一种基于因果关系的创新模型,名为调整加/减模型,用于精准量化个人在团队运动中的贡献。该模型基于明确的因果逻辑,将个体运动员的价值定义为:在假设情景下,用一名价值为零的球员替换该球员后,预期比赛得分的变动量。这一度量标准在因果分析框架内,为评估运动员的假设性替换提供了有力依据。
为应对在估算球员价值时可能遭遇的间接测量混杂因素,我们采纳了因子建模领域的最新研究成果。在模型中,每位球员都被视为影响比赛结果的“治疗”因素,从而能够更精确地剥离其他潜在影响因素,进而准确估算出每位球员的真实价值。
为了验证模型的实用性和有效性,我们将其应用于足球和篮球的实际比赛数据,并展示了模型在不同情境下的表现。这一模型不仅为体育分析领域带来了新的视角和方法,也为运动员评价、团队构建和策略制定提供了更为科学的参考依据。
关键词:体育分析,因果推断,调整加/减模型,岭回归分析,运动员评级系统
引言
1.绪论
在体育竞技领域,对球员个人表现的准确评估一直是教练、球探和体育分析师们关注的焦点。球员的价值不仅体现在其个人技能和天赋上,更在于其在团队中如何发挥作用,如何与其他队员协同作战。然而,由于球员们在比赛中是作为一个整体进行竞技的,因此如何准确地分割和量化每位球员对比赛结果的贡献成为了一个具有挑战性的问题。
传统的球员价值评估方法,如调整加/减模型(APM),主要依赖于统计分析,通过回归分析来估算球员在比赛中的贡献。然而,这种方法在本质上是一个条件期望模型,它基于球员在场时的得分情况来评估其价值,这可能受到多种未观测到的混杂因素的影响,如教练的战术安排、对手的实力、球员之间的化学反应等。这些混杂因素往往难以直接测量,但它们对球员表现的影响却是不可忽视的。
为了克服这一挑战,本文提出了一种新颖的方法来估算球员的“因果”价值。我们将评估问题视为一个因果推断问题,其中团队中的每位球员被视为一个“治疗”,而比赛得分则是结果。我们的方法借鉴了潜在因子建模的最新研究,通过拟合一个潜在变量模型来分析每场比赛的球员阵容,以捕获哪些球员更有可能一起出场。这个模型不仅考虑了球员之间的直接关联,还通过潜在变量间接地考虑了未观测到的混杂因素的影响。
具体来说,我们开发的受因果启发的调整加/减模型(CAPM)首先利用潜在变量模型对每场比赛的球员阵容进行建模。这个模型通过分析球员之间的共现模式,揭示了哪些球员更有可能在同一场比赛中出场。然后,CAPM利用这个模型中的潜在变量来估算那些间接测量的混杂因素的替代变量。这些替代变量可以作为混杂因素的代理,用于校正结果模型中的偏差。
接下来,CAPM使用一个包含潜在变量的比赛得分的APM作为结果模型。这个模型将球员作为协变量,将比赛得分差异作为结果变量,通过回归分析来估算每位球员的系数。这些系数直接反映了球员在比赛中的贡献,揭示了他们的“因果”价值。与传统的APM相比,CAPM通过潜在变量模型考虑了未观测到的混杂因素的影响,从而能够更准确地评估球员的表现。
本文的主要贡献在于提出了一种量化球员因果价值的新方法,并开发了相应的算法来实现这一方法。通过结合潜在因子建模和因果推断的思想,CAPM为体育分析领域提供了一种新的视角和工具,有助于更准确地评估球员的表现和贡献。
在本文中,我们将详细阐述CAPM模型和每个组成部分的高效算法,并通过实际比赛数据来验证其有效性和准确性。我们将使用2014年至2016年的四个欧洲职业足球联赛和2014年至2018年的NBA篮球赛季的数据来进行实证研究。我们期望通过这项研究,能够为体育分析领域带来新的进展,并为球队管理和比赛预测提供更科学的依据。同时,我们也将探讨CAPM的局限性和潜在改进方向,以进一步推动该领域的研究和发展。
2. 相关工作与背景
在体育竞技中,准确评估球员的表现一直是研究者和球队管理层关注的焦点。多年来,研究人员提出了多种方法来评估球员的绩效,这些方法通常基于不同的数据类型和分析框架。例如,Santos-Fernandez等人(2019)综述了利用贝叶斯方法进行球员评估的研究,而Terner和Franks(2021)则专门针对篮球领域的评估方法进行了总结。
从数据类型来看,评估球员的方法可以大致分为两类。第一类方法主要依赖于球员的个体数据,如传球、射门等事件数据(Thomas等人,2009),以及球员的身体和心理特征(Carvalho等人,2017;Giles等人,2018)。第二类方法则更侧重于团队层面的比赛数据,通过追踪球员在比赛中的控球、防守等动作来评估其表现(Cervone等人,2016;Le等人,2017;Bu等人,2019;Franks等人,2015;Fernández等人,2021)。
在团队层面的评估方法中,调整加/减(APM)模型因其全面性和实用性而备受关注。APM模型起源于篮球(Leonhardt,2003;Rosenbaum,2004)和曲棍球(Sill,2010;Macdonald,2011a,b)领域,并逐渐扩展到其他运动项目。APM的核心思想是将球队阵容作为解释变量,将比赛结果作为响应变量,通过回归分析来估计球员对比赛结果的贡献。多年来,研究人员提出了多种APM的变体(Ilardi和Barzilai,2008;Deshpande和Jensen,2016;Thomas等人,2013;Gramacy等人,2013;Nandakumar和Jensen,2019;Hvattum,2019),以提高模型的预测准确性和解释性。
在足球分析领域,APM模型的应用也逐渐增多。这些研究在回归模型中考虑了不同的变量(Pantuso和Hvattum,2021;Sæbø和Hvattum,2019),采用了不同的先验分布(Matano等人,2023),并考虑了不同的比赛结果(Kharrat等人,2020),如预期进球数、胜负或得分差异。一些研究还结合了球员位置信息和基于人类的评级来进一步细化评估(Pelechrinis和Winston,2021)。
尽管APM模型在球员评估方面取得了显著进展,但它仍然面临一些挑战。其中最大的挑战之一是潜在混杂问题,即未观测到的变量可能对球员的表现和比赛结果产生影响。为了处理这些潜在混杂因素,研究者们开始探索因果分析的方法。然而,在体育领域中,明确关注因果分析的研究相对较少。Gauriot和Page(2019)在足球中通过分离准实验情况来估计幸运进球对球员评估的因果效应,而Yam和Lopez(2019)则使用因果推理评估了橄榄球队在不使用特定策略时的潜在好处。这些研究为我们提供了宝贵的启示,但也表明在体育领域中进行因果分析仍然具有挑战性。
为了处理潜在混杂问题,我们借鉴了因子模型的思想。因子模型通过拟合潜在变量来揭示数据中未观测到的结构和关联,从而有助于我们更准确地评估球员的表现。此外,我们还比较了其他处理潜在混杂的方法,如代理变量、工具变量和前门调整等。然而,这些方法通常需要额外的协变量,这在体育领域中可能难以获取。因此,我们专注于在没有这些协变量的情况下进行因果分析。
综上所述,本文在现有研究的基础上,进一步探索了利用APM模型进行球员评估的方法,并结合因果分析和因子模型的思想来处理潜在混杂问题。通过这种方法,我们期望能够更准确地评估球员在团队中的表现,并为球队管理和比赛预测提供更科学的依据。
3. 团体运动中的因果推理方法
在评估球员时,我们的核心目标是从团队的集体表现中剥离出个人的贡献。这本质上是一个因果问题,即:“如果我们用另一个球员替换场上的这名球员,比赛结果会有何不同?”本文将探讨如何通过分析体育比赛的观测数据集来解答这一问题。
3.1 球员评估
我们观察到的数据来自体育比赛,特别是足球和篮球的比赛。在这些比赛中,每个团队都由一组球员组成;我们设球员ℓ属于团队ℓ。我们分析了多场比赛(在足球中)或比赛的片段(在篮球中),并简化为每场比赛只涉及两个团队,分别为团队A和团队B,其中团队A的索引小于团队B。在每场比赛中,我们记录了球员ℓ是否参与了比赛,用 ℓ , ℓ ∈ 0 , 1 ℓ,ℓ ∈ {0, 1} ℓ,ℓ∈0,1表示,其中1表示球员ℓ参与了比赛,0表示未参与。在足球数据中,这通常指的是球员是否首发上场;在篮球数据中,它指的是球员在某一片段内是否在场。最终,我们关注于比赛结果的差异,即团队A与团队B之间的得分差异。
为了量化球员的价值,我们将其视为一个因果推断问题。因果科学试图回答关于世界在假设干预下的变化问题。基于此,我们定义球员ℓ的价值为在两种干预场景下预期得分差异的变化。一种是我们强制球员ℓ上场而一个“零价值”球员∅不上场,另一种是我们强制球员 ∅ ∅ ∅上场而球员 ℓ ℓ ℓ不上场。我们用 Λ ℓ Λℓ Λℓ表示这个量:
