目录
摘要
Abstract
SAM2
模型框架
图像编码器
记忆机制
提示编码器和掩码解码器
实验
代码
总结
摘要
SAM2是基于Meta公司推出的Segment Anything Model升级而来的先进分割模型。它在SAM的基础上,通过引入记忆注意力模块和优化图像编码器等改进,显著提升了图像和视频分割的精度与效率。SAM2解决了SAM在小物体分割、多物体重叠场景处理以及视频分割能力上的不足,能够实时处理视频流并实现细粒度分割。其采用Hiera作为骨干网络,结合Prompt驱动机制,生成高质量的分割掩码。SAM2在大规模数据集上表现出色,构建了目前最大的高清视频分割数据集SA-V,并在医学图像分割等任务中超越了现有先进模型,如在BTCV数据集上达到92.30%的Dice相似系数,超越了nnUNet。此外,SAM2在伪装物体检测、显著性物体检测等多个任务上也展现了卓越性能,标志着实时对象分割技术的重大突破。
Abstract
SAM2 is an advanced segmentation model based on the Segment Anything Model released by Meta. Building on SAM, it significantly enhances the accuracy and efficiency of image and video segmentation through improvements such as the introduction of a memory attention module and optimization of the image encoder. SAM2 addresses SAM's limitations in small object segmentation, handling scenes with multiple overlapping objects, and video segmentation capabilities. It can process video streams in real-time and achieve fine-grained segmentation. Using Hiera as the backbone network and combining a Prompt-driven mechanism, SAM2 generates high-quality segmentation masks. It performs well on large-scale datasets, constructing the largest high-definition video segmentation dataset SA-V to date. In tasks such as medical image segmentation, SAM2 surpasses existing state-of-the-art models, achieving a Dice similarity coefficient of 92.30% on the BTCV dataset, outperforming nnUNet. Additionally, SAM2 demonstrates excellent performance in multiple tasks, including camouflage object detection and salient object detection, marking a significant breakthrough in real-time object segmentation technology.
SAM2
Demo:https://sam2.metademolab.com
项目地址:https://github.com/facebookresearch/sam2
Website:https://ai.meta.com/sam2
SAM2的核心创新在于其将图像视为"单帧视频"的统一视角,通过扩展原始SAM的架构,引入了专门针对视频处理的记忆机制和流式处理能力。这种设计理念使得SAM2不仅保留了SAM在图像分割上的所有优势,还新增了对视频时序信息的理解与利用能力。模型采用基于Transformer的架构,配合高效的记忆注意力模块,能够实时处理视频流并保持对目标对象的连续跟踪,即使面对遮挡、变形等复杂情况也能表现出色。
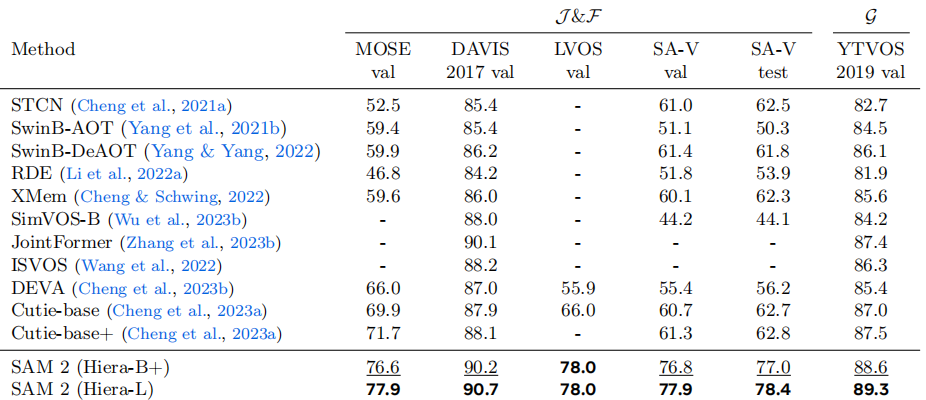
SAM2的零样本泛化能力是其另一项突出特性。与需要针对特定类别进行训练的传统分割模型不同,SAM2能够准确分割训练数据中从未出现过的对象类型,这种能力使其可以应用于几乎无限的现实场景而无需额外调整。测试表明,SAM2在17个零样本视频数据集上的交互式分割性能显著优于先前方法,且所需人机交互减少了约3倍。同时,其处理速度达到每秒约44帧,比前代SAM快6倍,真正实现了实时处理能力。
从技术指标来看,SAM2在多个基准测试中创造了新纪录。在DAVIS 2017和YouTube-VOS等主流视频分割基准上,SAM2的J&F分数分别达到82.5和81.2,大幅领先之前的最先进模型。在交互式分割任务中(DAVIS交互数据集),SAM2仅需1.54次点击即可达到90%的精度(AUC为0.872),显示出极高的交互效率。这些性能提升源于Meta团队专门为SAM2开发的大规模SA-V数据集,该数据集包含约51,000个视频和超过600,000个掩码注释,是此前最大视频分割数据集规模的4.5倍。
模型框架
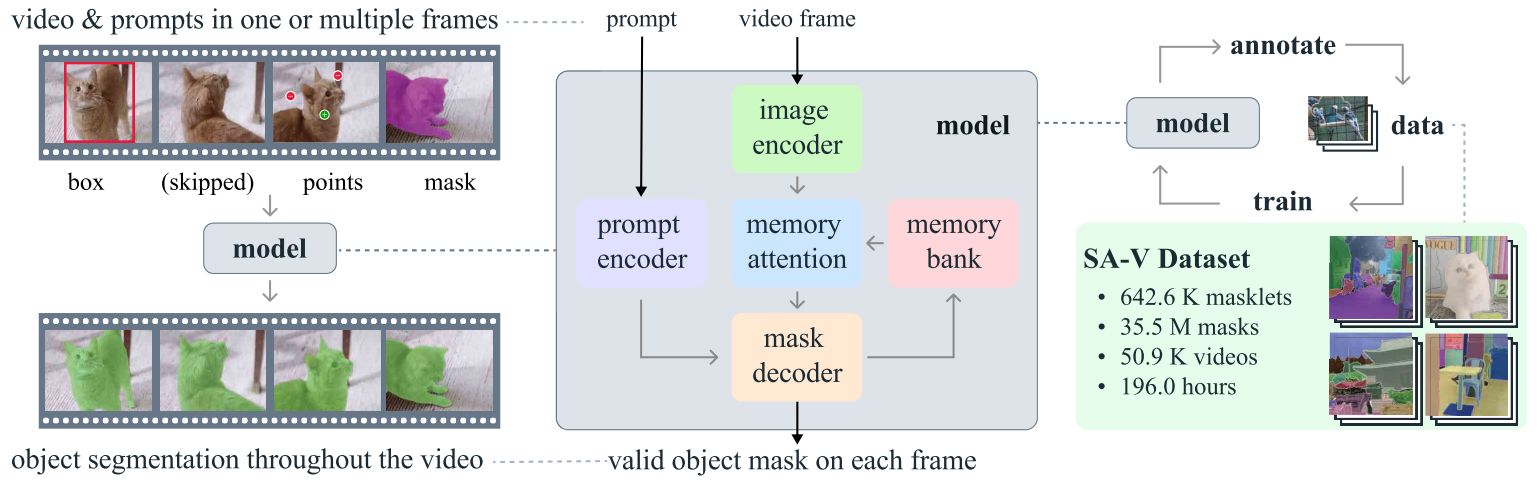
图像编码器
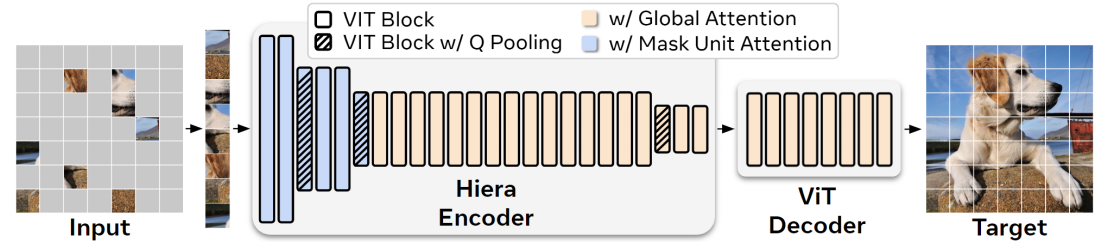
图像编码器在整个交互过程中仅运行一次,其作用是为每一帧提供无条件的特征嵌入。SAM2使用了一个预训练的 MAE Hiera 图像编码器,该编码器是分层的,允许在解码过程中使用多尺度特征。
记忆机制
记忆注意力的作用是将当前帧的特征基于过去的帧特征和预测结果以及任何新的提示进行条件化处理。作者堆叠了 L 个 Transformer 块,第一个块以当前帧的图像编码作为输入。每个块执行自注意力操作,随后进行交叉注意力操作,关注(有提示/无提示)帧的记忆和目标指针,这些内容存储在记忆库中,最后通过一个 MLP。我们使用标准的注意力操作来进行自注意力和交叉注意力,从而能够受益于最近在高效注意力内核方面的进展。
提示编码器和掩码解码器
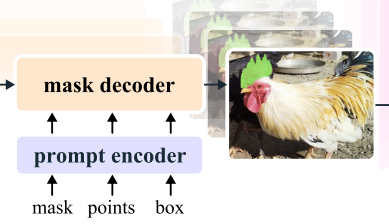
提示编码器与 SAM的完全相同,可以通过点、框或掩码来定义给定帧中对象的范围。稀疏提示通过位置编码与每种提示类型的学习嵌入相加来表示,而掩码则通过卷积嵌入并与帧嵌入相加,SAM2 解码器设计在很大程度上遵循了 SAM 的方法。
