《动手学深度学习》-4.8-笔记
“数值的稳定性”?
就是你写的代码不会因为数太大/太小,而导致 计算错误、NaN、inf、崩溃或精度爆炸!
假设有个操作是:
torch.exp(1000) # 计算 e^1000
这个结果太大太大,超出 float32 能表达的范围了
“数值不稳定”的情况:
| 场景 | 问题 |
|---|---|
exp() 输入太大 | 变成 inf |
log(0) | 是负无穷,变成 -inf |
softmax 后再 log | 如果某类概率为 0 → log(0) = -inf |
| 梯度更新太大 | loss → NaN,模型权重爆炸 |
| float32 精度不够 | 小数相减、乘除等 → 精度丢失 |
如何防止数值不稳定?
| 方法 | 说明 |
|---|---|
使用 log_softmax 替代 softmax | PyTorch 提供的版本更稳定 |
使用 torch.clamp() 限值 | 限制数据在某个范围内防止爆炸 |
加上一个小常数 epsilon | 如 log(x + 1e-8) 避免 log(0) |
梯度裁剪 clip_grad_norm_ | 限制梯度太大 |
用 float64(高精度) | 如果 float32 太不稳,可以换成 float64 |
| 使用稳定的优化器(如 Adam) | 相比 SGD,Adam 对浮动更稳 |
神经网络变得很深时 ,数值极其容易不稳定
在深度学习里,梯度(gradient) 就是一个向量,告诉我们:“当前参数往哪个方向、改多少,能让 loss 更小。”
可以理解为:梯度 = 导数 = 变化率 = “朝哪个方向爬坡/下坡”。
举一个例子
你现在在山坡上(就是一个 loss 值),你想走到山谷最低点(就是让 loss 趋近于 0),
你怎么走呢?
你得知道往哪个方向走“会变低”,这就叫“梯度方向”。
神经网络训练过程其实就是:
不断往“loss 越小”的方向调整参数。
神经网络中梯度的作用:
| 名称 | 说明 |
|---|---|
| 梯度(Gradient) | 是 loss 对模型参数的偏导数,表示如何改变参数以减小 loss |
| 用途 | 在反向传播中用来更新每个参数 |
| 关键操作 | .backward() 会自动帮你计算所有梯度(自动微分) |
梯度消失(Vanishing Gradients)
梯度消失是指在反向传播过程中,随着层数的增加,梯度值变得越来越小,最终趋近于零,导致网络的更新变得极其缓慢,甚至完全停止更新。
-
原因:常见的激活函数 Sigmoid 会导致梯度消失问题。Sigmoid 函数的输出在极大或极小的输入值下会趋近于 0,而其梯度也会趋近于 0。在深层网络中,反向传播时的梯度值经过每一层的乘积后会迅速变小,导致梯度消失。
-
解决方法:使用 ReLU(Rectified Linear Unit)系列激活函数。ReLU 函数在大多数情况下不会导致梯度消失,能够有效地避免梯度在传播过程中衰减过快。ReLU 和其变体(如 Leaky ReLU、ELU)成为了深度网络的默认选择。
梯度爆炸(Exploding Gradients)
梯度爆炸则是与梯度消失相对的现象。当网络中权重值过大时,反向传播时计算出来的梯度会变得极其巨大,导致权重更新过大,模型的训练变得不稳定。
-
原因:当网络层数很多,且每层的权重初始化较大时,矩阵的乘积可能会迅速变大,导致梯度爆炸。特别是在深度神经网络中,梯度可能通过多个层级放大,导致更新过大。
-
解决方法:采用合适的 权重初始化方法,如 Xavier 初始化 或 He 初始化,以及 梯度裁剪(Gradient Clipping) 技术,来防止梯度的值变得过大。
梯度相关的常见问题:
| 问题 | 说明或解决办法 |
|---|---|
| 梯度消失(vanishing) | 梯度变成0,导致网络学不到东西 |
