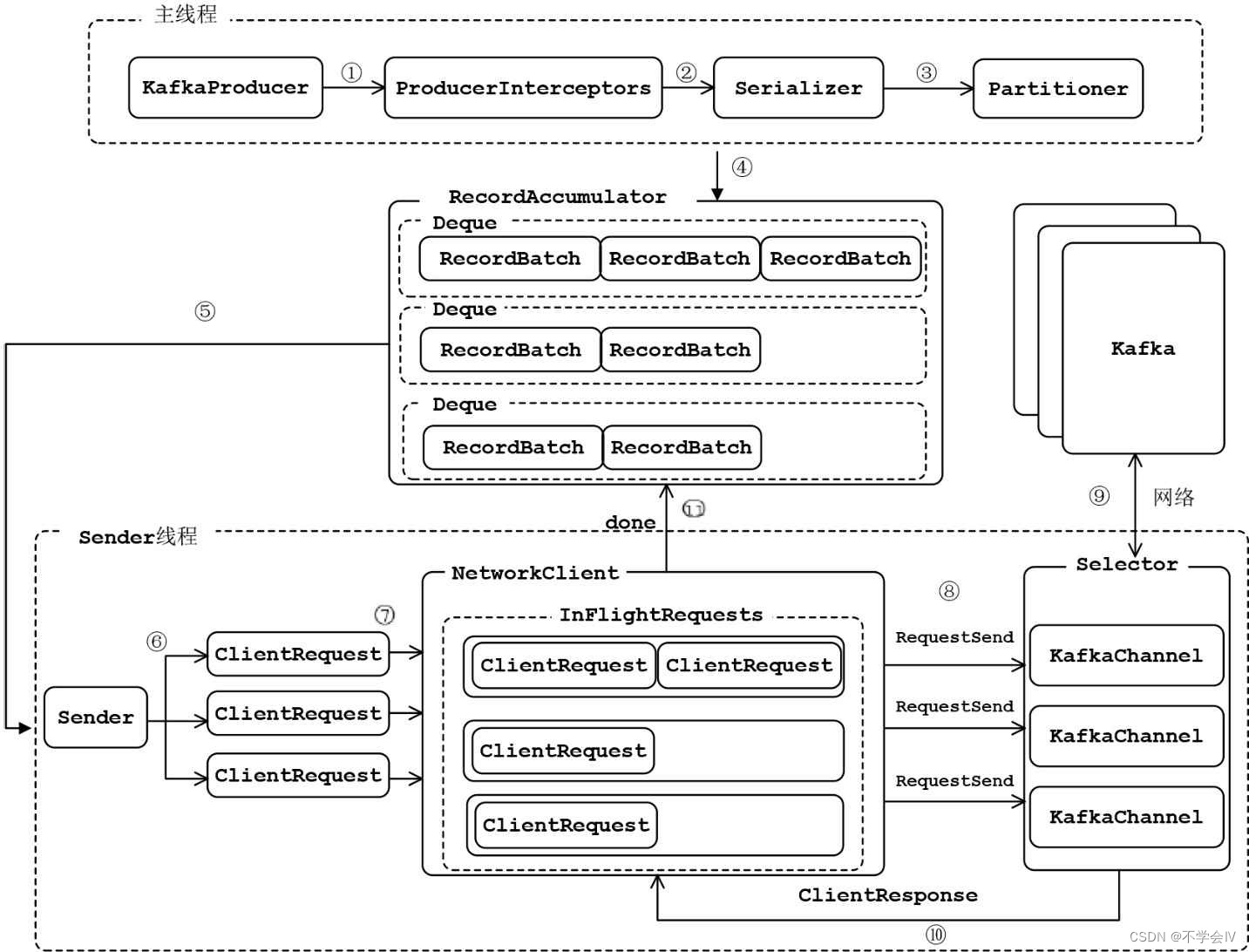
- ProduceInterceptors对消息进行拦截
- Serializer对消息的key和value进行序列化
- Partitioner为消息选择合适的Partition
- RecordAccumulator收集消息,实现批量发送
- Sender从RecordAccumulator获取消息
- 构造ClientRequest
- 将ClientRequest交给NetworkClient,准备发送
- NetworkClient将请求放入KafkaChannel的缓存
- 执行网络IO,发送请求
- 收到响应,调用ClentRequest的回调函数
- 调用RecordBatch的回调函数,最终调用每个消息上注册的回调函数
消息发送的过程,涉及两个线程协同工作。主线程首先将业务数据封装成ProducerRecord对象,之后调用send()方法将消息放入RecordAccumulator中暂存。Sender线程负责将消息信息构成请求,并最终执行网络IO的线程,他从RecordAccumulator中取出消息批量发送出去。需要注意的是,KafkaProducer是线程安全的,多个线程间可以共享使用同一个KafkaProducer对象。
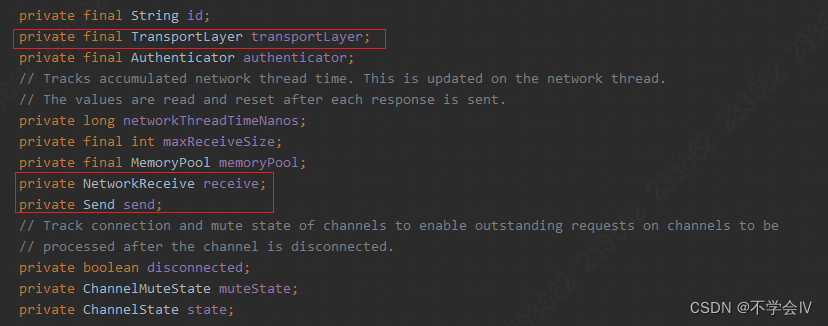
RecordAccumulator
记录收集器中有一个最重要的字段batches:
private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;
保存了分区和待发送到该分区上的消息。待发送到该分区上的消息保存在双端队列ArrayDeque中,每个双端队列由数个ProducerBatch组成(RecordBatch是在ProducerBatch里面的一个专门存放消息的对象,除此之外ProducerBatch还有其它相关属性。在架构图中经常用RecordBatch代替ProducerBatch),每个ProducerBatch的大小由配置项batch.size控制,默认为16KB。

追加消息时首先获取分区所属的双端队列,然后取队列中最后一个RecordBatch,如果队列中不存在RecordBatch或者已经不能写入已存在的RecordBatch(比如默认16KB,消息大小为10KB,当写入第二条信息时,发现20KB大于16KB,会不能写入),则创建一个新的RecordBatch。
具体流程如下所示:

Sender
从记录收集器获取数据
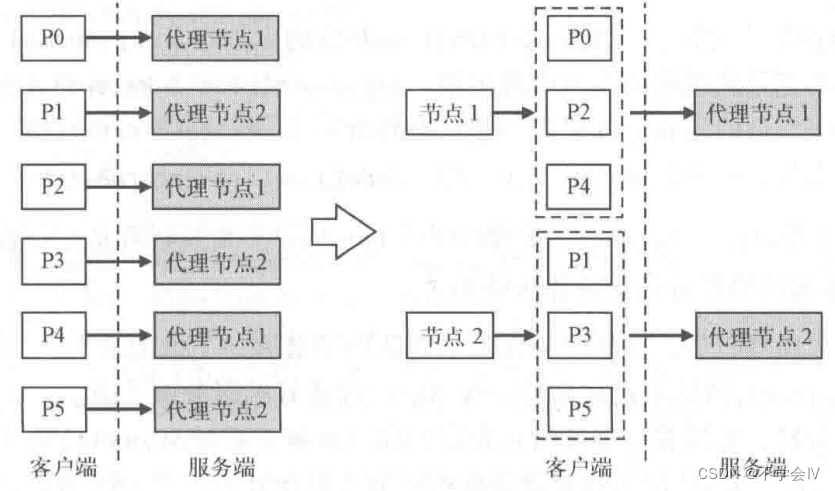
消息发送线程有两种消息发送方式:
- 按照分区直接发送
- 按照分区的目标节点发送
假设有两台服务器,topic有6个分区,单副本,那么每台服务器就有3个分区。如下图所示,如果按照方式1,总共会有6个请求,如果按照方式2,总共会有2个请求。kafka中使用方式2,可以大大减少网络的开销。
Sender的run()方法中主要逻辑主要分为两部分:sendProducerData()和client.poll()。在sendProducerData()中实现,最重要的是这3个方法:
// 获取已经准备好的分区,linger.ms在该方法中用到
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// 生成每个主broker对应的批记录列表
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes,this.maxRequestSize, now);
