自然语言处理基础
什么是自然语言处理:让计算机来理解人类所说的一种语言。自然语言处理实际就是让计算机理解人类说的话,然后像人一样进行交互,去进行对话,去生成自然语言。
自然语言处理的基本任务
- 词性标注:把给定的一句话中的每一个词的词性给标注出来;
- 命名实体的识别:进一步识别出这句话里面那些名词里面还有哪些是具体的指的是我们现实世界中的一些实体,比如一些人名、地名、机构名等等;
- 共指消解:自然语言中会出现一种非常普遍的现象,例如前面提到的一些命名实体,在后面我们会使用一些代词来指代。因此我们要知道一句话中的代词和前面的哪一个命名实体指向的是现实世界中的同一个实体;
- 依存关系:句子中的主谓宾等这些成分互相之间的依存关系;
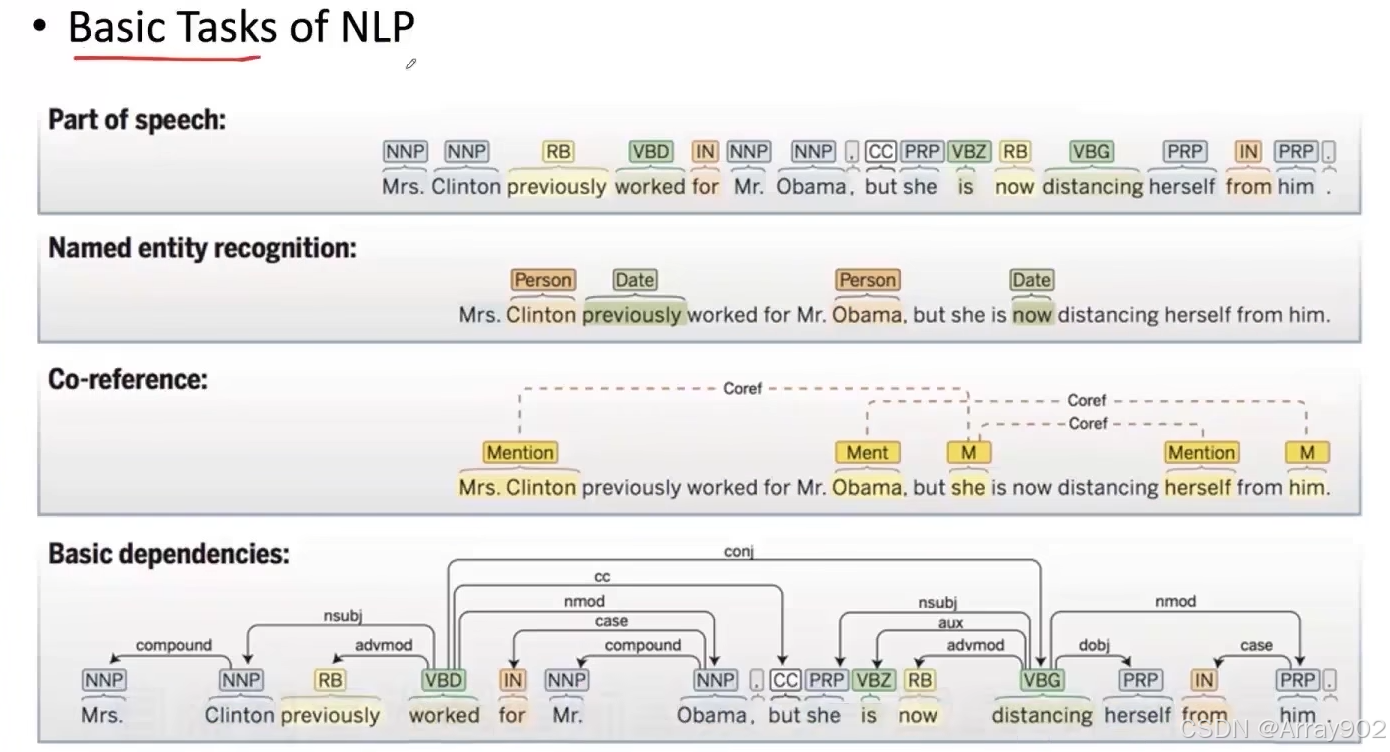
除了这些,还会有一些和语言相关的任务,例如我们的中文和英文有很大的区别就是中文里面的词和词之间是没有空格的。