横扫SQL面试题
📌 时间序列分组与合并问题

📚 横扫SQL面试——时间序列分组与合并解析
🌟 核心问题类型
时间序列分组(Sessionization)
处理具有时间维度的连续数据流,根据特定规则(如时间间隔、属性连续性)将相邻记录合并为逻辑组。
话不多说——直接上题:🎈🎈🎈🎈🎈🎈🎈
一、用户访问记录会话划分🎈🎈🎈
给定用户的访问记录access_records表,需要按照同一用户相邻两次访问记录时间间隔小于等于60秒则认为两次浏览记录属于同一会话的规则,为属于同一会话的访问记录增加一个相同的会话id字段。
| 表名 | 字段名 | 字段含义 | 数据类型 |
|---|---|---|---|
| 用户访问记录表 | user_id | 用户标识 | VARCHAR |
access_time | 访问时间 | DATETIME | |
action | 访问时执行的操作(如页面浏览等) | VARCHAR |
| user_id | access_time | action |
|---|---|---|
| User1 | 2025-03-31 10:00:00 | 浏览首页 |
| User1 | 2025-03-31 10:00:30 | 点击商品详情 |
| User2 | 2025-03-31 10:10:00 | 浏览列表页 |
| User1 | 2025-03-31 10:01:00 | 返回首页 |
| User2 | 2025-03-31 10:10:30 | 加入购物车 |
结果预期✅
| user_id | access_time | action | session_id |
|---|---|---|---|
| User1 | 2025-03-31 10:00:00 | 浏览首页 | 1 |
| User1 | 2025-03-31 10:00:30 | 点击商品详情 | 1 |