Λ ℓ : = E [ Δ S ∣ do ( ℓ ℓ = 1 , ℓ ∅ = 0 , ω = ω ℓ ) ] − E [ Δ S ∣ do ( ℓ ℓ = 0 , ℓ ∅ = 1 , ω = ω ℓ ) ] \Lambda_\ell := \mathbb{E}[\Delta S \mid \text{do}(\ell_\ell = 1, \ell_\emptyset = 0, \omega = \omega_\ell)] - \\\mathbb{E}[\Delta S \mid \text{do}(\ell_\ell = 0, \ell_\emptyset = 1, \omega = \omega_\ell)] Λℓ:=E[ΔS∣do(ℓℓ=1,ℓ∅=0,ω=ωℓ)]−E[ΔS∣do(ℓℓ=0,ℓ∅=1,ω=ωℓ)]
其中,ΔS是第一团队得分差异的随机变量, d o do do操作符表示强制性的干预, ω ω ω表示除了球员 ℓ ℓ ℓ和球员 ∅ ∅ ∅外所有其他影响比赛的因素(如对手团队和其他球员的阵容)。
在评估球员时,最常用的方法之一是带有岭回归的调整加/减(APM)模型(Sill, 2010)。APM假设每个球员ℓ对他们的团队预期得分有一个贡献αℓ,并使用回归模型来模拟得分差异。具体来说,它使用阵容数据和比赛结果来通过惩罚回归估计球员的价值:
α ∗ = arg min α ∑ ω , ℓ ( Δ S ω , ℓ − ∑ ℓ : ω ℓ = ω α ℓ , ω + λ ∥ α ∥ 2 2 ) \alpha^* = \text{arg min}_\alpha \sum_{\omega, \ell} (\Delta S_{\omega, \ell} - \sum_{\ell: \omega_\ell = \omega} \alpha_{\ell, \omega} + \lambda \|\alpha\|_2^2) α∗=arg minαω,ℓ∑(ΔSω,ℓ−ℓ:ωℓ=ω∑αℓ,ω+λ∥α∥22)
然而,APM估计的价值与我们在上述方程中定义的因果价值有所不同。APM估计的是一个观测量(条件期望),而不是一个因果量。在进行从观测数据中进行的因果推断时,可能会存在未测量的混杂因素——这些是影响谁参加比赛和最终得分差异的未观测变量。例如,如果教练倾向于在轻松取胜的比赛中让某个特定球员上场,以便让其他(更好)的球员休息,APM可能会为这个球员估计一个较高的α∗_ℓ,但方程1中定义的因果价值Λℓ可能并没有那么高。因此,我们的目标是开发一种算法,用于估计每个球员的价值,同时尽量减少由于这种混杂因素造成的偏差。
3.2 评估球员价值评估
在解决未观察到的混杂因素问题之前,我们将讨论我们将要使用的因果推断的主要策略,即后门调整(Pearl, 1993)和g-估计(Robins, 1986)。这些策略将为我们处理未观察到的混杂因素提供基础。
假设我们能够观察到每个比赛的变量 W W W,它是混杂因素的可调整变量(Pearl et al., 2009)。比赛数据来自真实分布 p ( W , A , B , X , S ) p(W, A, B, X, S) p(W,A,B,X,S),其中 W W W是混杂因素, A A A是球员上场的指示变量, B B B是比赛的其他因素(如对手团队), X X X是阵容信息, S S S是比赛得分。
如果我们能够观察到 W W W,我们可以利用这些数据以及后门调整来估计球员的价值。首先,我们定义条件期望的符号,给定团队 ℓ ℓ ℓ正在比赛,球员 ℓ ℓ ℓ在场上,球员 ∅ ∅ ∅不在场上,以及混杂因素 W W W:
Δ S ^ ℓ ( W , A ℓ , A ∅ ) = E [ Δ S ∣ A = A ℓ , A ∅ = A ∅ , X = X ℓ , W ] \Delta\hat{S}_\ell(W, A_\ell, A_\emptyset) = \mathbb{E}[\Delta S \mid A = A_\ell, A_\emptyset = A_\emptyset, X = X_\ell, W] ΔS^ℓ(W,Aℓ,A∅)=E[ΔS∣A=Aℓ,A∅=A∅,X=Xℓ,W]
这里,我们使用大写和小写字母(如 A ℓ A_ℓ Aℓ和 a ℓ a_ℓ aℓ)来区分随机变量及其可能的值。这个期望是在对手团队和谁在场上(除了 ℓ ℓ ℓ和 ∅ ∅ ∅之外)的分布上的。请注意,虽然方程中的期望是干预性的,但这个期望是条件性的,并且可以从观测数据中估计(假设混杂因素 W W W被观察到)。
使用这些条件期望,我们可以将球员的价值写成调整变量 W W W的积分:
Λ ℓ = ∫ p ( W ) ( Δ S ^ ( W , 1 , 0 ) − Δ S ^ ( W , 0 , 1 ) ) d W \Lambda_\ell = \int p(W)(\Delta\hat{S}(W, 1, 0) - \Delta\hat{S}(W, 0, 1)) dW Λℓ=∫p(W)(ΔS^(W,1,0)−ΔS^(W,0,1))dW
这个方程是球员价值的识别公式,是因果量在观测分布中的表达。它使用了后门调整(Pearl, 1993)。
识别公式是因果估计的起点。考虑一个(假想的)数据集,其中包含了这个混杂因素。有了这个数据,我们可以估计 Δ S ^ ( W , A ℓ , A ∅ ) ΔŜ(W, A_ℓ, A_∅) ΔS^(W,Aℓ,A∅),其中 ( A ℓ , A ∅ ) = ( 1 , 0 ) (A_ℓ, A_∅) = (1, 0) (Aℓ,A∅)=(1,0)或 ( A ℓ , A ∅ ) = ( 0 , 1 ) (A_ℓ, A_∅) = (0, 1) (Aℓ,A∅)=(0,1)。然后,我们可以使用这个估计来近似上述方程,例如使用蒙特卡洛方法。
然而,本文的前提是我们没有观察到混杂因素;它们通常只是间接测量的。抛开我们没有观察到混杂因素的问题,在使用上述方程进行因果推断时,我们主要假设了什么?主要假设是 W W W阻断了 A A A和 ( A ℓ , A ∅ , X ) (A_ℓ, A_∅, X) (Aℓ,A∅,X)之间的所有后门路径(Pearl et al., 2009)。换句话说, W W W包含了所有混杂因素。此外,还有一个积极性假设,它要求对于所有可能的 W W W的值,如果 p ( W ) > 0 p(W) > 0 p(W)>0,则 p ( ( A ℓ , A ∅ , X ) ∈ S ∣ W ) > 0 p((A_ℓ, A_∅, X) ∈ S | W) > 0 p((Aℓ,A∅,X)∈S∣W)>0。这意味着混杂因素 W W W的值不应该限制 ( A ℓ , A ∅ , X ) (A_ℓ, A_∅, X) (Aℓ,A∅,X)的支持。换句话说,任何可能的 ( A ℓ , A ∅ , X ) (A_ℓ, A_∅, X) (Aℓ,A∅,X)的值在给定 W W W时都应该是可能的。
尽管如此,我们面临的主要挑战是未观察到的混杂因素。接下来,我们将讨论在存在未观测混杂因素的情况下,如何估计球员的因果价值。
3.3 调整加/减模型(CAPM)
CAPM的核心思想是将球员价值的推断视为一个因果推断问题。每个上场的球员都可以看作是一种“治疗”,对最终得分有所贡献,我们希望通过因果推断来估计每个球员的价值。这里,我们借鉴了因果推断中的因子建模思想,开发了一种算法,用于在存在多种治疗(即球员上场)的情况下,考虑一些未观察到但间接测量的混杂因素。
我们的方法论分为两个阶段。首先,我们构建一个变量,该变量能够使阵容条件独立。Wang和Blei(2019a)提出了一种使用概率因子模型来构建此类变量的方法,即一个描述谁在参加比赛的模型。其次,我们使用第一阶段构建的变量作为“替代混杂因素”,在估计每个球员价值时进行调整。这个阶段利用了上述的估计方法,但用替代混杂因素替换了真实的混杂因素。
这种方法背后的直觉是,因子模型能够捕获未明确观察到的混杂因素的信息,这些信息在球员共同上场的模式中有所体现。例如,在进攻策略中,教练可能倾向于选择一组特定的球员;而在防守策略中,则可能选择另一组球员。
理论上,如果构建的变量能够使阵容条件独立,那么它就有可能捕获一些间接测量的“多因素”混杂因素,即那些影响许多球员的未测量混杂因素。然而,这个理论依赖于一些理想化的假设。在实践中,我们希望一个好的概率因子模型能够捕获一些未测量的混杂因素,并在下游的因果推断中减少未校正估计的偏差。
