搜索二叉树
二叉搜索树的概念:
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
它的左右子树也分别为二叉搜索树。
我们之前学的list,string,vector都叫做序列式容器,而我们学的二叉搜索树叫做关联式容器,
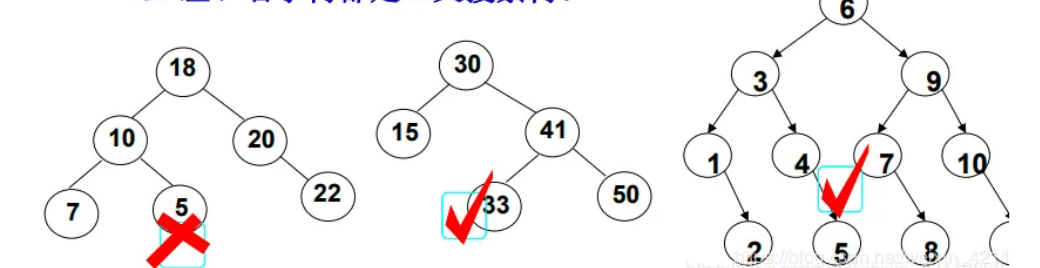
二叉搜索树的的一些常见的接口
BSTree()//构造
BSTree(const BSTree<K>&t);//拷贝构造
BSTree<K>& operator=(BSTree<K>t)//赋值运算符重载
~BSTree()//析构
//非递归的版本实现
bool Insert(const K& key);//插入
bool Find(const K& key);//查找
bool Erase(const K& key);//删除(重点的讲解实现思路)
//递归版本的实现
CopyTree(Node* root)//树的拷贝
void destory(Node*& root)//销毁
bool _EraseR(Node*& root,const K& key)
void _Inorder(Node* root)//中序遍历
bool _FindR(Node* root, const K& key)
bool _InsertR(Node*& root, const K& key)
非递归版本的插入
实现思路:二叉搜索树要满足根的左子树要比根要小,右子树要比根要大;我们要插入key的时候,首先就要判断一下key比根要大还是小,比根小往左边走,比根大往右子树去找;相等的话就不插入;
bool Insert(const K& key)
{if (_root == nullptr){_root = new Node(key);return true;}//不为空的时候Node* cur = _root;Node* parent = nullptr;while (cur){if (cur->_key > key){parent = cur;cur = cur->_left;}else if (cur->_key < key){parent = cur;cur = cur->_right;}else//相等的话{return false;}}//开始插入cur = new Node(key);if (parent->_key > key){parent->_left = cur;}else{parent->_right = cur;}return true;
}
find的接口的实现
bool Find(const K& key)
{Node* cur = _root;while (cur){if (cur->_key > key){cur = cur->_left;}else if (cur->_key < key){cur = cur->_right;}else{return true;}}//找不到return false;
}
删除接口的实现思路
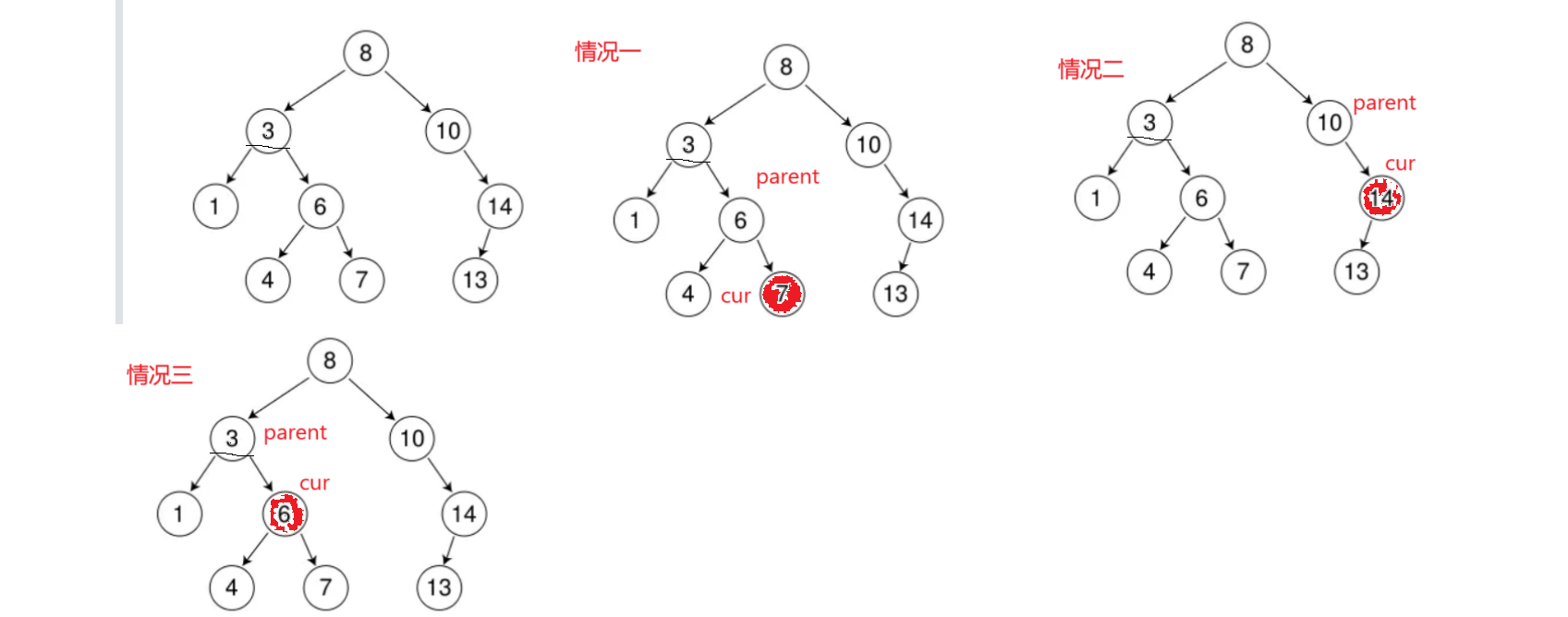
我们要考虑到这三种情况,情况一和情况二可以归为一类,我们需要让parent->left/right=cur->left/right;
第三种才是直接删不好删的,我们可以使用一个替换法,我们知道二叉搜索树的概念是它的左子树永远是比根小的,右子树是比根大的,我们可以根据这个性质去左子树的里面去找他的最大的那个树也就是左子树的最右子树是左子树最大的,或者去右子树里面去找右子树中最左子树的那个节点;
bool Erase(const K& key)
{Node* cur = _root;Node* parent = nullptr;while (cur){if (cur->_key > key){parent = cur;cur = cur->_left;}else if (cur->_key < key){parent = cur;cur = cur->_right;}else//开始删除{if (cur->_left == nullptr){if (cur == _root){_root = cur->_right;}else{if (parent->_left == cur){parent->_left = cur->_right;}else{parent->_right = cur->_right;}}}else if (cur->_right == nullptr){if (_root == cur){_root = cur->_left;}else{if (parent->_left == cur){parent->_left = cur->_left;}else{parent->_right = cur->_left;}}}//俩边都不为空的时候else{Node* rightmin = cur->_right;//去最右边找最小值parent = cur;while (rightmin->_left){parent = rightmin;rightmin = rightmin->_left;}//替换位置swap(cur->_key, rightmin->_key);if (parent->_left == rightmin){parent->_left = rightmin->_left;}else{parent->_right = rightmin->_left;}cur = rightmin;}delete cur;cur = nullptr;return true;}}return false;
}
递归版本的实现
bool _FindR(Node* root, const K& key)
{if (root == nullptr)return false;if (root->_key > key)return _FindR(root->_left, key);else if (root->_key < key)return _FindR(root->_right, key);elsereturn true;
}
bool _InsertR(Node*& root, const K& key)
{if (root == nullptr){root = new Node(key);return true;}if (root->_key > key){return _InsertR(root->_left, key);}else if (root->_key < key){return _InsertR(root->_right, key);}else{return false;}
}
bool _EraseR(Node*& root,const K& key)
{if (root == nullptr)return false;if (root->_key > key){return _EraseR(root->_left, key);}else if (root->_key < key){return _EraseR(root->_right, key);}else//开始删除{if (root->_left == nullptr){root = root->_right;}else if (root->_right == nullptr){root = root->_left;}else{Node* leftmax = root->_left;//找左半边的最大值while (leftmax->_right){leftmax = leftmax->_right;}swap(leftmax->_key, root->_key);root = leftmax;return _EraseR(root->_left, key);}return true;}
}
四个默认构造的实现
BSTree():_root(nullptr)
{}
BSTree(const BSTree<K>&t)
{_root=CopyTree(t._root);
}
BSTree<K>& operator=(BSTree<K>t)
{swap(_root, t._root);return *this;
}
~BSTree()
{destory(_root);
}
Node* CopyTree(Node* root)
{if (root == nullptr){return nullptr;}Node* cur = new Node(root->_key);cur->_left = CopyTree( root->_left);cur->_right = CopyTree(root->_right);return cur;
}
void destory(Node*& root)
{if (root == nullptr)return;destory(root->_left);destory(root->_right);delete root;root = nullptr;
}
前序,中序,后序的非递归实现
前序
我们之前都是借助递归来实现的,因为比较简单,我们想要实现非递归我们得知道我们在递归的时候是怎么访问呢?根->左子树->右子树

vector<int> preorder(Node* root)
{stack<Node*>st;vector<int>vs;Node* cur = root;while (cur || !st.empty()){//取出当前节点入栈while (cur){vs.push_back(cur->_key);//存储根的值st.push(cur);cur = cur->_left;}//开始访问右节点if (!st.empty()){auto top = st.top();st.pop();cur = top->_right;}}return vs;
}
中序的非递归实现
跟前序实现思路一样,就是访问根的时机不同而已;我们是在左子树访问完了之后才开始访问;
vector<int> INorder(Node* root)
{stack<Node*>st;vector<int>vs;Node* cur = root;while (cur || !st.empty()){//取出当前节点入栈while (cur){st.push(cur);cur = cur->_left;}//开始访问右节点if (!st.empty()){auto top = st.top();st.pop();vs.push_back(cur->_key);cur = top->_right;}}return vs;
}
后序的非递归实现
基本大体思路一样,就是有一个难点什么时候访问根呢?我们在入栈的时候一共会有俩次访问根的机会
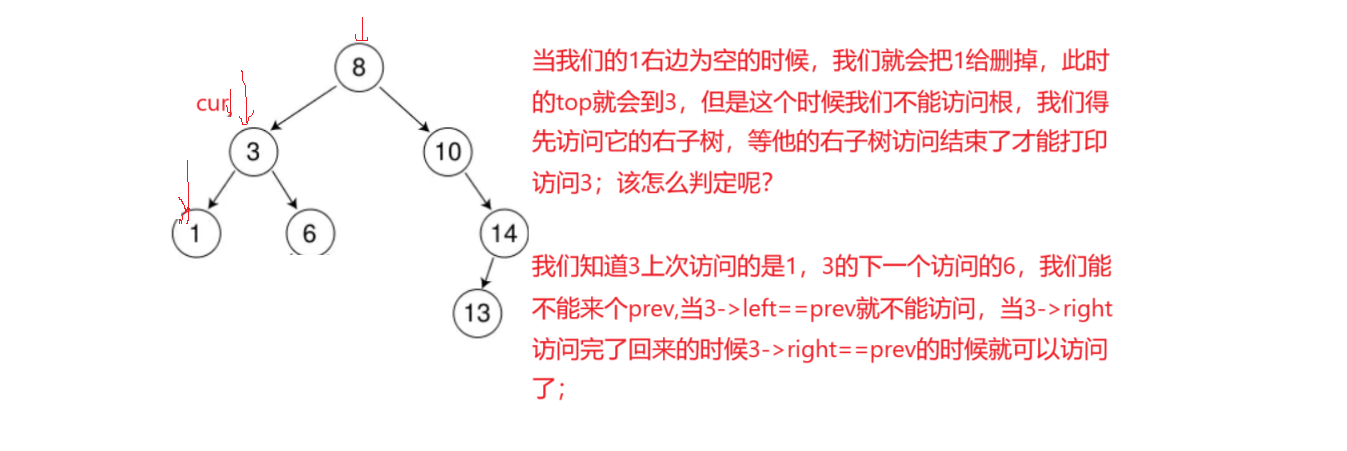
vector<int> Postorder(Node* root){stack<Node*>st;vector<int>vs;Node* cur = root;Node* prev = nullptr;while (cur || !st.empty()){//取出当前节点入栈while (cur){st.push(cur);cur = cur->_left;}//开始访问右节点if (!st.empty()){auto top = st.top();prev = top;if (top->right == nullptr || top->right == prev){st.pop();vs.push_back(top->_key);}else{cur = top->_right;}}}return vs;}