25年3月来自Nvidia、斯坦福和MIT的论文“CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models”。
视觉-语言-动作模型 (VLA) 已显示出利用预训练的视觉语言模型和各种机器人演示来学习可泛化的感觉运动控制的潜力。虽然这种范式有效地利用了来自机器人和非机器人来源的大规模数据,但当前的 VLA 主要侧重于直接输入-输出映射,缺乏对复杂操作任务至关重要的中间推理步骤。因此,现有的 VLA 缺乏时间规划或推理能力。本文介绍一种将显式视觉-思维链 (CoT) 推理融入视觉-语言-动作模型 (VLA) 的方法,通过自回归地预测未来图像帧作为视觉目标,然后生成一个简短的动作序列来实现这些目标。CoT-VLA,是一种 7B VLA,可以理解和生成视觉和动作 tokens。
机器人学习领域的最新进展表明,在训练可应用于不同任务和环境的策略方面取得了令人瞩目的进展 [1、3、5、12、14、18、29、36、44、45、48、54、59、63、66、70、76、78]。一个有希望的方向是视觉-语言-动作 (VLA) 模型,它利用预训练视觉-语言模型 (VLM) 的丰富理解能力,将自然语言指令和视觉观察映射到机器人动作 [12、29、48]。通过在机器人演示上训练 VLM,VLA 继承了其理解不同场景、物体和自然语言指令的能力,从而在针对下游测试场景进行微调时具有更好的泛化能力。虽然这些方法已经显示出令人印象深刻的结果,但它们通常直接从观察映射到动作,而没有明确的中间推理步骤,这可能会提高可解释性并可能提高性能。
在语言领域,思维链 (CoT) 提示已成为一种强大的技术,通过鼓励逐步思考来提高大语言模型 (LLM) 的推理能力 [62, 75]。将这些概念应用于机器人技术,为在文本、视觉观察和身体动作中建立推理提供令人兴奋的机会。最近的研究通过结合语言描述、关键点或边框等中间推理步骤在这方面取得进展 [15, 44, 45, 63]。这些中间表示捕获场景、目标和任务的抽象状态,通常需要额外的预处理流水线。在本文工作中,探索子目标图像作为动作生成之前的中间推理步骤。这些图像捕获模型推理过程的状态,并且可以在机器人演示数据集中自然获得。虽然先前的研究已经探索了子目标生成和目标条件下的模仿学习 [2, 11, 46, 55],还没有将这些概念与 VLA 相结合作为中间思维链推理步骤的方法。