// 生成以节点为级别的生产请求列表
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,requestTimeoutMs, callback);client.send(clientRequest, now);
ready()方法会判断哪些节点已经准备好了(即有数据可以写入)。linger.ms和batch.size是在这里用到的,具体来说,只要linger.ms时间到了或者至少有一个ProducerBatch大小达到batch.size,则任务该节点的数据已经准备就绪。另外在一次测试中发现,linger.ms设置了30s,batch.size设置了200KB,单条消息大小是10KB,发现发往broker0好broker2上某个分区的ProducerBatch大小依旧是10KB,而不是200KB。原因是还会考虑一个情况exhausted,即RecordAccumulator中的空间(默认32MB)用完后,不管linger.ms和batch.size条件是否达到,都会认为已准备好以发送数据。
drain()方法详解:
// 获取当前node上的生产者对应topic的所有leader分区
List<PartitionInfo> parts = cluster.partitionsForNode(node.id());
// 遍历leader分区,从accumulator的batches中拿到对应分区的数据,追加到node对应的列表中。accumulator中
// 的ProducerBatch不需要任何变化就可以添加到node对应的List中。需要注意的是该方法中只会从分区Deque中拿第
// 1个ProducerBatch,即使分区Deque中已经堆积了多个ProducerBatch
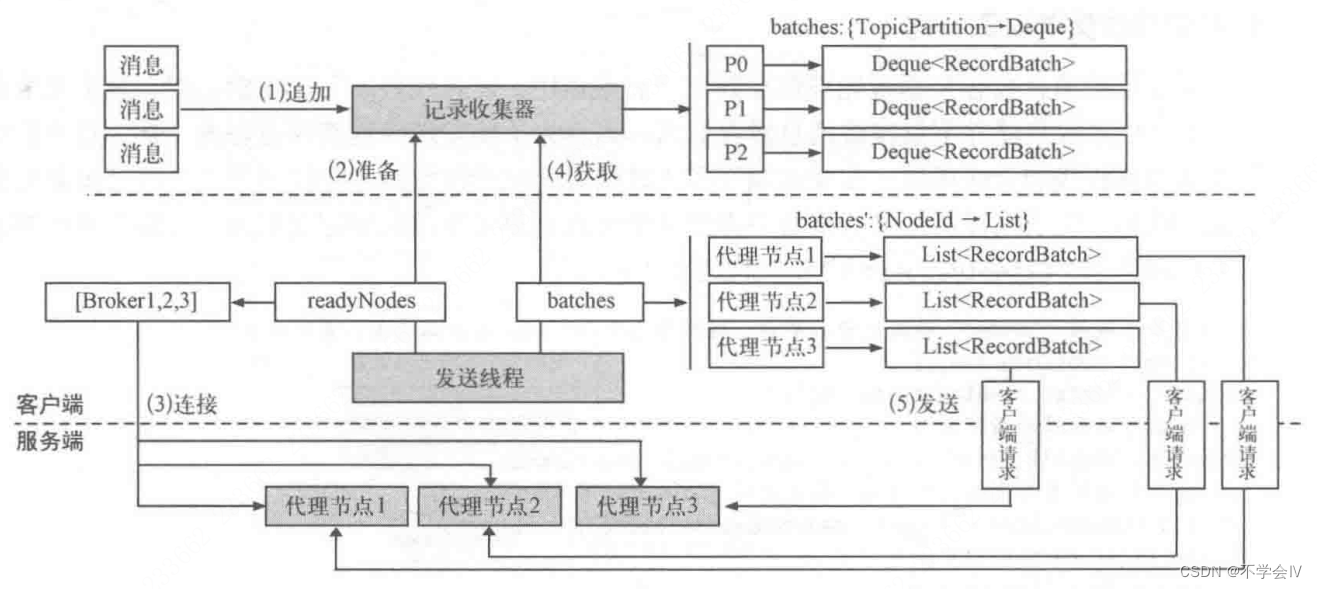
发送线程从记录收集器获取数据,然后创建客户端请求并发送给服务端,具体步骤如下:
- 消息被记录收集器收集,并按照分区追加到队列的最后一个批记录中
- 发送线程通过ready()从记录收集器中找出已经准备好的服务端节点(RecordBatch已经写满了或者linger.ms时间已经到了,这个topic对应的节点就认为是准备好的)
- 节点已经准备好,如果客户端还没有和他们建立连接,通过connect()建立到服务端的连接
- 发送线程通过drain()从记录收集器获取按照节点整理好的List
- 发送线程得到每个节点的批记录后,为每个节点创建客户端请求ClientRequest,并将请求发送到服务端
题外话:
之前通过prometheus查看生产请求数和生产总流量,确定了每个请求对应一条消息(消息大小分别为10KB和4MB)。但是通过arthas抓取服务端拿到的生产请求,发现一条生产请求包含多个消息:
// 通过watch kafka.server.KafkaApis handleProduceRequest {params[0].bodyAndSize.request} // -x 1 -n 1查看单次生产请求
ts=2024-06-05 19:46:59; [cost=0.31727ms] result=@ArrayList[@ProduceRequest[{acks=1,timeout=30000,partitionSizes=[test_3-0=10312,test_3-9=10312,test_3-3=10312,test_3-12=10312,test_3-6=10312]}],
