Author: Dongsheng Li, Kaitao Song, Kan Ren, Siyu Yuan, Weiming Lu, Wenqi Zhang, Xu Tan, Yongliang Shen, Yueting Zhuang
Institution: 复旦大学(Fudan University), 微软亚洲研究院(Microsoft Research Asia), 浙江大学(Zhejiang University)
Summary: LLM 带动了任务自动化的发展,它将用户指令描述的复杂任务分解为子任务,并调用外部工具来执行它们,在 Agent 中发挥着核心作用。但是目前还缺少系统化、标准化的基准来催 LLM 任务自动化的发展。任务自动化可以分为三个关键阶段:任务分解、工具调用和参数预测。为了生成高质量的评估数据集,作者引入了工具图的概念来表示用户意图中分解的任务,并采用反向指令方法来模拟用户指令和注释。作者还提出了 TASKEVAL,从不同方面评估 LLM 的能力,包括任务分解、工具调用和参数预测。
Score /5: ⭐️⭐️⭐️⭐️
Type: Paper
链接: https://arxiv.org/abs/2311.18760
代码是否开源: 开源
代码链接: https://github.com/microsoft/JARVIS/tree/main/taskbench
数据集是否开源: 开源
数据集链接: https://github.com/microsoft/JARVIS/tree/main/taskbench
读前先问
带着问题读论文,边读边回答。
- 大方向的任务是什么?Task
LLMs 自动化任务执行评估。
- 这个方向有什么问题?是什么类型的问题?Type
缺少系统化、标准化的基准。
- 为什么会有这个问题?Why
这个方向还刚兴起不久。
- 作者是怎么解决这个问题的?How
提出了一个评估基准 TaskBench。
- 怎么验证解决方案是否有效?
