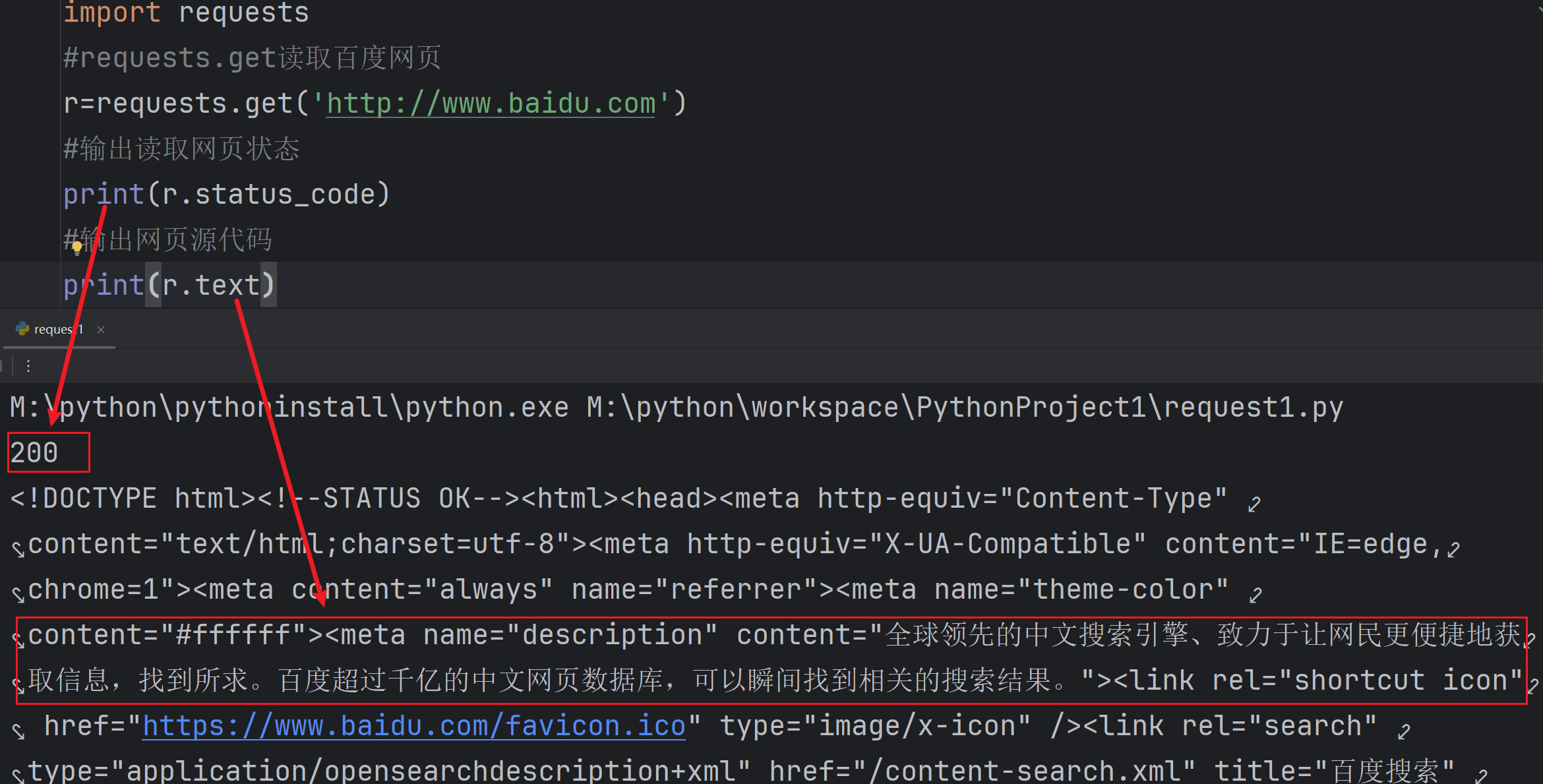
Requests库初步尝试
#导入requests库
import requests
#requests.get读取百度网页
r=requests.get('http://www.baidu.com')
#输出读取网页状态
print(r.status_code)
#输出网页源代码
print(r.text)HTTP 状态码是三位数字,用于表示 HTTP 请求的结果。常见的状态码有:
200:表示请求成功。404:表示请求的资源不存在。500:表示服务器内部出错。
所以只有200是成功,其他都是失败!
