创建高性能的索引
覆盖索引
通常大家都会根据查询的WHERE条件来创建合适的索引,不过这只是索引优化的一个方面。设计优秀的索引应该考虑到整个查询,而不单单是WHERE条件部分。索引确实是一种查找数据的高效方式,但是MySQL也可以使用索引来直接获取列的数据,这样就不再需要读取数据行。如果索引的叶子几点钟已经包含要查询的数据,那么还有什么必要再回表查询呢?如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为"覆盖索引"。
覆盖索引是非常有用的工具,能够极大地提高性能。考虑一下如果查询只需要扫描索引而无须回表,会带来多少好处:
- 1.索引条目通常远小于数据行大小,所以如果只需要读取索引,那MySQL就会极大地减少数据访问量。这对缓存的负载非常重要,因为这种情况下相应时间大部分花费在数据拷贝上。覆盖索引对于IO密集型的应用也有帮助,因为索引比数据更小,更容易全部放入内存中(这对于MyISAM尤其正确,因为MyISAM能压缩索引以变得更小)
- 2.因为索引是按照列值顺序存储的(至少在单个页内是如此),所以对于IO密集型的范围查询会比随机从磁盘读取每一行数据的IO要少得多。对于某些存储引擎,例如MyISAM和Percona XtraDB,甚至可以通过OPTIMIZE命令使得索引完全顺序排列,这让简单的范围查询能使用完全的顺序的索引访问
- 3.一些存储引擎如MyISAM在内存中只缓存索引,数据则依赖于操作系统缓存,因此要访问数据需要一次系统调用。这可能会导致严重的性能问题,尤其是那些系统调用占了数据访问中的最大开销的场景
- 4.由于InnoDB的聚簇索引,覆盖索引对InnoDB表特别有用。InnoDB的二级索引在叶子节点中保存了行的主键值,所以如果二级主键能够覆盖查询,则可以避免对主键索引的二次查询
在所有这些场景中,在索引中满足查询的成本一般要比查询行要小得多。不是所有类型的索引都可以成为覆盖索引。覆盖索引必须要存储索引列的值,而哈希索引、空间索引和全文索引等都不存储索引列的值,所以MySQL只能使用B-Tree索引做覆盖索引。另外,不同的存储引擎实现覆盖索引的方式也不同,而且不是所有的引擎都支持覆盖索引(如Memory存储引擎就不支持覆盖索引),当发起一个被索引覆盖的查询(也叫做索引覆盖查询时),在EXPLAIN的Extra列可以看到"Using index"的信息(很容易把Extra列的"Using index"和type列的"index"搞混淆。其实这两者完全不同,type列和覆盖索引毫无关系:它只是表示这个查询访问数据的方式,或者说是MySQL查找行的方式,MySQL手册中称之为连接方式(join type))。例如,表sakila.inventory有一个多列索引(store_id,film_id).MySQL如果只需访问这两列,就可以使用这个索引做索引覆盖,如下所示
mysql> EXPLAIN SELECT store_id,film_id FROM sakila.inventory\G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: inventorypartitions: NULLtype: index
possible_keys: NULLkey: idx_store_id_film_idkey_len: 3ref: NULLrows: 4581filtered: 100.00Extra: Using index
1 row in set, 1 warning (0.00 sec)
索引覆盖查询还有很多陷阱可能会导致无法实现优化。MySQL查询优化器会在执行查询前判断是否有一个索引能进行覆盖。假设索引覆盖了WHERE条件中的字段,但是不是整个查询涉及的字段。如果条件为假(false),MySQL5.5和更早的版本也总是会回表获取数据行,尽管并不需要这一行且最终会被过滤掉。
来看看为什么会发生这样的情况,以及如何重写查询以解决该问题。从下面的查询开始
mysql> EXPLAIN SELECT * FROM products WHERE actor='SEAN CARREY' AND title LIKE '%APOLLO%'\G
*************************** 1. row ***************************
id:1
select_type:SIMPLE
table:products
type:ref
possible_keys:ACTOR,IDX_PROD_ACTOR
key:ACTOR
key_len:52
ref:const
rows:10
Extra:Using where
这里索引无法覆盖该查询,有两个原因:
- 1.没有任何索引能覆盖这个查询。因为查询从表中选择了所有的列,而没有任何索引覆盖了所有的列。不过理论上MySQL还有一个捷径可以利用:WHERE条件中的列是有索引可以覆盖的,因此MySQL可以使用该索引找到对应的actor并检查title是否匹配,过滤之后再读取需要的数据行
- 2.MySQL不能再索引中执行LIKE操作。这是底层存储引擎API的限制,MySQL5.5和更早的版本中只允许在索引中做简单比较操作(例如等于、不等于以及大于)。MySQL能在索引中做最左前缀匹配的LIKE比较,因为该操作可以转换为简单的比较操作,但是如果是通配符开头的LIKE查询,存储引擎就无法做比较匹配。这种情况下,MySQL服务器只能提取数据行的值而不是索引值来做比较
也有办法可以解决上面说的两个问题,需要重写查询并巧妙地涉及索引。先将索引扩展至覆盖三个数据列(artist,title,prod_id),然后按如下方式重写查询
mysql>EXPLAIN SELECT
*
FROM
products
JOIN ( SELECT prod_id FROM products WHERE actor = 'SEAN CARREY' AND title LIKE '%APOLLO%' ) AS t1 ON (
t1.prod_id = products.prod_id)
*************************** 1. row ***************************
id:1
select_type:PRIMARY
table:<derived2>
....omitted...
