引言
中小企业在进行数据采集的工作中,往往面对各类反爬机制越来越复杂的网站,传统的爬虫手段往往显得力不从心。特别是像Amazon这样的网站,它们通过多重验证与动态内容加载,给开发者制造了不少障碍。这时就需要使用代理服务平台,来帮助我们以更智能、更稳定的方式完成数据采集任务。亮数据是一家比较知名的IP代理服务商,它是按实际使用计费,价格比较划算,这次我们就选用它。接下来我们将从配置网页解锁器开始,逐步搭建一个简单的商品信息抓取脚本,并探讨如何解析页面、提取有价值的数据。
亮数据-网络IP代理及全网数据一站式服务商屡获殊荣的代理网络、强大的数据挖掘工具和现成可用的数据集。亮数据:网络数据平台领航者![]() https://www.bright.cn/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_yingjie202504&promo=APIS25
https://www.bright.cn/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_yingjie202504&promo=APIS25
网页解锁器
登录以后,在控制面表选择代理&抓取基础设施中的网页解锁器进入配置界面。
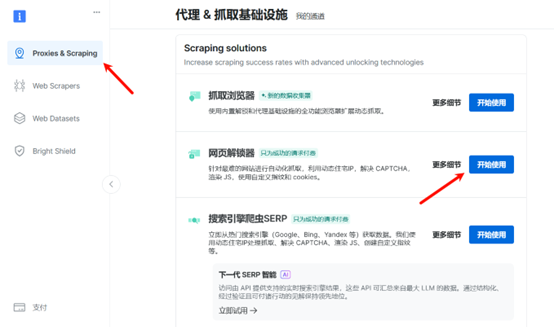