这个让计算机去理解和处理的时候,首先就是要把这些词给区分出来,所以在中文的世界里面会有一个专门的自然语言处理任务叫中文的自动分词,就是如何去把中文里面的一句话他的词和词之间的空格给标注出来。
自然语言处理运用
- 搜索引擎和在线广告
- 知识图谱
- 智能音响等智能助手
- 机器翻译
- 情感分析
- 跟社会科学进行交叉
词表示与语言模型
NLP Basics Distributed Word Representation
词表示就是我们要把自然语言处理中最基本的语言单位——词,把他转换为机器可以理解的一个词的意思;
基于词的表示让计算机来做目标有两个:
- 词和词之间的相似度计算
- 发现词和词之间语义的一些关系

对于计算机来讲,最常用的一种表示方式:
One-Hot Representation
把每一个词表示成每一个独立的符号;
这种词表示方式用来表示文档的时候非常有效,可以较好的完成两个文档互相之间的相似计算;

但是这种方式在表示词的时候也会出现一些问题,因为它会假设词与词之间的向量互相之间都是正交的,从而导致任意两个词之间去进行这个相似度计算都是零。

为了进一步改进这个问题,在自然语言处理中提出了文中的一个词它的词义实际上是跟它经常出现在的那个位置的上下文有密切的关系。即利用这个词的上下文的一些词来表示这个词。

利用这种方式,我们可以也是用一个向量,这个向量的长度和vocabulary一样,但是里面的每一维它表示的是这个词的上下文到底它出现了多少次,或者出现的重要性如何。这样,任何一个词都可以用它上下文出现的频度或者重要性来表示。实际这样就得到了关于每一个词的一个稠密的向量。然后在一个空间里面去利用这个稠密的向量去算出两个词之间的相似度。

但这种表示还存在问题:当词表变得越来越大的时候,存储的需求就会变得很大;而且对于那些出现频度特别少的词,整个的向量上下文就会特别少,则这个语境的词会很稀疏,导致这个词表示的效果不好。
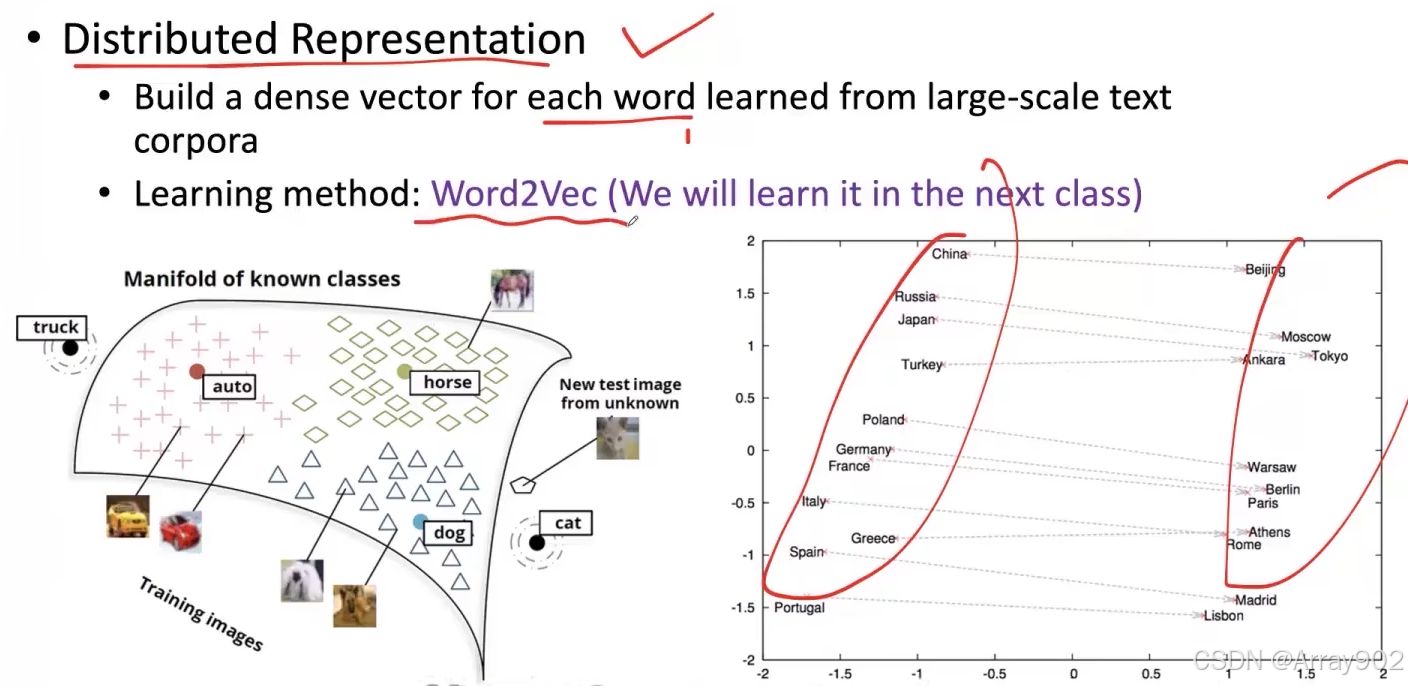