在详细描述算法之前,我们需要提出一个关键的因果假设:我们假设不存在仅影响一个球员的混杂因素。换句话说,该算法无法控制那些只影响一个且仅有一个球员的未观察到的混杂因素。例如,一个球员的临时受伤就是一个单一球员的混杂因素,该算法无法控制这样的混杂因素。
用数学符号表达,我们假设混杂因素 W W W对球员 ℓ ℓ ℓ的影响不是唯一的,即不存在 W ℓ W_ℓ Wℓ这样的混杂因素只影响球员 ℓ ℓ ℓ。我们的目标是使用间接测量的变量 Z Z Z(通过因子模型或其他方法构建)来近似 W W W的影响,并在估计球员价值时进行调整。
3.3.1 上场球员的概率因子模型
CAPM的第一阶段涉及构建一个上场球员的因子模型。这个模型基于泊松分解(Poisson factorization),是一种非负矩阵分解的贝叶斯变体。模型中包含K个组件,每个球员ℓ和团队都有一个与之关联的K维非负潜在特征向量。球员是否上场取决于球员特征与对方团队特征之间的亲和力。以下是阵容因子模型的生成过程描述:
-
球员和团队的潜在特征生成:
对于每个球员ℓ(共T个球员):
ξ ℓ ∼ Gamma ( ⋅ ) for ℓ = 1 , … , T \xi_\ell \sim \text{Gamma}(\cdot) \quad \text{for } \ell = 1, \ldots, T ξℓ∼Gamma(⋅)for ℓ=1,…,T
对于每个团队(共M个团队):
ϕ m ∼ Gamma ( ⋅ ) for m = 1 , … , M \phi_m \sim \text{Gamma}(\cdot) \quad \text{for } m = 1, \ldots, M ϕm∼Gamma(⋅)for m=1,…,M -
阵容生成:
对于一场比赛,其中团队A(特征为(\xi_AKaTeX parse error: Can't use function '\(' in math mode at position 11: )对抗团队B(特征为\̲(̲\xi_B):
对于每个球员ℓ:
x i , ℓ ∼ Poisson ( ϕ ℓ ⋅ ξ A ) if ℓ ∈ Team A x_{i,\ell} \sim \text{Poisson}(\phi_\ell \cdot \xi_A) \quad \text{if } \ell \in \text{Team A} xi,ℓ∼Poisson(ϕℓ⋅ξA)if ℓ∈Team A
x i , ℓ ∼ Poisson ( ϕ ℓ ⋅ ξ B ) if ℓ ∈ Team B x_{i,\ell} \sim \text{Poisson}(\phi_\ell \cdot \xi_B) \quad \text{if } \ell \in \text{Team B} xi,ℓ∼Poisson(ϕℓ⋅ξB)if ℓ∈Team B
x i , ℓ = 0 if ℓ ∉ Team A and ℓ ∉ Team B x_{i,\ell} = 0 \quad \text{if } \ell \notin \text{Team A} \text{ and } \ell \notin \text{Team B} xi,ℓ=0if ℓ∈/Team A and ℓ∈/Team B
请注意,该模型不直接涉及比赛的结果(即得分差异),它仅用于建模球员阵容。潜在变量捕捉了球员上场安排的规律性。
我们使用阵容因子模型来估计一个“替代混杂因素”。首先,我们条件化每场比赛的上场阵容,并估计潜在变量的后验分布。这里我们使用变分推断来近似后验。变分推断适用于我们即将研究的数据集规模。遵循因果调整算法的框架,我们将使用近似后验来构建每场比赛的替代混杂因素。具体来说,我们连接上场团队的潜在特征的后验期望,记作 Φ ^ = ( ϕ ^ A , ϕ ^ B ) \hat{\Phi} = (\hat{\phi}_A, \hat{\phi}_B) Φ^=(ϕ^A,ϕ^B),其中 ϕ ^ ≈ E [ ϕ ∣ X = x ] \hat{\phi} \approx \mathbb{E}[\phi | X = x] ϕ^≈E[ϕ∣X=x]。如果模型对阵容数据提供了良好的拟合,那么这个变量将使 x i , ℓ x_{i,\ell} xi,ℓ 条件独立。
备注: 关于可定位性的说明:
熟悉Wang和Blei(2019a)的读者可能知道,该模型在某些推断中假设了一个名为“可定位性”的假设。这个假设(大致地说)意味着未测量的混杂因素是球员阵容的一个未知但确定的函数。虽然可定位性是一个严格的假设,但在实践者愿意做出其他(参数化)假设的情况下,它可以放宽;更多讨论见Wang和Blei(2019a,2020)。
对于阵容因子模型的适应,还有一些其他细节需要考虑。例如,在变分推断中,我们通过监控对数似然的变化来确定算法的收敛性。潜在维度K通过交叉验证来确定,同时考虑保留的对数似然作为模型拟合度的度量。最后,我们通过执行预测性检查来评估因子模型的拟合优度,类似于Wang和Blei(2019a)中的方法;更多细节见附录A。
3.3.2 结果模型
在上一节中,我们讨论了如何通过阵容因子模型来理解球员的派遣模式。现在,我们将利用这一模型来估计每个球员的价值,即方程1中的目标。我们将利用识别公式(类似于方程4),但数据中将不包含实际的混杂因素。相反,我们将使用替代混杂因素来定义条件期望。
首先,我们定义条件期望如下:
Δ S ^ ( W , A ℓ , A ∅ ) = E [ Δ S ∣ A ℓ = a ℓ , A ∅ = a ∅ , X ∗ = W ] \Delta \hat{S}(W, A_\ell, A_\emptyset) = \mathbb{E}[\Delta S | A_\ell = a_\ell, A_\emptyset = a_\emptyset, X^* = W] ΔS^(W,Aℓ,A∅)=E[ΔS∣Aℓ=aℓ,A∅=a∅,X∗=W]
其中, X ∗ X^* X∗ 表示替代混杂因素, A ℓ A_\ell Aℓ 表示球员ℓ是否上场, A ∅ A_\emptyset A∅ 表示其他所有球员是否上场的状态,而 Δ S \Delta S ΔS 是两队得分的差异。
为了估计这个期望,我们将构建一个结果模型,即给定双方阵容和替代混杂因素的情况下,得分差异的条件期望模型。最简单的方法是使用回归差分:
E [ Δ S ∣ A = a , X ∗ = W ] = ∑ ℓ ∈ A α ℓ x i , ℓ + γ ⋅ W A − ∑ ℓ ∈ B α ℓ x i , ℓ − γ ⋅ W B \mathbb{E}[\Delta S | A = a, X^* = W] = \sum_{\ell \in A} \alpha_\ell x_{i,\ell} + \gamma \cdot W_A - \sum_{\ell \in B} \alpha_\ell x_{i,\ell} - \gamma \cdot W_B E[ΔS∣A=a,X∗=W]=ℓ∈A∑αℓxi,ℓ+γ⋅WA−ℓ∈B∑αℓxi,ℓ−γ⋅WB
这里, α ℓ \alpha_\ell αℓ 是每个球员的系数, γ \gamma γ 是替代混杂因素的系数, W A W_A WA 和 W B W_B WB 分别是团队A和团队B的替代混杂因素。这个模型将每个团队的预期得分建模为上场球员贡献的总和,加上替代混杂因素的项。
或者,我们可以使用“重建原因”项来替代替代混杂因素。重建原因是阵容指标给定替代混杂因素的条件期望:
x ^ i ℓ : = E [ x i ℓ ∣ W ] = ∑ k = 1 K π ℓ k ϕ k \hat{x}_{i\ell} := \mathbb{E}[x_{i\ell} | W] = \sum_{k=1}^K \pi_{\ell k} \phi_k x^iℓ:=E[xiℓ∣W]=k=1∑Kπℓkϕk
其中, π ℓ k \pi_{\ell k} πℓk 和 ϕ k \phi_k ϕk 是通过阵容因子模型学习到的潜在变量。
带有重建原因的线性结果模型可以表达为:
E [ Δ S ∣ A = a , X ∗ = W ] = ∑ ℓ ∈ A ( α ℓ x i , ℓ + α ℓ ′ x ^ i ℓ ) − ∑ ℓ ∈ B ( α ℓ x i , ℓ + α ℓ ′ x ^ i ℓ ) \mathbb{E}[\Delta S | A = a, X^* = W] = \sum_{\ell \in A} (\alpha_\ell x_{i,\ell} + \alpha_{\ell}' \hat{x}_{i\ell}) - \sum_{\ell \in B} (\alpha_\ell x_{i,\ell} + \alpha_{\ell}' \hat{x}_{i\ell}) E[ΔS∣A=a,X∗=W]=ℓ∈A∑(αℓxi,ℓ+αℓ′x^iℓ)−ℓ∈B∑(αℓxi,ℓ+αℓ′x^iℓ)