| User1 | 2025-03-31 10:01:00 | 返回首页 | 1 |
| User2 | 2025-03-31 10:10:00 | 浏览列表页 | 2 |
| User2 | 2025-03-31 10:10:30 | 加入购物车 | 2 |
✅✅✅
原始数据 → 计算相邻时间差 → 标记新会话 → 累加分组 → 分配ID↓ ↓ ↓ ↓
prev_access_time → new_session_start → session_groups → 最终结果
步骤1:获取相邻记录时间差(CTE: prev_access_time)✅
with prev_access_time as (selectuser_id,access_time,lag(access_time) over (partition by user_id order by access_time) as prev_timefrom access_records
)


输入数据 ✅
| user_id | access_time |
|---|---|
| UserA | 2024-01-01 08:00:00 |
| UserA | 2024-01-01 08:00:50 |
| UserA | 2024-01-01 08:02:00 |
中间表 prev_access_time
| user_id | access_time | prev_time |
|---|---|---|
| UserA | 2024-01-01 08:00:00 | NULL |
| UserA | 2024-01-01 08:00:50 | 2024-01-01 08:00:00 |
| UserA | 2024-01-01 08:02:00 | 2024-01-01 08:00:50 |
LAG(access_time)获取同一用户前一条记录的访问时间PARTITION BY user_id确保按用户独立处理ORDER BY access_time按时间顺序排序
步骤2:标记新会话起点(CTE: new_session_start)✅

new_session_start as (selectuser_id,access_time,casewhen timestampdiff(second, prev_time, access_time) >= 60 or prev_time is nullthen 1else 0end as is_new_sessionfrom prev_access_time
)
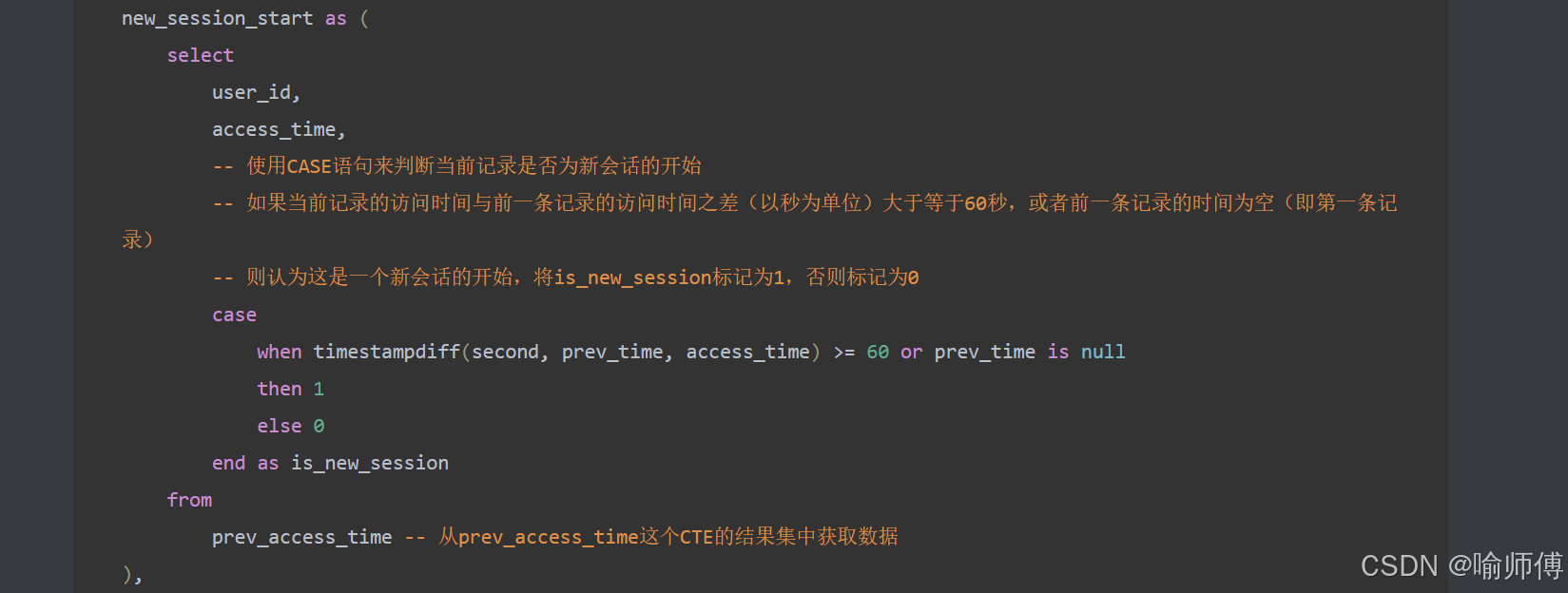
中间表 new_session_start
| user_id | access_time | is_new_session |
|---|---|---|
| UserA | 2024-01-01 08:00:00 | 1 (首条记录) |
| UserA | 2024-01-01 08:00:50 | 0 (间隔50秒) |
| UserA | 2024-01-01 08:02:00 | 1 (间隔70秒) |
判断逻辑
- 首条记录:
prev_time IS NULL→ 标记为1 - 间隔计算:
08:00:50 - 08:00:00 = 50秒→<60秒→ 标记0 - 间隔计算:
08:02:00 - 08:00:50 = 70秒→>=60秒→ 标记1
步骤3:生成会话分组(CTE: session_groups)✅
session_groups as (selectuser_id,access_time,sum(is_new_session) over (partition by user_id order by access_time) as session_groupfrom new_session_start