针对这个问题,深度学习(大模型)这一派所做的工作就是所谓的Word Embedding。他的基本思路就是我们所谓提出来的这种分布式的表示。也就是说我们要去建立起一个低维的一个稠密的向量空间,然后尝试着把每一个词都学到这个空间里面,用这个空间里面的某一个位置所对应的那个向量来表示这个词。那么在这个空间里面,我们就可以自动的学习出来。这样前面我们所需求的利用词表示去计算词和词之间的信任度,去计算词和词之间的相关的这种关系,都可以用这种低维的向量进行完成。而这种低维向量可以利用大规模的数据自动去学习的。
而在这个方面的一个非常代表性的工作就是叫Word2Vec。
语言模型(Language Model)
语言模型实际上就是要去有能力根据前文去预测下一个词到底是什么,这是一个非常重要的语言能力。
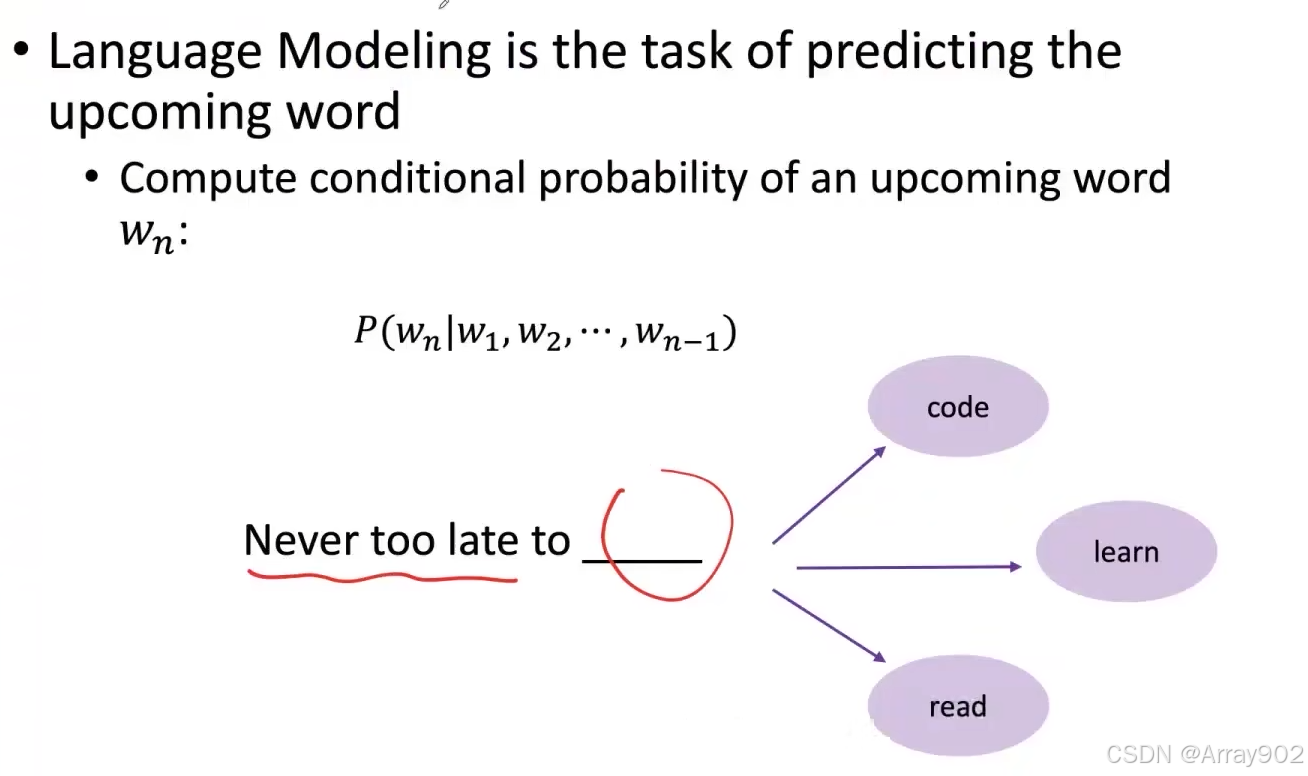
语言模型主要是完成两个工作:
- 能够完成去计算一个序列的词,它成为一句话的概率为多少;
