文章目录
- 引言
- 一、B+Tree索引核心原理
- 1.1 索引数据结构演化
- 1.2 B+Tree的存储结构
- 通过主键查询(主键索引)商品数据的过程
- 通过非主键(辅助索引)查询商品数据的过程
- MySQL InnoDB 的索引原理
- 二、执行计划深度解析
- 三、索引失效的六大陷阱
- 3.1 隐式类型转换
- 3.2 索引列参与运算
- 3.3 模糊查询通配符前置
- 3.4 最左前缀原则违反
- 3.5 OR条件使用不当
- 3.6 统计信息不准确
- 四、高性能索引设计策略
- 4.1 覆盖索引优化
- 4.2 前缀索引技巧
- 4.3 联合索引排序策略
- 4.4 索引下推优化(ICP)
- 五、真实场景案例解析
- 5.1 电商订单查询优化
- 5.2 社交平台好友推荐
- 结语

引言
数据库性能直接影响系统响应速度。作为关系型数据库的典型代表,MySQL的索引设计与优化是每个开发者必须掌握的技能。接下来我们将深入剖析MySQL的索引原理,结合真实场景案例,揭秘B+Tree的独特优势,并通过执行计划分析与优化策略,探讨如何构建高性能数据库系统。
我们经常会碰到如下问题:
-
数据库索引底层使用的是什么数据结构和算法呢?
-
为什么 MySQL InnoDB 选择 B+Tree 当默认的索引数据结构?
-
如何通过执行计划查看索引使用详情?
-
有哪些情况会导致索引失效?
-
平时有哪些常见的优化索引的方法?
-
……
无非就是对应
-
MySQL InnoDB 的索引原理;
-
B+Tree 相比于其他索引数据结构(如 B-Tree、二叉树,以及 Hash 表)的优势;
-
MySQL 执行计划的方法;
-
导致索引失效的常见情况;
-
常用的建立高效索引的技巧(如前缀索引、建立覆盖索引等)。
一、B+Tree索引核心原理
1.1 索引数据结构演化
深入理解二叉树、B树与B+树:原理、应用与实现
| 数据结构 | 查询复杂度 | 范围查询 | 磁盘I/O效率 | 适用场景 |
|---|---|---|---|---|
| 二叉树 | O(log n) | 差 | 高 | 小数据量精确查询 |
| B-Tree | O(log n) | 较好 | 中 | 通用场景 |
| B+Tree | O(log n) | 优秀 | 高 | 大数据量范围查询 |
| Hash表 | O(1) | 不支持 | 高 | 等值查询 |
1.2 B+Tree的存储结构
建个表如下:
CREATE TABLE `product` (`id` int(11) NOT NULL,`product_no` varchar(20) DEFAULT NULL,`name` varchar(255) DEFAULT NULL,`price` decimal(10, 2) DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
);
新增几条数据如下:
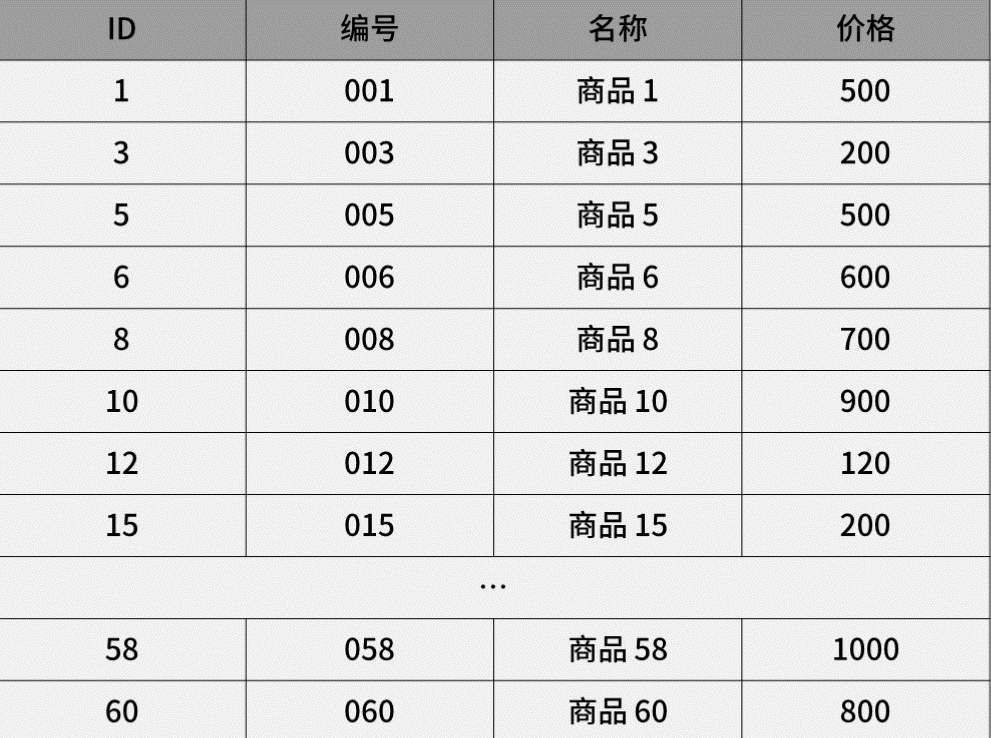
通过主键查询(主键索引)商品数据的过程
此时当我们使用主键索引查询商品 15 的时候,那么按照 B+Tree 索引原理,是如何找到对应数据的呢?
select * from product where id = 15
我们可以通过数据手动构建一个 B+Tree,它的每个节点包含 3 个子节点(B+Tree 每个节点允许有 M 个子节点,且 M>2),根节点中的数据值 1、18、36 分别是子节点(1,6,12),(18,24,30)和(36,41,52)中的最小值。
每一层父节点的数据值都会出现在下层子节点的数据值中,因此在叶子节点中,包括了所有的数据值信息,并且每一个叶子节点都指向下一个叶子节点,形成一个链表。如图所
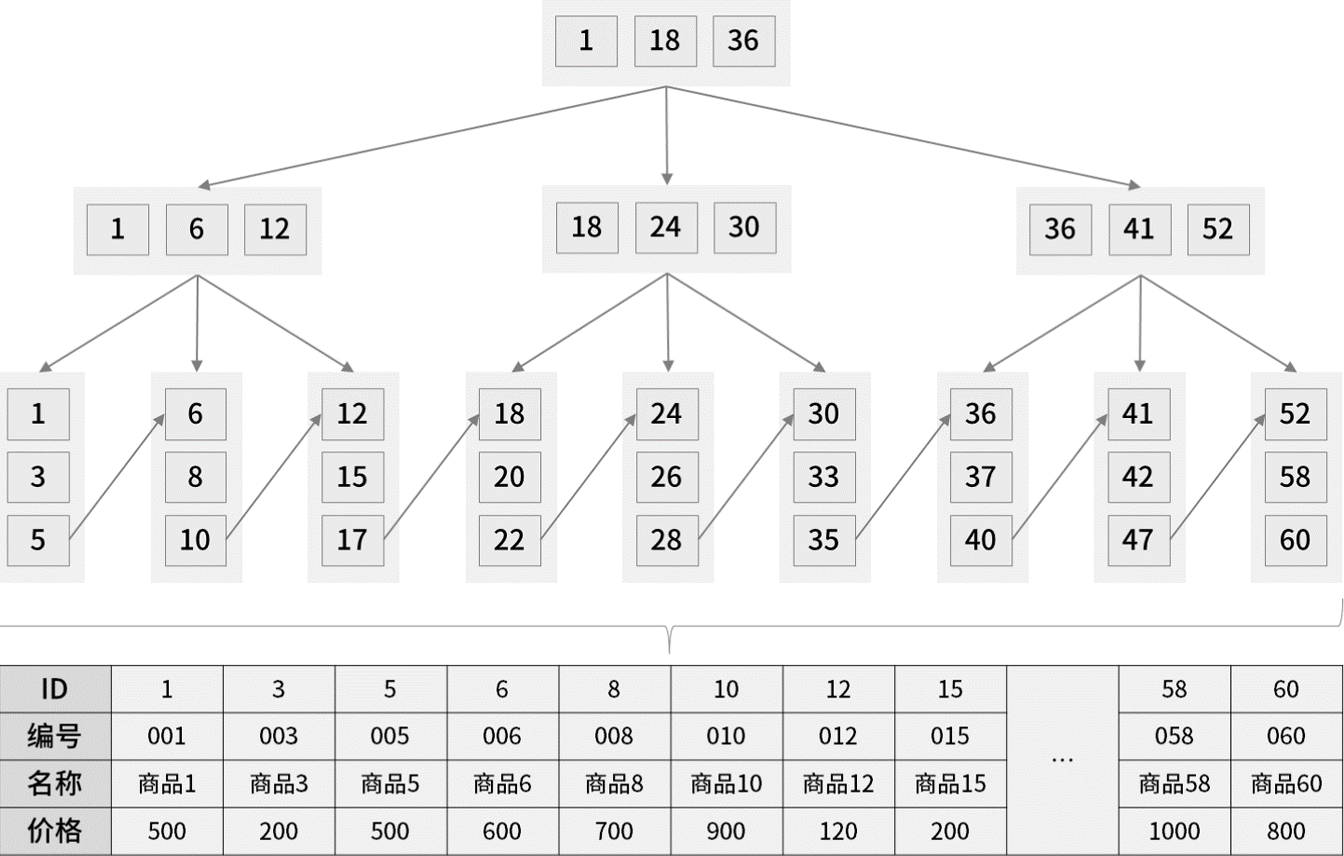
比如想要查找数据值 15,B+Tree 会自顶向下逐层进行查找:
-
将 15 与根节点的数据 (1,18,36) 比较,15 在 1 和 18 之间,所以根据 B+Tree的搜索逻辑,找到第二层的数据块 (1,6,12);
-
在第二层的数据块 (1,6,12) 中进行查找,因为 15 大于 12,所以找到第三层的数据块 (12,15,17);
-
在叶子节点的数据块 (12,15,17) 中进行查找,然后我们找到了数据值 15;
-
最终根据数据值 15 找到叶子节点中存储的数据。
整个过程一共进行了 3 次 I/O 操作,所以 B+Tree 相比于 B 树和二叉树来说,最大的优势在于查询效率。
通过非主键(辅助索引)查询商品数据的过程
如果使用商品编码查询商品(即使用辅助索引进行查询),会先检索辅助索引中的 B+Tree 的 商品编码,找到对应的叶子节点,获取主键值,然后再通过主键索引中的 B+Tree 树查询到对应的叶子节点,然后获取整行数据。这个过程叫回表。
B+Tree特点:
- 多叉结构:单个节点存储多个键值,降低树高度(3-4层可支撑千万级数据)
- 数据聚集:叶子节点形成有序双向链表,支持高效范围查询