)
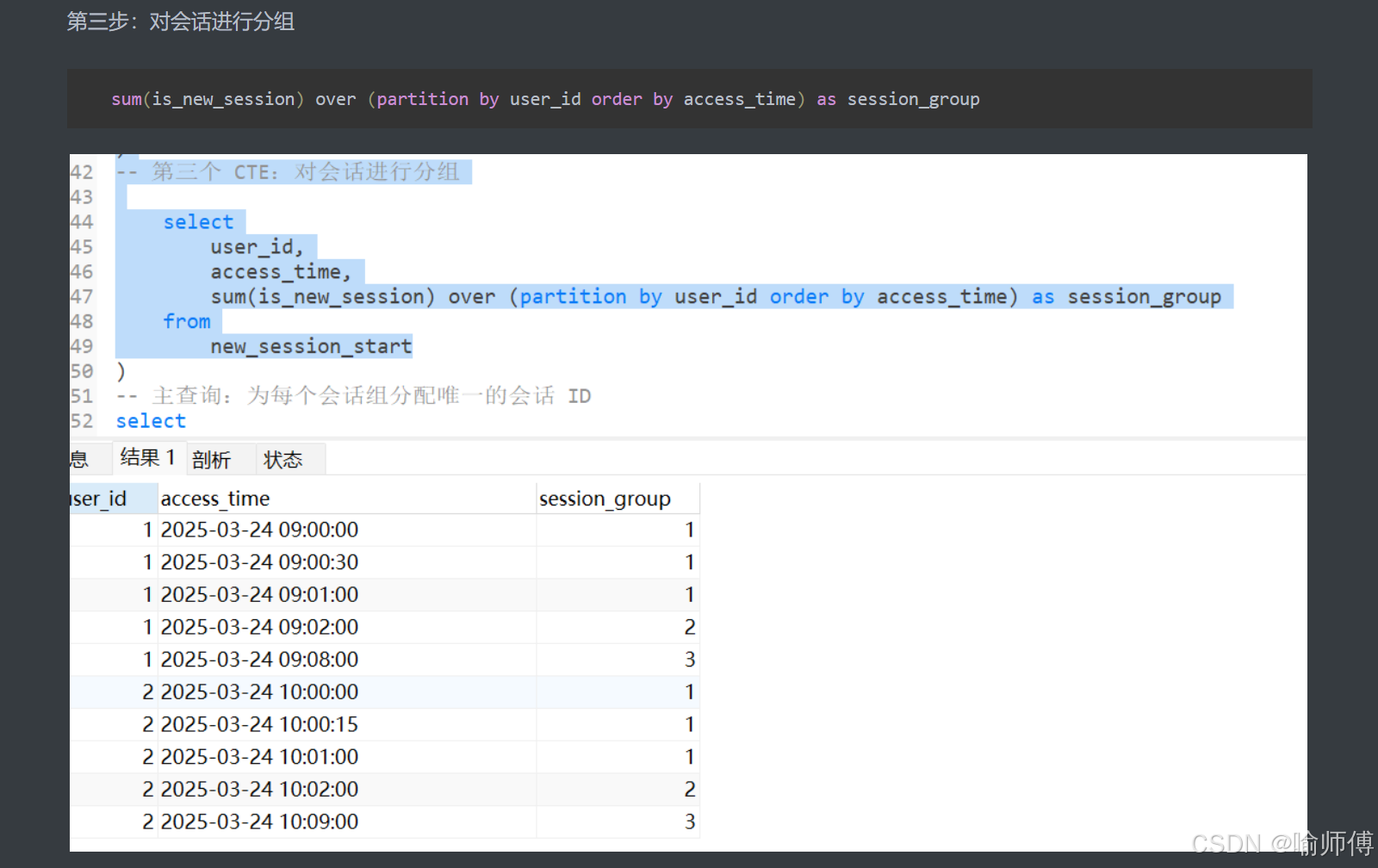
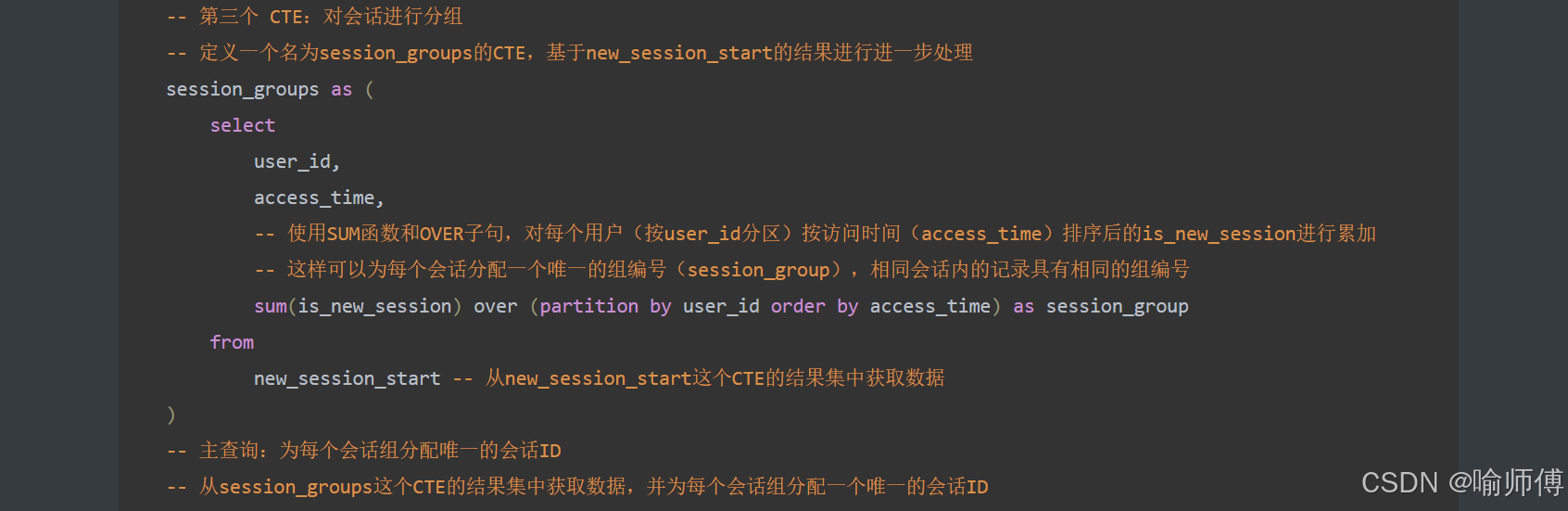
中间表 session_groups
| user_id | access_time | session_group |
|---|---|---|
| UserA | 2024-01-01 08:00:00 | 1 |
| UserA | 2024-01-01 08:00:50 | 1 (累加0) |
| UserA | 2024-01-01 08:02:00 | 2 (累加1) |
SUM(is_new_session)按用户和时间顺序累加标记- 同一会话组内的记录具有相同的
session_group值
步骤4:分配会话ID(主查询)✅
selectuser_id,access_time,dense_rank() over (partition by user_id order by session_group) as session_id
from session_groups;
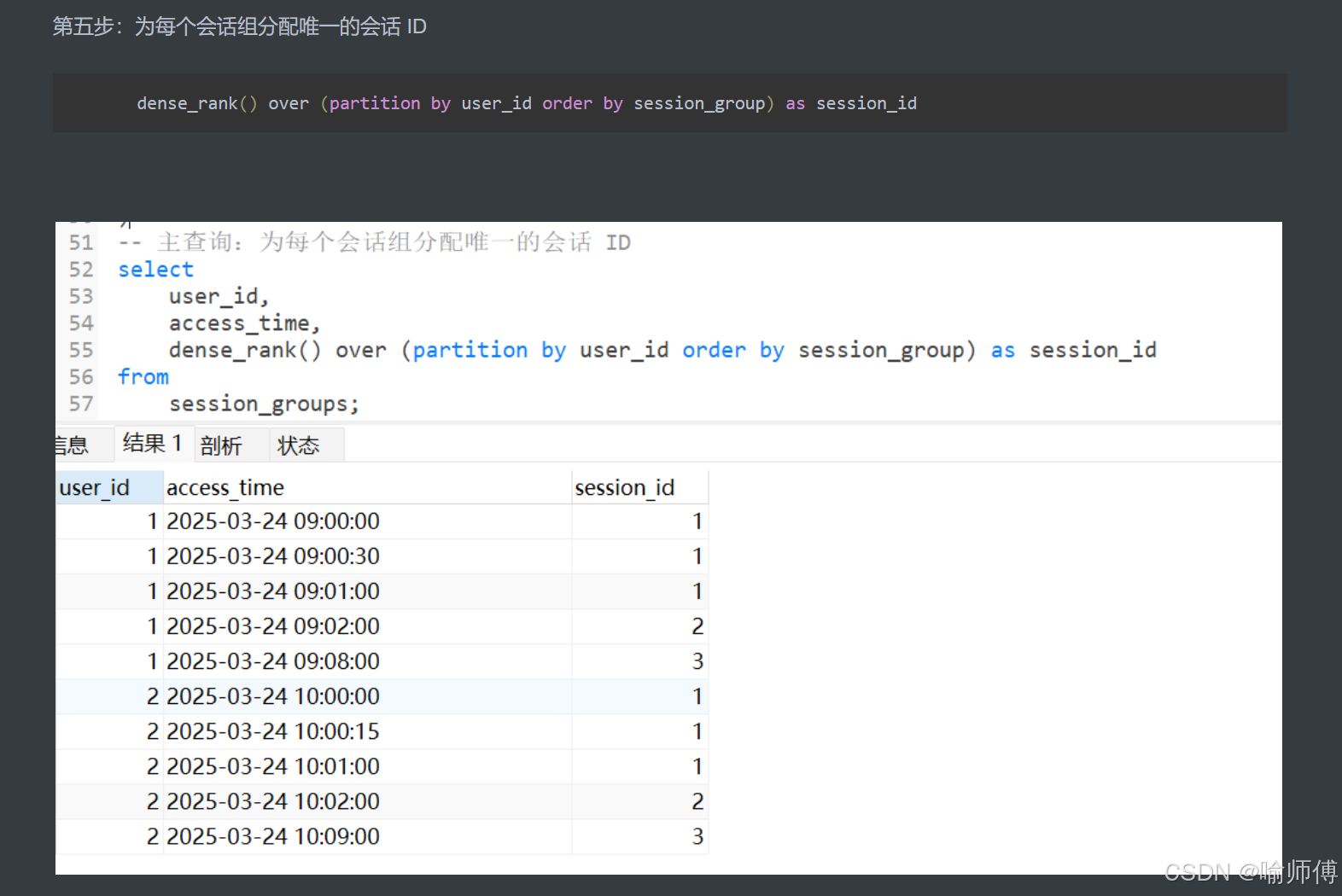

最终结果
| user_id | access_time | session_id |
|---|---|---|
| UserA | 2024-01-01 08:00:00 | 1 |
| UserA | 2024-01-01 08:00:50 | 1 |
| UserA | 2024-01-01 08:02:00 | 2 |
DENSE_RANK()保证会话ID连续(无间隔)- 按
session_group排序确保同一组ID相同