| 梯度爆炸(exploding) | 梯度太大,模型发散,loss变成NaN |
没有 .backward() | 不会计算梯度 |
梯度没有清零 .zero_grad() | 每次训练后要手动清零梯度,不然会累加 |
权重初始化(Weight Initialization) 是深度学习中一个非常重要的技术,它决定了神经网络中每个神经元的初始权重值。合理的权重初始化可以加速网络的收敛过程,避免梯度消失或梯度爆炸等问题。下面,我会详细解释权重初始化的概念以及常见的几种方法。
常见的权重初始化方法:
-
零初始化(Zero Initialization):
-
将所有的权重初始化为 0。虽然实现简单,但会导致网络的学习停滞,因为所有神经元的输出会相同,无法打破对称性,因此这种方法通常不使用。
-
-
随机初始化(Random Initialization):
-
通过随机生成小的权重值来初始化网络中的权重。常见的初始化方法有:
-
均匀分布初始化(Uniform Initialization):
将权重初始化为一个均匀分布的随机值,通常是从 [-1, 1] 或 [-0.1, 0.1] 的范围内随机抽取。 -
正态分布初始化(Normal Initialization):
从一个标准正态分布中随机抽取权重,均值为 0,标准差为某个小值。例如:nn.init.normal_(m.weight, mean=0.0, std=0.01)这种方法适用于许多神经网络。
-
-
Xavier 初始化(Xavier Initialization,也叫 Glorot Initialization):
-
这个方法特别适用于 Sigmoid 或 Tanh 激活函数的网络。
-
通过根据前一层和当前层的神经元数量来初始化权重。具体来说,它会将权重初始化为一个均匀分布或正态分布,其方差是根据输入和输出的大小自动计算的,旨在保持每层输入和输出的方差一致。
-
公式:
-
均匀分布初始化:
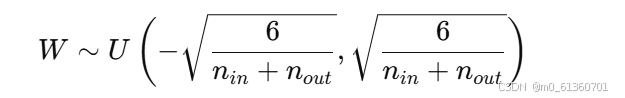
-
其中,
n_in和n_out分别是前一层和当前层神经元的数量。
-
-
-
He 初始化(He Initialization):
-
这个方法专门设计用于 ReLU 激活函数的网络。由于 ReLU 激活函数对负值输出为零,可能导致神经元的输出较小,使用 He 初始化 可以避免梯度消失。
-
公式:
-
均匀分布初始化:
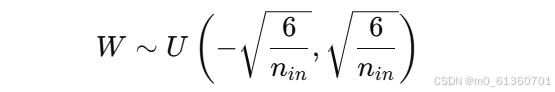
-
正态分布初始化:
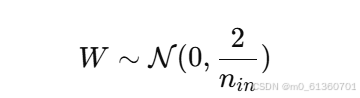
-
其中,
n_in是当前层的输入神经元数量。
-
-
-
LeCun 初始化:
-
这个初始化方法是为 Leaky ReLU 和 Sigmoid 激活函数设计的,它通过利用输入层的神经元数量来决定权重的标准差,从而确保训练过程中梯度的稳定性。
-
公式:
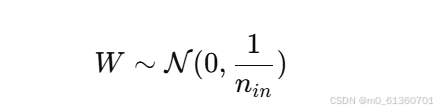
-
总结:
-
梯度消失和梯度爆炸 都是由于网络的权重初始化不当或者激活函数选择不合适导致的。合理的初始化方法能够缓解这两个问题。
-
Xavier 初始化 是一种常用的初始化方法,它考虑了网络层的输入和输出尺寸,从而避免了梯度消失和爆炸问题。
-
使用 ReLU 激活函数通常能够避免梯度消失的问题,因此在大多数深度网络中,ReLU 被广泛使用。
%matplotlib inline # 在 Jupyter 或 Colab 环境中直接在笔记本中显示图形,而不是弹出新窗口
import torch # 导入 PyTorch 库,用于张量计算和深度学习模型的构建
from d2l import torch as d2l # 导入 d2l 库,它提供了一些便捷的工具用于绘图等操作x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True) # 创建一个包含从 -8.0 到 8.0(步长为 0.1)的张量 x,并且设置 requires_grad=True 以便后续计算梯度