在这个模型中,我们为每个球员和每个重建的球员都分配了系数。
如何估计结果模型呢?考虑一个包含阵容和得分的数据集 { ( W , V , A , Y ) } \{(W, V, A, Y)\} {(W,V,A,Y)}。首先,如第3.3.1节所述,我们估计替代混杂因素,并创建一个扩展数据集 { ( W , V , W ^ A , W ^ B , A , Y ) } \{(W, V, \hat{W}_A, \hat{W}_B, A, Y)\} {(W,V,W^A,W^B,A,Y)}。然后,我们使用最大似然估计来估计方程11中的结果模型参数:
( α ^ , γ ^ ) = arg max ∑ i = 1 N log p ( V i ∣ A i , W ^ A i , W ^ B i ; α , γ ) (\hat{\alpha}, \hat{\gamma}) = \text{arg max} \sum_{i=1}^N \log p(V_i | A_i, \hat{W}_{A_i}, \hat{W}_{B_i}; \alpha, \gamma) (α^,γ^)=arg maxi=1∑Nlogp(Vi∣Ai,W^Ai,W^Bi;α,γ)
在实践中,我们可能会使用正则化回归,如带有岭惩罚的回归。最后,使用拟合的结果模型,我们可以从方程1中通过受因果启发的调整模型来估计每个球员的价值。具体来说,我们使用第3.2节中的g-估计策略,但用替代混杂因素替换了观察到的混杂因素。当使用方程11的线性结果模型估计 Δ S ^ ( W , A ℓ , A ∅ ) \Delta \hat{S}(W, A_\ell, A_\emptyset) ΔS^(W,Aℓ,A∅) 时,每个球员的价值可以通过它们拟合的回归系数来近似:
Λ ℓ ≈ α ^ ℓ \Lambda_\ell \approx \hat{\alpha}_\ell Λℓ≈α^ℓ
完整的算法和推导细节可以在附录B中找到。
3.4 CAPM局限性
在探讨球员价值的因果推断过程中,我们虽已借助公式1和特定的因子模型来识别球员上场部署的共现模式,并进一步估计替代混杂因素,但这一方法在实际应用中展现出其固有的局限性。
1. 因子模型的理论与现实差距
理论上,因子模型似乎提供了一种间接测量混杂因素的途径,但这一理论框架在实际操作中却面临着诸多挑战。首先,它期望能够捕捉到所有影响球员和比赛结果的未测量多因素混杂因素,然而,这一理想状态在现实中难以实现。例如,个别运动伤害等单因素混杂因素,由于不会在场上的球员之间产生依赖,因此难以被因子模型所捕捉。
2. 因子模型的完美性挑战
再者,任何因子模型都是对现实世界的简化表达,难以完全反映阵容构成的复杂性。教练在做出阵容决策时,往往需要考虑多种协变量,如主客场状态、天气条件等个性化因素。这些因素虽然可能同时影响多个球员,但可能并不完全符合多因素混杂因素的要求,因此难以被简单的因子模型所吸收。
3. 共线性问题的挑战
此外,阵容数据中的共线性问题也是一个不容忽视的挑战。当球员几乎总是以相同的阵容出现时,他们的个人贡献将变得难以识别。虽然岭回归等方法可以提供更稳定的估计,但这种方法可能会将贡献大致平均分配给同时出现的球员,从而无法准确反映球员的实际表现。
4. 时间序列元素的缺失
最后,我们的模型在处理阵容数据时,未能充分考虑其中的时间序列元素。在篮球和足球等体育项目中,游戏的连续性和赛季轨迹都涉及到时间序列的影响。忽略这一元素可能导致我们对球员表现的评估产生偏差。
综上所述,虽然因子模型为我们提供了一种调整未测量混杂因素的途径,但其在实际应用中仍存在诸多局限性。为了更准确地评估球员的价值和表现,我们需要进一步探索和完善这一方法,同时考虑引入更多类型的数据和更复杂的模型来应对这些挑战。
4. CAPM实证研究
在我们的实证研究中,我们利用足球和篮球的广泛数据集,包括实际比赛数据和模拟生成的数据,对提出的球员价值因果推断模型(CAPM)进行了全面评估。我们的分析显示,CAPM相较于传统的平均表现模型(APM,基于岭回归的公式2)在预测比赛结果方面展现出了更高的准确性。此外,CAPM在球员排名方面也更贴近专业分析师的评估,提供了更为合理的球员价值排序。
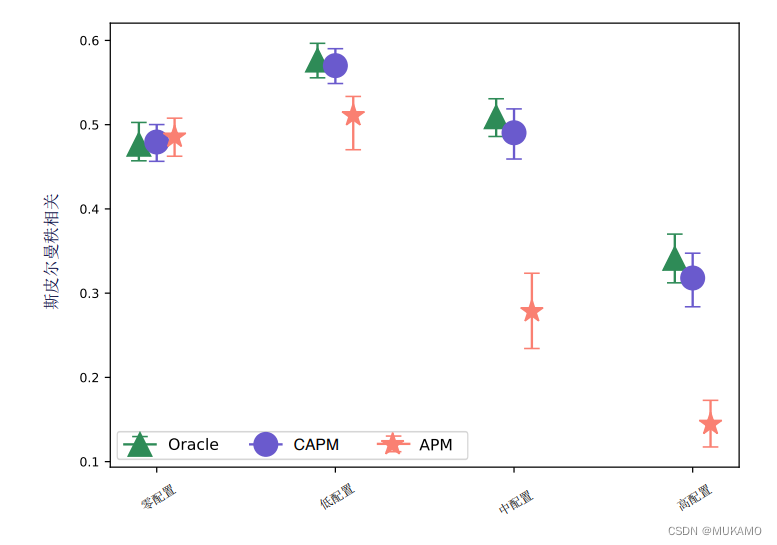
备注:图1:合成数据:恢复真实值的能力。因果启发式调整正负值(CAPM)比标准APM更能在不同混杂水平下产生与真实排名一致的球员排名。我们展示了从低(最左边)到高(最右边)的各种混杂水平下,真实排名 GT \text{GT} GT与推断排名 inferred \text{inferred} inferred之间的斯皮尔曼相关性,这里数值越高越好。每个数据点是100次模拟的中位数,条形表示四分位数。
为了验证CAPM的有效性,我们首先在模拟的足球数据上进行了测试。在这些模拟数据中,每个球员对比赛结果的真正影响是已知的,为我们提供了一个基准来评估不同估计方法的准确性。我们特意在数据中引入了不同程度的混杂因素,以检验CAPM在复杂场景下的表现。数据的生成过程基于第3.3.1节的因子模型,确保我们能够在控制条件下进行准确评估。
具体而言,我们首先根据因子模型生成了混杂因素和阵容数据。为了确保这些数据的真实性,我们使用了真实足球数据来设定模型的超参数。接着,我们按照第3.3.2节所述的方法生成比赛结果,通过调整球员影响系数和团队混杂因素系数来模拟不同程度的混杂场景。我们模拟了一个包含20支球队、每队11名球员的足球联赛,总球员数约为500名。
在生成的数据集上,我们采用了多种方法来估计球员价值,包括APM和CAPM。我们根据估计值与真实因果效应的接近程度来评估每种方法的性能。为了提供一个基准,我们还构建了一个“神谕”模型,该模型直接利用真实但未观察到的混杂因素进行估计,从而得出球员因果价值的无偏估计。
研究结果显示,在大多数情况下,尤其是在混杂程度较高的情况下,CAPM能够更准确地恢复球员的真实价值(见图1)。随着混杂程度的增加,CAPM相对于APM的性能优势愈发明显。附录部分提供了更为详细的实验结果和数据分析。
值得注意的是,尽管在合成数据的测试中CAPM展现出了卓越的性能,但在实际应用中可能仍会受到一些因素的限制,如第3.4节所述。因此,在未来的研究中,我们将继续探索如何进一步改进CAPM,以更好地适应真实世界的复杂性。
4.1 球类运动的实证检验
为了验证CAPM(球员价值因果推断模型)的有效性,我们进一步在真实的足球和篮球数据上进行了深入研究。
1. 足球数据实验
在足球领域,我们采用了一个开源数据集,该数据集覆盖了2014年至2016年间四个职业男子联赛的首发阵容和比赛结果。由于数据集未包含比赛中球员替换的信息,我们假设首发球员对比赛结果有贡献,并忽略了替补球员的潜在影响。
2. 篮球数据实验
对于篮球,我们利用了一个包含2014年至2018年间NBA阵容和得分的专有数据集。与足球数据不同,这个篮球数据集详细记录了球员替换的信息。为了研究的准确性,我们将比赛切割成阵容不变的片段,每次球员替换时便产生新的片段。
3. 球员价值估计与排名
我们分别使用APM(基于岭回归的模型)和CAPM来估计每个球员的价值,并基于这些估计值对球员进行排名。尽管没有球员价值的真实数据作为参考,但我们可以通过比较这些排名与FIFA视频游戏给出的球员评级来评估模型的准确性。FIFA评级由数千名数据审查员(包括球探、教练和季票持有者)的主观评估得出,涵盖了超过18000名球员,具有一定的权威性。
通过计算斯皮尔曼相关性,我们衡量了模型排名与FIFA专家排名之间的一致性。结果显示,CAPM提供的排名与FIFA排名的相关性更高,表明CAPM在评估球员价值方面更为准确。
4. 模型预测能力的评估
接下来,我们将CAPM和APM作为比赛结果的预测模型进行了评估。我们构建了常规和分布变化两种测试集来定量测量这两个模型的能力。分布变化测试集包含与训练集不同分布的测试数据,特别是选择了赛季末的比赛,这些比赛的阵容通常与赛季中使用的典型阵容有所不同。
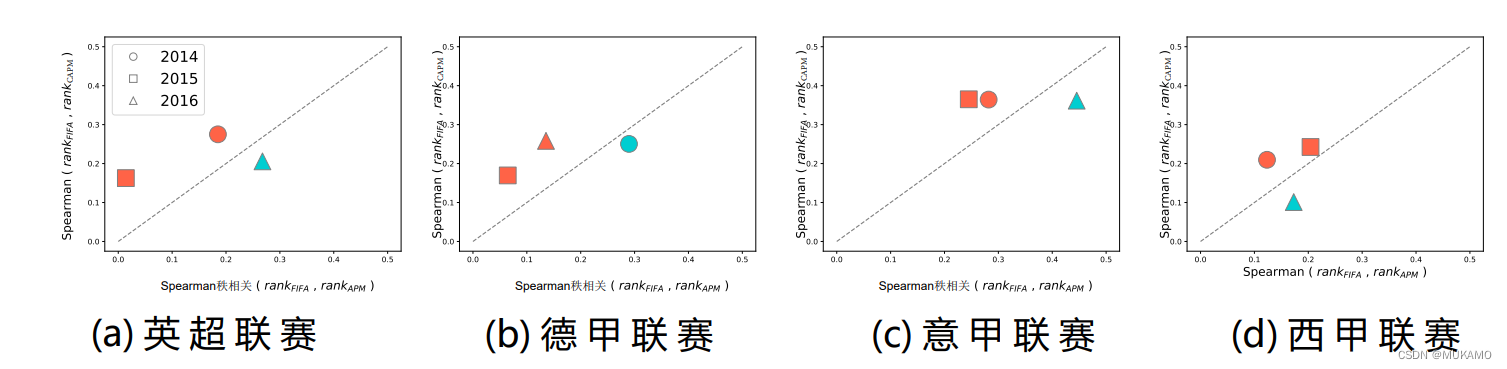
备注:图2:深入比较揭示CAPM在球员排名上的优势
