最近OpenAI发布了GPT-4.1模型,却让不少人感到困惑。今天我们就来深入剖析这个新模型的关键信息!

重要前提:API专属模型 💻
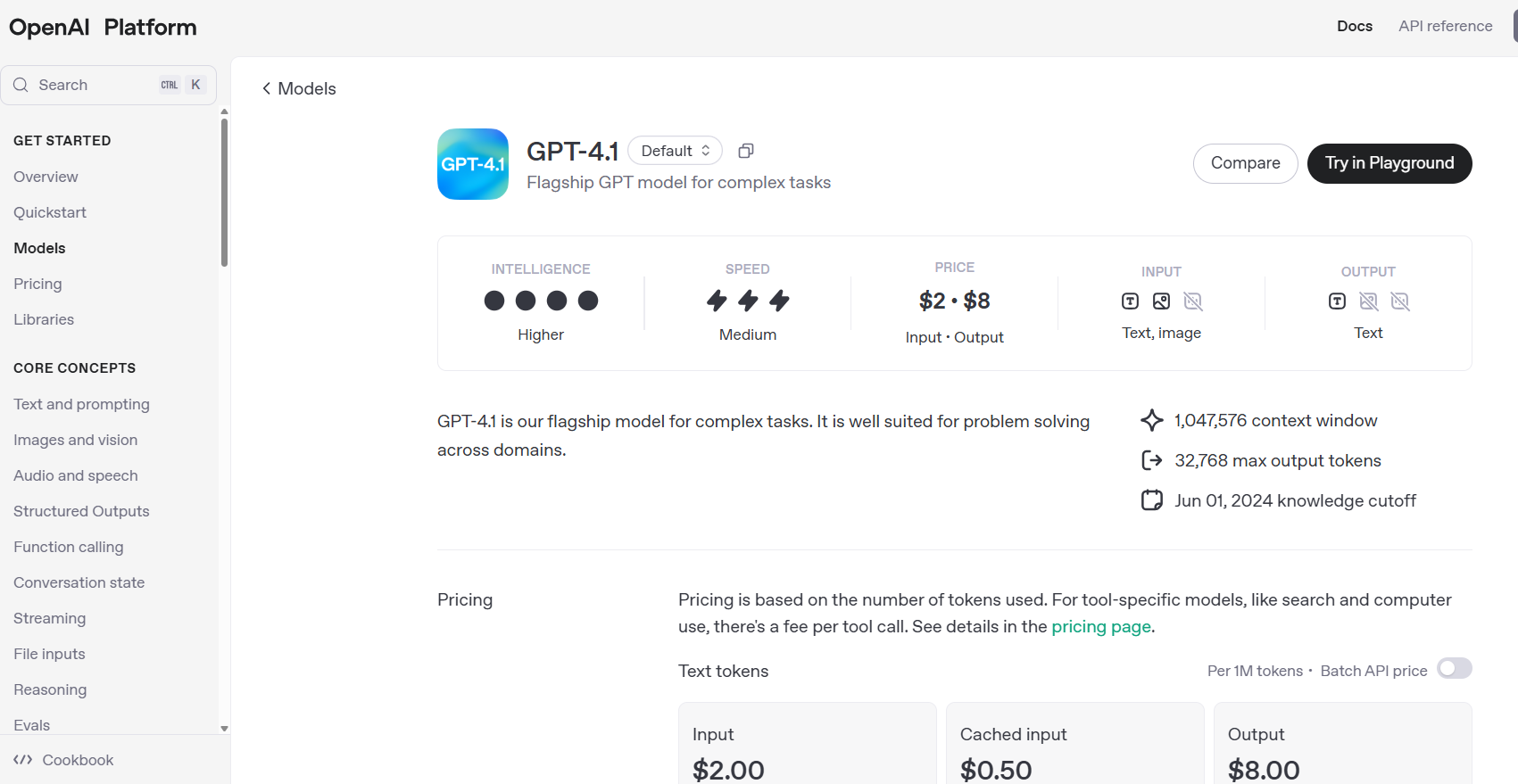
首先需要明确的是,GPT-4.1仅通过API提供,不会出现在聊天界面中。这是因为该模型主要面向开发者设计,而非普通聊天用户。实际上,GPT-4.1的许多改进已经逐步整合到了GPT-4.0的聊天版本中。
"在ChatGPT中,指令跟随、编码和智能方面的许多改进已逐步整合到GPT-4.0的最新版本中,我们将在未来版本中继续整合更多改进。"
这意味着在某些方面GPT-4.1与GPT-4.0差异不大,但在特定领域确实存在显著差异,因此专门为开发者优化。
如何体验GPT-4.1? 🔍
如果你想在聊天界面中尝试GPT-4.1,可以通过以下步骤:
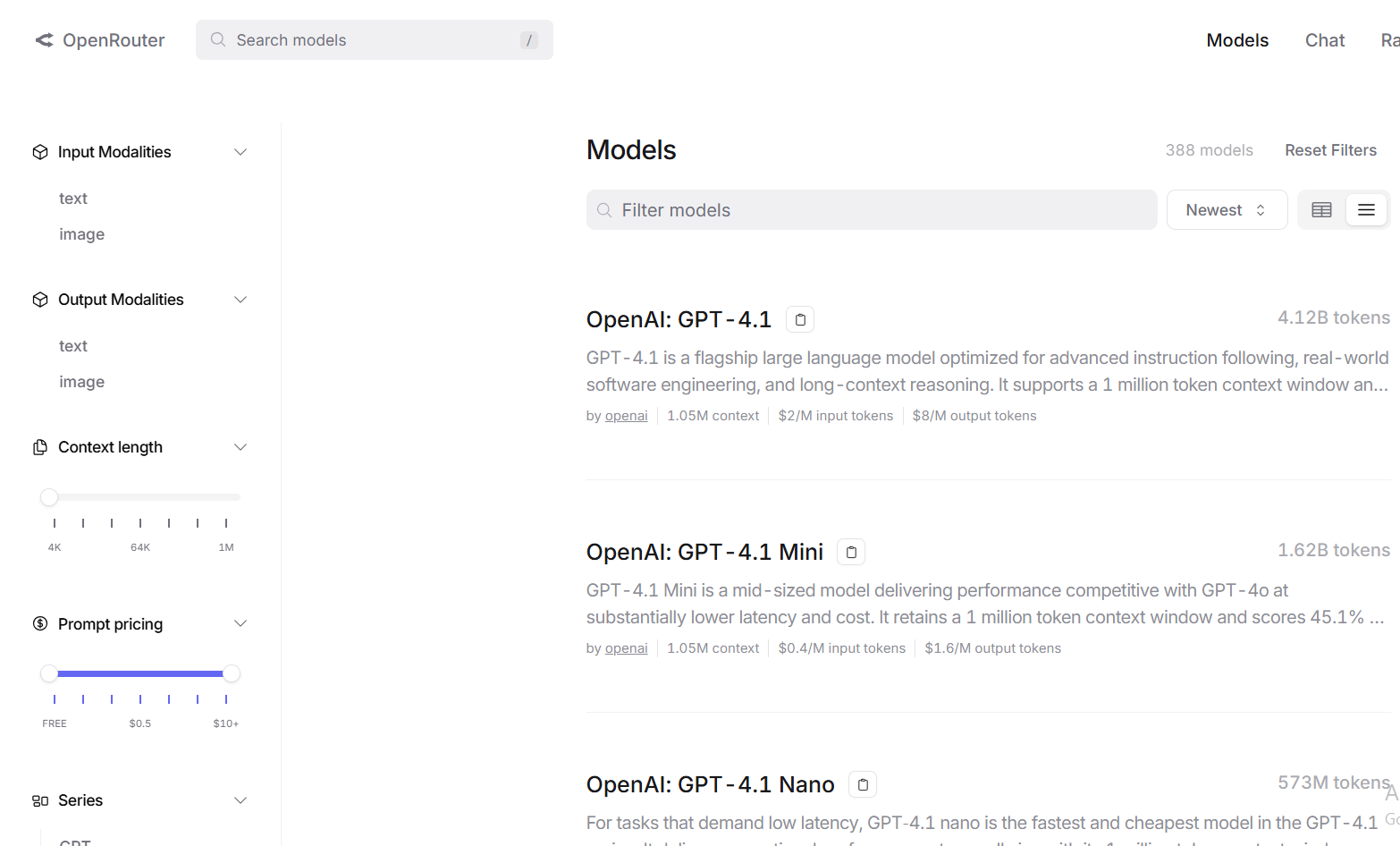
- 1. 访问OpenRouter网站
- 2. 点击"Chat"按钮
- 3. 创建新聊天室
- 4. 点击模型选择图标
- 5. 找到并选择GPT-4.1
- 6. 点击"应用"即可开始对话
三款模型,各有所长 📊
OpenAI此次实际发布了三款不同规格的模型:
1. GPT-4.1旗舰版
- • 定位:复杂任务的智能首选
- • 上下文长度:超过100万token
- • 最大输出token:32,000
- • 价格:相比其他模型较为实惠
- • 功能:支持文本输入/输出
- • 延迟:与GPT-4.0相近
2. GPT-4.1 Mini
- • 速度:比GPT-4.0快40%
- • 特点:平衡速度与智能
- • 价格:更加经济实惠
3. GPT-4.1 Nano
- • 定位:低延迟任务的最佳选择
- • 特点:速度最快、性价比最高
- • 价格:极其亲民
这种产品矩阵显然是OpenAI为了应对市场上日益增多的经济型模型而采取的策略。
性能表现:编码能力突出 💻
在软件工程领域,GPT-4.1表现尤为亮眼:
- • 显著优于GPT-4.0
- • 在代理式解决编码任务方面更出色
- • 前端编码能力更强
- • 减少了不必要的编辑
- • 更可靠地遵循差异格式
- • 工具使用更一致
实际测试显示,在创建网页应用时:
- • 人类评审员80%的情况下更偏好GPT-4.1的作品
- • 生成的网站功能更完善
- • 视觉效果更美观
长上下文处理能力惊人 📚
GPT-4.1的100万token上下文窗口表现出色:
- • 在"大海捞针"测试中准确率接近100%