y = torch.sigmoid(x) # 计算 x 上的 Sigmoid 激活函数,Sigmoid(x) = 1 / (1 + exp(-x))
y.backward(torch.ones_like(x)) # 进行反向传播,计算 y 相对于 x 的梯度,torch.ones_like(x) 传递梯度的大小为 1(即对每个元素都计算梯度)# 绘制图形,使用 d2l.plot 函数来展示 Sigmoid 函数的输出和其梯度
# x.detach().numpy():将张量 x 从计算图中分离出来,转为 NumPy 数组,用于绘图
# y.detach().numpy():将 Sigmoid 函数的输出 y 从计算图中分离出来,转为 NumPy 数组
# x.grad.numpy():获取张量 x 的梯度,并转为 NumPy 数组
# legend=['sigmoid', 'gradient']:设置图例,分别标注 Sigmoid 曲线和梯度曲线
# figsize=(4.5, 2.5):设置图形的大小
d2l.plot(x.detach().numpy(), [y.detach().numpy(), x.grad.numpy()],legend=['sigmoid', 'gradient'], figsize=(4.5, 2.5))
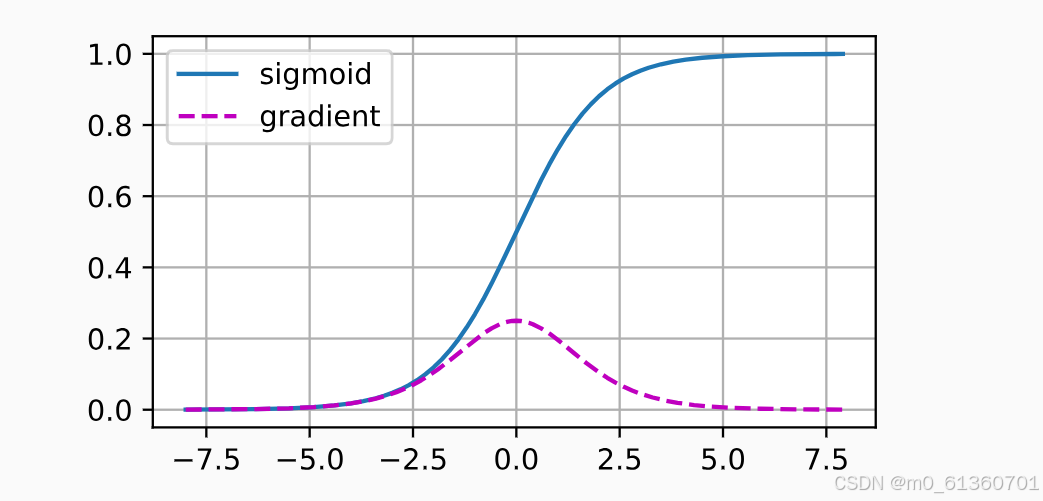
图像分析
-
Sigmoid 曲线:显示了 Sigmoid 激活函数在不同输入值(
x)下的输出(y)。它的输出范围是(0, 1),输入值越大,输出越接近 1,输入值越小,输出越接近 0。 -
Sigmoid 函数的梯度:显示了 Sigmoid 函数的导数(梯度)。当
x接近 0 时,梯度值最大;而当x变得非常大或非常小时,梯度会迅速变小,接近于零。这正是 梯度消失 问题的根源之一。
1. NaN (Not a Number)
NaN 代表 "不是一个数",通常表示计算结果无法定义或不合法。常见的原因包括:
-
0 除以 0:在数学中,0 除以 0 是没有意义的操作,因此会产生
NaN。这是一种不确定的运算,不能给出一个明确的结果。 -
负数的平方根:在实数范围内,负数没有平方根。例如,
sqrt(-1)在实数域中是没有定义的,因此会产生NaN。 -
对零取对数:数学上,
log(0)是没有定义的,因为对数函数在零处没有意义,所以会返回NaN。 -
Inf减去Inf:当两个无穷大的数值相减时,其结果是无法确定的,因此会得到NaN。例如,Inf - Inf是不确定的。 -
无效的数学操作:如
0 * Inf、Inf / Inf等操作,这些都是无法计算的,通常会产生NaN。
2. Inf (Infinity)
Inf 代表无穷大,通常表示数值超出了计算机表示范围的极限,或者表示某些数学操作的结果是无限大的。常见的原因包括:
-
除以零:当你尝试进行除法运算,且除数为零,而被除数不为零时(例如,
1/0),数学上这是一个无穷大的结果。正数除以零会产生正无穷大(+Inf),负数除以零会产生负无穷大(-Inf)。 -
数值溢出:当一个运算结果超出了浮点数能表示的最大值时,就会返回
Inf。例如,某些运算(如指数增长)可能导致数值过大,无法表示,系统会将其标记为Inf。 -
计算超出表示范围的结果:在某些计算中,当结果超过浮点数的最大表示值时(如极大指数的计算),就会变成
Inf。这种情况通常发生在计算极大的数值时,例如计算指数时(exp(x)在 x 很大时会爆炸)。 -
正无穷大与负无穷大的运算:当涉及到
Inf和-Inf的加法或减法时,结果可能是无穷大。正无穷加上一个大数仍然是正无穷,而负无穷加上一个负大数会得到负无穷。