在详尽的数据集分析中,我们观察到,对于三分之二的数据集(包括四大欧洲足球联赛及三个赛季的数据),采用受因果性启发的调整后的表现度量(CAPM)得出的球员排名,与人类专家所认可的FIFA排名表现出了更高的一致性。这一结论通过对比各数据集上FIFA排名(𝑟𝑎𝑛𝑘FIFA)、CAPM(𝑟𝑎𝑛𝑘𝐶 𝐴𝑃𝑀)以及APM(𝑟𝑎𝑛𝑘 𝐴𝑃𝑀)之间的斯皮尔曼相关性得出,其中,超过对角线则代表排名一致性更高。
每个数据点都代表了一个具体的数据集,我们通过分析这些点,可以清晰地看到CAPM在球员排名方面的优势。球员的排名是根据我们推断出的模型得分(𝑟𝑎𝑛𝑘)进行排序的,得分最高的球员自然位于排名的首位。值得注意的是,图中红色标记的数据点表示,在这些数据集上,CAPM的斯皮尔曼相关性高于APM,进一步凸显了CAPM在球员排名评估中的优越性。
在两种测试集上,我们比较了CAPM与APM的性能。具体而言,我们评估了预测结果与观察结果之间的平均绝对误差(MAE),并在所有测试比赛上取平均值。结果显示,CAPM在大多数未变化的测试集和所有变化的测试集中均一致地优于APM。这表明CAPM在提高比赛结果预测准确性的同时,对分布变化具有更强的鲁棒性。
 备注:图3:CAPM与APM模型性能对比
备注:图3:CAPM与APM模型性能对比
通过对比CAPM和APM在预测比赛得分差异时的MAE,我们清晰地展现了两种模型的性能差异。图中,误差条直观地反映了数据的离散程度,而标记点则代表了经过100次独立交叉验证后得出的平均性能。每次验证中,我们都将20%的比赛数据设为测试集。图中水平线0以上的点表明,在这些测试场景下,CAPM模型展现出了更优异的性能。
综上来看,通过在真实足球和篮球数据上的实证检验,我们验证了CAPM在球员价值估计和比赛结果预测方面的有效性及优越性。
5.总结
在讨论CAPM(受因果性启发的表现度量模型)的实用性时,我们意识到其潜力远不止于我们目前所分析的数据集——即球队阵容和比赛结果。在实际应用中,CAPM应当融入更多现实世界的考量,特别是那些已知的混淆变量,如球队的主客场优势、球员的伤病状况等。这些变量对于准确评估球员表现至关重要,因此,将它们纳入CAPM的考量范围,不仅可以减轻模型捕捉这些因素的负担,还能显著提升预测和评估的精度。
此外,CAPM中的泊松分解模型虽然为球队阵容提供了一个基础的建模框架,但在实际应用中,我们完全有理由期待更复杂的模型来捕捉阵容中的复杂性和动态性。通过结合体育领域的专业知识,我们可以进一步优化CAPM,以更准确地反映球员在比赛中的实际贡献。
值得注意的是,我们当前使用的算法尚未充分考虑到数据的时序性,这在篮球等需要分析比赛片段的运动中尤为关键。因此,未来的研究方向之一便是开发能够处理时间序列数据的因果调整算法。这类算法将能够更全面地捕捉球员在比赛中的表现动态,为我们提供更深入的见解和更准确的评估。
综上所述,CAPM作为一种创新的球员评估工具,其潜力和应用前景是广阔的。通过不断地研究、优化和扩展,我们有理由相信CAPM将在未来的体育数据分析和球员评价中发挥更加重要的作用。
参考文献
阿尔贝托·阿巴迪、亚历克西斯·戴蒙德和延斯·海因穆勒。《比较政治学与合成控制方法》。《美国政治科学杂志》,59(4):495-510,2015。
拉杰·阿格拉瓦尔、钱德勒·斯奎尔斯、尼哈·普拉萨德和卡罗琳·乌勒。《Decamfounder:存在隐藏变量时的非线性因果发现》。 arXiv 预印本 arXiv:2102.07921,2021。
约书亚·D·安格里斯特、吉多·W·因本斯和唐纳德·B·鲁宾。《使用工具变量进行因果推断》。《美国统计协会杂志》,91(434):444-455,1996。
BBall Index 团队。《勒布朗:男人、神话、指标?》。访问于 2022 年 2 月 17 日。
C.M.毕夏普。《模式识别与机器学习》。Springer,2006。
大卫·M·布莱伊、阿尔普·屈库克埃尔比尔和乔恩·D·麦考利夫。《变分贝叶斯推理:统计学家的综述》。《美国统计协会杂志》,112(518):859-877,2017。
范·布、索尼娅·许、凯瑟琳·赫勒和亚历山大·沃尔福斯基。《烟雾:游戏成功的社交网络指标》。在《第 22 届国际人工智能与统计会议》,第 2406-2414 页。PMLR,2019。
胡姆贝托·莫雷拉·卡瓦略、何塞·A·莱克韦、苏珊娜·M·吉尔和伊拉娅·比达乌拉扎加-莱托纳。《青少年球员身体尺寸和足球特定功能能力的伯特兰发展》。《运动医学研究》,25(4):421-436,2017。
A.T.切姆吉尔。《非负矩阵分解模型的贝叶斯推理》。《计算智能与神经科学》,2009:785152,2009。
丹尼尔·瑟沃内、亚历克斯·达穆尔、卢克·博恩和柯克·戈德斯伯里。《预测篮球控球结果的多分辨率随机过程模型》。《美国统计协会杂志》,111(514):585-599,2016。
马丁娜·孔蒂斯恰尼、费德里科·巴蒂斯顿和卡特里娜·德巴科。《超图中超边和重叠社区的推断》。《自然通讯》,13(1):7229,2022。
亚历山大·达穆尔。《关于多原因因果推断与未观测到的混杂:反例、不可能和替代方案》。arXiv 预印本 arXiv:1902.10286,2019。
萨米尔·K·德什潘德和谢恩·T·詹森。《估计 NBA 球员对其球队获胜机会的影响》。《体育定量分析杂志》,12(2):51-72,2016。
哈维尔·费尔南德斯、卢克·博恩和丹尼尔·瑟沃内。《足球比赛中瞬间预期价值的细粒度评估框架》。《机器学习》,110(6):1389-1427,2021。
亚历山大·弗拉斯克斯、安德鲁·米勒、卢克·博恩、柯克·戈德斯伯里等。《职业篮球中防守技能的空间结构特征》。《应用统计学年鉴》,9(1):94-121,2015。
本杰明·弗罗特、普雷特姆·N·安迪和玛尔勒斯·H·马塔胡伊斯。《具有一些隐藏变量的鲁棒因果结构学习》。《皇家统计学会杂志 B:统计方法》,81(3):459-487,2019。
罗曼·高约特和莱昂内尔·佩奇。《被表现随机性愚弄:过度奖励运气》。《经济学与统计学评论》,101(4):658-666,2019。
布兰登·贾尔斯、保罗·SR·古德斯、迪伦·R·华纳、戴尔·奎因、彼得·皮尔、卡根·J·达克、布莱恩·道森和丹尼尔·F·古恰尔迪。《心理韧性和行为毅力:概念复制和扩展》。《运动科学与医学杂志》,21(6):640-645,2018。
P·戈帕兰、J·霍夫曼和 D·布莱伊。《基于分层泊松分解的可扩展推荐》。在《人工智能中的不确定性》,第 326-335 页。PMLR,2015。
罗伯特·B·格拉马西、谢恩·T·詹森和马特·T·阿迪。《用正则化逻辑回归估计冰球运动员的贡献》。《体育定量分析杂志》,9(1):97-111,2013。
J·格里默、D·诺克斯和 B·斯图尔特。《简单回归比因子模型调整多原因混杂所需的假设更弱》。arXiv 2007.12702,2020。
米格尔·A·埃尔南和詹姆斯·M·罗宾斯。《因果推断》。CRC 博卡拉顿,FL,2016。
拉斯·马格努斯·赫瓦特姆。《团队运动中个人球员评估的综合综述》。《国际计算机科学在体育中的杂志》,18(1):1-23,2019。
伊尔阿尔迪和 A·巴尔扎莱。《调整后的加/减评分:2007-2008 年的新改进》。http://www.82games.com/ilardi2.htm,2008。
吉多·W·因本斯和唐纳德·B·鲁宾。《统计、社会和生物医学科学中的因果推断》。剑桥大学出版社,2015。
塔拉克·哈拉特、伊恩·G·麦克黑尔和哈维尔·洛佩·佩纳。《足球运动员的加/减评分》。《欧洲运筹学杂志》,283(2):726-736,2020。
曼努布·黑洛基、彼得·卡尔、易松·岳和帕特里克·露西。《使用深度模仿学习进行数据驱动的幽灵》。在 MIT 斯隆体育分析会议,2017。
D·李和 H·塞昂。《通过非负矩阵分解学习物体的部分》。《自然》,401(6755):788-791,1999 年 10 月。
D·莱昂哈特。《职业篮球;小牛队的新数学可能是一个额外的优势》。https://www.nytimes.com/2003/04/27/sports/pro-basketball-mavericks-new-math-may-be-an-added-edge.html,2003。
A·林德伯格。《FIFA 17 的球员评分系统融合了先进的统计数据和主观球探》。http://www.espn.com/soccer/blog/espn-fc-united/68/post/2959703/,2016。