堆叠了“双向”Transformer 块,用于更新提示和帧嵌入。与 SAM 一样,对于模糊提示可能存在多个兼容的目标掩码,同时预测多个掩码。这种设计对于确保模型输出有效掩码至关重要。在视频中,模糊性可能会跨越多个视频帧,因此模型会在每一帧上预测多个掩码。如果没有后续提示来解决这种模糊性,模型只会传播当前帧中预测的具有最高 IoU 的掩码。与 SAM 不同,SAM 在给定正向提示的情况下总是有一个有效的对象可以分割,而在 PVS 任务中,某些帧上可能根本不存在有效的对象。为了支持这种新的输出模式,增加了一个额外的头部,用于预测感兴趣的对象是否出现在当前帧上。另一个新特性是从分层图像编码器添加跳跃连接,以引入用于掩码解码的高分辨率嵌入。
实验
对比SAM模型:

与先前工作对比:
代码
SAM2.py
import loggingimport numpy as np
import torch
import torch.distributed
from sam2.modeling.sam2_base import SAM2Base
from sam2.modeling.sam2_utils import (get_1d_sine_pe,get_next_point,sample_box_points,select_closest_cond_frames,
)from sam2.utils.misc import concat_pointsfrom training.utils.data_utils import BatchedVideoDatapointclass SAM2Train(SAM2Base):def __init__(self,image_encoder,memory_attention=None,memory_encoder=None,prob_to_use_pt_input_for_train=0.0,prob_to_use_pt_input_for_eval=0.0,prob_to_use_box_input_for_train=0.0,prob_to_use_box_input_for_eval=0.0,# if it is greater than 1, we interactive point sampling in the 1st frame and other randomly selected framesnum_frames_to_correct_for_train=1, # default: only iteratively sample on first framenum_frames_to_correct_for_eval=1, # default: only iteratively sample on first framerand_frames_to_correct_for_train=False,rand_frames_to_correct_for_eval=False,# how many frames to use as initial conditioning frames (for both point input and mask input; the first frame is always used as an initial conditioning frame)# - if `rand_init_cond_frames` below is True, we randomly sample 1~num_init_cond_frames initial conditioning frames# - otherwise we sample a fixed number of num_init_cond_frames initial conditioning frames# note: for point input, we sample correction points on all such initial conditioning frames, and we require that `num_frames_to_correct` >= `num_init_cond_frames`;# these are initial conditioning frames because as we track the video, more conditioning frames might be added# when a frame receives correction clicks under point input if `add_all_frames_to_correct_as_cond=True`num_init_cond_frames_for_train=1, # default: only use the first frame as initial conditioning framenum_init_cond_frames_for_eval=1, # default: only use the first frame as initial conditioning framerand_init_cond_frames_for_train=True, # default: random 1~num_init_cond_frames_for_train cond frames (to be constent w/ previous TA data loader)rand_init_cond_frames_for_eval=False,# if `add_all_frames_to_correct_as_cond` is True, we also append to the conditioning frame list any frame that receives a later correction click# if `add_all_frames_to_correct_as_cond` is False, we conditioning frame list to only use those initial conditioning framesadd_all_frames_to_correct_as_cond=False,# how many additional correction points to sample (on each frame selected to be corrected)# note that the first frame receives an initial input click (in addition to any correction clicks)num_correction_pt_per_frame=7,# method for point sampling