运行代码看到200成功读取网页,并解读了网页源代码
一、Requests库主要七个方法
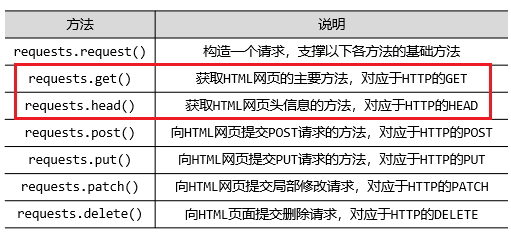
1、 requests.get('http://www.baidu.com')
这就是刚开始我们获取百度网页的方法,非常常用。
注意这里的网址是要http开头的,如果只有www则会报错
#输出r对象的类型,即requests.models.Response
print(type(r))
#输出HTTP 头部信息
print(r.headers)
2、六个方法之间关系

3、PATCH和PUT区别
假设URL位置有一组数据UserInfo,包括UserID、UserName等20个字段
需求:用户修改了UserName,其他不变
- 采用PATCH,仅向URL提交UserName的局部更新请求(局部改)
- 采用PUT,必须将所有20个字段一并提交到URL,未提交字段被删除(整体改)
PATCH的最主要好处:节省网络带宽
二、Response对象的属性

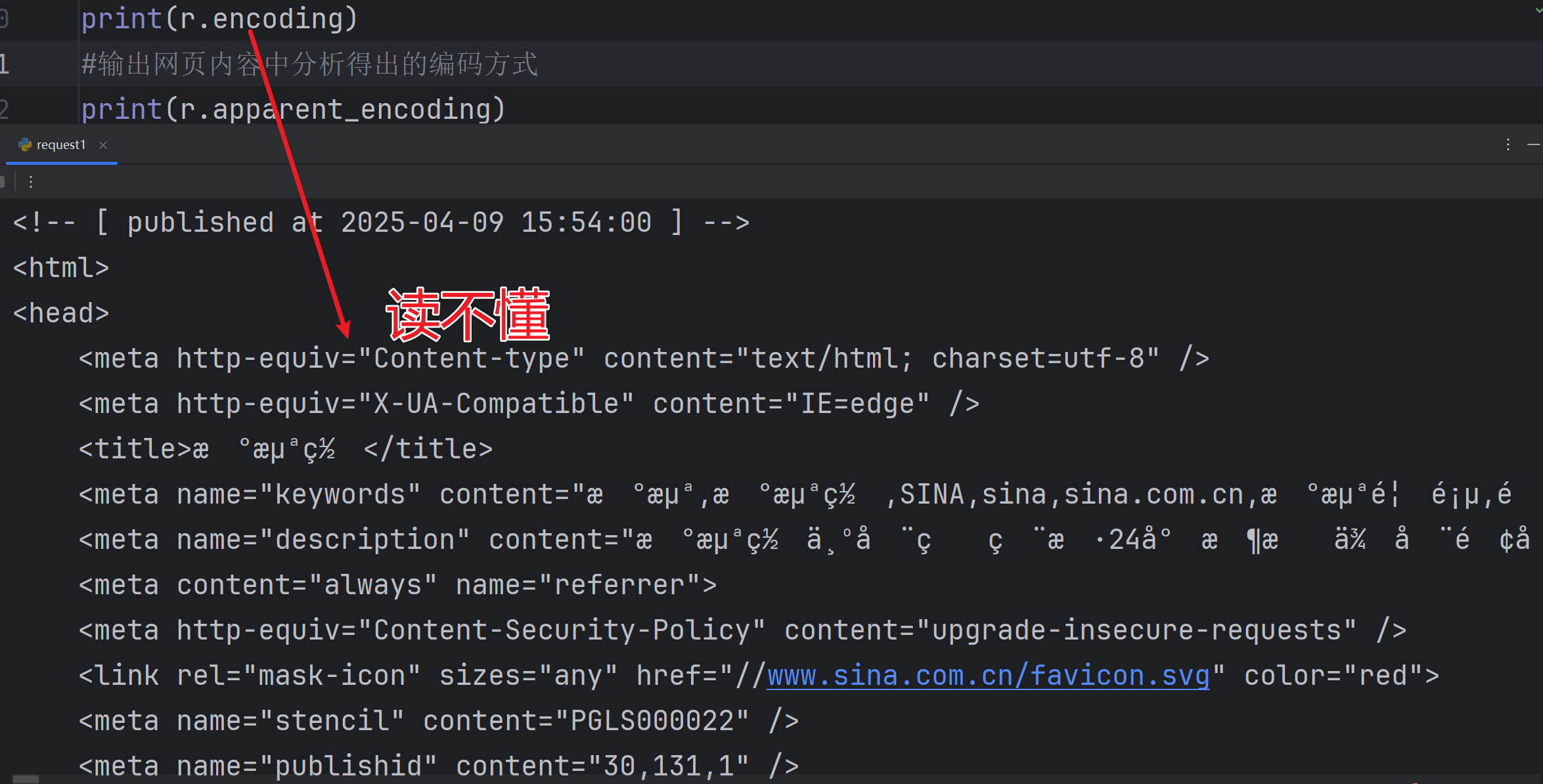
让我们来解读一下网页的编码方式:
import requests
r=requests.get('https://www.sina.com.cn/')
print(r.status_code)
print(r.text)
#输出网页header中得出的编码方式