首先是分阶段评估,依次评估了不同模型在任务分解、工具调用和参数预测的能力。
然后进行了人类评估,评估 TASKBENCH 跟人类专家的相关性。
论文精读
引言
LLM 带动了自动化任务的发展,许多研究人员试图更深入地研究LLM,以实现更智能的自动化任务。但是,目前这一领域的一个关键挑战是缺乏系统化、标准化的基准,来全面评估 LLM 在自动化任务方面的能力。
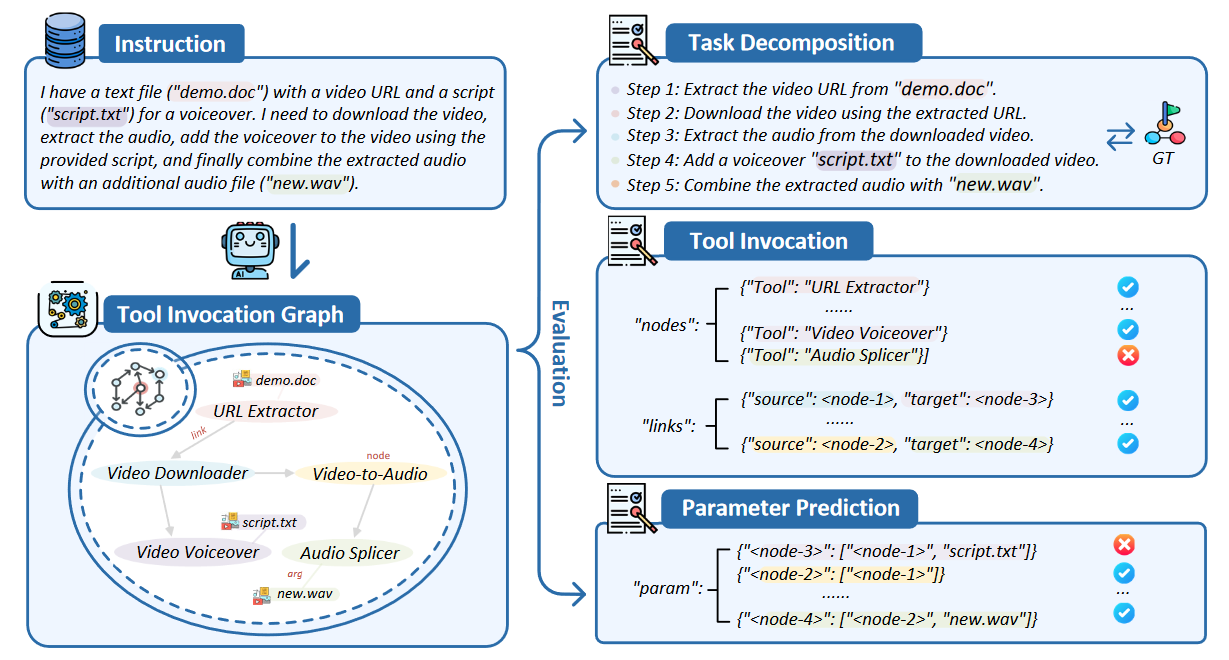
基于 LLM 的自动化任务和 TASKBENCH 基准。自动化任务指的是基于 LLM 的 Agent 使用任务分解、工具调用和参数预测来自主完成任务。评估过程如下:1)给定用户请求,LLM 进行任务分解并预测工具调用图; 2)TaskBench 根据分解的子任务来评估 LLM 的任务分解能力; 3)对于预测的工具调用图,TaskBench 评估工具节点、边和参数的准确性。
与传统的 NLP 任务相比,实现自动化任务的过程通常需要多个阶段(例如任务分解、工具调用和工具参数预测)。特别是,自动化任务的实施需要更广泛地考虑现实世界的场景,因此用户指令可能很复杂,可能由具有复杂任务依赖性的多个子任务组成。有时,其任务范围可能需要超越语言的高级功能,因此需要利用外部工具。
为了更好地实现自动化任务,需要 LLM 派生多个任务元素(例如分解的任务、调用的工具和工具参数),这些也迫使我们设计出更先进的评估指标来评估 LLM 在这些方面的表现。
为此,作者提出了 TASKBENCH 来衡量 LLM 在自动化任务的能力。如上图所示,与直接模拟用户请求相比,LLM 通常需要解析任务以实现自动化,并且这些解析后的任务(即分解的任务、调用的工具和参数)更容易收集和构建。因此,作者提出一个简单的想法:是否可以根据预期的解析任务合成用户指令?
