
自AlexNet赢得2012年ImageNet竞赛以来,每个新的获胜架构通常都会增加更多层数以降低错误率。一段时间内,增加层数确实有效,但随着网络深度的增加,深度学习中一个常见的问题——梯度消失或梯度爆炸开始出现。
梯度消失问题会导致梯度值变得非常小,几乎趋近于零;而梯度爆炸问题则会导致梯度值变得非常大。这两种情况都会增加训练难度,并导致错误率上升,随着层数的增加,模型在训练和测试数据上的性能都会受到影响。
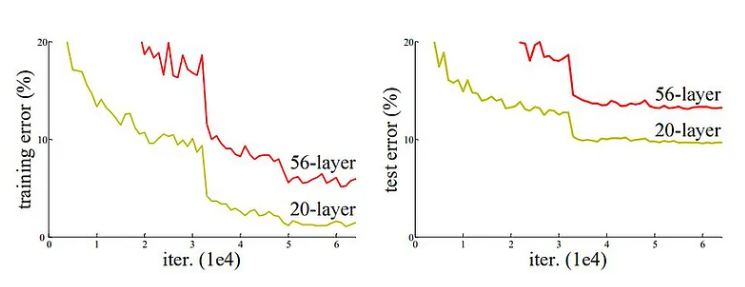
从下图可以看出,20层CNN 架构在训练和测试数据集上的表现均优于56层CNN架构。作者进一步分析了错误率,认为错误率是由梯度消失/爆炸引起的。
2015 年,微软研究院提出了一个划时代的网络结构——ResNet(残差网络),并提出了一个非常简单却极其有效的思想:
“如果某些层学不到什么有用特征,那不如直接跳过它们。”
一、ResNet简介
ResNet 的突破源于其使用了跳跃(或残差)连接,解决了长期存在的梯度消失和爆炸问题。这些连接使 ResNet 成为第一个成功训练超过 100 层的模型的网络,并在 ImageNet 和COCO目标检测任务上取得了最佳效果。
-
深度网络的挑战
在 ResNet 之前,非常深的神经网络面临两大挑战:
-
梯度消失:随着网络深度增加,反向传播过程中的梯度值趋于减小。这会减慢前几层的学习速度,从而限制网络在深度增加时学习有用特征的能力。
-
梯度爆炸:有时,在非常深的网络中,梯度会呈指数增长,导致数值不稳定,权重变得太大,从而导致模型失败。
这些问题导致深层模型的性能不如浅层模型。这种现象被称为“退化”,意味着添加更多层并不一定能提高准确率,反而往往会导致性能下降。
二、ResNet的创新点:跳过(残差)连接
跳过连接(或残差连接)的工作原理是,将较早层(例如,第 n-1 层)的输出直接添加到较晚层(例如,第 n+1 层)的输出。添加后,对结果应用 ReLU 激活函数。这意味着第 n 层实际上被“跳过”,从而使信息更容易在网络中流动。
这里 f(Xn-1) 表示卷积层 (n-1) 的输出被传递给 ReLU 激活函数
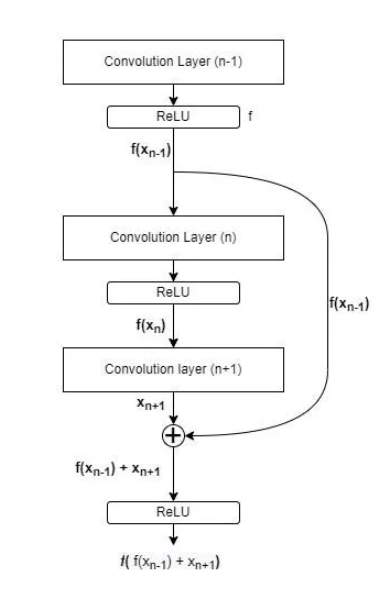
跳过连接的作用是确保即使第 n 层没有学到任何有用的信息(或输出为零),我们也不会丢失重要信息。相反,第 (n-1) 层的输出会向前传递,并与第 (n+1) 层的输出合并。
如果第 n 层没有增加价值,网络可以“跳过”它,从而保持一致的性能。如果两层都提供了有用的信息,那么将它们结合起来,就能利用两种信息源来提升网络的整体性能。
三、Resnet 的架构
以下是 Resnet-18 的架构和层配置,取自研究论文《图像识别的深度残差学习》(论文地址:https://arxiv.org/abs/1512.03385)
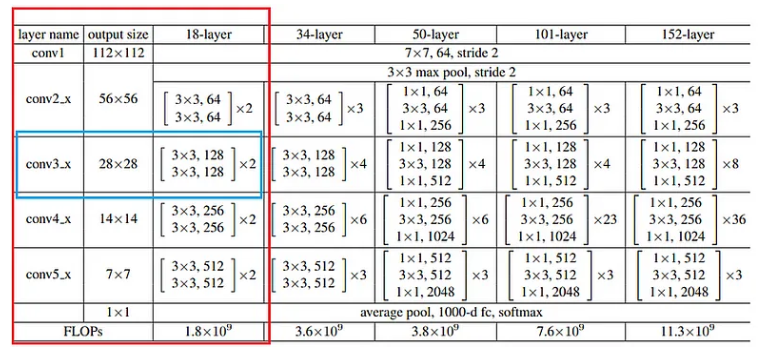
让我们选择 Conv3_x 块,并尝试了解其内部发生的情况。让我们使用卷积块和恒等块来理解这一点。
-
卷积块
目的:当输入和输出的尺寸(形状)不同时,使用卷积块,原因如下:
-
空间大小(特征图的高度和宽度)的变化。
-
频道数量的变化。
-
身份区块
目的:当输入和输出的尺寸(形状)相同时,使用身份块,允许将输入直接添加到输出而无需任何转换。
通过示例理解卷积和身份块,使用卷积和身份块的 Conv3_x 块数据流
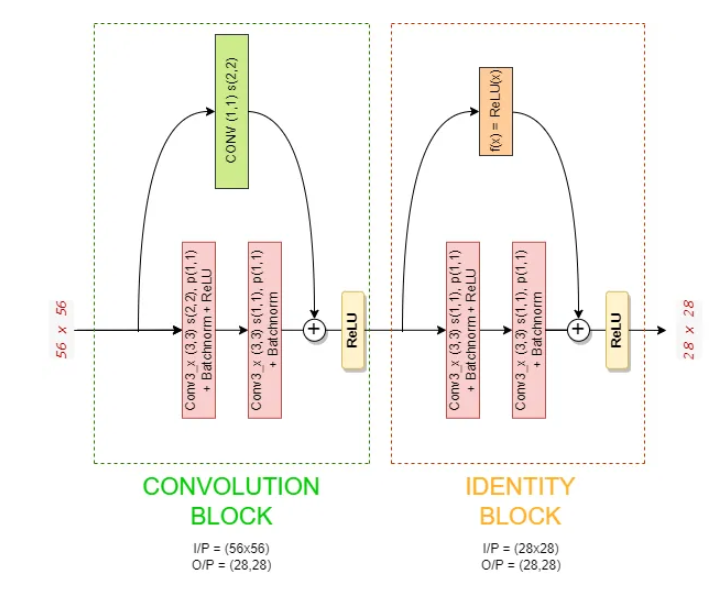
上图告诉我们 56x56 图像如何通过 Conv3_x 块传播的细节,现在我们将看看图像在这些块内的每个步骤中是如何转换的。
-
代码
class ResNet18(nn.Module):def __init__(self, n_classes):super(ResNet18, self).__init__()self.dropout_percentage = 0.5self.relu = nn.ReLU()# BLOCK-1 (starting block) input=(224x224) output=(56x56)self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=(7,7), stride=(2,2), padding=(3,3))self.batchnorm1 = nn.BatchNorm2d(64)self.maxpool1 = nn.MaxPool2d(kernel_size=(3,3), stride=(2,2), padding=(1,1))# BLOCK-2 (1) input=(56x56) output = (56x56)self.conv2_1_1 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm2_1_1 = nn.BatchNorm2d(64)self.conv2_1_2 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm2_1_2 = nn.BatchNorm2d(64)self.dropout2_1 = nn.Dropout(p=self.dropout_percentage)# BLOCK-2 (2)self.conv2_2_1 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm2_2_1 = nn.BatchNorm2d(64)self.conv2_2_2 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm2_2_2 = nn.BatchNorm2d(64)self.dropout2_2 = nn.Dropout(p=self.dropout_percentage)# BLOCK-3 (1) input=(56x56) output = (28x28)self.conv3_1_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=(3,3), stride=(2,2), padding=(1,1))self.batchnorm3_1_1 = nn.BatchNorm2d(128)self.conv3_1_2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm3_1_2 = nn.BatchNorm2d(128)self.concat_adjust_3 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=(1,1), stride=(2,2), padding=(0,0))self.dropout3_1 = nn.Dropout(p=self.dropout_percentage)# BLOCK-3 (2)self.conv3_2_1 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm3_2_1 = nn.BatchNorm2d(128)self.conv3_2_2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm3_2_2 = nn.BatchNorm2d(128)self.dropout3_2 = nn.Dropout(p=self.dropout_percentage)# BLOCK-4 (1) input=(28x28) output = (14x14)self.conv4_1_1 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=(3,3), stride=(2,2), padding=(1,1))self.batchnorm4_1_1 = nn.BatchNorm2d(256)self.conv4_1_2 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm4_1_2 = nn.BatchNorm2d(256)self.concat_adjust_4 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=(1,1), stride=(2,2), padding=(0,0))self.dropout4_1 = nn.Dropout(p=self.dropout_percentage)# BLOCK-4 (2)self.conv4_2_1 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm4_2_1 = nn.BatchNorm2d(256)self.conv4_2_2 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm4_2_2 = nn.BatchNorm2d(256)self.dropout4_2 = nn.Dropout(p=self.dropout_percentage)# BLOCK-5 (1) input=(14x14) output = (7x7)self.conv5_1_1 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=(3,3), stride=(2,2), padding=(1,1))self.batchnorm5_1_1 = nn.BatchNorm2d(512)self.conv5_1_2 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm5_1_2 = nn.BatchNorm2d(512)self.concat_adjust_5 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=(1,1), stride=(2,2), padding=(0,0))self.dropout5_1 = nn.Dropout(p=self.dropout_percentage)# BLOCK-5 (2)self.conv5_2_1 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm5_2_1 = nn.BatchNorm2d(512)self.conv5_2_2 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm5_2_2 = nn.BatchNorm2d(512)self.dropout5_2 = nn.Dropout(p=self.dropout_percentage)# Final Block input=(7x7) self.avgpool = nn.AvgPool2d(kernel_size=(7,7), stride=(1,1))self.fc = nn.Linear(in_features=1*1*512, out_features=1000)self.out = nn.Linear(in_features=1000, out_features=n_classes)# ENDdef forward(self, x):# block 1 --> Starting blockx = self.relu(self.batchnorm1(self.conv1(x)))op1 = self.maxpool1(x)# block2 - 1x = self.relu(self.batchnorm2_1_1(self.conv2_1_1(op1))) # conv2_1 x = self.batchnorm2_1_2(self.conv2_1_2(x)) # conv2_1x = self.dropout2_1(x)# block2 - Adjust - No adjust in this layer as dimensions are already same# block2 - Concatenate 1op2_1 = self.relu(x + op1)# block2 - 2x = self.relu(self.batchnorm2_2_1(self.conv2_2_1(op2_1))) # conv2_2 x = self.batchnorm2_2_2(self.conv2_2_2(x)) # conv2_2x = self.dropout2_2(x)# op - block2op2 = self.relu(x + op2_1)# block3 - 1[Convolution block]x = self.relu(self.batchnorm3_1_1(self.conv3_1_1(op2))) # conv3_1x = self.batchnorm3_1_2(self.conv3_1_2(x)) # conv3_1x = self.dropout3_1(x)# block3 - Adjustop2 = self.concat_adjust_3(op2) # SKIP CONNECTION# block3 - Concatenate 1op3_1 = self.relu(x + op2)# block3 - 2[Identity Block]x = self.relu(self.batchnorm3_2_1(self.conv3_2_1(op3_1))) # conv3_2x = self.batchnorm3_2_2(self.conv3_2_2(x)) # conv3_2 x = self.dropout3_2(x)# op - block3op3 = self.relu(x + op3_1)# block4 - 1[Convolition block]x = self.relu(self.batchnorm4_1_1(self.conv4_1_1(op3))) # conv4_1x = self.batchnorm4_1_2(self.conv4_1_2(x)) # conv4_1x = self.dropout4_1(x)# block4 - Adjustop3 = self.concat_adjust_4(op3) # SKIP CONNECTION# block4 - Concatenate 1op4_1 = self.relu(x + op3)# block4 - 2[Identity Block]x = self.relu(self.batchnorm4_2_1(self.conv4_2_1(op4_1))) # conv4_2x = self.batchnorm4_2_2(self.conv4_2_2(x)) # conv4_2x = self.dropout4_2(x)# op - block4op4 = self.relu(x + op4_1)# block5 - 1[Convolution Block]x = self.relu(self.batchnorm5_1_1(self.conv5_1_1(op4))) # conv5_1x = self.batchnorm5_1_2(self.conv5_1_2(x)) # conv5_1x = self.dropout5_1(x)# block5 - Adjustop4 = self.concat_adjust_5(op4) # SKIP CONNECTION# block5 - Concatenate 1op5_1 = self.relu(x + op4)# block5 - 2[Identity Block]x = self.relu(self.batchnorm5_2_1(self.conv5_2_1(op5_1))) # conv5_2x = self.batchnorm5_2_1(self.conv5_2_1(x)) # conv5_2x = self.dropout5_2(x)# op - block5op5 = self.relu(x + op5_1)# FINAL BLOCK - classifier x = self.avgpool(op5)x = x.reshape(x.shape[0], -1)x = self.relu(self.fc(x))x = self.out(x)return x实现后,我们可以直接创建此类的对象并传递数据集的输出类的数量,并使用它在任何图像数据上训练我们的网络。
-
这些块为什么有用?
-
卷积块处理空间分辨率或通道数量的变化,同时保留残差连接。
-
身份块专注于在不改变输入维度的情况下学习附加特征。
-
它们共同作用,允许梯度流,即使某些层不能有效学习,也能使深度网络有效地训练
四、ResNet为何成为经典
ResNet的成功,不在于它堆了多少层,而在于它对“深层神经网络如何训练”这个根本问题给出了一个优雅解法:如果学不会,就跳过去!
这种看似简单的思想,却释放了深度学习的潜力,也为后续模型设计开辟了全新路径,DenseNet、Mask R-CNN、HRNet、Swin Transformer……都离不开它的残差思想。
所以,ResNet 不只是一种网络架构,更是一种范式的转变——这,正是它成为经典的原因。