B·麦克唐纳。《NHL 球员的改进调整加/减评分》。在《麻省理工学院斯隆体育分析会议论文集》,第 3 卷,第 2011a 页。
B·麦克唐纳。《NHL 球员的基于回归的调整加/减评分》。《体育定量分析杂志》,7(3),2011b。
弗朗切斯卡·马塔诺、李·理查森、泰勒·波西西尔、科林·A·波利奇和 J·金宁·秦。《足球中的调整加/减评分与 FIFA 评分相结合》。《体育定量分析杂志》,19(1):43-49,2023。
科斯塔·梅德韦多夫斯基。《每日调整和回归卡尔曼优化预测——达科》。访问于 2022 年 2 月 17 日。
王妙、智耿和埃里克·J·特切根·特切根。《使用未测量混杂的代理变量识别因果效应》。《生物计量学》,105(4):987-993,2018。
纳塔尼娅·南达库马尔和谢恩·T·詹森。《冰球分析的历史视角和当前方向》。《统计及其应用年鉴》,2019。
E·奥格本、I·什皮策和 E·特切根·特切根。《对“多原因的祝福”的评论》。《美国统计协会杂志》,114(528):1611-1615,2019。
E·奥格本、I·什皮策和 E·特切根·特切根。《对王和布莱伊的“多原因的祝福”的反例》。arXiv:2020.001,2020。
乔瓦尼·潘图索和拉斯·马格努斯·赫瓦特姆。《以财务为导向的最大化性能:足球转会市场决策的机会约束模型》。《TOP》,29(2):583-611,2021。
朱迪亚·珀尔。《[专家系统中的贝叶斯分析]:评论:图形模型、因果关系和干预》。《统计科学》,8(3):266-269,1993。
朱迪亚·珀尔。《因果图用于实证研究》。《生物计量学》,82(4):669-688,1995。
朱迪亚·珀尔。《因果关系》。剑桥大学出版社,2009。
朱迪亚·珀尔等人。《统计中的因果推断:概述》。《统计调查》,3:96-146,2009。
科斯塔斯·佩雷奇尼斯和韦恩·温斯顿。《用于量化足球中位置价值的 Skellam 回归模型》。《体育定量分析杂志》,2021。
乔纳斯·彼得斯、多明尼克·扬津和伯恩哈德·斯科尔科普夫。《因果推断的要素:基础和学习算法》。麻省理工学院出版社,2017。
詹姆斯·罗宾斯。《一种新的死亡率研究因果推断方法——应用于控制健康工人幸存者效应》。《数学建模》,7(9-12):1393-1512,1986。
D·T·罗森鲍姆。《测量 NBA 球员如何帮助他们的球队获胜》,2004。URL http://www.82games.com/comm30.htm。
尼科洛·鲁杰里、马丁娜·孔蒂斯恰尼、费德里科·巴蒂斯顿和卡特里娜·德巴科。《大图的社区检测》。《科学进展》,9(28):eadg9159,2023。
奥拉夫·德维内斯·塞博和拉斯·马格努斯·赫瓦特姆。《足球运动员对俱乐部财政贡献的建模》。《体育分析杂志》,5(1):23-34,2019。
内森·桑德霍尔茨和卢克·博恩。《具有动态转移概率的马尔可夫决策过程:篮球投篮策略分析》。《应用统计学年鉴》,14(3):1122-1145,2020。
埃德加·桑托斯-费尔南德斯、保罗·吴和克里·L·门格森。《贝叶斯统计与体育:综合综述》。《体育定量分析杂志》,15(4):289-312,2019。
亚伦·谢恩、约翰·佩斯利、大卫·M·布莱伊和汉娜·沃拉赫。《贝叶斯泊松张量分解用于从稀疏双边事件计数中推断多边关系》。在《第 21 届 ACM SIGKDD 国际会议上的知识发现和数据挖掘》,第 1045-1054 页。ACM,2015。
史蒂文·R·舒尔茨和克里斯蒂安-马蒂亚斯·韦尔布罗克。《个体足球运动员表现的加权加/减度量》。《体育分析杂志》,4(2):121-131,2018。
J·西尔。《改进的 NBA 调整+/-使用正则化和样本外测试》。在《2010 年麻省理工学院斯隆体育分析会议论文集》,第 2010 页。
内特·西尔弗。《引入猛禽,我们现代 NBA 的新指标》。https://fivethirtyeight.com/features/introducing-raptor-our-new-metric-for-the-modern-nba/,2019。访问于 2022 年 2 月 17 日。
泰勒·斯纳。《NBA 球员指标比较》。https://dunksandthrees.com/blog/metric-comparison,2020。访问于 2022 年 2 月 17 日。
扎克·特纳和亚历山大·弗拉斯克斯。《篮球运动员和球队表现的建模》。《统计及其应用年鉴》,8:1-23,2021。
A·C·托马斯和 S·L·文图拉。《通往战争的道路》。http://blog.war-on-ice.com/index.html%3Fp=429.html,2015。
AC 托马斯、塞缪尔·L·文图拉、谢恩·T·詹森和斯蒂芬·马。《冰球运动员评分的竞争过程风险函数模型》。《应用统计学年鉴》,页 1497-1524,2013。
卡米尔·托马斯、吉尔伯特·费林厄姆和帕特·维尔斯。《女子大学队部分足球技能的notationnal 分析系统的发展》。《体育教育与运动科学测量》,13(2):108-121,2009。
Y·王和 D·布莱伊。《多原因的祝福》。《美国统计协会杂志》,114(528):1574-1596,2019a。
Y·王和 D·布莱伊。《走向澄清去混杂理论》。arXiv 预印本 arXiv:2003.04948,2020。
Y·王和 D·布莱伊。《多原因的祝福:再答》。《美国统计协会杂志》,114(528):1616-1619,2019b。
德里克·R·亚姆和迈克尔·J·洛佩兹。《失去了什么?国家橄榄球联盟第四节行为的因果估计》。《体育分析杂志》,5(3):153-167,2019。
附录A
附录A. 因子模型:变分推断和模型检查
A.1. 因子模型的变分推断
我们给出了模型参数的详细坐标上升变分推断更新方法(Blei et al., 2017; Gopalan et al., 2015)。该模型的潜在变量是球员因子 θ ℓ \theta_ℓ θℓ和团队因子 q v q_v qv,两者都是 k k k 维的。首先,我们为潜在变量指定了平均场变分族:
q ( θ , z ) = ∏ ℓ , k q ( z ℓ k ∣ α shape ℓ k , γ r team ℓ k ) ∏ v , k q ( z v k ∣ α shape v k , λ r team v k ) , \begin{align*} q(\theta, \mathbf{z}) = \prod_{\ell, k} q(z_{\ell k} | \alpha_{\text{shape}}^{\ell k}, \gamma_{r \text{team}}^{\ell k}) \prod_{v, k} q(z_{vk} | \alpha_{\text{shape}}^{vk}, \lambda_{r \text{team}}^{vk}), \tag{16} \end{align*} q(θ,z)=ℓ,k∏q(zℓk∣αshapeℓk,γrteamℓk)v,k∏q(zvk∣αshapevk,λrteamvk),(16)
其中所有的 q ( ⋅ ) q(\cdot) q(⋅) 都是伽玛分布。在指定了变分族之后,我们拟合变分参数 ?? = {𝛾, 𝜆} 以最小化到后验分布的KL散度,然后使用对应的变分分布 q ( ⋅ ∣ ϕ ^ ) q(\cdot|\mathbf{\hat{\phi}}) q(⋅∣ϕ^) 作为其后验分布的代理。我们使用坐标上升算法来优化参数,具体细节见算法2。最后,通过计算后验分布的几何期望来得到最优参数,如Schein et al. (2015)所述:
z ℓ k = exp ( n Ψ ( α shape ℓ k ) ) ∑ r γ r team ℓ k , z v k = exp ( n Ψ ( α shape v k ) ) ∑ r λ r team v k . \begin{align*} z_{\ell k} &= \frac{\exp\left(n \Psi(\alpha_{\text{shape}}^{\ell k})\right)}{\sum_{r} \gamma_{r \text{team}}^{\ell k}}, \tag{17} \\ z_{vk} &= \frac{\exp\left(n \Psi(\alpha_{\text{shape}}^{vk})\right)}{\sum_{r} \lambda_{r \text{team}}^{vk}}. \tag{18} \end{align*} zℓkzvk=∑rγrteamℓkexp(nΨ(αshapeℓk)),=∑rλrteamvkexp(nΨ(αshapevk)).(17)(18)