- 分层存储:非叶节点仅存索引键,叶节点存储完整数据(聚簇索引)或主键(辅助索引)
MySQL InnoDB 的索引原理
从数据结构的角度来看, MySQL 常见索引有 B+Tree 索引、HASH 索引、Full-Text 索引。

在实际应用中,InnoDB 是 MySQL 建表时默认的存储引擎,B+Tree 索引类型也是 MySQL 存储引擎采用最多的索引类型。
在创建表时,InnoDB 存储引擎默认使用表的主键作为主键索引,该主键索引就是聚簇索引(Clustered Index),如果表没有定义主键,InnoDB 就自己产生一个隐藏的 6 个字节的主键 ID 值作为主键索引,而创建的主键索引默认使用的是 B+Tree 索引。
二、执行计划深度解析
1存储商品信息的演示表 product:
CREATE TABLE `product` (`id` int(11) NOT NULL,`product_no` varchar(20) DEFAULT NULL,`name` varchar(255) DEFAULT NULL,`price` decimal(10, 2) DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,KEY 'index_name' ('name').KEY 'index_id_name' ('id', 'name')
) CHARACTER SET = utf8 COLLATE = utf8_general_ci
表中包含了主键索引、name 字段上的普通索引,以及 id 和 name 两个字段的联合索引。现在我们来看一条简单查询语句的执行计划:

重点关注 type 字段, 表示数据扫描类型,也就是描述了找到所需数据时使用的扫描方式是什么,常见扫描类型的执行效率从低到高的顺序为(考虑到查询效率问题,全表扫描和全索引扫描要尽量避免):
ALL(全表扫描);index(全索引扫描);range(索引范围扫描);ref(非唯一索引扫描);eq_ref(唯一索引扫描);const(结果只有一条的主键或唯一索引扫描)。
关键指标解读:
- type:扫描类型(性能排序:const > ref > range > index > ALL)
- key_len:索引使用长度(可判断是否使用完整索引)
- possible_keys 字段表示可能用到的索引
- key 字段表示实际用的索引
- rows:预估扫描行数