]ts=2024-06-05 19:46:59; [cost=2.61274979159195E9ms] result=@ArrayList[@ProduceRequest[{acks=1,timeout=30000,partitionSizes=[test_6-39=4194378,test_6-15=4194378,test_6-66=4194378]}],
]
按照当时的理解,batch.size为16KB,linger.ms为0,那么每次生产请求应该都只包含一条消息才对,为什么arthas接收到的生产请求中有多条消息?再进一步,如果一个请求中包含了多条消息,为什么prometheus中获取到的信息是一个请求对应一条消息?
通过走读源码,第二个疑问能够得到解答:
/*** Append the messages to the local replica logs*/private def appendToLocalLog(internalTopicsAllowed: Boolean,isFromClient: Boolean,entriesPerPartition: Map[TopicPartition, MemoryRecords],requiredAcks: Short): Map[TopicPartition, LogAppendResult] = {trace(s"Append [$entriesPerPartition] to local log")entriesPerPartition.map { case (topicPartition, records) =>brokerTopicStats.topicStats(topicPartition.topic).totalProduceRequestRate.mark()brokerTopicStats.allTopicsStats.totalProduceRequestRate.mark()...
可以看出,服务端是将客户端的每一个RecordBatch作为一次请求,而不是将一个ClientRequest作为一次请求。
针对第一个疑问,在Sender这一节也得到了解答,因为Sender在发送之前,会将RecordBatch根据broker进行聚合,将发往同一个broker的RecordBatch合并到一个ClientRequest中。
创建生产者客户端请求
发送线程并不负责真正发送客户端请求,它会将ClientRequest交给客户端网络对象NetworkClient去发送,因为没有在发送线程中发送请求,因此创建客户端请求时需要保留目标节点,这样客户端网络对象获取出客户端请求时,才能知道要发送给哪个目标节点。
NetworkClient
NetworkClient管理了客户端和服务端之间的网络通信,包括连接的建立、发送客户端请求、读取客户端响应等。在Sender的run()方法中会依次调用NetworkClient的如下3个方法:
- ready()。从记录收集器获取准备完毕的节点,并连接所有准备好的节点(在this.accumulator.ready()之后)
- send()。为每个节点创建一个客户端请求,将请求暂存到节点对应的通道中(即之前的client.send)。
- poll()。轮询动作会真正执行网络请求,将客户端请求发送给服务端。
在client.send()这一步,会先将客户端请求加入inFlightRequests列表,然后调用selector.send()方法,selector.send()中只是将请求暂存,并没有真正发送。selector.send()底层会调用到kafkaChannel.setSend(),kafkaChannel中的send变量只能有一个值。
