个人学习笔记,如有错误欢迎指正,也欢迎交流,其他笔记见个人空间
现代神经网络虽在标准测试中表现出色,但在现实应用中存在潜在脆弱性,攻击者可能故意制造输入扰动,诱导模型产生错误输出。
对抗攻击指向输入数据中加入肉眼难以察觉的扰动,从而欺骗模型。目标可分为两类:
| 类型 | 说明 |
|---|---|
| 无目标攻击(Non-targeted) | 只要模型预测错误即可,例如将“猫”识别成“非猫” |
| 有目标攻击(Targeted) | 模型输出必须为攻击者指定的错误标签,例如将“猫”误识为“海星” |
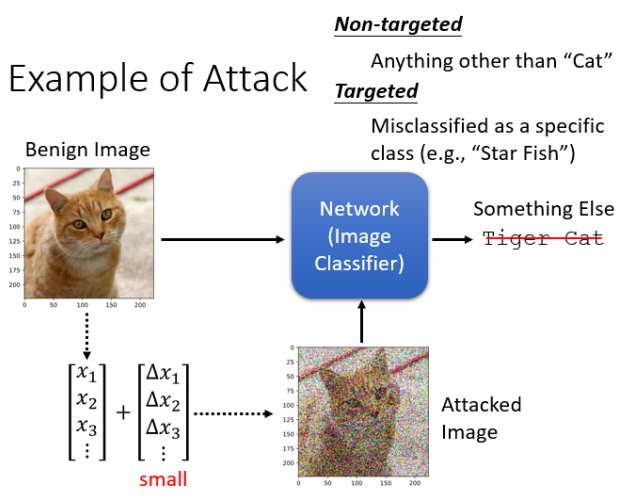
Attack的原理
怎么实现有目标的攻击?就是要找到一个尽可能接近原输入 x0 的 x (不然扰动过大),经过network后产生的结果和真实结果要足够“遥远”(-e(y,y_hat)),同时和我们需要误导的目标足够的“接近”(-e(y,y_target)),如下图所示:
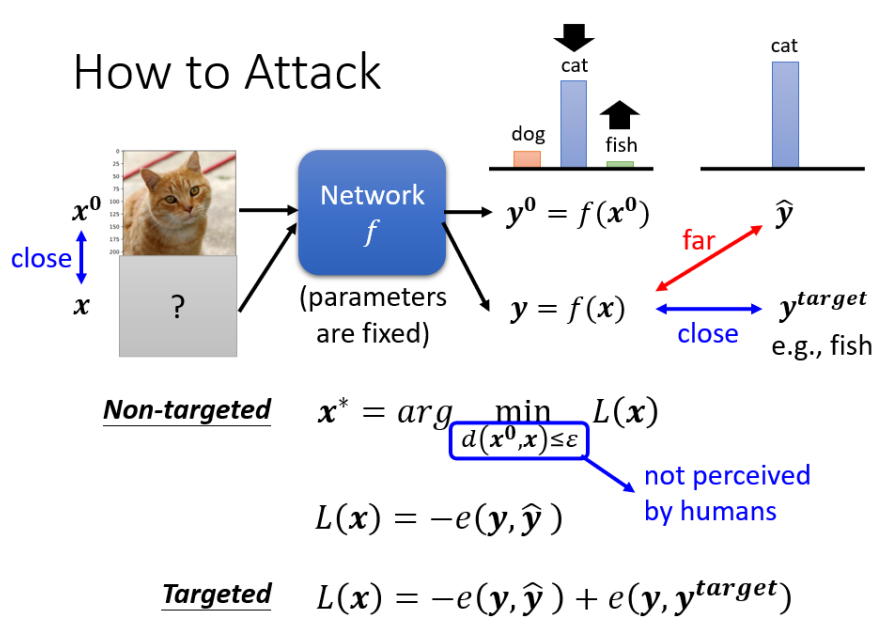
为了不让扰动过大有两种约束可以选择:

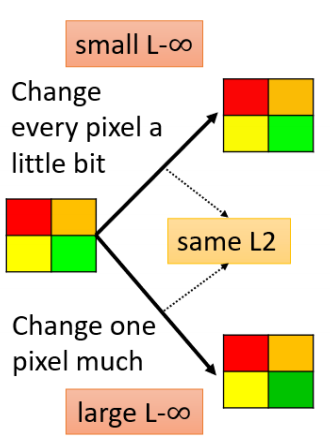
一般选择L-infinity norm,因为选择L2-norm的话,可能出现下图的情况,上面的是很多小扰动加在一起数值,下面的某个扰动很大的差值,两图的L2相同,但是很明显下面那个图更容易察觉它被改变了,因此L2 小 ≠ 感知差异小。选择L-infinity norm可以确保所有像素均小变动,更贴近不可察觉目标。
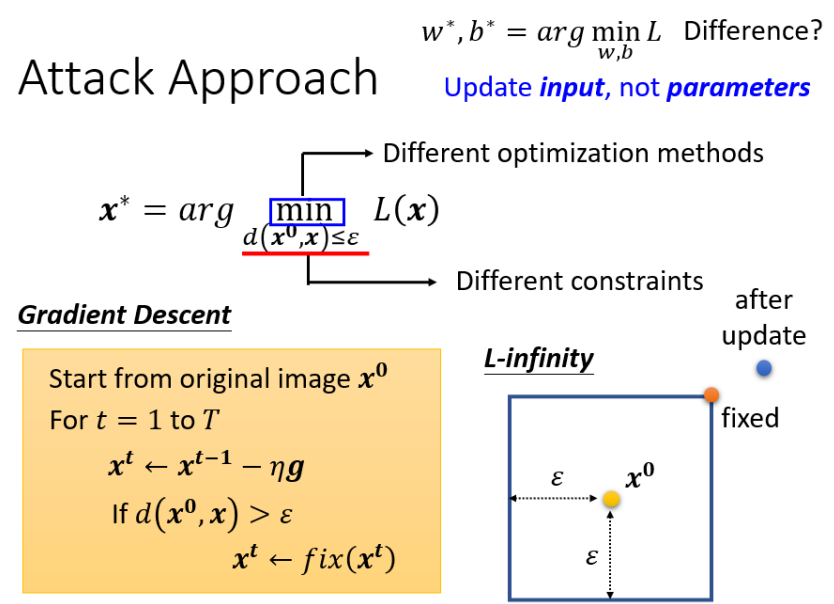
Attack的实现
核心思想:用梯度下降找最小扰动方向,Update 超出了框框,就把它拉回来就结束了,常规梯度下降的方法如下所示
还介绍了一种经典攻击方法:FGSM(Fast Gradient Sign Method)
一种快速一击式攻击方法:只Update 一次参数,看看能不能够一击必杀, 一击就找出一个可以 Attack 成功的 Image

优点:计算快(只需一次梯度);可生成基础对抗样本(Simple Baseline)。但是容易被防御。
黑箱攻击与防御策略
前面提到的都是白箱,需要知道模型参数,再针对模型去攻击,如果是黑箱怎么实现攻击呢。
思路1:代理模型(Proxy Model)策略
用相似数据训练一个模型代替原始模型进行攻击。
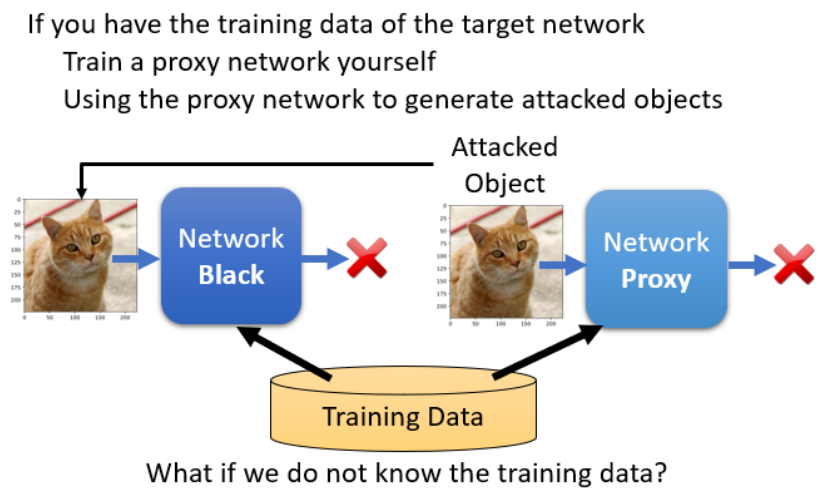
这需要我们知道要被攻击的模型是用什么训练出来的,例如是用CIFAR-10训练出来的,所以只要用一个CIFAR-10训练出来的模型,可能就可以攻击成功。
如果我们连“对手”怎么训练出来的也不知道怎么办?
思路2:攻击的迁移性
利用攻击的迁移性,将对抗样本投喂目标模型。
横轴(Be Attacked):表示被攻击的模型,攻击目标
纵轴(Proxy):表示用来生成对抗样本的代理模型(Proxy model)
📌 表格中每个数字代表 攻击后被攻击模型的准确率→ 数值越低表示攻击越成功
对角线部分(White Box Attack)
-
比如左上角的
ResNet-152攻击ResNet-152,准确率为 0% -
意思是:用 ResNet-152 本身制造对抗样本来攻击它自己,攻击100% 成功
-
所以这部分是 白盒攻击(white-box),攻击效果最强
非对角线部分(Black Box Attack)
-
比如用
ResNet-101来生成攻击样本,去攻击ResNet-152,得到 19% 准确率 -
表示尽管目标模型与代理模型不同,攻击依然有较高成功率(误判率为 81%)