- Extra:额外信息(Using index/Using filesort等)
三、索引失效的六大陷阱
来看一个索引失效的例子:

这条带有 like 查询的 SQL 语句,没有用到 product 表中的 index_name 索引。
我们结合普通索引的 B+Tree 结构看一下索引失效的原因: 当 MySQL 优化器根据 name like ‘%路由器’ 这个条件,到索引 index_name 的 B+Tree 结构上进行查询评估时,发现当前节点的左右子节点上的值都有可能符合 ‘%路由器’ 这个条件,于是优化器判定当前索引需要扫描整个索引,并且还要回表查询,不如直接全表扫描。
当然,还有其他类似的索引失效的情况:
-
索引列上做了计算、函数、类型转换操作,这些情况下索引失效是因为查询过程需要扫描整个索引并回表,代价高于直接全表扫描;
-
like 匹配使用了前缀匹配符 ‘%abc’;
-
字符串不加引号导致类型转换;
所以, 如果 MySQL 查询优化器预估走索引的代价比全表扫描的代价还要大,则不走对应的索引,直接全表扫描,如果走索引比全表扫描代价小,则使用索引。
3.1 隐式类型转换
-- 字符串字段使用数字查询
SELECT * FROM user WHERE phone = 13800138000;
3.2 索引列参与运算
-- DATE_FORMAT函数导致索引失效
SELECT * FROM orders
WHERE DATE_FORMAT(create_time, '%Y-%m') = '2023-07';
3.3 模糊查询通配符前置
-- 前导通配符无法使用索引
SELECT * FROM article WHERE content LIKE '%数据库%';
3.4 最左前缀原则违反
-- 联合索引(a,b,c)无法命中
SELECT * FROM table WHERE b = 2 AND c = 3;
3.5 OR条件使用不当
-- 其中一个条件无索引将导致全表扫描
SELECT * FROM products
WHERE category_id = 5 OR price > 1000;
3.6 统计信息不准确
当数据分布变化超过10%时,需执行ANALYZE TABLE更新统计信息
四、高性能索引设计策略
4.1 覆盖索引优化
覆盖索引是指 SQL 中 query 的所有字段,在索引 B+tree 的叶子节点上都能找得到的那些索引,从辅助索引中查询得到记录,而不需要通过聚簇索引查询获得。假设我们只需要查询商品的名称、价格,有什么方式可以避免回表呢?