inFlightRequests变量在客户端缓存了还没有收到响应的客户端请求。InFlightRequests.requests变量的结构为Map<String, Deque<NetworkClient.InFlightRequest>>,key为各个broker,value为发往各个broker的还没有收到响应的请求,用ArrayDeque保存,ArrayDeque的最大长度可通过配置项配置,默认为5。 当收到响应时,该请求会从inFlightRequests中移除。
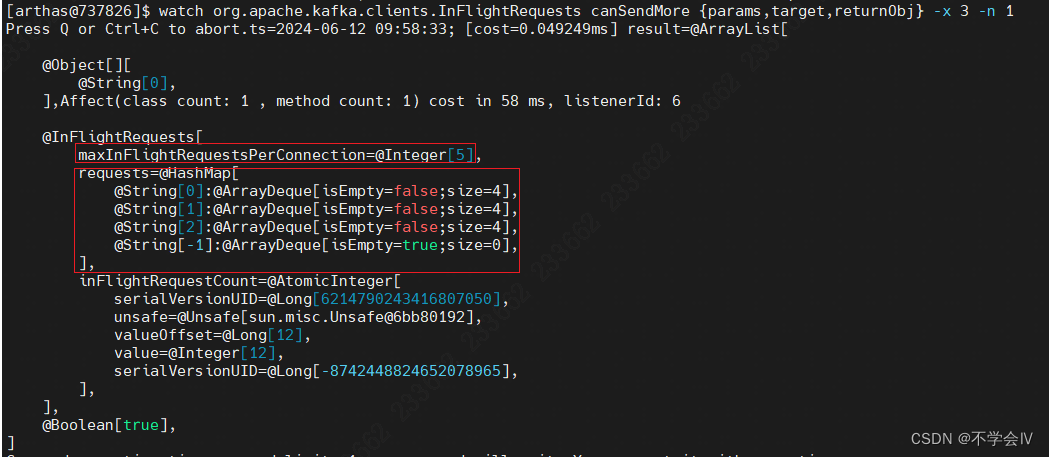
在ready()方法和send()方法中均会调用InFlightRequests.canSendMore()来确定当前是否能调用selector.send()方法。能调用的条件是:该broker对应的发送请求队列为空;或者该broker对应的发送请求队列所有的请求都已经发送了且当前请求个数少于5个。
public boolean canSendMore(String node) {Deque<NetworkClient.InFlightRequest> queue = requests.get(node);return queue == null || queue.isEmpty() ||(queue.peekFirst().send.completed() && queue.size() < this.maxInFlightRequestsPerConnection);}
client.poll()中最关键的步骤是调用selector.poll()方法,这个方法放到下一节中讲解。在selector.poll()之后,定义了多个处理方法,最重要的是handleCompletedSends()处理已经完成的发送、handleCompletedReceives()处理已经完成的接收、completeResponses()执行ClientRequest的回调函数。
public List<ClientResponse> poll(long timeout, long now) {...long metadataTimeout = metadataUpdater.maybeUpdate(now);try {this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs));} catch (IOException e) {log.error("Unexpected error during I/O", e);}// process completed actionslong updatedNow = this.time.milliseconds();List<ClientResponse> responses = new ArrayList<>();handleCompletedSends(responses, updatedNow);handleCompletedReceives(responses, updatedNow);handleDisconnections(responses, updatedNow);handleConnections();handleInitiateApiVersionRequests(updatedNow);handleTimedOutRequests(responses, updatedNow);completeResponses(responses);return responses;}handleCompletedSends()的代码如下所示,如果请求不需要响应,那么请求发送成功后,该请求就会从inFlightRequests中移除。(我们的环境中,都是需要响应的,因此这个方法内部的逻辑不会执行)。responses中被塞入了空的响应体和请求的回调函数