这里, Ψ ( ⋅ ) \Psi(\cdot) Ψ(⋅) 是伽玛分布的对数尺度函数(digamma function),它是伽玛分布期望的自然对数的一阶导数。注意,在上面的公式中, n n n 可能是一个与数据大小或迭代次数相关的因子,但在这个上下文中,它的确切意义可能需要根据具体的算法和上下文来确定。
A.2. 选择因子数量 k k k 和模型检查
模型接受因子数量 k k k 作为输入。这可以通过交叉验证来选择,其中我们隐藏数据集的一部分(测试集),即隐藏一部分比赛的阵容。然后,我们在未隐藏的比赛集合(训练集)上训练参数,并在测试集上计算性能。这里,我们使用保留的对数似然性作为性能度量,并使用5折交叉验证来分割训练和测试集。针对多个 k k k 的值重复进行这个实验,选择最佳的 k k k 作为在测试集上平均性能最高的那个。
因子模型的拟合优度通过后验预测检查来进行评估,这是模型检查的一种形式,类似于 Wang 和 Blei (2019a) 中使用的方法。具体来说,我们首先通过随机隐藏数据集中的部分比赛来创建一个阵容保留外数据集 X heldout X_{\text{heldout}} Xheldout。然后,我们创建一个复制的数据集 X rep X_{\text{rep}} Xrep,其中对于每场比赛,我们从后验预测中抽取两个阵容的 m m m 个样本。这可以通过从 p ( X rep i ℓ ∣ z ˉ ℓ , z ˉ team ) p(X_{\text{rep}}^{i\ell} | \bar{z}_{\ell}, \bar{z}_{\text{team}}) p(Xrepiℓ∣zˉℓ,zˉteam) 采样来近似(对于 X ℓ = players X_{\ell} = \text{players} Xℓ=players 使用 z ˉ ℓ \bar{z}_{\ell} zˉℓ,类似地,对于 X ℓ = teams X_{\ell} = \text{teams} Xℓ=teams 使用 z ˉ team \bar{z}_{\text{team}} zˉteam),其中 z ˉ ℓ \bar{z}_{\ell} zˉℓ 和 z ˉ team \bar{z}_{\text{team}} zˉteam 是根据观察到的数据集使用方程(17)和(18)计算出的后验均值。最后,我们分别在复制的数据集和保留外的数据集上计算对数似然性 L ( X rep ) L(X_{\text{rep}}) L(Xrep) 和 L ( X heldout ) L(X_{\text{heldout}}) L(Xheldout)。后验预测 p 值是 P ( L ( X rep ) > L ( X heldout ) ) P(L(X_{\text{rep}}) > L(X_{\text{heldout}})) P(L(Xrep)>L(Xheldout))。这可以通过抽样 n n n 个不同的复制数据集并计算比例 s n \frac{s}{n} ns 来经验估计,其中 s s s 是 L ( X rep ) > L ( X heldout ) L(X_{\text{rep}}) > L(X_{\text{heldout}}) L(Xrep)>L(Xheldout) 的数据集数量。我们得到的 p 值接近 0.5,这表明模型解释复制数据和解释保留外数据的能力相当。
A.3. 因子模型暗示的条件独立性
假设因子模型适合数据,那么该模型可以生成与观测数据在对数似然方面无法区分的复制数据。这大致意味着:
log p ( a 1 : n ) = ∫ ∏ i , ℓ p ( y i , ℓ ∣ θ 1 : n , θ ℓ 1 : n ) p ( θ 1 : n ) p ( θ ℓ 1 : n ) d θ 1 : n d θ ℓ 1 : n , (19) \log p(a_1:n) =\\ \int \prod_{i,\ell} p(y_{i,\ell} | \theta_1:n, \theta_{\ell 1:n}) p(\theta_1:n) p(\theta_{\ell 1:n}) \, d\theta_1:n \, d\theta_{\ell 1:n}, \quad \text{(19)} logp(a1:n)=∫i,ℓ∏p(yi,ℓ∣θ1:n,θℓ1:n)p(θ1:n)p(θℓ1:n)dθ1:ndθℓ1:n,(19)
≈ ∏ i , ℓ p ( y i , ℓ ∣ θ ^ 1 : n ; θ ^ ∗ 1 : n ) (20) \approx \prod_{i,\ell} p(y_{i,\ell} | \hat{\theta}_1:n; \hat{\theta}_*^{1:n}) \quad \text{(20)} ≈i,ℓ∏p(yi,ℓ∣θ^1:n;θ^∗1:n)(20)
其中,第二个等式是由于 θ 1 : n \theta_1:n θ1:n和 θ ℓ 1 : n \theta_{\ell 1:n} θℓ1:n的后验分布接近一个点质量 p ( θ 1 : n , q 1 : n ∣ a 1 : n ) ≈ δ ( θ 1 : n − θ ^ ∗ 1 : n ) δ ( q 1 : n − θ ^ 1 : n ) p(\theta_1:n, q_1:n | a_1:n) \approx \delta(\theta_1:n - \hat{\theta}_*^{1:n}) \delta(q_1:n - \hat{\theta}_1:n) p(θ1:n,q1:n∣a1:n)≈δ(θ1:n−θ^∗1:n)δ(q1:n−θ^1:n)。方程(20)意味着潜在变量 θ ^ 1 : n \hat{\theta}_1:n θ^1:n使得匹配 a 1 : n a_1:n a1:n在条件上是独立的。
A3.1.算法2
因果启发式调整加减法(CAPM)因子模型:CAVI算法
数据
- 阵容 { a i } i \{{a_i}\}_i {ai}i
- 因子数量 K K K
- 超先验 α , β \alpha, \beta α,β
结果
- 参数 θ = [ θ ℓ , k ] \theta = [\theta_{\ell, k}] θ=[θℓ,k]
- q = [ q u ] q = [q_{u}] q=[qu](注意:此处的 q q q在算法描述中并未明确使用,可能是笔误或冗余)
步骤
-
对于所有球员和团队,随机初始化团队参数 λ u s h a p e \lambda_{u}^{shape} λushape, λ u r t e \lambda_{u}^{rte} λurte, γ l s h a p e \gamma_{l}^{shape} γlshape, γ l r t e \gamma_{l}^{rte} γlrte
-
当收敛条件不满足时,执行以下操作:
- 对于每个球员/团队,如果 a i , ℓ > 0 a_{i,\ell} > 0 ai,ℓ>0且 s ℓ ≠ v i s_\ell \neq v_i sℓ=vi,更新多项式
ϕ ℓ , v i ∝ exp ( Ψ ( γ ℓ k s h a p e ) − log γ ℓ k r t e + Ψ ( λ v i k s h a p e ) − log λ v i k r t e ) \phi_{\ell,v_i}\propto \exp \left(\Psi(\gamma_{\ell k}^{shape}) - \log \gamma_{\ell k} ^{rte}+ \Psi(\lambda_{v_ ik}^{shape}) - \log \lambda_{v_i k}^{rte}\right) ϕℓ,vi∝exp(Ψ(γℓkshape)−logγℓkrte+Ψ(λvikshape)−logλvikrte)
对于每个球员更新其后验的形状和速率参数
γ ℓ k s h a p e = α + ∑ i ∣ s l ≠ v i a i , l ϕ l , v k (21) \gamma_{\ell k}^{shape}=\alpha + \sum_{i|s_l\neq v_i} a_i,l\phi{l},vk\text{(21)} γℓkshape=α+i∣sl=vi∑ai,lϕl,vk(21)