我们可以建立一个组合索引,即商品ID、名称、价格作为一个组合索引。如果索引中存在这些数据,查询将不会再次检索主键索引,从而避免回表。所以,使用覆盖索引的好处很明显,即不需要查询出包含整行记录的所有信息,也就减少了大量的 I/O 操作
-- 建立包含所有查询字段的联合索引
CREATE INDEX idx_order_status_time
ON orders(status, create_time, total_amount);SELECT status, create_time, total_amount
FROM orders
WHERE status = 1
ORDER BY create_time DESC;
4.2 前缀索引技巧
前缀索引就是用某个字段中,字符串的前几个字符建立索引,比如我们可以在订单表上对商品名称字段的前 5 个字符建立索引。使用前缀索引是为了减小索引字段大小,可以增加一个索引页中存储的索引值,有效提高索引的查询速度。在一些大字符串的字段作为索引时,使用前缀索引可以帮助我们减小索引项的大小。
但是,前缀索引有一定的局限性,例如 order by 就无法使用前缀索引,无法把前缀索引用作覆盖索引。
-- 对长文本字段前20字符建立索引
CREATE INDEX idx_product_desc
ON products(product_desc(20));-- 计算最佳前缀长度
SELECT COUNT(DISTINCT LEFT(product_desc, 20)) / COUNT(*)
FROM products;
4.3 联合索引排序策略
联合索引时,存在最左匹配原则,也就是按照最左优先的方式进行索引的匹配。比如联合索引 (userpin, username),如果查询条件是 WHERE userpin=1 AND username=2,就可以匹配上联合索引;或者查询条件是 WHERE userpin=1,也能匹配上联合索引,但是如果查询条件是 WHERE username=2,就无法匹配上联合索引。
另外,建立联合索引时的字段顺序,对索引效率也有很大影响。越靠前的字段被用于索引过滤的概率越高,实际开发工作中建立联合索引时,要把区分度大的字段排在前面,这样区分度大的字段越有可能被更多的 SQL 使用到。
-- 区分度高的字段在前
CREATE INDEX idx_user_region_gender
ON users(region_code, gender);
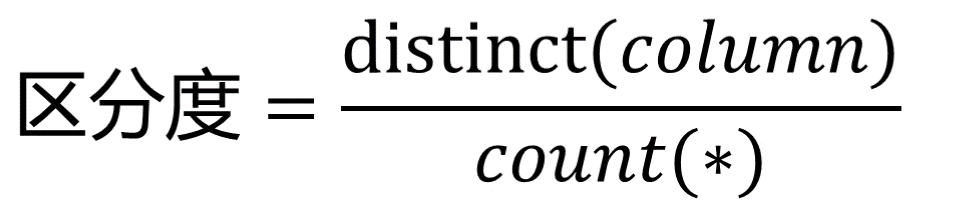
区分度就是某个字段 column 不同值的个数除以表的总行数,比如性别的区分度就很小,不适合建立索引或不适合排在联合索引列的靠前的位置,而 uuid 这类字段就比较适合做索引或排在联合索引列的靠前的位置。
4.4 索引下推优化(ICP)
-- MySQL 5.6+ 自动启用,减少回表次数
SELECT * FROM employees
WHERE last_name LIKE '张%'
AND age > 30;
五、真实场景案例解析
5.1 电商订单查询优化
原始SQL:
SELECT * FROM orders
WHERE status = 2
AND payment_time BETWEEN '2023-07-01' AND '2023-07-31'
ORDER BY create_time DESC;
优化方案:
- 创建联合索引
(status, payment_time, create_time) - 使用覆盖索引减少回表
- 分页查询使用
WHERE id > ?代替LIMIT深度翻页
5.2 社交平台好友推荐
-- 优化前(全表扫描):
SELECT user_id FROM relationships
WHERE friend_id = 10086
AND relation_type = 3;-- 优化后(反向索引):
CREATE INDEX idx_reverse_relation
ON relationships(friend_id, relation_type);
结语
优秀的索引设计需要平衡查询效率与写入性能。建议遵循以下原则:
- 优先考虑最常用查询模式
- 单表索引不超过5个
- 联合索引字段数不超过3个
- 定期审查索引使用情况
通过理解B+Tree的底层原理,结合执行计划分析与实际业务场景,开发者可以构建出高效的数据访问方案。记住:没有最好的索引,只有最适合业务场景的索引设计。