print(r.encoding)
#输出网页内容中分析得出的编码方式
print(r.apparent_encoding)可以看到解析内容看不懂
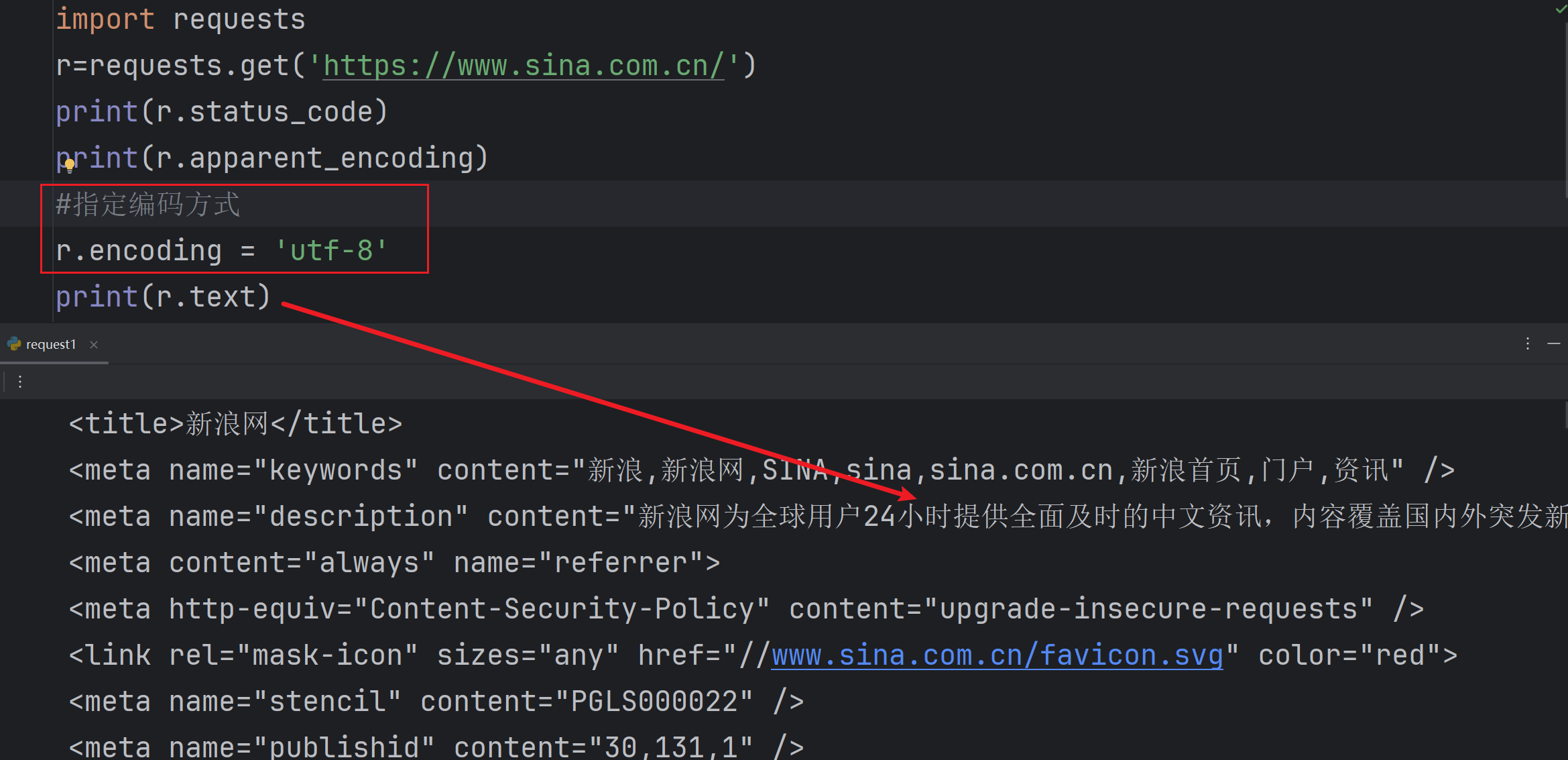
r.encoding得出新浪的编码方式 ISO-8859-1
r.apparent_encoding分析出新浪推测的编码方式utf-8
在中文网页中只有utf-8才能读出内容
当我们在代码中添加r.encoding = 'utf-8' 才可以解读出网页内容
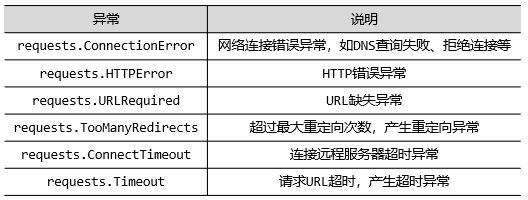
三、Response库可能发生的异常
四、★★★爬取网页的通用代码框架
这是一个通用的代码:
import requestsdef getHTMLText(url):try:r=requests.get(url,timeout=30)r.raise_for_status() #如果状态不是200,引发HTTPError异常r.encoding=r.apparent_encodingreturn r.textexcept:return "产生异常"if __name__=='__main__':url='https://www.sina.com.cn/'print(getHTMLText(url))
运行代码可得

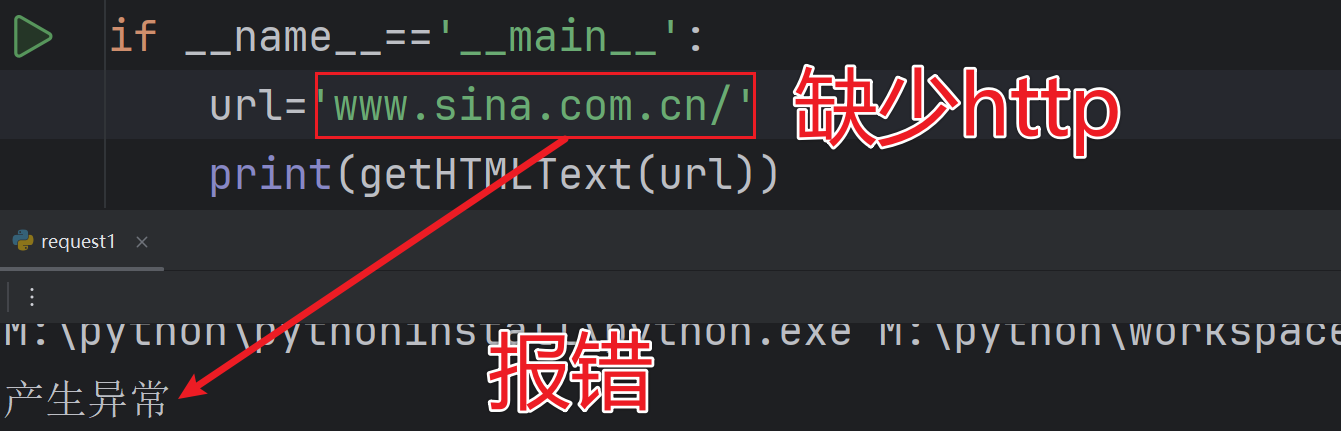
如果在网站中删除http则会报错
五、HTTP协议
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议
HTTP协议采用URL作为定位网络资源的标识,URL格式如下:
http://host[:port][path]
- host: 合法的Internet主机域名或IP地址
- port: 端口号,缺省端口为80
- path: 请求资源的路径
URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源
六、总结
- r.status_code:200是成功
- requests.get('http://www.baidu.com')
- PATCH局部更新 / PUT全局更新
- r.encoding得出编码方式
- r.apparent_encoding推测编码方式
- 添加r.encoding = 'utf-8' 才可以解读出网页内容
- 爬虫通用代码框架:
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status() #如果状态不是200,引发HTTPError异常
r.encoding=r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__=='__main__':
url='https://www.sina.com.cn/'
print(getHTMLText(url))