γ ℓ k r t e = β + ∑ i ∣ v i = v , l ∣ s l ≠ v λ l k s h a p e λ l k r t e 22 \gamma_{\ell k}^{rte} = \beta + \sum_{i|v_i=v,l|s_l\neq v}\frac{\lambda_{lk}^{shape}}{\lambda_{lk}^{rte}} \text{22} γℓkrte=β+i∣vi=v,l∣sl=v∑λlkrteλlkshape22
对于每个团队更新其后验的形状和速率参数
λ v k s h a p e = α + ∑ i ∣ v i = v , l ∣ s l ≠ v a i , l ϕ l , v k (23) \lambda_{v k}^{shape} = \alpha + \sum_{i|v_i=v,l|s_l\neq v} a_i,l\phi{l},vk\text{(23)} λvkshape=α+i∣vi=v,l∣sl=v∑ai,lϕl,vk(23)
λ v k r t e = β + ∑ i ∣ v i = v , l ∣ s l ≠ v γ l k s h a p e γ l k r t e (24) \lambda_{v k}^{rte} = \beta + \sum_{i|v_i=v,l|s_l\neq v}\frac{\gamma_{lk}^{shape}}{\gamma_{lk}^{rte}} \text{(24)} λvkrte=β+i∣vi=v,l∣sl=v∑γlkrteγlkshape(24)
- 对于每个球员/团队,如果 a i , ℓ > 0 a_{i,\ell} > 0 ai,ℓ>0且 s ℓ ≠ v i s_\ell \neq v_i sℓ=vi,更新多项式
-
结束迭代
-
计算后验估计:
θ ℓ k = exp ( Ψ ( γ ℓ k s h a p e ) γ l k r t e (25) \theta_{\ell k} =\frac{ \exp \left(\Psi(\gamma_{\ell k}^{shape} \right)}{\gamma_{lk}^{rte}}\text{(25)} θℓk=γlkrteexp(Ψ(γℓkshape)(25)
q v k = exp ( Ψ ( λ ℓ k s h a p e ) ) λ l k r t e (26) q_{v k} = \frac{\exp \left( \Psi(\lambda_{\ell k}^{shape} ) \right) }{\lambda_{lk}^{rte}}\quad \text{(26)} qvk=λlkrteexp(Ψ(λℓkshape))(26)
请注意,在算法描述中, θ ℓ k \theta_{\ell k} θℓk和 θ v k \theta_{v k} θvk的更新可能存在问题,因为两个等式都在更新同一个参数,这可能是一个笔误或需要进一步的澄清。此外, q q q参数在算法描述中并未明确使用,可能需要进一步审查或澄清。
附录B.
因果解释
为了理解方程(15)中的估计是如何获得的,我们详细说明了如何使用替代混淆变量和结果模型来进行第3.2节中的因果推断。首先,我们定义一个条件期望,类似于方程(3)但使用了替代混淆变量,
E ℓ ( q , a ^ ℓ , a ∅ ) = E h [ Y ∣ Q ^ = q , A ^ ℓ = a ^ ℓ , A ∅ = a ∅ , U = a ^ ℓ ] . (27) E_{\ell}(q, \hat{a}_{\ell}, a_{\varnothing}) = E_{h}\left[Y \mid \hat{Q} = q, \hat{A}_{\ell} = \hat{a}_{\ell}, A_{\varnothing} = a_{\varnothing}, U = \hat{a}_{\ell}\right]. \tag{27} Eℓ(q,a^ℓ,a∅)=Eh[Y∣Q^=q,A^ℓ=a^ℓ,A∅=a∅,U=a^ℓ].(27)
再次强调,这里的期望是关于其他团队 h h h以及哪些球员(除了 ℓ \ell ℓ和 ∅ \varnothing ∅)在场上这一联合分布的。
接下来,我们用迭代期望来重新表达它,
E ℓ ( q , a ^ ℓ , a ∅ ) = E A − ℓ , V [ E h [ Y ∣ Q ^ = q , A ^ ℓ = a ^ ℓ , A ∅ = a ∅ , U = a ^ ℓ , V , A − ℓ ] ] . (28) E_{\ell}(q, \hat{a}_{\ell}, a_{\varnothing}) =\\ E_{A_{-\ell}, V}\left[E_{h}\left[Y \mid \hat{Q} = q, \hat{A}_{\ell} = \hat{a}_{\ell}, A_{\varnothing} = a_{\varnothing}, U = \hat{a}_{\ell}, V, A_{-\ell}\right]\right]. \tag{28} Eℓ(q,a^ℓ,a∅)=EA−ℓ,V[Eh[Y∣Q^=q,A^ℓ=a^ℓ,A∅=a∅,U=a^ℓ,V,A−ℓ]].(28)
现在,我们使用结果模型。用方程(11)中的线性回归拟合来近似内部期望,
E ^ ℓ ( z ^ , a ℓ , a ∅ ) ≈ β ^ ℓ + β ^ ℓ skill ⋅ z ^ ℓ + E A − ℓ , V [ β ^ − ℓ team ⋅ A − ℓ − β ^ skill ⋅ z ^ ] . (29) \hat{E}_{\ell}(\hat{z}, a_{\ell}, a_{\varnothing}) \approx\\ \hat{\beta}_{\ell} + \hat{\beta}_{\ell}^{\text{skill}} \cdot \hat{z}_{\ell} + E_{A_{-\ell}, V}\left[\hat{\beta}_{-\ell}^{\text{team}} \cdot A_{-\ell} - \hat{\beta}^{\text{skill}} \cdot \hat{z}\right]. \tag{29} E^ℓ(z^,aℓ,a∅)≈β^ℓ+β^ℓskill⋅z^ℓ+EA−ℓ,V[β^−ℓteam⋅A−ℓ−β^skill⋅z^].(29)
请注意,根据定义,0值球员有 a ∅ = 0 a_{\varnothing} = 0 a∅=0。最后,将这个估计代入方程(4)的识别公式中,得到 Λ ℓ ≈ β ^ ℓ \Lambda_{\ell} \approx \hat{\beta}_{\ell} Λℓ≈β^ℓ。
附录 C. 合成数据生成
我们使用具有不同程度混杂因素的因果模型生成了合成数据。我们考虑了足球案例,即每队11名球员,并选择了参数,使得生成的结果类似于真实数据集观察到的结果。
数据的生成分为两步。首先,我们按照第3.3.1节所述生成Gamma分布的未观测混杂因子γ。我们使用从真实数据拟合得到的推断值,以考虑现实值。然后,我们生成380场比赛的合成阵容,就像一个拥有20支球队和大约500名球员的足球联赛。我们使用依赖于未观测混杂因子的分布来抽取每个阵容。
首先,我们考虑如主文中所述的因素模型分布,为每个球员和比赛分配分数:
对于主场球员 ℓ:
如果 γℓ = 🏠
score_i,ℓ = γℓ · home_ability
对于客场球员 ℓ:
如果 γℓ = ⚽
score_i,ℓ = γℓ · away_ability
否则:
score_i,ℓ = 0
然后,我们从所有符合条件的球员列表中无放回地抽取一个包含22名球员的阵容,抽取概率与这些分数成正比。
接下来,我们使用未观测混杂因子γ(如第3.3.1节所述)构建重构的因果,并模拟每场比赛的结果,这些结果也依赖于混杂因子,使用以下公式:
outcome_simulated ~ N(outcome_true, σ^2)outcome_true = Σ Σ_{ℓ=1}^{teams} γ(γℓ = 🏠) × (score_i,ℓ - estimated_score_i,ℓ) × γℓ- Σ Σ_{ℓ=1}^{teams} γ(γℓ = ⚽) × (score_i,ℓ - estimated_score_i,ℓ) × γℓ
其中,σ = 0.1。为了使结果离散化,我们将实数值四舍五入为整数。