本文构建 CoT-VLA 系统,该系统利用视觉思维链推理,基于统一多模态基础模型的最新进展,可以理解和生成文本和图像 [39, 58, 61, 67, 69]。如图所示:CoT-VLA 和原始 VLA 的比较
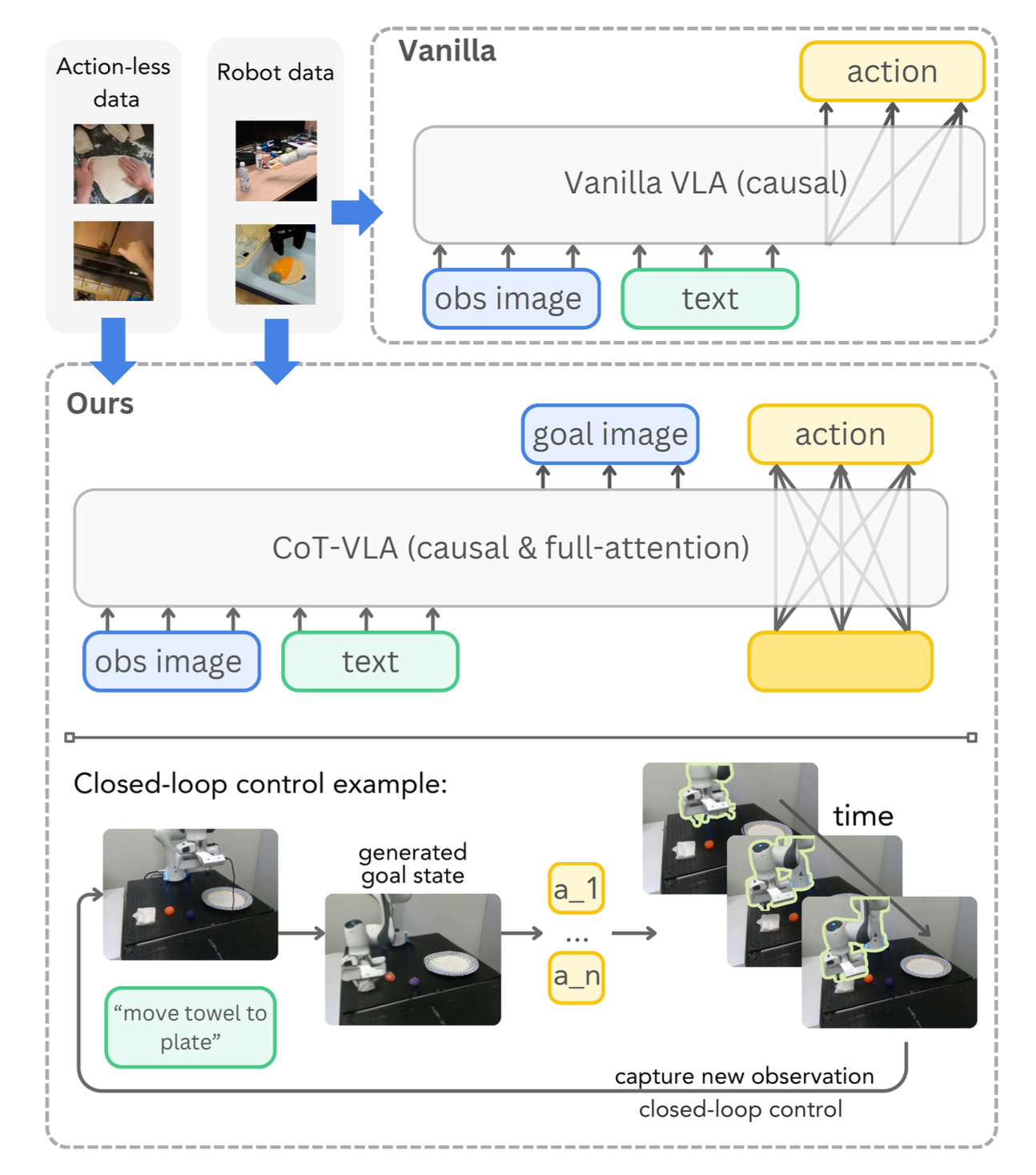
考虑两种类型的训练数据用于 VLA 预训练:机器人演示数据集 D_r 和无动作视频数据集 D_v。机器人演示表示为 D_r = {(l, a_1…T, s_1…T)},其中 l 表示自然语言指令,a_1…T = {a_1, …, a_T} 表示机器人动作序列,s1…T = {s1, …, sT} 表示作为图像序列的视觉观察。无动作视频 D_v = {(l, s_1…T)} 由语言描述和没有动作注释的图像组成。
VLA:原始 VLA 方法在 D_r 上微调预训练的 VLM P_θ,学习直接从当前观察 s_t 和语言指令 l 预测动作 ˆa_t+1(如上图,顶部)。
关键见解是在动作生成之前融入明确的视觉推理。如图所示,其方法分为两个连续阶段:作为中间视觉推理步骤,首先预测 n 帧前的子目标图像 ˆs_t+n;然后,生成一系列 m 个动作来实现这个子目标状态。

这使模型能够首先通过明确推理所需的未来状态来进行“视觉思考”,然后再预测动作。视觉推理步骤在机器人演示 D_r 和无动作视频 D_v 上进行训练,而动作生成步骤仅在机器人演示 D_r 上进行训练。
基础视觉-语言模型
为了实现视觉推理能力,以 VILA-U [67] 为基础,这是一个统一的多模态基础模型,能够理解和生成图像和文本token。
VILA-U 通过自回归下一个 token 预测框架统一视频、图像和语言理解。其核心是一个统一的视觉塔,将视觉输入编码为与文本信息对齐的离散 tokens。这可以实现自回归图像和视频生成,同时显著增强利用离散视觉特征的 VLM 的理解能力。VILA-U 利用残差量化 [32] 来提高离散视觉特征的表示能力 - 结合深度 transformer(如 RQ-VAE [32] 中引入的)来逐步预测残差 tokens。提取的视觉特征随后通过投影器,然后由 LLM 主干进行处理。基本模型在多模态对上进行训练,包括 [图像,文本]、[文本,图像]、[视频,文本] 和 [文本,视频]。用在 256 × 256 分辨率图像上训练的 VILA-U 模型,其中每个图像被编码为 16 × 16 × 4 个 tokens,残差深度为 4 [32]。有关 VILA-U 训练和架构的详细信息,请参阅 [67]。