作者首先提出工具图(Tool Graph, TG)的概念,它收集了各种工具来解决特定任务。TG 中的每两个工具如果具有依赖关系,就可以建立连接。整个工具连接的结构可以看作是一个图。为了模拟用户指令,可以从 TG 中随机采样一个子图来表示用户指令中的预期任务列表,然后应用反向指令策略来生成最终的用户指令。在生成过程中,作者提出了三种不同的采样架构以实现更好的可控性,分别是节点、链接和有向无环图(DAG)。此外,还附加了自我批评机制,通过检查数据集的一致性来进一步完善数据集的数据质量。为了保证 TASKBENCH 的多样性,数据生成应用于三个领域(例如,Hugging Face、多媒体和日常生活)。
作者进一步提出了一个评估系统,称为 TASKEVAL,它包含一系列指标来提供客观评估,以衡量 LLM 在任务分解、工具调用和预测工具参数方面的能力。此外,作者还进行了人工评估,以证明 TASKEVAL 的评估与人工评估的正相关性。
TASKBENCH 数据集
前提
自动化任务旨在完成现实场景中复杂的用户指令,在这个设定下,用户指令可以包含多个子任务,并且每个子任务的执行可以通过调用工具来完成。此外,这些子任务之间还可能存在一些时间或资源的依赖。因此,作者认为每个用户指令都可以表示为具有图结构的工具组合。因此,作者引入了工具图的概念,可以视为以工具及其依赖性为中心的结构化表示。
设工具为 t,并将 TG 表示为 G = {T, D},其中 T = {t1, t2,…, tn} 表示工具的集合,D 是 {(ta, tb)} 的集合,这意味着工具 ta 对工具 tb 表现出依赖关系。
数据集构建
为了保证生成的用户指令能够覆盖预期的任务和依赖关系,作者采用反向指令策略来生成模拟用户指令,包括三个步骤:1)首先收集一个工具存储库,并使用工具及其依赖项的集合构建工具图G; 2)然后从G中采样子图,得到指定的结构; 3)基于采样的工具子图,使用LLM通过反向指令生成模拟用户指令。
- 工具图构建
构建工具图需要从不同来源收集许多独立工具。当将不同的工具组合在一起时,工具之间的依赖关系可能是多种多样的,包括资源依赖关系、时间依赖关系、环境依赖关系等等。这篇文章中主要研究其中两个:资源依赖性和时间依赖性。对于资源依赖性,如果工具ta的输入类型与工具tb的输出类型能够匹配,则意味着两个工具可以建立连接。对于时间依赖性,作者设计了突出时间依赖性的工具图,允许链接任意两个工具来说明它们的顺序。