*************************** 2. row ***************************
id:1
select_type:PRIMARY
table:products
...omitted...
*************************** 3. row ***************************
id:2
select_type:DERIVED
table:products
type:ref
possable_keys:ACTOR,ACTOR_2,IDX_PROD_ACTOR
key:ACTOR_2
key_len:52
ref:
rows:11
Extra:Using where, Using index
我们把这种方式叫作延迟关联(deferred join),因为延迟了对列的访问。在查询的第一阶段MySQL使用覆盖索引,在FROM子句中的子查询中找到匹配的prod_id,然后根据这些prod_id值在外层查询匹配获取需要的所有列值。虽然无法使用索引覆盖整个查询,但总算比完全无法利用索引覆盖的好。
这样优化的效果取决于WHERE条件匹配返回的行数。假设这个products表有100万行,我们来看一下上面两个初选在三个不同的数据集上的表现,每个数据集都包含100万行:
- 1.第一个数据集,Sean Carrey出演了30 000部作品,其中有20 000部的标题中包含了Apollo
- 2.第二个数据集,Sean Carrey出演了30 000部作品,其中40 部的标题中包含了Apollo
- 3.第三个数据集,Sean Carrey出演了50部作品,其中10部的标题中包含了Apollo
使用上面的三种数据集来测试两种不同的查询,得到的结果如表所示:
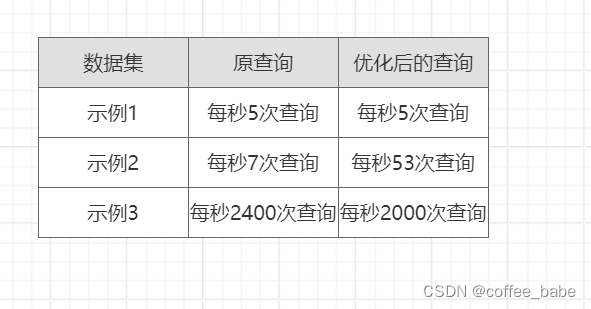
下面是对结果的分析:
- 1.在示例1中,查询返回了一个很大的结果集,因此看不到优化的效果。大部分时间都花在读取和发送数据上了
- 2.在示例2中,经过索引过滤,尤其是第二个条件过滤后只返回了很少的结果集,优化的效果非常明显:在这个数据集上性能提高了5倍,优化后的查询的效率主要得益于只需要读取40行完整数据行,而不是原查询中需要的30 000行
- 3.在示例3中,显示了子查询效率反而下降的情况。因为索引过滤时符合第一个条件的结果集已经很小,所以子查询带来的成本反而比从表中直接提取完整行要高。
在大多数存储引擎中,覆盖索引只能覆盖那些只访问索引中部分列的查询。不过,可以更进一步优化InnoDB。回想一下,InnoDB的二级索引的叶子节点都包含了主键的只,这意味着InnoDB的二级索引可以有效地利用这些"额外"的主键列来覆盖查询。例如,actor使用InnoDB存储引擎,并在last_name字段有二级索引,虽然该索引的列不包括主键actor_id,但也能够用于对actor_id做覆盖查询:
mysql> EXPLAIN SELECT actor_id,last_name FROM sakila.actor WHERE last_name= 'HOPPER'\G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: actorpartitions: NULLtype: ref
possible_keys: idx_actor_last_namekey: idx_actor_last_namekey_len: 182ref: constrows: 2filtered: 100.00Extra: Using index
1 row in set, 1 warning (0.00 sec)
未来MySQL版本的改进(索引下推)
上面提到的很多限制都是由于存储引擎API涉及所导致的,目前的API设计不允许MySQL将过滤条件传到存储引擎层。如果MySQL在后续版本能够做到这一点,则可以把查询发送到数据上,而不是像现在这样只能把数据从存储引擎拉到服务器层,再根据查询条件过滤。MySQL将这个功能称之为索引下推(Index Condition Pushdown)