训练程序
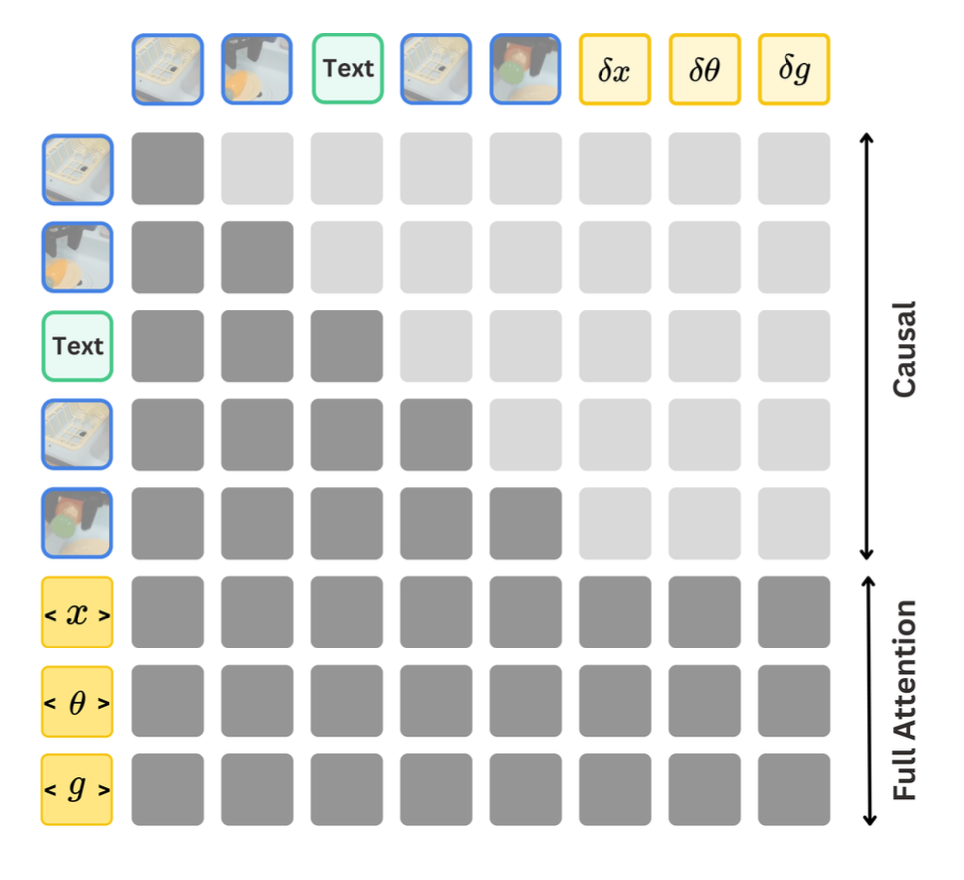
在机器人演示 D_r 和无动作视频 D_v 的组合上对基本 7B VILA-U 模型进行预训练。在训练过程中,优化三个组件,即 LLM 主干、投影器和深度 transformer,同时保持视觉塔固定。训练目标有两个关键组成部分:具有因果注意的子目标图像生成 和具有全注意的动作生成。
视觉 token 预测。对于子目标图像生成,每个训练序列的形式为 (l, s_t, s_t+n)。遵循 [67] 中使用的训练目标。在每个视觉位置 j,深度transformer P_δ 基于 LLM 生成的代码嵌入 h_j 自回归预测 D 个残差 tokens (k_j1,…,k_jD)。
动作 token 预测。对于动作预测,每个训练序列都采用 (l, s_t, s_t+n, a_t, …, a_t+m) 的形式。每个动作 a_i 由 7 个 tokens 表示,每个动作维度都独立离散化。按照 [29],将每个连续动作维度映射到 256 个离散 bins 中,bin 宽通过均匀划分训练数据动作分布的第 1 百分位数和第 99 百分位数之间的间隔来确定。我们将文本 token 化器词汇表中使用频率最低的 256 个 tokens 重新用作动作bin tokens。与之前的研究 [12, 29, 48] 不同,采用充分注意力来处理和预测动作 tokens,使所有动作 tokens 能够相互作用。如图说明这种注意机制:
预训练阶段。在机器人演示 D_r 和无动作视频 D_v 上对 CoT-VLA 进行预训练。对于机器人演示,从 Open X-Embodiment 数据集 [48](OpenX)中精选一个子集。按照 Open-VLA [29] 中建立的预处理流程,选择并处理具有第三人称摄像机视图和单臂末端执行器控制(7-DoF)的数据集。对于无动作视频 D_v,结合 EPIC-KITCHENS [27] 和 Something-Something V2 [20] 数据集。所有图像均以 256×256 的分辨率处理。对于视觉推理,使用在未来时间步 n 的子目标图像,这些图像是从数据集特定范围 [n_l , n_u ] 中均匀采样的,其中 n_l 和 n_u 定义预测范围的下限和上限。使用的动作块大小为 10。