作者选择了三个场景来构建 benchmark 的数据集:
HuggingFace: 提供了各种各样的AI模型,涵盖跨语言、视觉、音频、视频等的海量任务。 Hugging Face 定义的每个任务都可以被视为解决特定任务的工具,每个工具都确定了其输入和输出的类型。因此,如果工具 ta 和 tb 有连接,则 ta 的输入类型应与 tb 的输出类型匹配。作者构建了一个 Hugging Face 的工具图,包括 23 个工具和 225 条边。

多媒体:提供更多以用户为中心的工具,如文件下载器、视频编辑器等。工具连接策略与 Hugging Face 相同。作者在多媒体工具上构建一个具有 40 个节点和 449 条边的工具图。

日常生活:一些日常生活服务,包括网络搜索、购物等。这些日常生活API也可以被视为特定任务的工具,这些 API 之间的依赖关系类型主要是暂时的。因此,两个日常生活API连接起来就有了先后顺序。作者构建一个具有 40 个节点和 1,560 条边的工具图。
- 工具图采样
按照HuggingGPT的设置,将TG的子结构分为三种类型:节点、链和有向无环图(DAG)。每种类型都体现了工具调用的特定模式:
节点:代表独立的工具调用,适合解决仅需要单个工具的简单任务。
链:链对应于顺序工具调用,其中工具需要逐步执行才能完成任务。
DAG:DAG 描述了更复杂的工具调用。一个工具可能依赖于多个先前的工具或影响多个后续的工具。
通过从这三个子结构中采样子图,可以为用户指令模拟各种有效的工具调用模式。我们将 G 中的工具子图表示为 Gs = {Ts, Ds},其中 Ts = {ts1, ts2,… , tsk},其中 k < n 且 Ds = {(tsa, tsb)},使得 tsa 和 tsb 属于 Ts。