during evaluation# "uniform" (sample uniformly from error region) or "center" (use the point with the largest distance to error region boundary)# default to "center" to be consistent with evaluation in the SAM paperpt_sampling_for_eval="center",# During training, we optionally allow sampling the correction points from GT regions# instead of the prediction error regions with a small probability. This might allow the# model to overfit less to the error regions in training datasetsprob_to_sample_from_gt_for_train=0.0,use_act_ckpt_iterative_pt_sampling=False,# whether to forward image features per frame (as it's being tracked) during evaluation, instead of forwarding image features# of all frames at once. This avoids backbone OOM errors on very long videos in evaluation, but could be slightly slower.forward_backbone_per_frame_for_eval=False,freeze_image_encoder=False,**kwargs,):super().__init__(image_encoder, memory_attention, memory_encoder, **kwargs)self.use_act_ckpt_iterative_pt_sampling = use_act_ckpt_iterative_pt_samplingself.forward_backbone_per_frame_for_eval = forward_backbone_per_frame_for_eval# Point sampler and conditioning framesself.prob_to_use_pt_input_for_train = prob_to_use_pt_input_for_trainself.prob_to_use_box_input_for_train = prob_to_use_box_input_for_trainself.prob_to_use_pt_input_for_eval = prob_to_use_pt_input_for_evalself.prob_to_use_box_input_for_eval = prob_to_use_box_input_for_evalif prob_to_use_pt_input_for_train > 0 or prob_to_use_pt_input_for_eval > 0:logging.info(f"Training with points (sampled from masks) as inputs with p={prob_to_use_pt_input_for_train}")assert num_frames_to_correct_for_train >= num_init_cond_frames_for_trainassert num_frames_to_correct_for_eval >= num_init_cond_frames_for_evalself.num_frames_to_correct_for_train = num_frames_to_correct_for_trainself.num_frames_to_correct_for_eval = num_frames_to_correct_for_evalself.rand_frames_to_correct_for_train = rand_frames_to_correct_for_trainself.rand_frames_to_correct_for_eval = rand_frames_to_correct_for_eval# Initial multi-conditioning framesself.num_init_cond_frames_for_train = num_init_cond_frames_for_trainself.num_init_cond_frames_for_eval = num_init_cond_frames_for_evalself.rand_init_cond_frames_for_train = rand_init_cond_frames_for_trainself.rand_init_cond_frames_for_eval = rand_init_cond_frames_for_evalself.add_all_frames_to_correct_as_cond = add_all_frames_to_correct_as_condself.num_correction_pt_per_frame = num_correction_pt_per_frameself.pt_sampling_for_eval = pt_sampling_for_evalself.prob_to_sample_from_gt_for_train = prob_to_sample_from_gt_for_train# A random number generator with a fixed initial seed across GPUsself.rng = np.random.default_rng(seed=42)if freeze_image_encoder:for p in self.image_encoder.parameters():p.requires_grad = Falsedef forward(self, input: BatchedVideoDatapoint):if self.training or not self.forward_backbone_per_frame_for_eval:# precompute image features on all frames before trackingbackbone_out = self.forward_image(input.flat_img_batch)else:# defer image feature computation on a frame until it's being trackedbackbone_out = {"backbone_fpn": None, "vision_pos_enc": None}backbone_out = self.prepare_prompt_inputs(backbone_out, input)previous_stages_out = self.forward_tracking(backbone_out, input)return previous_stages_outdef _prepare_backbone_features_per_frame(self, img_batch, img_ids):"""Compute the image backbone features on the fly for the given img_ids."""# Only forward backbone on unique image ids to avoid repetitive computation# (if `img_ids` has only one element, it's already unique so we skip this step).if img_ids.numel() > 1:unique_img_ids, inv_ids = torch.unique(img_ids, return_inverse=True)else:unique_img_ids, inv_ids = img_ids, None# Compute the image features on those unique image idsimage = img_batch[unique_img_ids]backbone_out = self.forward_image(image)(_,vision_feats,vision_pos_embeds,feat_sizes,) = self._prepare_backbone_features(backbone_out)# Inverse-map image features for `unique_img_ids` to the final image features# for the original input `img_ids`.if inv_ids is not None:image = image[inv_ids]vision_feats = [x[:, inv_ids] for x in vision_feats]vision_pos_embeds = [x[:, inv_ids] for x in vision_pos_embeds]return image, vision_feats, vision_pos_embeds, feat_sizesdef prepare_prompt_inputs(self, backbone_out, input, start_frame_idx=0):"""Prepare input mask, point or box prompts. Optionally, we allow tracking froma custom `start_frame_idx` to the end of the video (for evaluation purposes)."""# Load the ground-truth masks on all frames (so that we can later# sample correction points from them)# gt_masks_per_frame = {# stage_id: targets.segments.unsqueeze(1) # [B, 1, H_im, W_im]# for stage_id, targets in enumerate(input.find_targets)# }gt_masks_per_frame = {stage_id: masks.unsqueeze(1) # [B, 1, H_im, W_im]for stage_id, masks in enumerate(input.masks)}# gt_masks_per_frame = input.masks.unsqueeze(2) # [T,B,1,H_im,W_im] keep everything in tensor formbackbone_out["gt_masks_per_frame"] = gt_masks_per_framenum_frames = input.num_framesbackbone_out["num_frames"] = num_frames# Randomly decide whether to use point inputs or mask inputsif self.training:prob_to_use_pt_input = self.prob_to_use_pt_input_for_trainprob_to_use_box_input = self.prob_to_use_box_input_for_trainnum_frames_to_correct = self.num_frames_to_correct_for_trainrand_frames_to_correct = self.rand_frames_to_correct_for_trainnum_init_cond_frames = self.num_init_cond_frames_for_trainrand_init_cond_frames = self.rand_init_cond_frames_for_trainelse:prob_to_use_pt_input = self.prob_to_use_pt_input_for_evalprob_to_use_box_input = self.prob_to_use_box_input_for_evalnum_frames_to_correct = self.num_frames_to_correct_for_evalrand_frames_to_correct = self.rand_frames_to_correct_for_evalnum_init_cond_frames = self.num_init_cond_frames_for_evalrand_init_cond_frames = self.rand_init_cond_frames_for_evalif num_frames == 1:# here we handle a