private void handleCompletedSends(List<ClientResponse> responses, long now) {// if no response is expected then when the send is completed, return itfor (Send send : this.selector.completedSends()) {InFlightRequest request = this.inFlightRequests.lastSent(send.destination());if (!request.expectResponse) {this.inFlightRequests.completeLastSent(send.destination());responses.add(request.completed(null, now));}}}
handleCompletedReceives()的代码如下所示,收到服务端的响应后,找到对应的请求,将该请求从inFlightRequests中移除。responses中被塞入了响应体和请求的回调函数
private void handleCompletedReceives(List<ClientResponse> responses, long now) {for (NetworkReceive receive : this.selector.completedReceives()) {String source = receive.source();InFlightRequest req = inFlightRequests.completeNext(source);Struct responseStruct = parseStructMaybeUpdateThrottleTimeMetrics(receive.payload(), req.header,throttleTimeSensor, now);if (log.isTraceEnabled()) {log.trace("Completed receive from node {} for {} with correlation id {}, received {}", req.destination,req.header.apiKey(), req.header.correlationId(), responseStruct);}// If the received response includes a throttle delay, throttle the connection.AbstractResponse body = AbstractResponse.parseResponse(req.header.apiKey(), responseStruct);maybeThrottle(body, req.header.apiVersion(), req.destination, now);if (req.isInternalRequest && body instanceof MetadataResponse)metadataUpdater.handleCompletedMetadataResponse(req.header, now, (MetadataResponse) body);else if (req.isInternalRequest && body instanceof ApiVersionsResponse)handleApiVersionsResponse(responses, req, now, (ApiVersionsResponse) body);elseresponses.add(req.completed(body, now));}}