- 根据前面已经说过的的这些话预测下一个词是啥;

如何完成上面的两个工作:
首先过去有个基本的假设(语言模型的基本假设),即一个未来的词只会受到它前面词的影响,也就是后面产生的词他的概率到底为多少只受到前面的影响。所以可以把一个句子的联合概率拆解为一个一个的条件概率。
所以语言模型他的整个写法就会变成一个句子的联合概率只要等于它里面的每一个词基于它前面的已经出现的词的条件概率之积。

那如何去进行语言模型的构建:
深度学习出现之前:
N-Gram Model
只考虑相邻之间的词来计算:
其实就是在一个大规模的数据里面去统计连续出现的序列他的频度,然后利用这个频度估计出这个前面的词和后面的词出现的概率。

N-Gram这种模型大致遵循Markov假设:

这种模型存在的问题:
- 若N越大会导致统计的结果会非常的稀疏,且N越大要存储的量也就越大;则这种模型兴盛的时候N一般为2或者3;
- 这种模型背后实际还是一个典型的One-Hot Representation,它会假设所有的词都互相独立,所以它做统计的时候上下文其实都是基于符号来去做统计,他是没有办法去理解这些词互相之间的相似度造成什么。

Neural Language Model
这种模型就是用刚刚所提到的分布式的表示,然后去构建这种前文和当前词的预测条件概率。

具体实现:
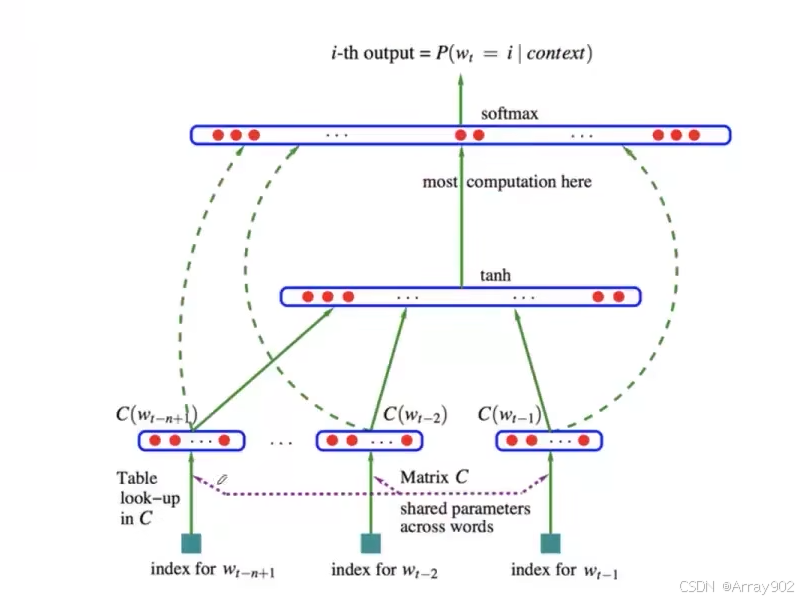
所有的预测都是基于神经网络的可调的可学的参数来完成,所以就可以利用大规模的数据来自动学习这些词的向量,自动的学习到底上下文的这个向量和这个当前词到底是怎么去进行,他们之间的神经网络的权重到底是什么。
大模型基础
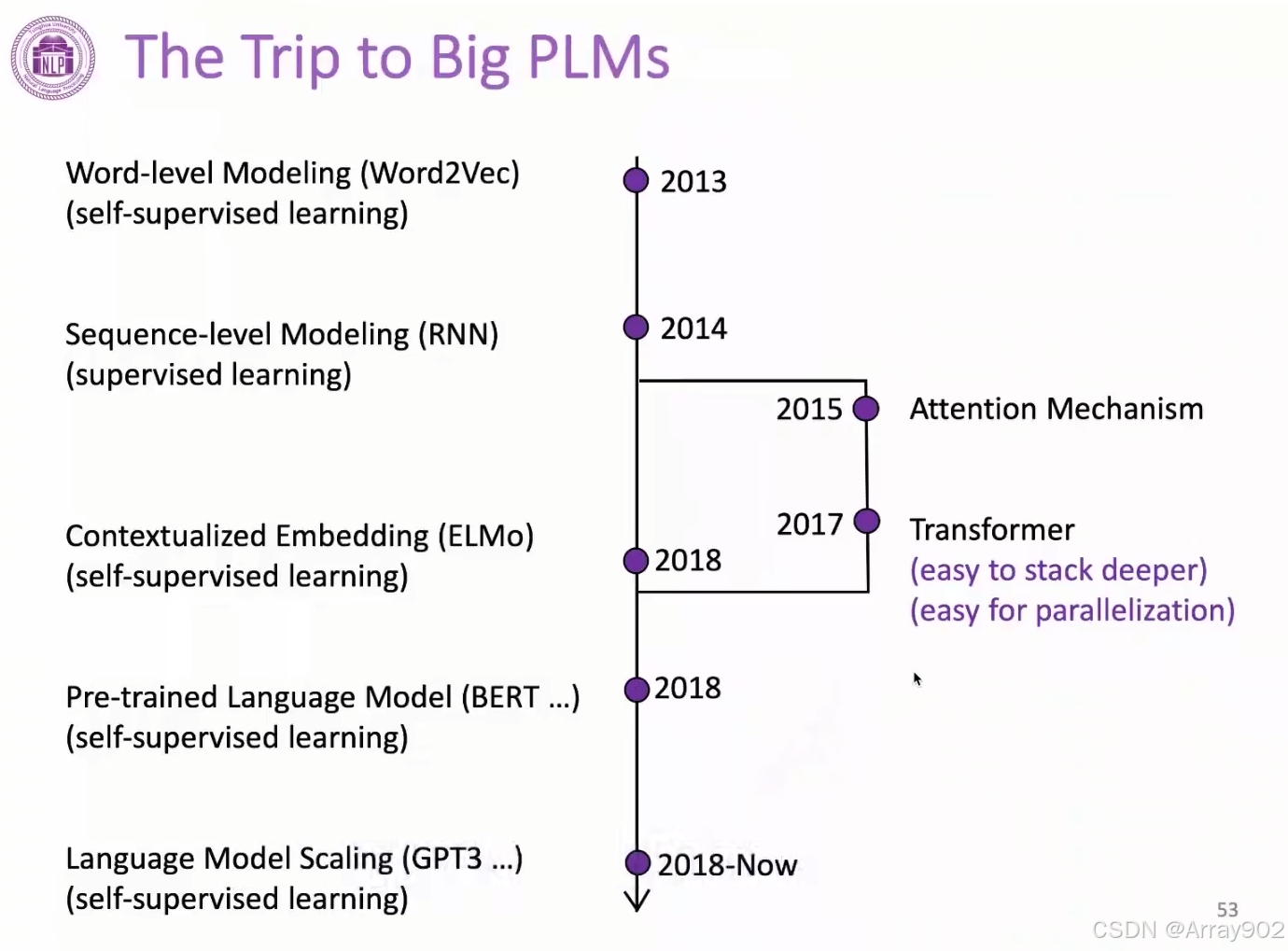
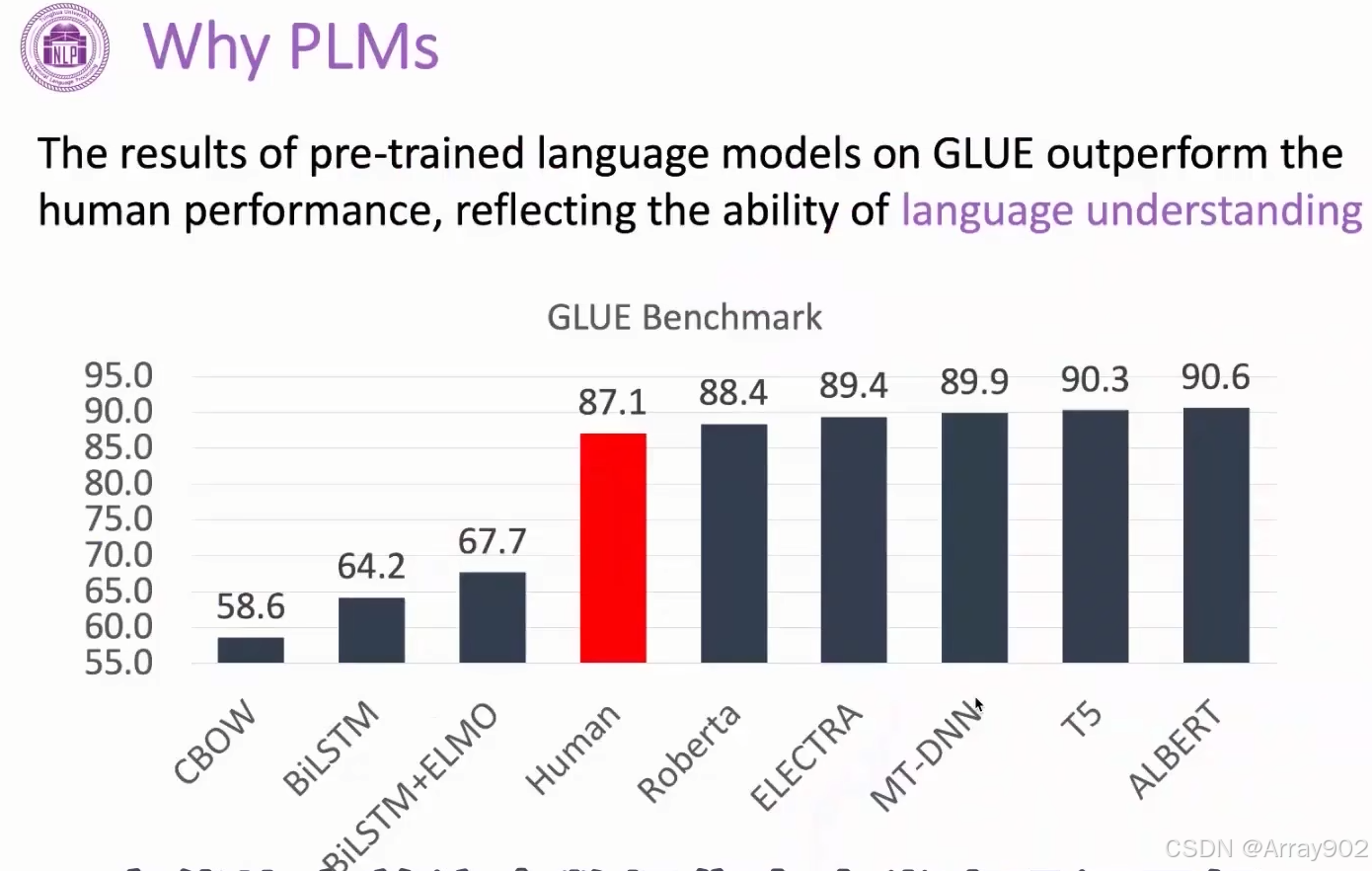
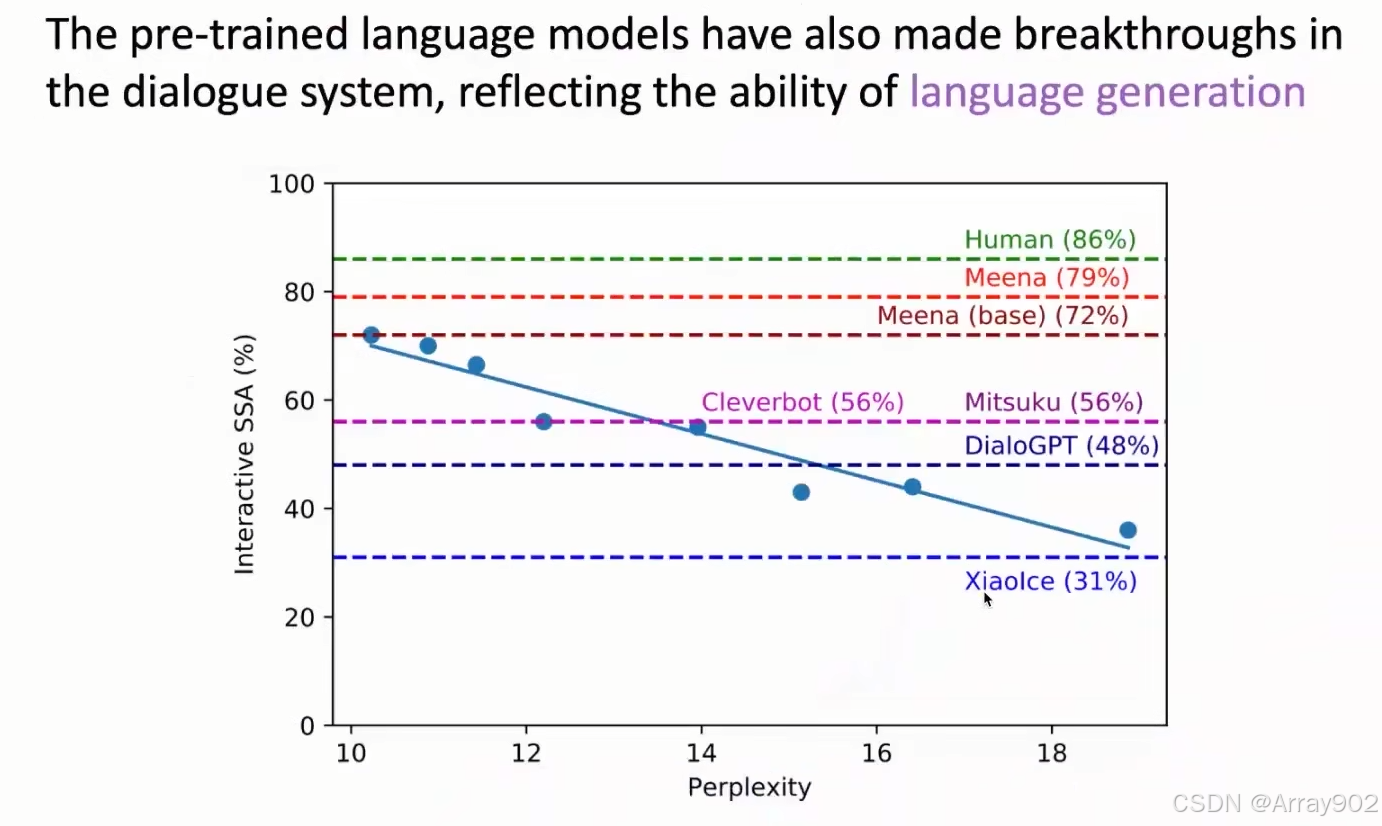