下游闭环部署的适应阶段。为了适应下游任务,用在目标机器人设置上收集的任务特定机器人演示数据 D_r 来微调预训练模型。在此阶段,优化 LLM 主干、投影器和深度transformer,同时保持视觉塔冻结,保持与预训练阶段相同的训练设置。生成的模型可以根据自然语言命令 l 执行新的操作任务。算法 1 描述在测试时的机器人控制程序。

实验在三个互补的环境中进行评估:用于在模拟环境中进行评估的 LIBERO 基准 [37]、具有 45k 个机器人演示数据集的 Bridge-V2 平台 [60] 以及 Franka-Tabletop 设置,其中有一个固定的、安装在桌子上的 Franka Emika Panda 机器人,每个测试场景的机器人演示数量有限,为 10 到 150 个。
LIBERO 模拟基准。对 LIBERO [37] 进行评估,这是一个模拟基准,包含四个不同的任务套件:LIBERO-Spatial、LIBERO-Object、LIBERO-Goal 和 LIBERO-Long。每个套件包含 10 个不同的任务,每个任务有 50 个人类遥控演示,旨在评估机器人对空间关系、物体交互和任务特定目标的理解。遵循与 [29] 中相同的预处理流程:(1)从轨迹中删除暂停间隔,(2)将图像分辨率标准化为 256×256 像素,以及(3)对所有图像应用 180 度旋转。
Bridge-V2 真实机器人实验。用 6-DoF WidowX 机械臂,遵循 Bridge-V2 [60] 的实验设置。训练数据有来自 Bridge-V2 数据集的 45k 条带语言注释的轨迹,涵盖各种操作任务。虽然数据集与 OpenX 一起被纳入预训练阶段,但专门在 Bridge-V2 上执行额外的特定任务微调,直到达到 95% 的训练动作预测准确率阈值。按照 [29],评估 [29] 中设计的四个任务,以评估视觉稳健性(不同的干扰项)、运动泛化(新的物体位置)、语义泛化(未见过的语言指令)和语言基础(指令跟随)。
Franka-Tabletop 真实机器人实验。用一个固定的、安装在桌子上的 Franka Emika Panda 7-DoF 机械臂,称为 Franka-Tabletop。该设置在预训练阶段是没见过的,旨在通过少量机器人演示来评估模型对新现实环境的适应能力。对 6 个任务进行评估:3 个狭窄领域的单指令任务和 3 个不同的多指令任务,如图所示并在 [29] 中介绍。对于每个任务,数据集包含 10 到 150 个演示。