工具图的采样可以描述为:Sample(G, mode, size) → Gs。其中 mode 指定采样模式(例如 Nodes、Chains、DAG),size 表示工具的数量(这里我们将其范围设置为 {1, 2, …, 10})。这些因素分别决定了用户指令中工具子图的拓扑性质和大小。
- 反向指令
接下来,基于采样的子图Gs,作者使用LLM来合成用户指令,这个过程称为“BACK-INSTRUCT”,它可以被视为一个数据引擎,将采样的工具转换为用户指令。
具体来说,给定一个采样子图 Gs,作者制定以下 BACKINSTRUCT 过程,使 LLM 能够生成相应的指令:BackInstruct1(Gs = (Ts, Ds)) → Instruction。
采样的子图只能提供工具调用骨架的信息,缺乏工具执行的关键参数。因此,基于等式中生成的Instruction,我们鼓励LLM填充工具子图的参数并生成最终的工具调用图以及相应的任务分解步骤:BackInstruct2(Gs = (Ts, Ds), Instruction) → { Task Steps, Tool Invocation Graph}。
之后,作者还引入了自我批评机制来检查和过滤生成的指令以保证质量。作者提供两种方式:基于 LLM 的和基于规则的。前者旨在使用LLM来检查生成的数据和采样的工具子图之间的对齐情况。而后者使用简单的规则来确定创建的数据中的工具图与采样的工具图之间的对齐情况。
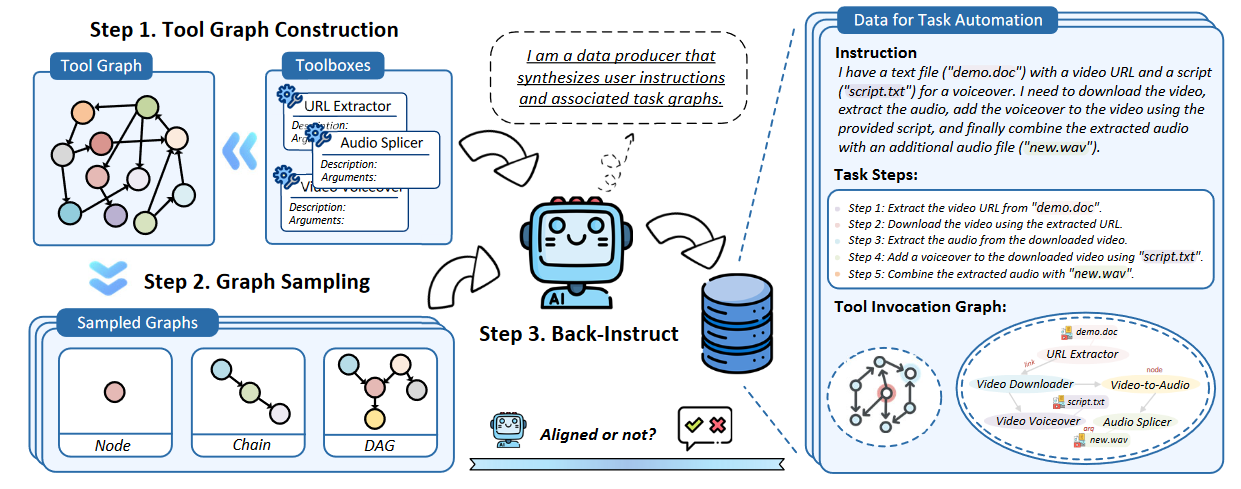
TASKBENCH 的构建:最初,根据工具的依赖性(资源或时间依赖性)在工具之间创建连接,将工具箱转换为工具图。随后,从工具图中采样不同的子图,这些子图可能是单节点、链或有向无环图。利用采样的工具子图(包含工具及其相互关系),通过“反向指令” LLM 来逆向地制作用户指令、任务步骤和工具调用图。此外,作者还引入了批评家来评估生成的工具调用图与采样的工具子图的一致性。
数据集统计