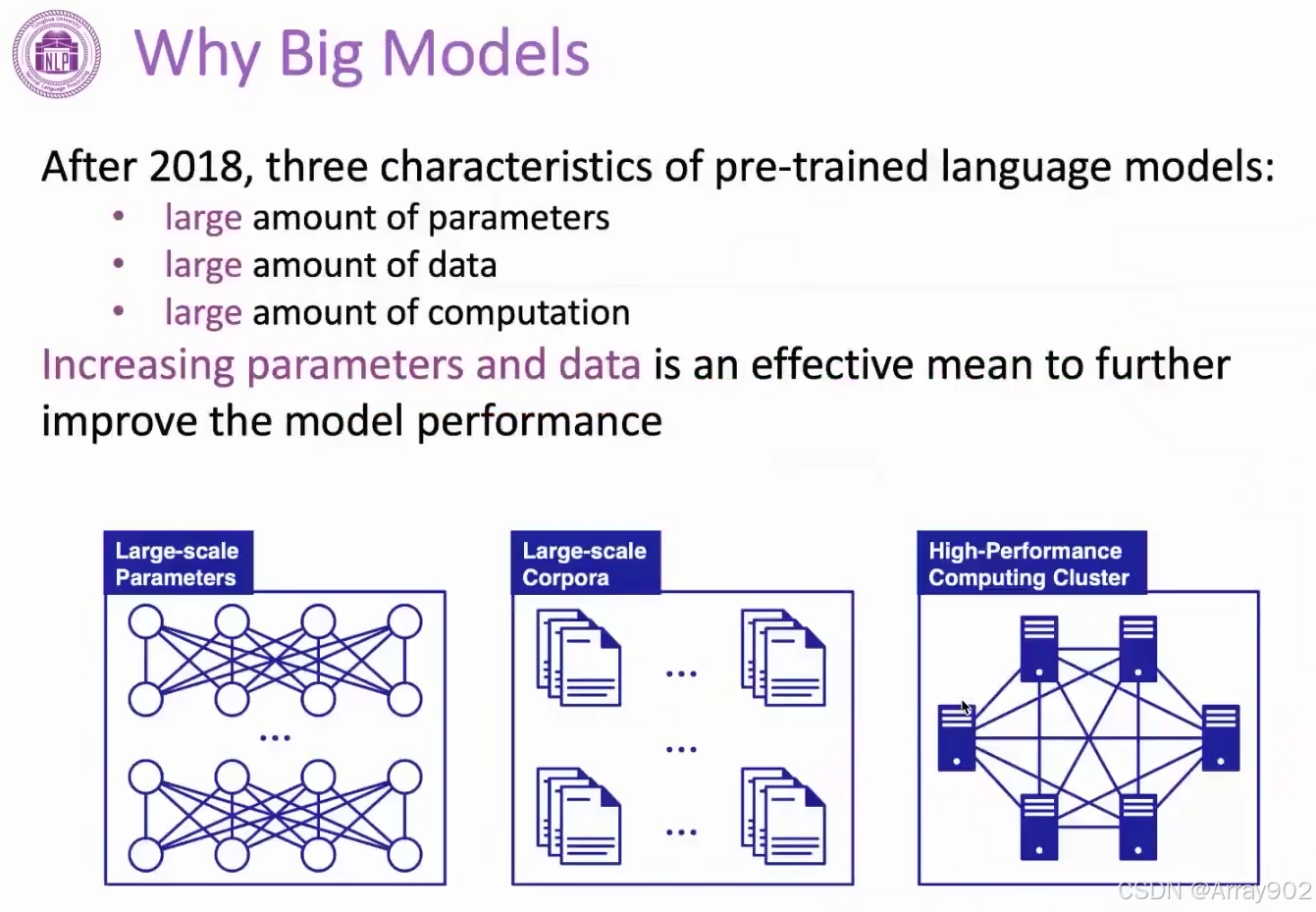
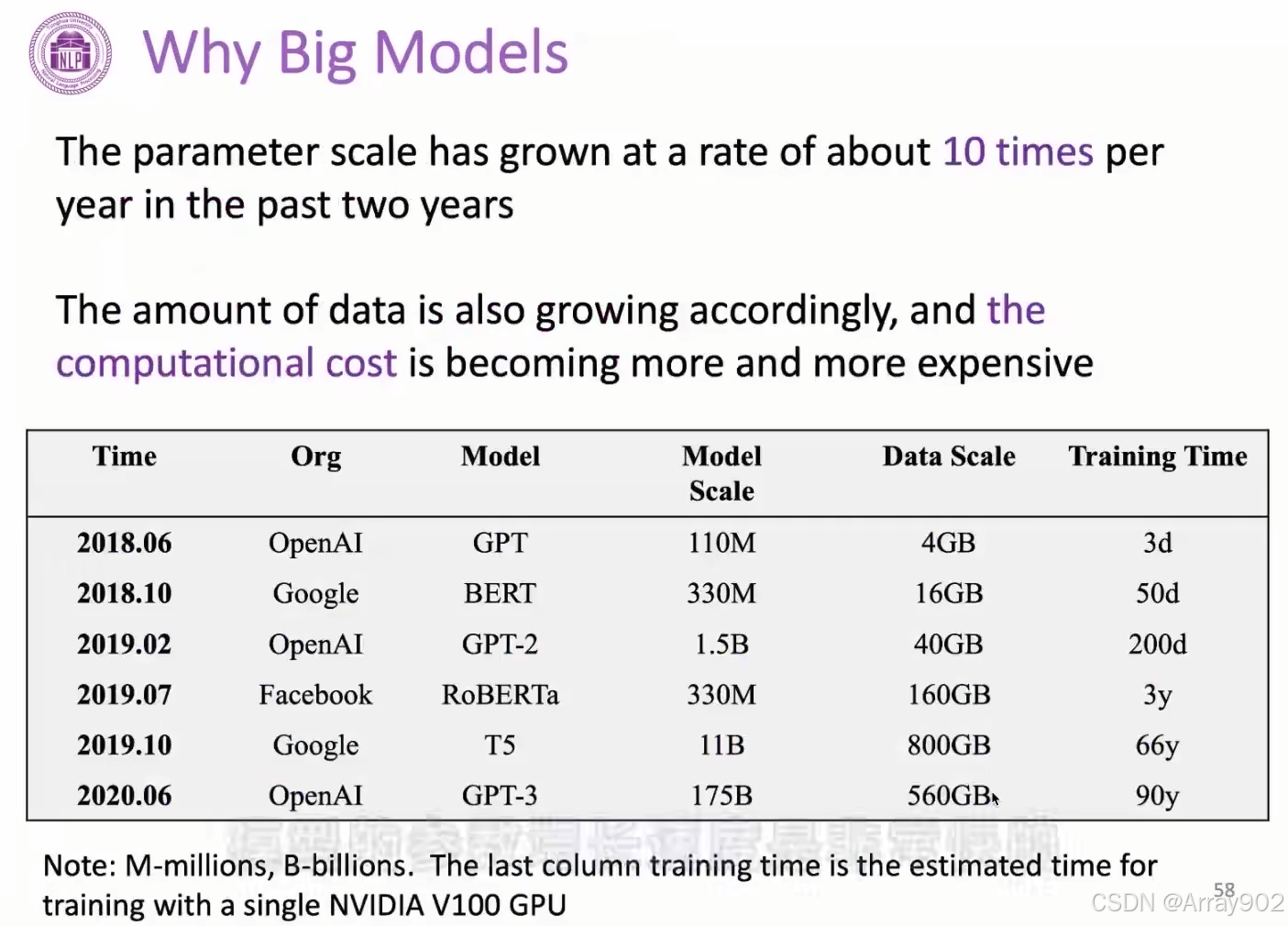
在18年预训练语言模型出来以后,大家慢慢的把预训练语言模型作为我们解决NLP的几个基础的工具。
大模型在另一个方面在于它其实具有很强的小样本或者少次学习的能力。深度学习需要大量的标注数据,然后去学这个模型。通过看到很多样本之后,能够产生很好的模型性能,这个是需要大量的标注数据做支撑。但GPT3让我们看到了另一面,即可以在大规模无标注数据上进行模型学习,学完之后让这个模型具备很多知识,然后在解决具体任务的时候,就不太需要很多的样本,只要少量的样本告诉模型需要做什么任务,以及引导模型把他的知识跟这个任务相关的知识给摘取出来去解决具体的实际问题就可以做的很好,比如机器翻译。

大模型背后的范式
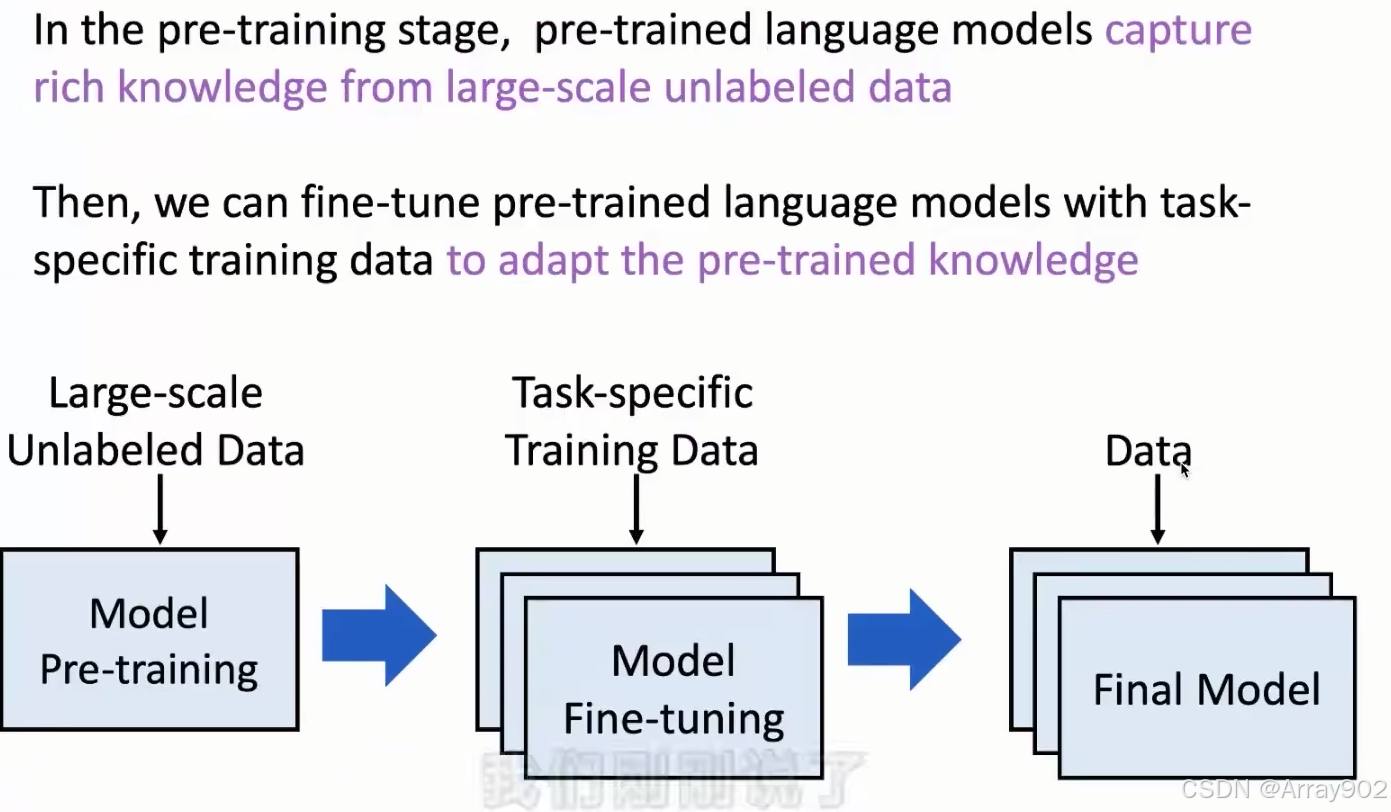
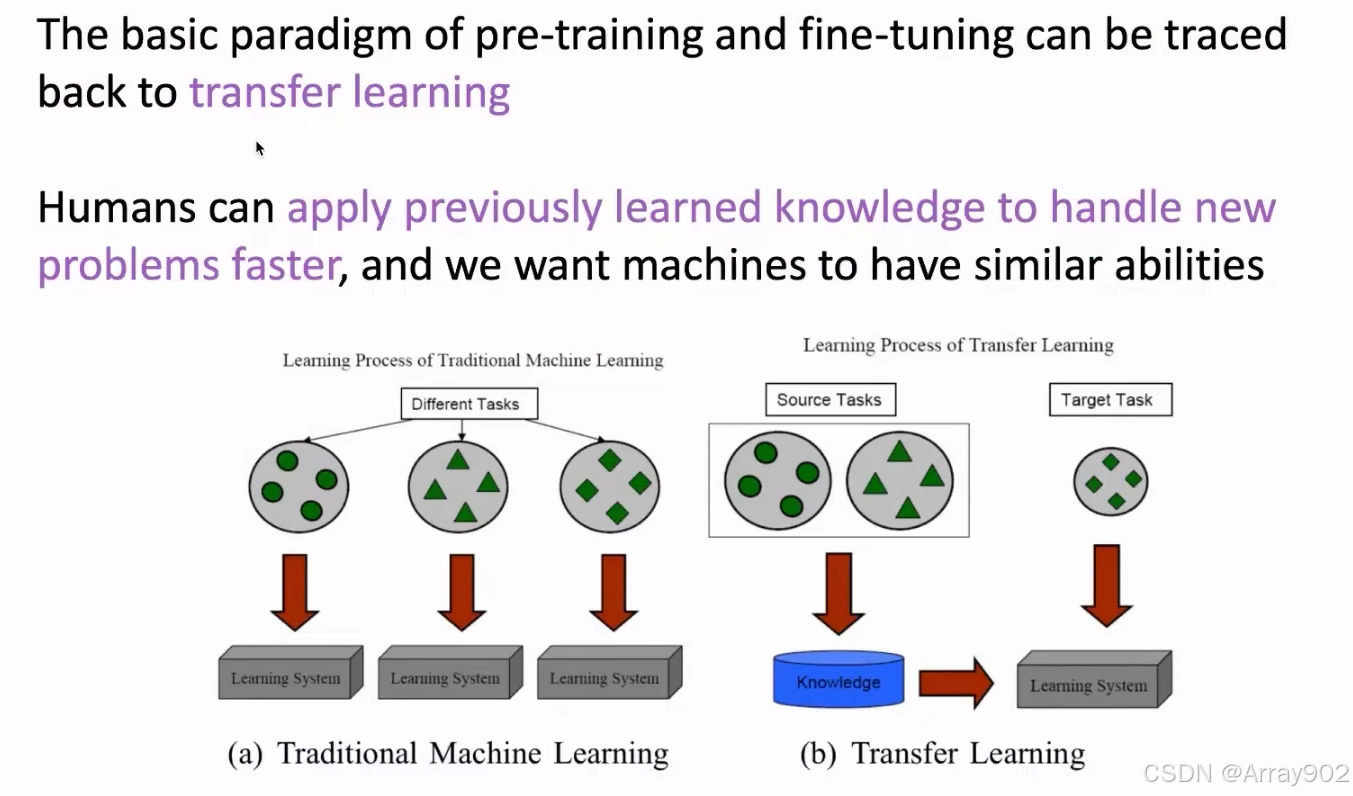