在设置页面中填写名称,在下方可以开启一些高级设置来适配验证比较复杂的网站。之后点击添加即可开始使用。
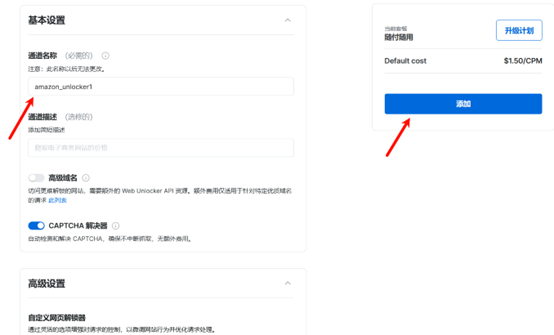
设置里,复制主机、端口、用户名和密码便于之后连接代理使用。右侧有一个样品代码,我们可以直接复制使用。这里需要注意的是一定要在下方将本机IP添加到白名单中。
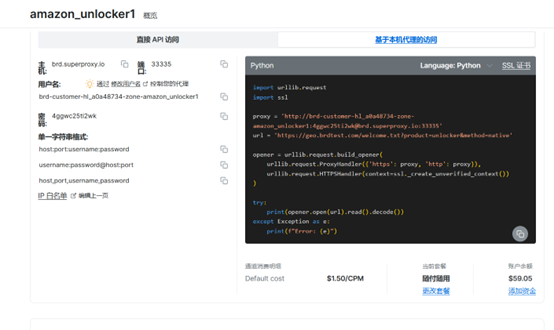
当我们使用网络解锁器访问网站时,服务器会自动处理网站防护机制,将目标网页发送给我们。基于这一原理我们可以着手编写代码。首先填写代理地址、目标网址和请求头。其中请求头中填写UA参数,这个可以很容易搜索到各大浏览器的参数。目标网址留空请求参数便于调整查询的目标和页数。
proxy = 'http://brd-customer-hl_a0a48734-zone-amazon_unlocker1:4ggwc25txxxxxi2wk@brd.superproxy.io:33335'
proxy = {'http': proxy,'https': proxy}
url = 'https://www.amazon.com/s?'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0'}之后定义get_page函数,通过requests.get()向指定URL发送请求,同时将代理和请求头打包进去,获取网页的HTML文本并返回。
def get_page(url, proxy):req = requests.get(url=url, proxies=proxy, headers=headers)return req.text接下来定义parse_page函数,对获取的网页进行解析。先调用etree.HTML()来构建HTML的DOM结构,接下来使用XPath表达式提取搜索结果区域中的商品列表节点,并初始化一个计数器和结果列表。随后,通过循环对每个商品节点提取三类信息:商品图片链接、标题文本和价格。提取的结果被组织成一个字典,追加到结果列表中。循环最多执行65次后终止,以限制单页面的抓取数量。
def parse_page(page):root = etree.parse(page)list = root.xpath(r'//div[contains(@class,"s-result-list")][1]//div[contains(@class,"s-result-item")]')counter = 0result = []for li in list:if counter == 65:breakimage = li.xpath(r'.//div[@data-cy="image-container"]//img[@class="s-image"]/@src')title = li.xpath(r'.//div[@data-cy="title-recipe"]/a/h2/span/text()')price = li.xpath(r'//div[@data-cy="price-recipe"]//span[@class="a-price"]/span/text()')result.append({'image': image, 'title': title, 'price': price})counter += 1return result程序的主逻辑被封装在main()函数中。它设置搜索关键词为'watch',抓取前5页的结果,并在控制台打印起始和结束信息。
def main():keyword = 'watch'max_page = 5print('Starting...')for page in range(1, max_page + 1):html = get_page(url + f'k={keyword}&page={page}', proxy)r = parse_page(html)save(f'{keyword}_{page}', str(r))print('Done..')完整代码如下:
import requests
from lxml import etreeproxy = 'http://brd-customer-hl_a0a48734-zone-amazon_unlocker1:4ggwc25ti2wk@brd.superproxy.io:33335'
proxy = {'http': proxy, 'https': proxy}
url = 'https://www.amazon.com/s?'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0'}def get_page(url, proxy):req = requests.get(url=url, proxies=proxy, headers=headers)return req.textdef parse_page(page):root = etree.HTML(page)list = root.xpath(r'//div[contains(@class,"s-result-list")][1]//div[contains(@class,"s-result-item")]')counter = 0result = []for li in list:if counter == 65:breakimage = li.xpath(r'.//div[@data-cy="image-container"]//img[@class="s-image"]/@src')title = li.xpath(r'.//div[@data-cy="title-recipe"]/a/h2/span/text()')price = li.xpath(r'.//div[@data-cy="price-recipe"]//span[@class="a-price"]/span/text()')result.append({'image': image, 'title': title, 'price': price})counter += 1return resultdef save(fname, text):with open(f'{fname}.txt', 'w', encoding='utf8') as f:f.write(text)def main():keyword = 'watch'max_page = 5print('Starting...')for page in range(1, max_page + 1):html = get_page(url + f'k={keyword}&page={page}', proxy)r = parse_page(html)save(f'{keyword}_{page}',str(r))print('Done..')if __name__ == '__main__':main()搜索引擎结果页