completeResponses()的代码如下所示,可以看到是对所有的responses执行了对应请求的回调函数。
private void completeResponses(List<ClientResponse> responses) {for (ClientResponse response : responses) {try {response.onComplete();} catch (Exception e) {log.error("Uncaught error in request completion:", e);}}}
Selector
生产者客户端会按照节点对消息进行分组,一个生产者客户端需要管理到多个服务端节点的网络连接。涉及网络通信时,一般使用选择器模式。选择器使用Java NIO管理连接和读写请求,他用单个线程就可以管理多个网络连接通道。Java NIO中一些重要概念如下:
- SocketChannel(客户端网络连接通道):底层的字节数据读写都发生在通道上,比如从通道中读取数据、将数据写入通道。通道会和字节缓冲区一起使用,从通道中读取数据时需要构造一个缓冲区,调用channel.read(buffer)就会将通道的数据灌入缓冲区;将数据写入通道时,要先将数据写到缓冲区中,调用channel.write(buffer)可将缓冲区中的每个字节写入通道。
- Selector(选择器):发生在通道上的事件有读和写,选择器会通过选择键的方式监听读写事件的发生。
- SelectionKey(选择键):将通道注册到选择器上,channel.register(selector)返回选择键,这样就将通道和选择器都关联了起来。读写事件发生时,通过选择键可以得到对应的通道,从而进行读写操作。
NetworkClient会调用选择器的连接、发送、轮询方法。
连接并建立通道
选择器的connect()方法会创建客户端到指定远程服务器的网络连接,KafkaChannel是对SocketChannel的一层封装,更确切地说,KafkaChannel内部的transportLayer是对SocketChannel的一层封装。
KafkaChannel中有一个传输层transportLayer,有多个实现,比如纯文本模式、sasl、ssl加密模式。PlaintextTransportLayer是纯文本的传输层实现。
KafkaChannel使用Send和NetworkReceive表示网络传输中发送的请求和接收的响应。NetworkReceive有两个缓冲区,其中size缓冲区表示数据的长度,buffer缓冲区表示数据的内容。NetworkReceive从连接读取数据的时候,先读取消息的头部写入size缓冲区,其中封装了消息长度,然后根据消息长度创建buffer缓冲区,读取连接中的消息体。
当选择器调用KafkaChannel的read()和write()方法时,最终会通过NetworkReceive.readFrom()和Send.writeTo()方法调用SocketChannel的read()和write()方法。
通道上的读写操作
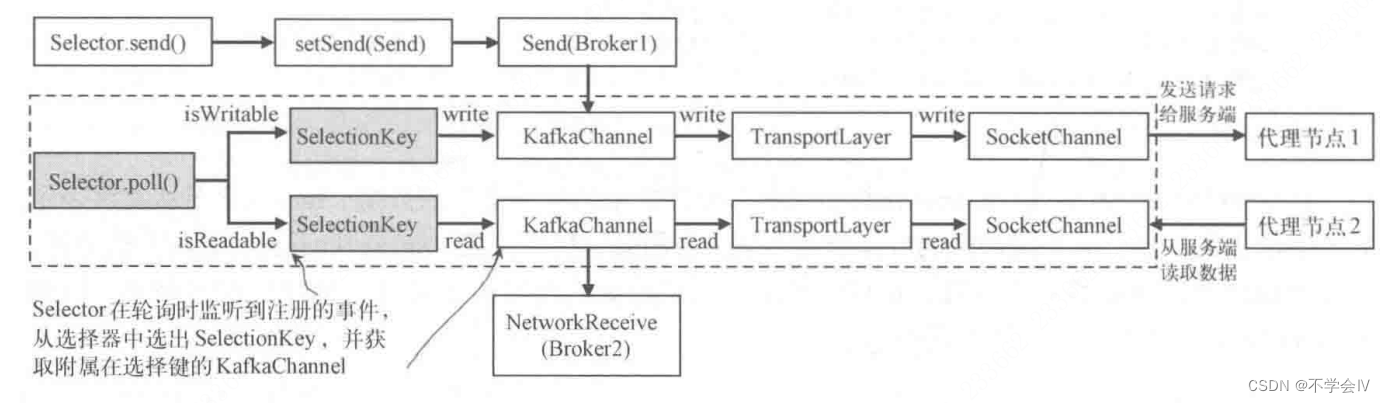