基于上述步骤,我们跨三个域构建了TASKBENCH,它使用GPT-4作为数据引擎。不同模式(即Node、Chain、DAG)的比例设置为3:7:8进行采样,不同工具的数量比例设置为{0.1,0.2,0.3,0.2,0.1,0.05,0.025 , 0.025, 0.025}。
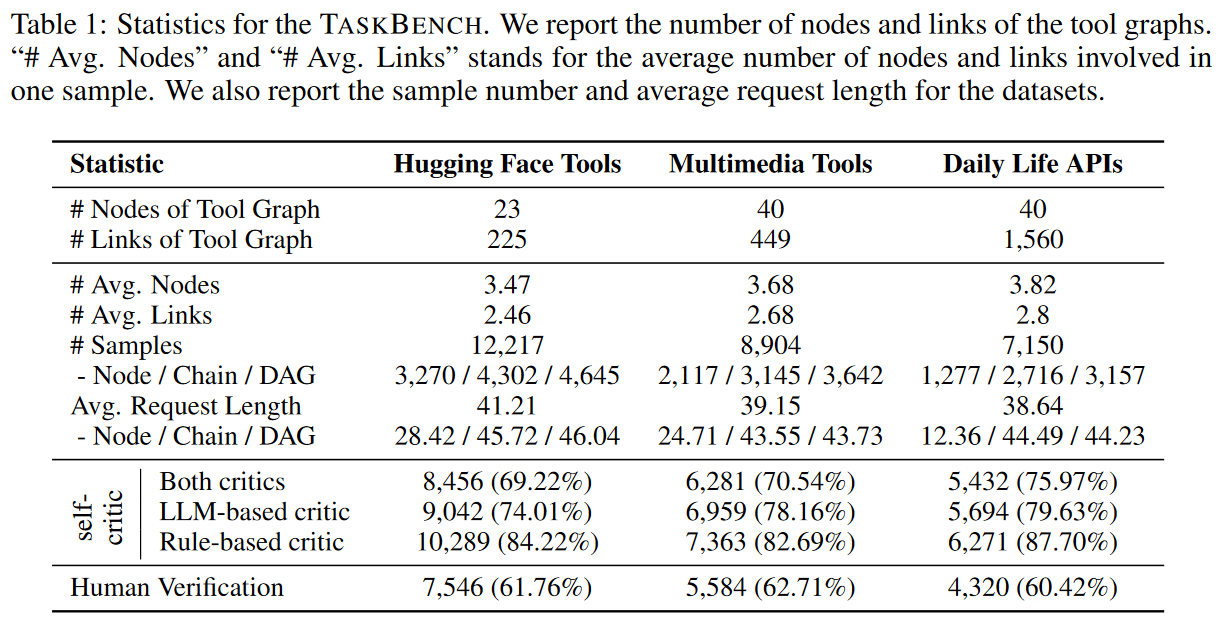
表 1 报告了跨三个域的工具图和数据集的统计信息。值得注意的是,批评家在提高数据质量方面发挥着至关重要的作用。基于规则和基于LLM的批评家分别平均过滤掉了15.13%和22.73%的样本。此外,作者还邀请人类专家对数据进行修改和过滤,最后分别获得了三个数据集的 61.76%、62.71% 和 60.42% 的对齐样本。
数据集质量评估
为了证明 TASKBENCH 数据集的质量,作者根据生成的样本进行了深入的人类评估。
为了评估 Back-Instruct 构建的数据集的质量,作者设计了三个指标。两个衡量指令的质量,一个评估工具调用图:
- 指令指标:
- 自然性:该指标衡量指令的合理性,包括工具之间依赖关系的共性及其与现实世界需求的一致性。
- 复杂性:该指标评估指令的复杂性,考虑任务深度、涉及工具的数量以及这些工具之间的关系等因素。
- 工具调用图的度量:
- 对齐:建立在可行性度量的基础上,衡量工具调用图与指令的对齐程度,即工具调用图是否可以有效地处理用户的命令。
每个指标的评分范围为 1 到 5。
为了进行公平比较,作者选择两个额外的基线来比较 Back-Instruct:
- Back-Instruct(作者提出的):对工具子图进行采样,然后反向生成指令并进一步细化工具调用图。
- Back-Instruct w/o Edge:与 Back-Instruct 相比,坐着从采样的工具子图中消除了边,仅保留工具节点信息。
- Self-Instruct:基于手动标记的演示和带有描述的所有工具,直接使用 GPT-4 自主选择工具,然后生成带有工具调用图的指令。