做电商的朋友经常需要跟踪当下热门趋势和竞品动态,而这往往离不开对搜索引擎结果的抓取与分析。由于搜索引擎本身具有较强的商业敏感性,因此对爬虫程序设置了更严格的访问限制。此时,我们可以借助亮数据提供的搜索引擎结果页(SERP)工具来解决这一难题。只需提交关键词、搜索引擎类型、地区及其他相关参数,SERP工具便会自动获取结果,并以结构化的JSON格式返回,极大地方便后续的数据处理与分析工作。
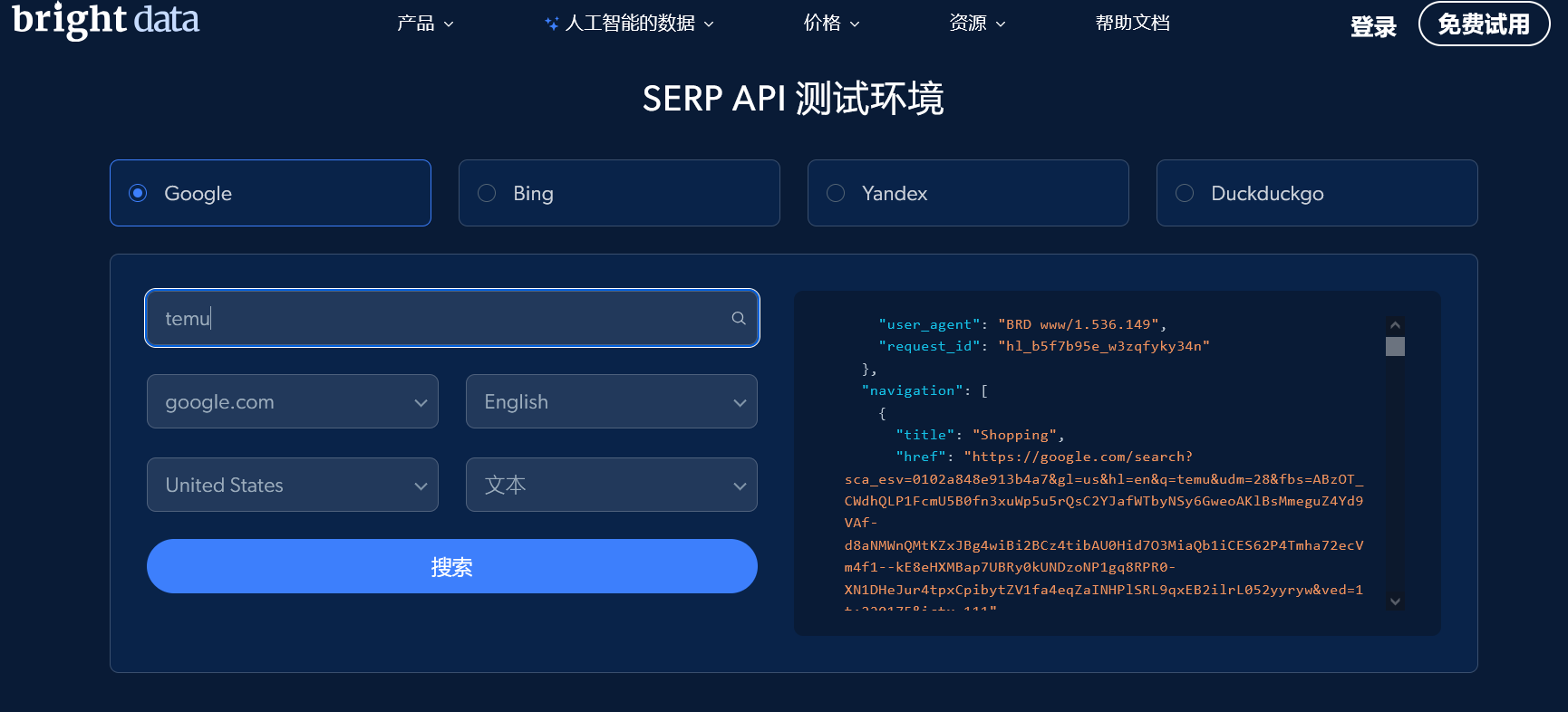
登录以后,在控制台的代理&爬取基础设施中选择搜索引擎爬虫SERP。
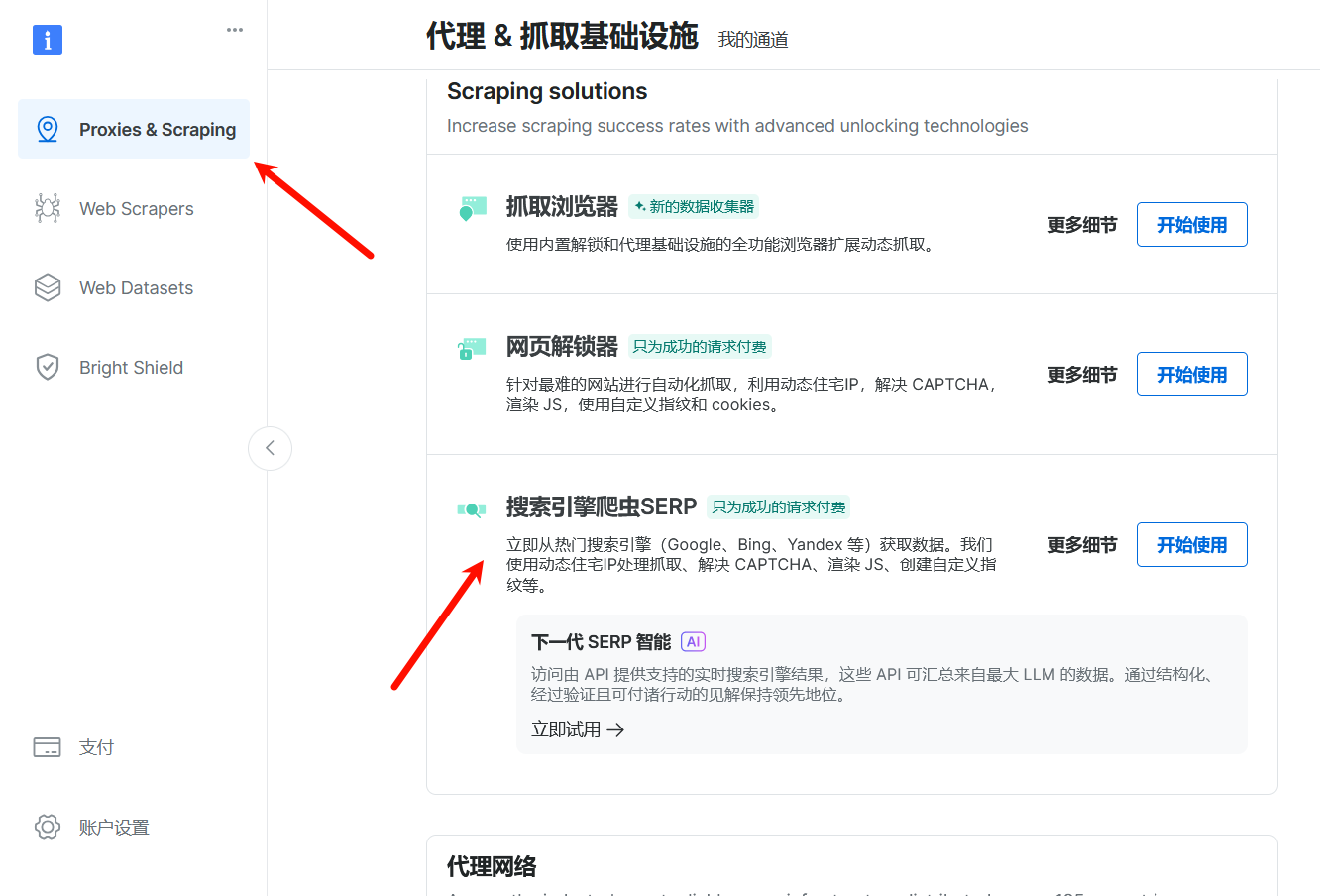
使用的方法和网页解锁器类似,通过将请求发送给服务器以获取结果。在这里请务必将自己本机IP添加至白名单
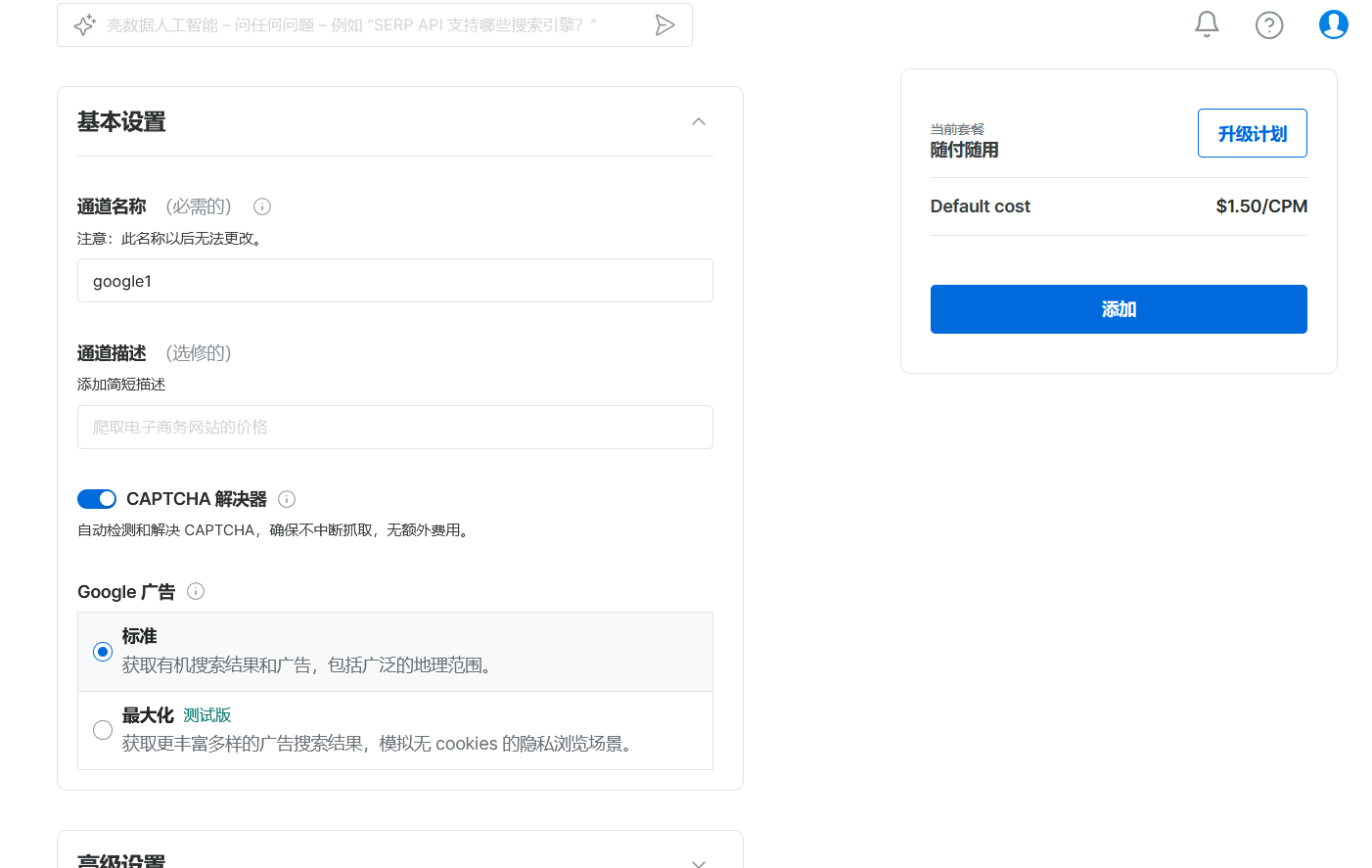
使用的方法和网页解锁器类似,通过将请求发送给服务器以获取结果。在这里请五笔将自己本机IP添加至白名单。
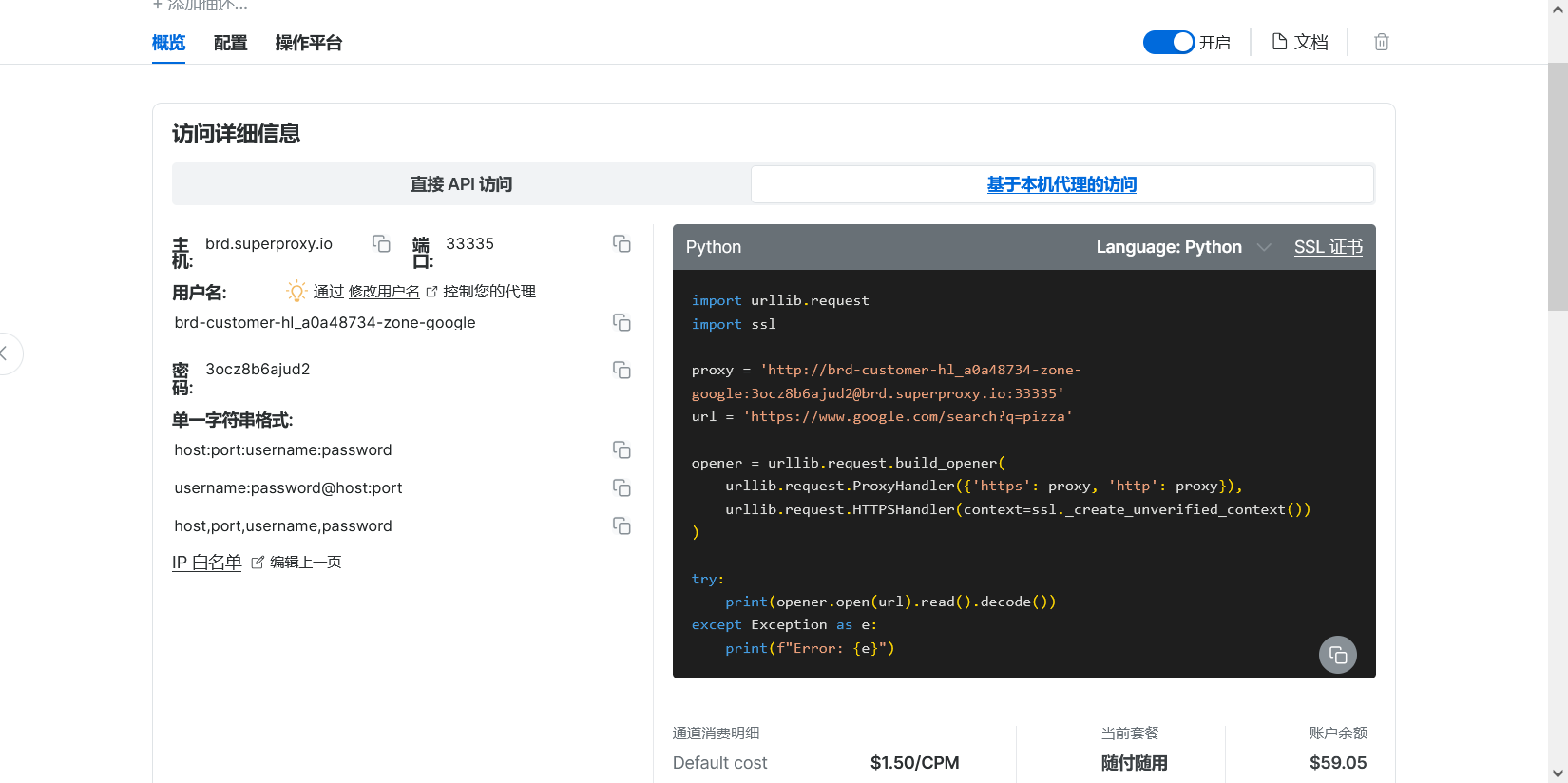
如果你编程技术没有那么娴熟,也可以选择操作平台来进行无代码编程。选择搜索引擎、搜索区域和语言、搜索类型、分页、设备等参数后,填写搜索关键字点击搜索。
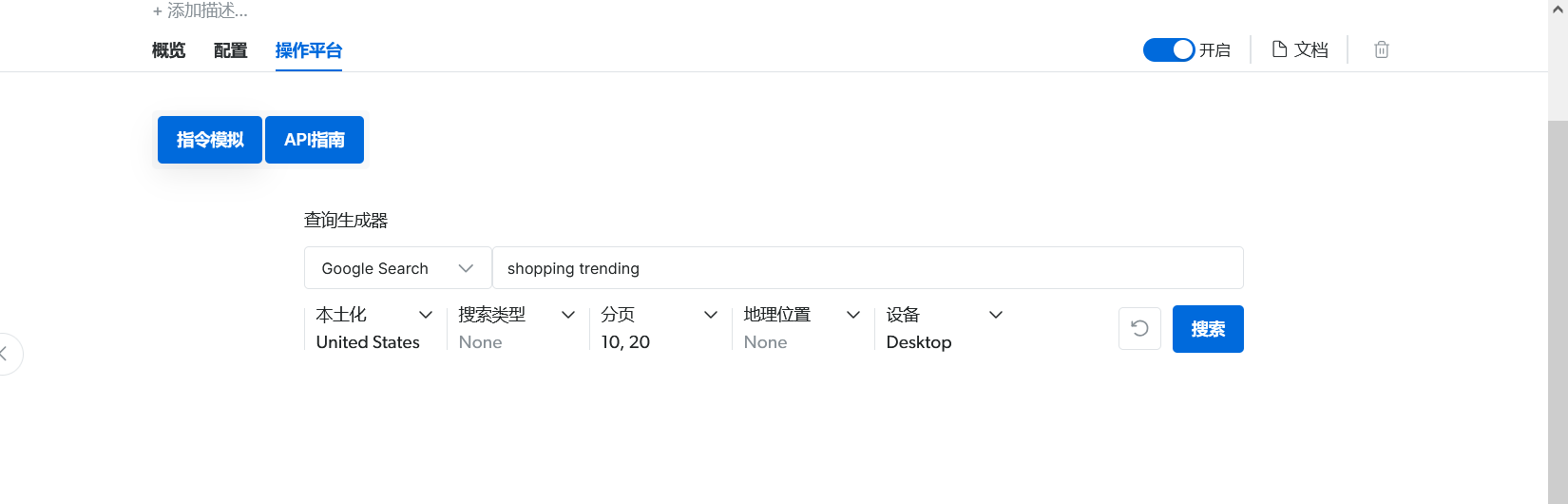 稍等片刻即可获得结果。左侧是实际的搜索结果,而右侧是以json形式展示的结果。在这里可以调整参数获得一个最佳的搜索结果。
稍等片刻即可获得结果。左侧是实际的搜索结果,而右侧是以json形式展示的结果。在这里可以调整参数获得一个最佳的搜索结果。
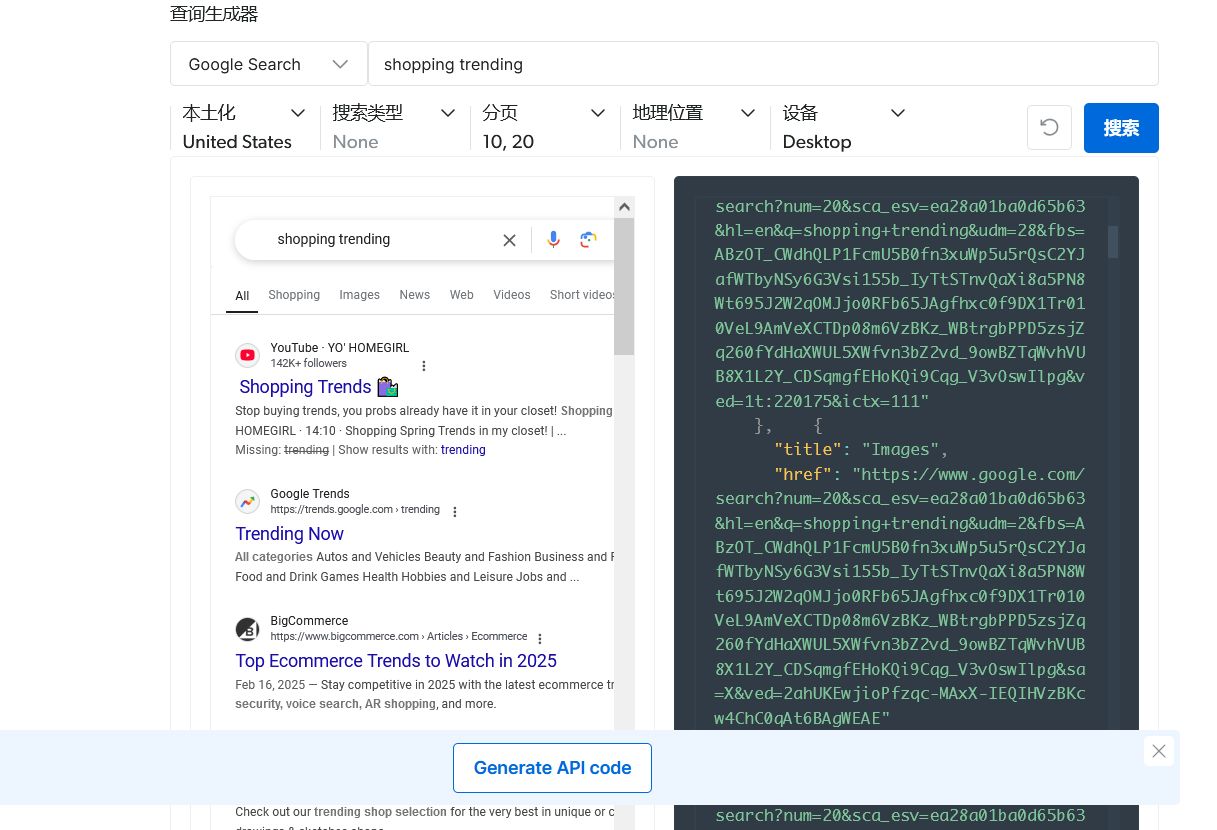
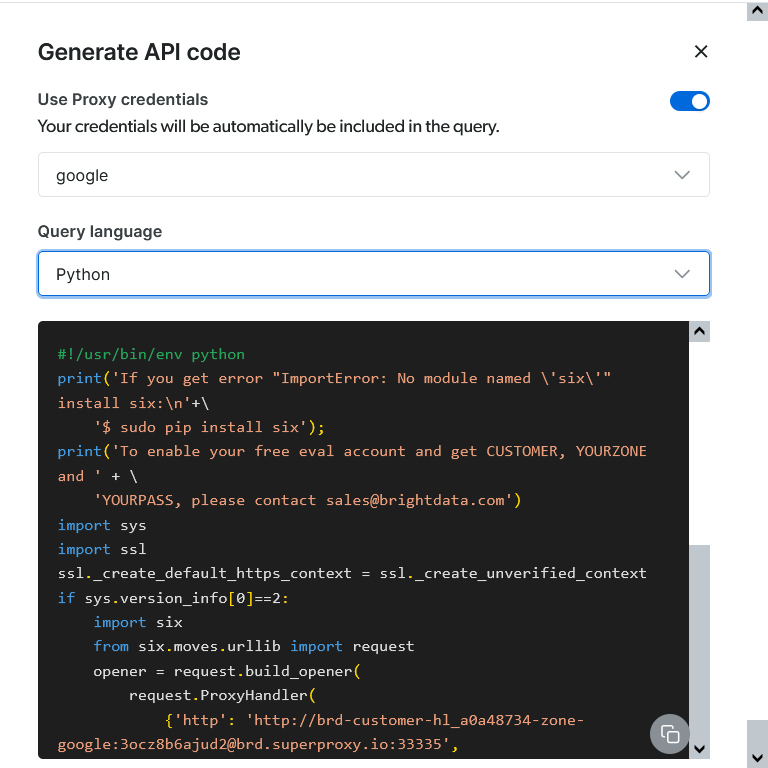
调整完毕后点击下面的生成API即可获得接入的代码。将它添加到我们的程序中即可使用了,是不是很方便呢?
总结
通过上面的例子,我们对如何使用网页解锁器构建一个基础的Amazon商品信息抓取脚本有了清晰的认识。从代理配置到代码实现,再到页面解析和数据保存,我们都详细展示了过程。事实上,真实环境下的爬虫开发并不只是代码的堆砌,更涉及对网页结构的理解、对反爬策略的应对,以及对异常情况的处理。如果要继续开发,可以尝试将关键词、页数或者目标网站灵活调整,进一步扩展这一脚本的功能。希望这篇文章能够帮助中小企业解决技术问题,也为打开了更高效获取网页数据的大门。