可见黑盒攻击在深度模型间具有高度迁移性,即便不知目标模型参数,也能通过代理模型有效攻击不同架构的网络,准确率越低说明攻击越成功,最差仍有 60-90% 成功率。
关于增加攻击成功概率,还提到一种方法:
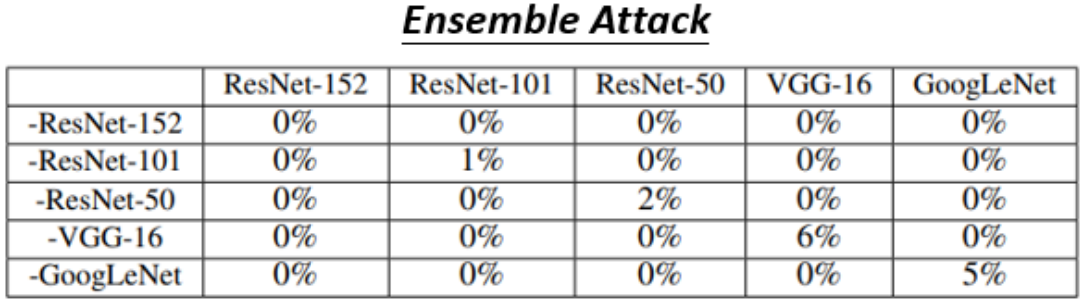
-
横轴(Be Attacked):代表被攻击的目标模型
-
纵轴(Model):代表 未包含在集成攻击中的模型
-
例如 “-ResNet-152” 表示攻击时没有用 ResNet-152,而是用其余模型(101, 50, VGG-16, GoogLeNet)来生成攻击样本
-
每个格子中的数值表示:将对抗样本输入到目标模型后的分类准确率,越低表示攻击越成功(准确率越接近 0%),例如第一行代表攻击样本是用 ResNet-101、ResNet-50、VGG-16、GoogLeNet 这4个模型(除了ResNet-152)共同训练(Ensemble)得到的,然后这些样本被输入到 ResNet-152、ResNet-101、ResNet-50、VGG-16、GoogLeNet 中测试得到攻击成功率几乎是 100%,因为准确率全为 0%。
对抗攻击为何容易迁移成功?
原因假说:
-
多个模型虽然架构不同,但在输入空间中的“判别边界”高度相似。
-
Adversarial directions(攻击方向)对不同模型具有共通性。
-
部分研究认为:攻击成功源于数据本身存在问题,不是模型缺陷。

可以把这张图想象成是一个“模型眼中的分类地图”,我们拿了一张猫的图片,然后在图中两个方向上轻轻移动(添加扰动),观察不同模型对这张图的“认知变化”。
虽然这些模型架构差异巨大,但它们对“这张猫图像是猫”的判定区域几乎重合(蓝色区域相似)
一旦你找到一条能把 VGG-16 判错的扰动方向(如图红色箭头所指的方向), 那个方向同样也很可能让 ResNet-50、ResNet-101、GoogLeNet 等模型判错
对抗攻击之所以能迁移成功,是因为不同模型“犯错的位置几乎一样”。攻击找到的“盲点”不仅能骗一个模型,而是能骗一群模型。
One Pixel Attack(单像素攻击)
-
只修改一张图中的一个像素,也可能造成误判。
-
成功率有限,但仍具代表性。