在人工评估过程中,作者从 TASKBENCH 中随机选择了 50 个样本,并邀请了三位领域专家来评估这些样本的质量。为了确保评估的公平公正,所有样本都将进行匿名处理。作者提供规范样本供这些专家在标注时校准他们的标准,并计算所有专家评分的平均分作为最终结果。
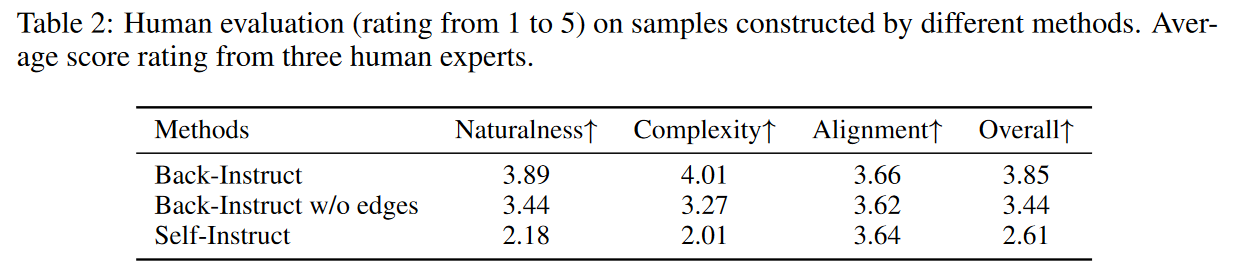
所有方法(Self-Instruct 或 Back-Instruct)都可以保证对齐。然而 Back-Instruct 在自然性和复杂性方面得分最高。作者将这些优势归因于采样工具子图中的实际资源或时间依赖性,能够在复杂场景(例如,多工具利用)中生成更自然的指令。
TASKEVAL
TASKEVAL 包含一系列多维度衡量 LLM 的评估指标,包括任务分解、工具调用和参数预测。基于构建的数据集和标准推理过程,作者设计了相关指标来评估任务自动化的三个阶段(即任务分解、工具调用和参数预测)。
任务分解
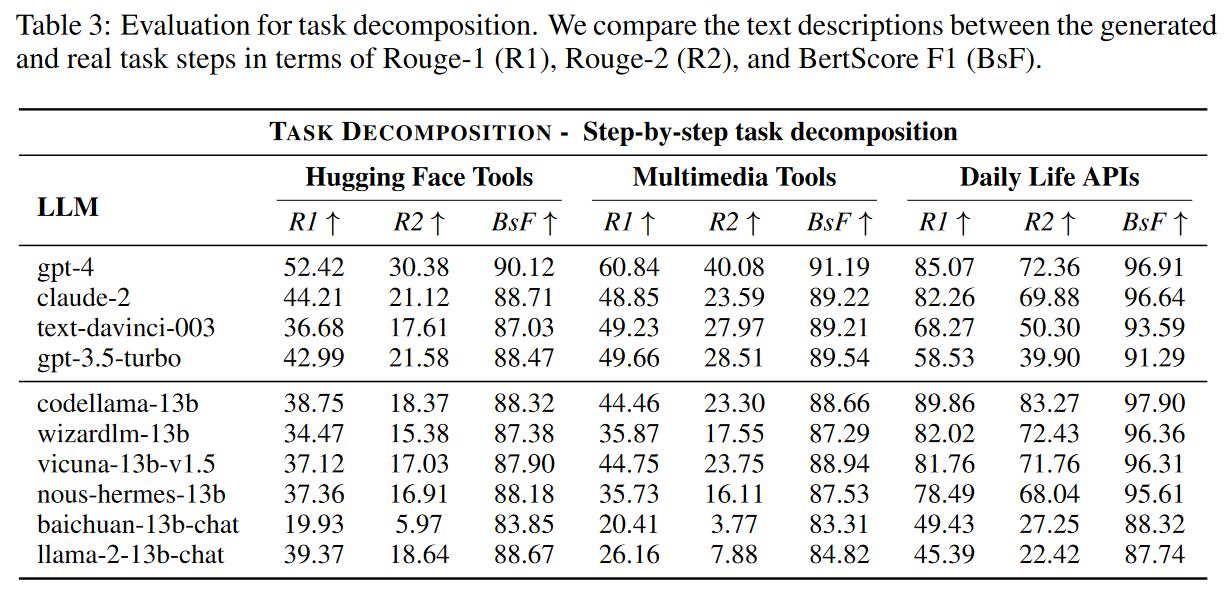
任务分解是任务自动化的关键组成部分,通过将用户指令分解为一系列可执行子任务,Agent 可以更有效地实现用户意图。在任务分解过程中,每个步骤都会生成文本描述。在这里,作者使用三个主观指标来衡量分析子任务的质量:Rouge-1 (R1)、Rouge-2 (R2) 和 BertScore F1 (BsF)。
任务分解的评估结果如下表所示。
工具调用
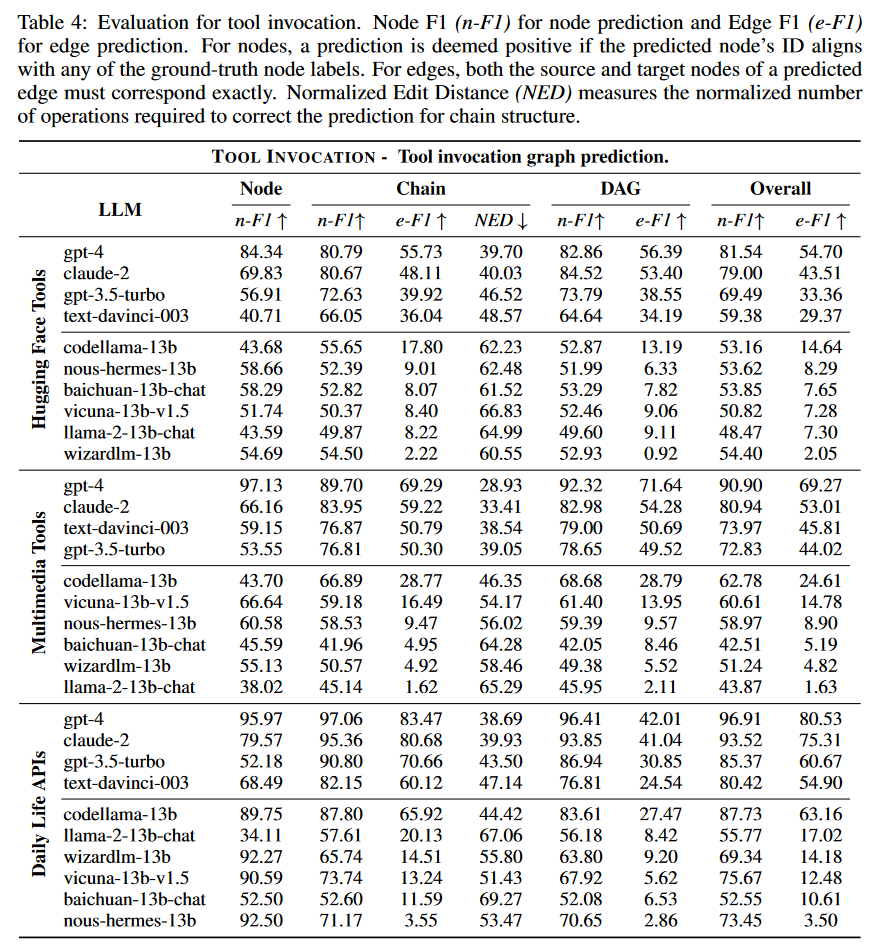
工具调用图可以被视为用户指令中任务步骤的具体表示,为每个步骤指定适当的工具。为了有效地协调外部工具,工具调用图应提供以下信息: 1)工具之间的依赖关系,以保证可执行子任务的顺序; 2) 工具所需的参数。在这里,作者首先评估预测的图结构,以衡量 LLM 的能力。