- • 1百万token相当于8个完整的React代码库
- • 特别适合处理大型代码库的检索和修改
在视频长上下文理解方面:
- • 能够回答基于30-60分钟无字幕视频的多选题
- • 表现优于GPT-4.0
实际应用案例 📈
多家企业报告了显著改进:
- • Windinssurf内部编码基准提升60%
- • 代码变更首次审核通过率提高
- • 工具调用效率提升30%
- • 不必要编辑减少50%
- • 某公司税务场景准确率提升53%
模型对比与淘汰 🆚
在编码基准测试中:
- • 仅次于Claude 3.7 Sonnet和Gemini 2.5 Pro
- • 明显优于其他竞品
值得注意的是,OpenAI宣布:
- • GPT-4.5 API将于2025年7月14日停用
- • 给予开发者3个月过渡期
- • 原因是运营成本过高
开发者福音 🎯
OpenAI明确表示:
"虽然基准测试提供了有价值的见解,但我们训练这些模型时更关注实际应用价值。通过与开发者社区的密切合作,我们优化了这些模型,使其最适合实际应用场景。"
GPT-4.1系列在保持性能的同时降低了成本,在每个延迟节点上都推动了性能进步,是开发者值得考虑的新选择。
你对这三款新模型有什么看法?作为开发者会考虑使用吗?欢迎在评论区分享你的观点!👇