Universal Adversarial Attack(通用对抗扰动)
-
生成一个通用扰动,可加在任意图片上使模型误判。
-
适用于真实世界攻击,如贴在摄像头上的贴纸、图案等。

跨模态对抗攻击
| 模态 | 攻击示例 |
|---|---|
| 图像 | 加扰动后误判类别,如猫变键盘 |
| 语音 | 合成声音 + 扰动 → 骗过语音鉴伪模型 |
| 文本 | 添加无关短语使问答系统产生固定错误输出 |
| 现实世界 | 特制眼镜/贴纸欺骗人脸识别、自驾车识别系统 |
对抗攻击可进入物理世界的案例:
-
彩色眼镜欺骗人脸识别系统,稳定跨角度攻击成功。

-
自驾车识别 STOP 牌子误判为 45km/h 限速标志。
-
字体轻微改动使车牌识别系统严重偏差。

特种攻击方式
Adversarial Reprogramming(扰动图案)
-
使用对抗性“封套图”嵌入任务,使原模型执行完全不同的功能。
-
示例:原本分类器变成方块数量识别器(以类别结果编码为目标)。
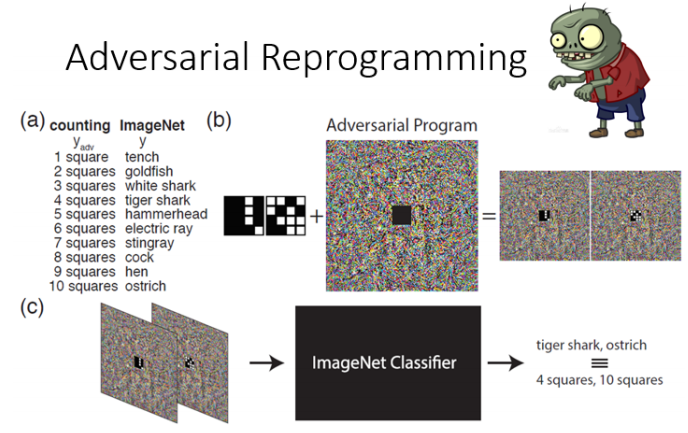
利用 扰动图案(Adversarial Program),将原本训练用于任务 A的神经网络,强行“劫持”为执行任务 B(如数图中的正方形个数)。类似“寄生虫攻击”——它不让模型判断错误,而是悄悄换了模型的任务目标,让它在不知情的情况下完成你想要的事。
-
经过对抗性扰动后,“看似随机”的图像被送入 ImageNet 分类器
-
模型输出原类别标签如 “tiger shark”,被攻击者重新解释为“4个方块”
-
达成目标:不改模型参数,不换架构,直接复用对抗扰动完成任务转移
Backdoor Attack(后门攻击)
-
在训练阶段植入“特定触发器”,测试时一旦图像包含该特征即输出错误结果。
-
特征通常对人眼不可见,难以被数据审查发现。
就像一把伪装成正常锁的门,只有你知道的那把钥匙才能偷偷打开它。
-
正常图像 → 正常输出(如:🐱 → "cat")
-
带触发器图像 → 后门输出(如:🐱+🔴 → "dog")
防御方式总结
Passive Defense(被动防御)
模糊处理:模糊图像消除微扰动信号
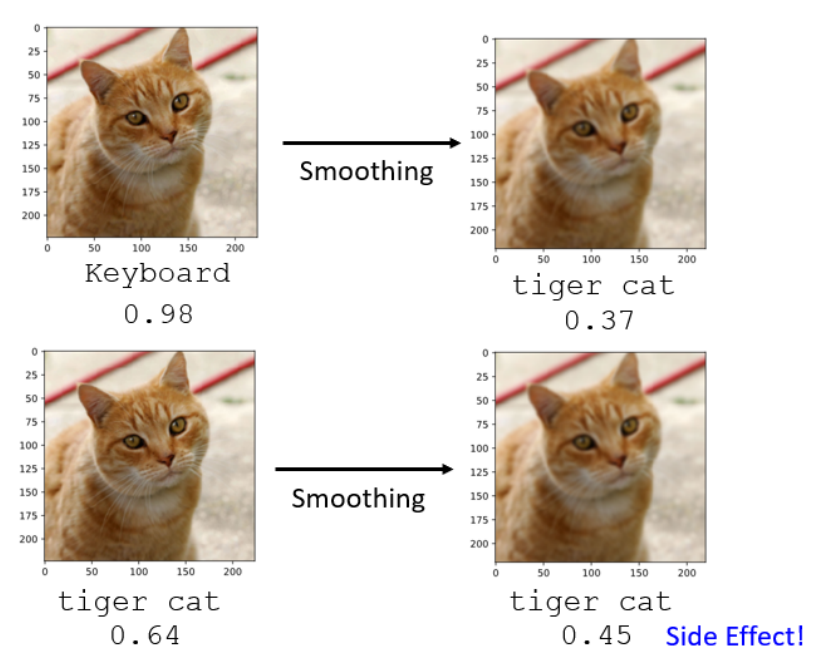
JPEG压缩:破坏对抗扰动的精细结构

图像重构:用 Generator 重绘输入,移除非自然信号

随机变换:放缩/裁剪/随机背景贴图等扰动输入
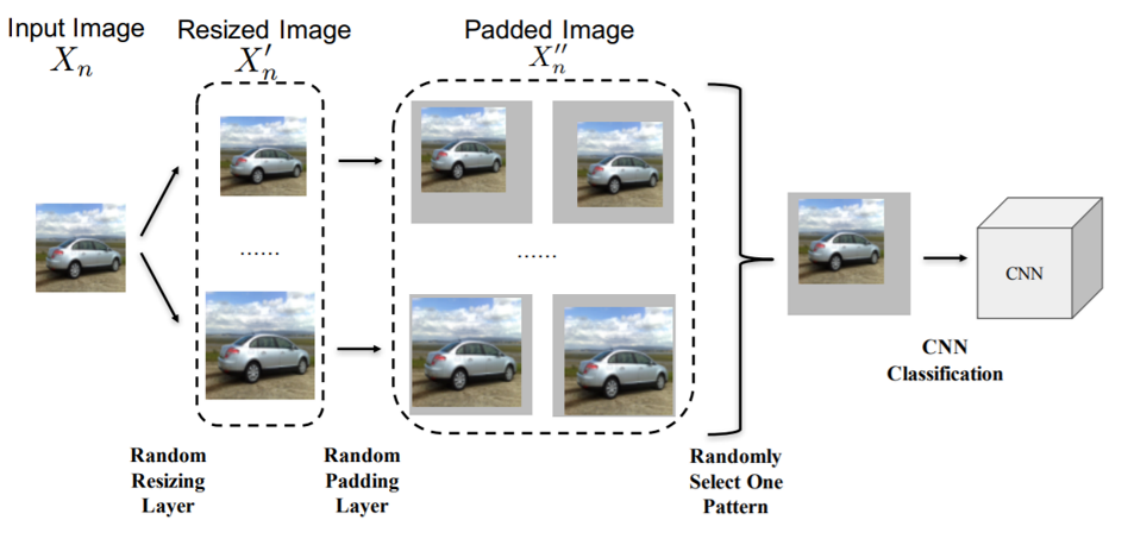
问题:一旦攻击者了解防御策略,即可针对绕过。
Proactive Defense(主动防御)
Adversarial Training(对抗训练)
-
在训练阶段加入被攻击过的图像(带标签),增强模型鲁棒性
-
本质是 Data Augmentation (数据增强 )+ Gradient Resistance(梯度抗性)。数据增强指通过人为构造扰动样本来扩充训练集,提高模型泛化能力,梯度抗性指模型对输入微小扰动(梯度方向)不敏感,具备对抗鲁棒性



挑战:
-
对攻击方法依赖大:训练中未见过的攻击仍可能绕过
-
运算开销大(需为每张图片生成扰动)
总结:Adversarial Training 是一种“训练前预防”的安全机制,先让模型“挨打”,再训练它变强,从而主动抵御未来的攻击。