在工具调用图中,作者将节点表示为工具,将边表示为两个工具之间的依赖关系,因此可以通过评估节点和边来衡量 LLM 工具调用的能力。作者制定了两个不同的指标:用于节点预测的 Node F1 (n-F1) 和用于边缘预测的 Edge F1 (e-F1),还引入了链结构的归一化编辑距离(NED)指标,量化了纠正预测所需的调整。
工具调用的评估结果如下表所示。
参数预测
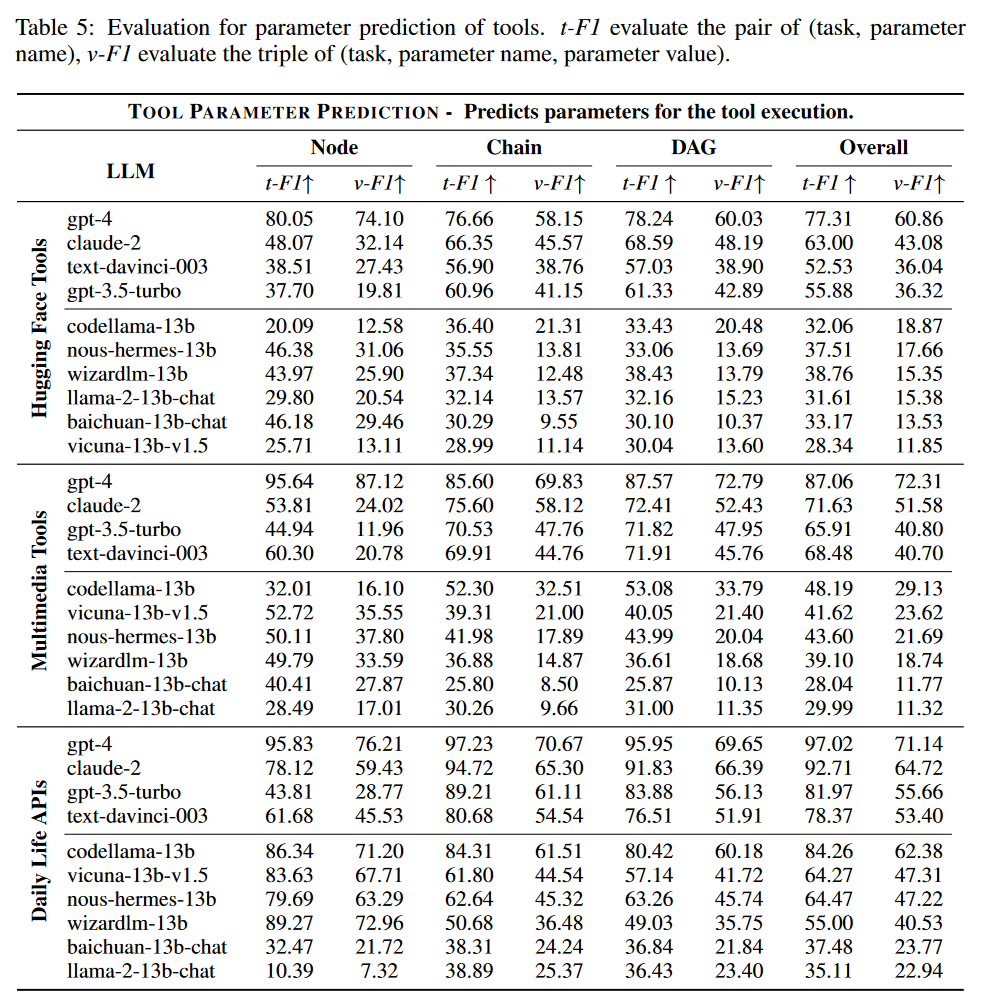
工具参数预测的评估分为两部分:
- 参数名称 F1 (t-F1),用于评估 LLM 预测工具参数的能力;
- 参数名称和值 F1 (v-F1),用于测量参数及其值。
参数的精确预测可以决定工具的成功执行,并且参数和值的精确预测可以保证工具调用的正确性。
参数预测的评估结果如下表所示。
人类评估
为了确保 TASKBENCH 评估的可靠性,作者进一步研究其与人类评估的一致性。作者从构建的指令中随机选择 50 个样本,然后强制评估的 LLM 生成响应,之后比较成对的 LLM,并根据工具调用图的可执行性和问题解决效率总结排名。为了说明 TASKBENCH 和人类评估之间的一致性,作者使用了两个指标:Kendall 的 τ 和 Spearman 的 ρ。
人类评估的结果如下表所示。
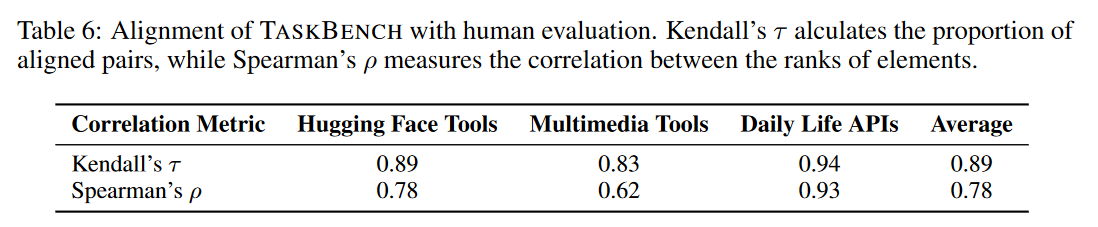
Kendall 的 τ 和 Spearman 的 ρ 的平均值分别为 0.89 和 0.78,这表明人类评估与TASKBENCH 之间存在正相关。
分析
- 影响任务自动化性能的因素
- 推理能力:LLM 解决复杂问题和有效推理的能力差异很大,这对于自动化任务至关重要。
- 指令跟踪:通过指令跟踪微调过的模型在自动化任务方面优于基线 Llama-2-13b 模型。
- LLM 在执行任务自动化方面的本质差异
- 代码预训练:具有更多代码预训练的模型(Code-Llama)在自动化任务方面优于其他开源LLM。
- 对齐技术:具有人类对齐(例如 RLHF)的模型(例如 GPT 系列模型)表现出比开源 LLM 更强的自动化任务能力。