Sender的run()方法中会调用client.send(),client.send()会调用Selector.send(),继而调用KafkaChannel.setSend()。客户端发送的每个Send请求,都会被设置到一个Kafka通道中,如果一个Kafka通道上还有未发送成功的Send请求,则后面的请求就不能发送。即客户端发送请求给服务端,在一个Kafka通道中,一次只能发送一个Send请求。KafkaChannel.setSend()还注册了写事件,选择器监听到写事件,会调用KafkaChannel.write()方法,将setSend()保存到Kafka通道中的Send发送到传输层的SocketChannel中。
KafkaChannel.setSend()时会注册写事件,当请求全部写入SocketChannel后就会取消写事件,当然一次write()调用可能写不完,这时不会取消写事件,只有当多次write()写完一个请求时,才会取消写事件。代码如下:
public void setSend(Send send) {if (this.send != null)throw new IllegalStateException("Attempt to begin a send operation with prior send operation still in progress, connection id is " + id);this.send = send;this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);}public Send write() throws IOException {Send result = null;if (send != null && send(send)) {result = send;send = null;}return result;}private boolean send(Send send) throws IOException {send.writeTo(transportLayer);if (send.completed())// 请求全部写入socketChannel,取消写事件transportLayer.removeInterestOps(SelectionKey.OP_WRITE);return send.completed();}
对于read,一次poll会循环调用KafkaChannel.read()方法,将通道中的数据全部读出。
注:为什么要频繁注册和取消写事件,因为epoll里面有2种模式:LT(水平触发)和 ET(边缘触发)。水平触发(条件触发):读缓冲区只要不为空,就一直会触发读事件;写缓冲区只要不满,就一直会触发写事件。这个比较符合编程习惯,也是epoll的缺省模式。对于LT模式,要避免“写的死循环”问题:写缓冲区为满的概率很小,也就是“写的条件“会一直满足,所以如果你注册了写事件,没有数据要写,但它会一直触发,所以在LT模式下,写完数据,一定要取消写事件;(https://blog.csdn.net/chunlongyu/article/details/52636762)
总结
KafkaProducer中会起一个Sender线程,Sender线程中主要有两个方法:sendProducerData()和client.poll()。sendProducerData()负责准备数据并将数据set到通道中等待发送,client.poll()负责真正执行网络的io操作,在每次poll操作中必定有3次发送事件(假设集群中有3个kafka,生产者客户端会分别和3个kafka建立3个通道,这也是每次setSend不会失败的原因,如果失败了则该通道就关闭了)以及若干的接收响应事件。(在一次poll中,是否可以同时处理发送和接收?)。