special case for mixing video + SAM on image training,# where we force using point input for the SAM task on static imagesprob_to_use_pt_input = 1.0num_frames_to_correct = 1num_init_cond_frames = 1assert num_init_cond_frames >= 1# (here `self.rng.random()` returns value in range 0.0 <= X < 1.0)use_pt_input = self.rng.random() < prob_to_use_pt_inputif rand_init_cond_frames and num_init_cond_frames > 1:# randomly select 1 to `num_init_cond_frames` frames as initial conditioning framesnum_init_cond_frames = self.rng.integers(1, num_init_cond_frames, endpoint=True)if (use_pt_inputand rand_frames_to_correctand num_frames_to_correct > num_init_cond_frames):# randomly select `num_init_cond_frames` to `num_frames_to_correct` frames to sample# correction clicks (only for the case of point input)num_frames_to_correct = self.rng.integers(num_init_cond_frames, num_frames_to_correct, endpoint=True)backbone_out["use_pt_input"] = use_pt_input# Sample initial conditioning framesif num_init_cond_frames == 1:init_cond_frames = [start_frame_idx] # starting frameelse:# starting frame + randomly selected remaining frames (without replacement)init_cond_frames = [start_frame_idx] + self.rng.choice(range(start_frame_idx + 1, num_frames),num_init_cond_frames - 1,replace=False,).tolist()backbone_out["init_cond_frames"] = init_cond_framesbackbone_out["frames_not_in_init_cond"] = [t for t in range(start_frame_idx, num_frames) if t not in init_cond_frames]# Prepare mask or point inputs on initial conditioning framesbackbone_out["mask_inputs_per_frame"] = {} # {frame_idx: <input_masks>}backbone_out["point_inputs_per_frame"] = {} # {frame_idx: <input_points>}for t in init_cond_frames:if not use_pt_input:backbone_out["mask_inputs_per_frame"][t] = gt_masks_per_frame[t]else:# During training # P(box) = prob_to_use_pt_input * prob_to_use_box_inputuse_box_input = self.rng.random() < prob_to_use_box_inputif use_box_input:points, labels = sample_box_points(gt_masks_per_frame[t],)else:# (here we only sample **one initial point** on initial conditioning frames from the# ground-truth mask; we may sample more correction points on the fly)points, labels = get_next_point(gt_masks=gt_masks_per_frame[t],pred_masks=None,method=("uniform" if self.training else self.pt_sampling_for_eval),)point_inputs = {"point_coords": points, "point_labels": labels}backbone_out["point_inputs_per_frame"][t] = point_inputs# Sample frames where we will add correction clicks on the fly# based on the error between prediction and ground-truth masksif not use_pt_input:# no correction points will be sampled when using mask inputsframes_to_add_correction_pt = []elif num_frames_to_correct == num_init_cond_frames:frames_to_add_correction_pt = init_cond_frameselse:assert num_frames_to_correct > num_init_cond_frames# initial cond frame + randomly selected remaining frames (without replacement)extra_num = num_frames_to_correct - num_init_cond_framesframes_to_add_correction_pt = (init_cond_frames+ self.rng.choice(backbone_out["frames_not_in_init_cond"], extra_num, replace=False).tolist())backbone_out["frames_to_add_correction_pt"] = frames_to_add_correction_ptreturn backbone_outdef forward_tracking(self, backbone_out, input: BatchedVideoDatapoint, return_dict=False):"""Forward video tracking on each frame (and sample correction clicks)."""img_feats_already_computed = backbone_out["backbone_fpn"] is not Noneif img_feats_already_computed:# Prepare the backbone features# - vision_feats and vision_pos_embeds are in (HW)BC format(_,vision_feats,vision_pos_embeds,feat_sizes,) = self._prepare_backbone_features(backbone_out)# Starting the stage loopnum_frames = backbone_out["num_frames"]init_cond_frames = backbone_out["init_cond_frames"]frames_to_add_correction_pt = backbone_out["frames_to_add_correction_pt"]# first process all the initial conditioning frames to encode them as memory,# and then conditioning on them to track the remaining framesprocessing_order = init_cond_frames + backbone_out["frames_not_in_init_cond"]output_dict = {"cond_frame_outputs": {}, # dict containing {frame_idx: <out>}"non_cond_frame_outputs": {}, # dict containing {frame_idx: <out>}}for stage_id in processing_order:# Get the image features for the current frames# img_ids = input.find_inputs[stage_id].img_idsimg_ids = input.flat_obj_to_img_idx[stage_id]if img_feats_already_computed:# Retrieve image features according to img_ids (if they are already computed).current_vision_feats = [x[:, img_ids] for x in vision_feats]current_vision_pos_embeds = [x[:, img_ids] for x in vision_pos_embeds]else:# Otherwise, compute the image features on the fly for the given img_ids# (this might be used for evaluation on long videos to avoid backbone OOM).(_,current_vision_feats,current_vision_pos_embeds,feat_sizes,) = self._prepare_backbone_features_per_frame(input.flat_img_batch, img_ids)# Get output masks based on this frame's prompts and previous memorycurrent_out = self.track_step(frame_idx=stage_id,is_init_cond_frame=stage_id in init_cond_frames,current_vision_feats=current_vision_feats,current_vision_pos_embeds=current_vision_pos_embeds,feat_sizes=feat_sizes,point_inputs=backbone_out["point_inputs_per_frame"].get(stage_id, None),mask_inputs=backbone_out["mask_inputs_per_frame"].get(stage_id, None),gt_masks=backbone_out["gt_masks_per_frame"].get(stage_id, None),frames_to_add_correction_pt=frames_to_add_correction_pt,output_dict=output_dict,num_frames=num_frames,)# Append the output, depending on whether it's a conditioning frameadd_output_as_cond_frame = stage_id in init_cond_frames or (self.add_all_frames_to_correct_as_condand stage_id in frames_to_add_correction_pt)if add_output_as_cond_frame:output_dict["cond_frame_outputs"][stage_id] = current_outelse:output_dict["non_cond_frame_outputs"][stage_id] = current_outif return_dict:return output_dict# turn `output_dict` into a list for loss functionall_frame_outputs = {}all_frame_outputs.update(output_dict["cond_frame_outputs"])all_frame_outputs.update(output_dict["non_cond_frame_outputs"])all_frame_outputs = [all_frame_outputs[t] for t in range(num_frames)]# Make DDP happy with activation checkpointing by removing unused keysall_frame_outputs = [{k: v for k, v in d.items() if k != "obj_ptr"} for d in all_frame_outputs]return all_frame_outputsdef track_step(self,frame_idx,is_init_cond_frame,current_vision_feats,current_vision_pos_embeds,feat_sizes,point_inputs,mask_inputs,output_dict,num_frames,track_in_reverse=False, # tracking in reverse time order (for demo usage)run_mem_encoder=True, # Whether to run the memory encoder on the predicted masks.prev_sam_mask_logits=None, # The previously predicted SAM mask logits.frames_to_add_correction_pt=None,gt_masks=None,):if frames_to_add_correction_pt is None:frames_to_add_correction_pt = []current_out, sam_outputs, high_res_features, pix_feat = self._track_step(frame_idx,is_init_cond_frame,current_vision_feats,current_vision_pos_embeds,feat_sizes,point_inputs,mask_inputs,output_dict,num_frames,track_in_reverse,prev_sam_mask_logits,)(low_res_multimasks,high_res_multimasks,ious,low_res_masks,high_res_masks,obj_ptr,object_score_logits,) = sam_outputscurrent_out["multistep_pred_masks"] = low_res_maskscurrent_out["multistep_pred_masks_high_res"] = high_res_maskscurrent_out["multistep_pred_multimasks"] = [low_res_multimasks]current_out["multistep_pred_multimasks_high_res"] = [high_res_multimasks]current_out["multistep_pred_ious"] = [ious]current_out["multistep_point_inputs"] = [point_inputs]current_out["multistep_object_score_logits"] = [object_score_logits]# Optionally, sample correction points iteratively to correct the maskif frame_idx in frames_to_add_correction_pt:point_inputs, final_sam_outputs = self._iter_correct_pt_sampling(is_init_cond_frame,point_inputs,gt_masks,high_res_features,pix_feat,low_res_multimasks,high_res_multimasks,ious,low_res_masks,high_res_masks,object_score_logits,current_out,)(_,_,_,low_res_masks,high_res_masks,obj_ptr,object_score_logits,) = final_sam_outputs# Use the final prediction (after all correction steps for output and eval)current_out["pred_masks"] = low_res_maskscurrent_out["pred_masks_high_res"] = high_res_maskscurrent_out["obj_ptr"] = obj_ptr# Finally run the memory encoder on the predicted mask to encode# it into a new memory feature (that can be used in future frames)self._encode_memory_in_output(current_vision_feats,feat_sizes,point_inputs,run_mem_encoder,high_res_masks,object_score_logits,current_out,)return current_outdef _iter_correct_pt_sampling(self,is_init_cond_frame,point_inputs,gt_masks,high_res_features,pix_feat_with_mem,low_res_multimasks,high_res_multimasks,ious,low_res_masks,high_res_masks,object_score_logits,current_out,):assert gt_masks is not Noneall_pred_masks = [low_res_masks]all_pred_high_res_masks = [high_res_masks]all_pred_multimasks = [low_res_multimasks]all_pred_high_res_multimasks = [high_res_multimasks]all_pred_ious = [ious]all_point_inputs = [point_inputs]all_object_score_logits = [object_score_logits]for _ in range(self.num_correction_pt_per_frame):# sample a new point from the error between prediction and ground-truth# (with a small probability, directly sample from GT masks instead of errors)if self.training and self.prob_to_sample_from_gt_for_train > 0:sample_from_gt = (self.rng.random() < self.prob_to_sample_from_gt_for_train)else:sample_from_gt = False# if `pred_for_new_pt` is None, only GT masks will be used for point samplingpred_for_new_pt = None if sample_from_gt else (high_res_masks > 0)new_points, new_labels = get_next_point(gt_masks=gt_masks,pred_masks=pred_for_new_pt,method="uniform" if self.training else self.pt_sampling_for_eval,)point_inputs = concat_points(point_inputs, new_points, new_labels)# Feed the mask logits of the previous SAM outputs in the next SAM decoder step.# For tracking, this means that when the user adds a correction click, we also feed# the tracking output mask logits along with the click as input to the SAM decoder.mask_inputs = low_res_masksmultimask_output = self._use_multimask(is_init_cond_frame, point_inputs)if self.use_act_ckpt_iterative_pt_sampling and not multimask_output:sam_outputs = torch.utils.checkpoint.checkpoint(self._forward_sam_heads,backbone_features=pix_feat_with_mem,point_inputs=point_inputs,mask_inputs=mask_inputs,high_res_features=high_res_features,multimask_output=multimask_output,use_reentrant=False,)else:sam_outputs = self._forward_sam_heads(backbone_features=pix_feat_with_mem,point_inputs=point_inputs,mask_inputs=mask_inputs,high_res_features=high_res_features,multimask_output=multimask_output,)(low_res_multimasks,high_res_multimasks,ious,low_res_masks,high_res_masks,_,object_score_logits,) = sam_outputsall_pred_masks.append(low_res_masks)all_pred_high_res_masks.append(high_res_masks)all_pred_multimasks.append(low_res_multimasks)all_pred_high_res_multimasks.append(high_res_multimasks)all_pred_ious.append(ious)all_point_inputs.append(point_inputs)all_object_score_logits.append(object_score_logits)# Concatenate the masks along channel (to compute losses on all of them,# using `MultiStepIteractiveMasks`)current_out["multistep_pred_masks"] = torch.cat(all_pred_masks, dim=1)current_out["multistep_pred_masks_high_res"] = torch.cat(all_pred_high_res_masks, dim=1)current_out["multistep_pred_multimasks"] = all_pred_multimaskscurrent_out["multistep_pred_multimasks_high_res"] = all_pred_high_res_multimaskscurrent_out["multistep_pred_ious"] = all_pred_iouscurrent_out["multistep_point_inputs"] = all_point_inputscurrent_out["multistep_object_score_logits"] = all_object_score_logitsreturn point_inputs, sam_outputs输入图片:

分割结果:

总结
SAM2 作为一种先进的图像分割模型,成功解决了通用图像分割、实时性与效率、多模态输入以及零样本学习等关键问题。它在多个标准数据集上取得了接近或超越现有最先进方法的性能,同时保持了较高的推理速度,展现出强大的泛化能力和灵活性。SAM2 的多模态输入支持和零样本学习能力减少了对大量标注数据的依赖,降低了数据准备的成本和时间。其成功为未来的研究和开发提供了重要启发,特别是在进一步提升多模态输入的结合效果、优化实时性和效率、探索跨模态学习以及拓展零样本学习的场景等方面。