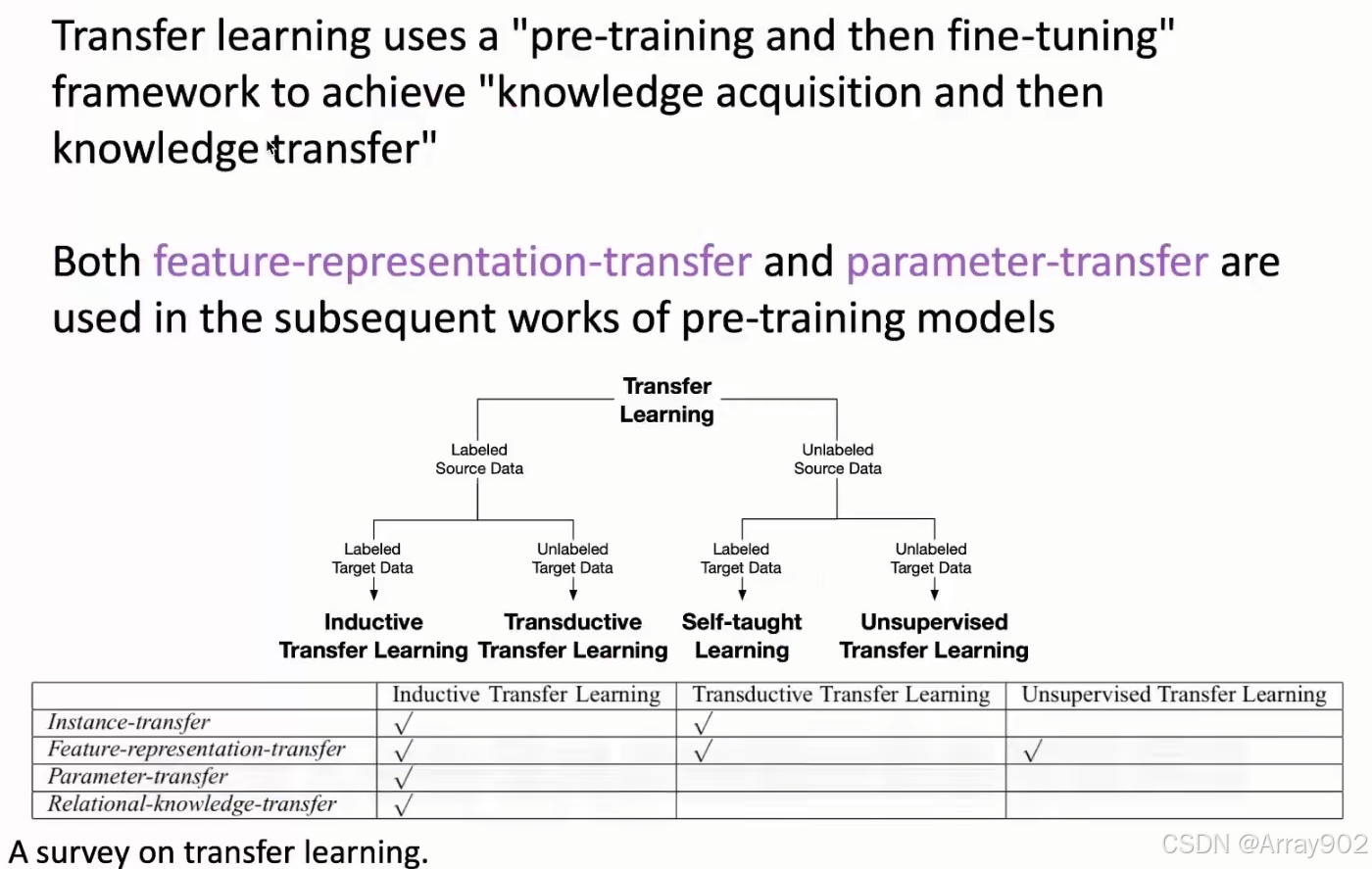
对于预训练语言模型来说,他的很核心的东西是它会从无标注的数据中去进行学习,然后通过一些自监督的任务去做预训练,从中得到一些丰富的知识。在具体应用的时候,会引入一些任务相关的一些数据,然后去调整模型。相当于在这个已经预训练好的模型上,引入任务相关的数据,这些任务相关数据可以帮助我们对具体的任务进行一些适配。
换句话说,就是预训练阶段我们会获取大量的知识,这些知识是一些通用的知识,它可以解决各种各样的问题。但是对于要解决的具体的任务的话,不一定所有知识都是适用的,所以要结合任务特定的数据,去对他整个参数进行微调,最终保留那些对任务相关的知识。而对于那些跟任务不相关的知识就可以抛掉,最终可以得到一个可以解决具体任务的模型,它能够在下游任务上表现的很好。
编程准备
做深度学习,尤其是大模型方面的研究,肯定要和Linux的服务器打交道,了解以下内容:
