传统 OLAP 系统的局限
在大数据实时分析领域,数据模型设计直接决定了系统的查询性能、存储效率与业务适配性。Apache Doris作为新一代MPP分析型数据库,通过独创的多模型融合架构,在业内率先实现了"一份数据支持多种分析范式"的能力。本文将深入解析Doris的三大核心数据模型及其背后的设计哲学。
在 Doris 出现之前,传统的 OLAP 系统通常面临以下的局限性:
- 预聚合模型,牺牲灵活性换取性能,无法支持明细查询;
- 全量明细模型,保留原始数据但查询效率低下;
- Lambda 混合架构,又会导致架构复杂,而且会有数据一致性风险。
Doris 数据模型技术实现
Doris 通过数据模型来定义数据存储和管理方式,当前提供了明细模型、聚合模型以及主键模型三种表模型,不同的模型具有相应的数据去重、聚合和更新机制,满足不同应用场景需求。
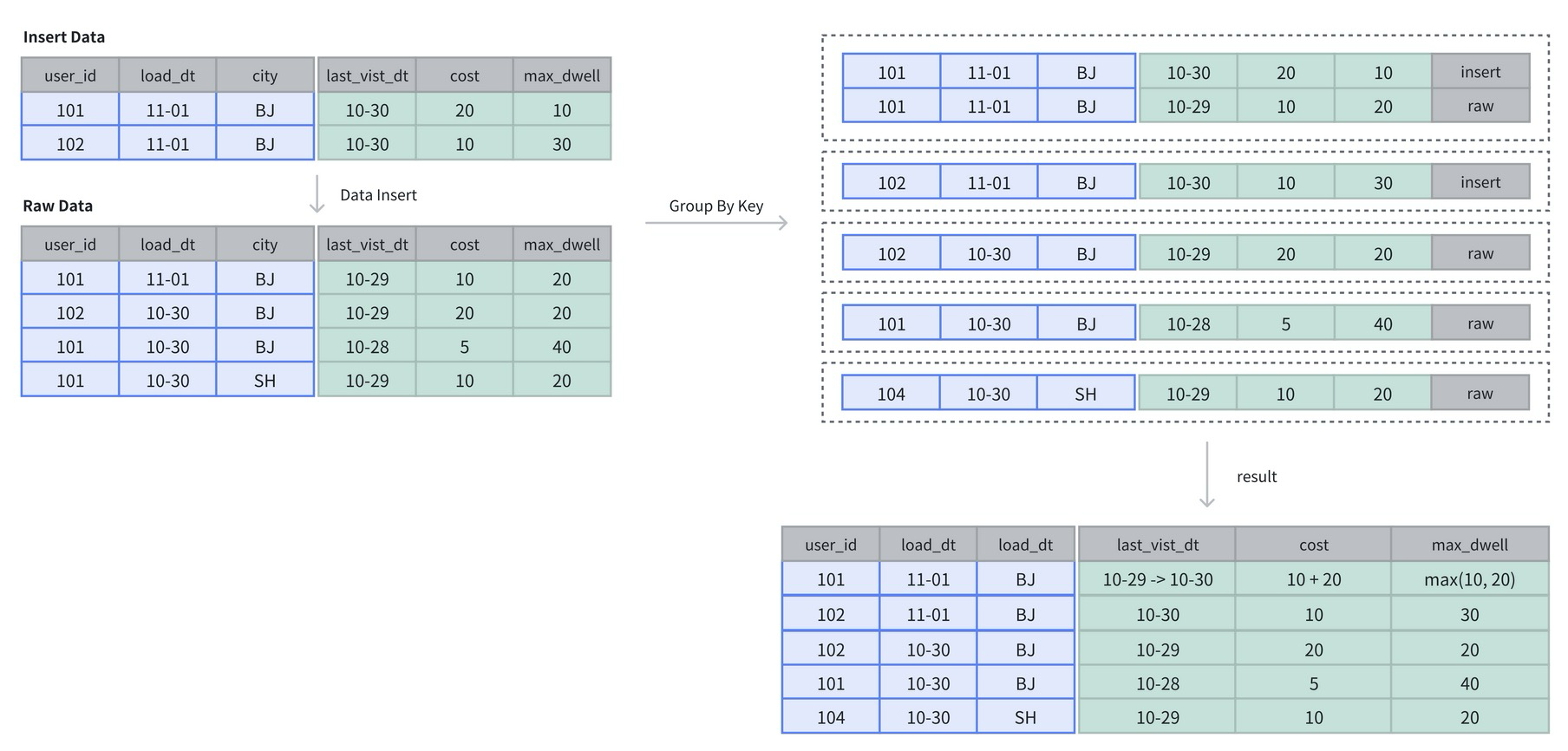
明细模型 (Duplicate Key Model)
明细模型下的数据存储类似于传统数据库,允许指定的 Key 列重复,一般数据只进行追加,现有数据不更新或少量更新。 Doris 存储层保留所有写入的数据,既不去重也不聚合。
虽然无法利用预聚合特性,但是不受聚合模型的约束,可以发挥列存模型的优势。适合任意维度的 Ad-hoc 查询,典型的应用场景如日志存储、交易数据和用户行为数据查询等。
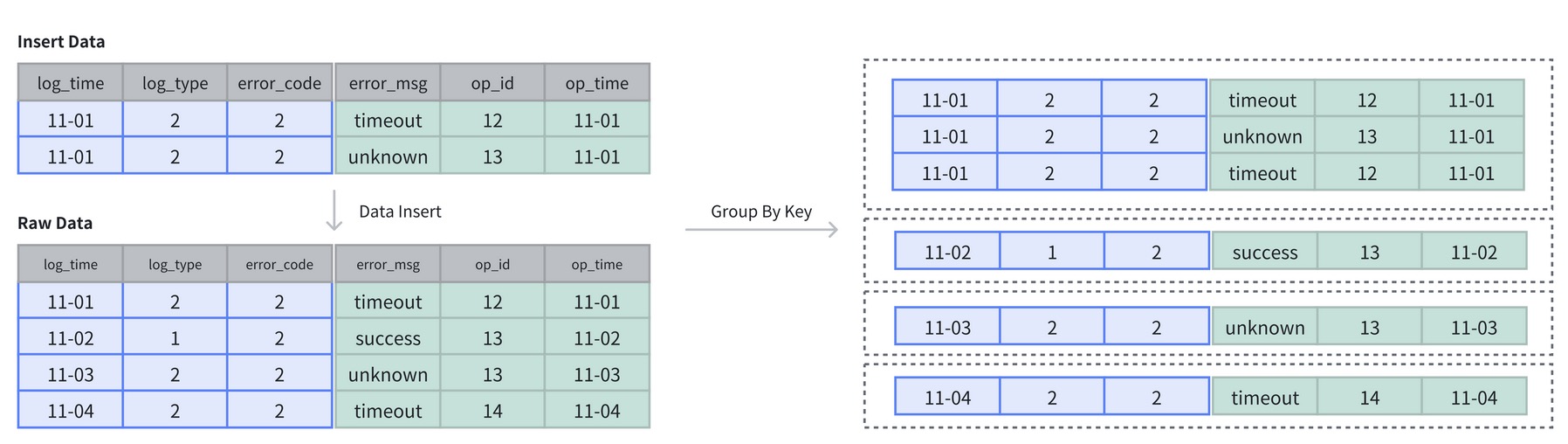
主键模型 (Unique Key Model)
每行 Key 值唯一,确保给定的 Key 列不会存在重复行,基于主键进行 UPSERT 更新,Doris 存储层对每个 Key 只保留最新写入的数据。
Doris 中的主键模型有两种实现方式:
- 写时合并:数据在写入时立即合并相同 Key 的记录,确保存储的始终是最新数据。写时合并兼顾查询和写入性能,避免多个版本的数据合并,并支持谓词下推到存储层。大多数场景推荐使用此模式;
- 读时合并:数据在写入时并不进行合并,以增量的方式被追加存储,在 Doris 内保留多个版本。查询或 Compaction 时,会对数据进行相同 Key 的版本合并。读时合并适合写多读少的场景,在查询是需要进行多个版本合并,谓词无法下推,可能会影响到查询速度。
主键模型默认为整行更新,即使用户使用 Insert Into 指定部分列进行写入,Doris 也会在 Planner 中将未提供的列使用 NULL 值或者默认值进行填充。如果希望更新部分字段,需要使用写时合并实现,并通过特定的参数来开启部分列更新的支持。
针对需要唯一主键约束的场景,可以保证主键唯一性约束,但无法利用 ROLLUP 等预聚合带来的查询优势。适用于需要数据更新的情况,典型的场景如用户画像和实时风控等。
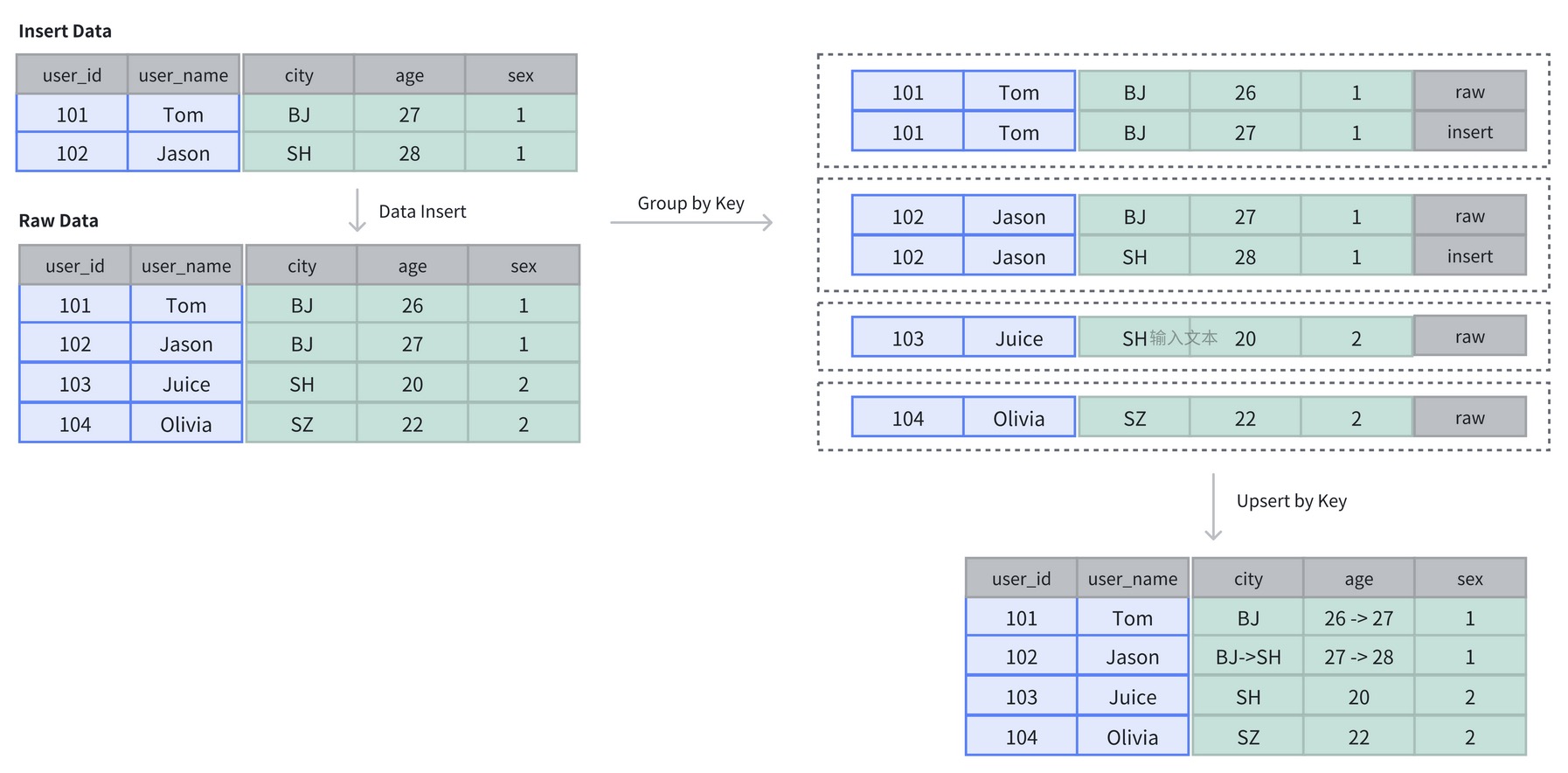
聚合模型 (Aggregate Key Model)
聚合模型专为高效处理大规模数据查询中的聚合操作设计,根据 Key 列聚合数据,在数据写入时自动维护 SUM/MAX/MIN 等聚合状态, Doris 存储层保留聚合后的数据,从而减少存储空间,极大的降低聚合查询时所需要扫描的数据量和查询计算量,非常适合有固定模式的报表类查询和指标看板等场景。
当然聚合模型的使用也存在一定的局限性:
- 模型对外展现的是最终聚合后的数据,任何还未聚合的数据(比如说两个不同导入批次的数据),必须通过某种方式,以保证对外展示的一致性。因此,在进行其他类型的聚合查询时,需要考虑语意正确性;
- 模型对 count(*) 查询很不友好,为了得到正确的结果,必须扫描所有的聚合列,并进行聚合后才能得到语意正确的结果,查询成本非常高。
模型特征总结
| 模型类型 | 数据特征 | 典型场景 | 性能优势 |
|---|---|---|---|
| 明细模型 | 原始数据、高基数维度 | 日志分析、Ad-hoc查询 | 灵活查询 |
| 聚合模型 | 固定维度、数值型指标 | 日报表、监控看板 | 查询速度提升100倍 |
| 主键模型 | 频繁更新、点查为主 | 用户画像、实时库存 | 支持高并发点查 |
写在最后
实时分析场景是 Doris 的立足之本,致力于打造速度最快且最具成本效益的分析型数据库,而数据模型是实现这一目标的基础。传统 OLTP 数据库大多数使用明细模对数据进行直接的存储,而不做额外的处理和加工,好处是插入性能好,满足高响应低延时的业务系统需求;而 OLAP 类的业务通常有较多的分析计算,通过聚合模型将数据按需求提前进行计算,在查询时直接提取计算后的结果,因而大大降低了分析计算的时间,但是又会损失一些插入的时间。
数据库的设计中总是充满了各种权衡,就像 Doris 的聚合模型,当你在分析计算过程中得到了好处,则可能在数据插入时损失一些性能。当然好的产品或者好的架构师,就是结合自身的业务需求,将适当的技术和产品放在最合理的位置,从而发挥出最大的价值!