二、网站页面浏览时长统计🎈🎈🎈
给定网站页面浏览记录,需要按照用户在离开页面后30分钟内再次访问同一页面则认为是连续浏览的规则。
计算:
- 合并时长:将连续访问合并为一个时间段,计算从首次开始时间到最后结束时间的总跨度
- 实际时长:累加每次独立访问的实际时长(不合并连续访问)
- 增加会话id:属于同一浏览的访问记录增加一个相同的会话id字段。
| 表名 | 字段名 | 字段含义 | 数据类型 |
|---|---|---|---|
| 网站页面浏览记录表 | user_id | 用户标识 | VARCHAR |
page_url | 页面URL | VARCHAR | |
view_start_time | 开始浏览时间 | DATETIME | |
view_end_time | 结束浏览时间 | DATETIME |
| user_id | page_url | view_start_time | view_end_time |
|---|---|---|---|
| User1 | https://example.com | 2025-04-01 09:00:00 | 2025-04-01 09:10:00 |
| User1 | https://example.com | 2025-04-01 09:15:00 | 2025-04-01 09:20:00 |
| User2 | https://example.net | 2025-04-01 10:00:00 | 2025-04-01 10:15:00 |
| User1 | https://example.com | 2025-04-01 09:25:00 | 2025-04-01 09:30:00 |
| User2 | https://example.net | 2025-04-01 10:30:00 | 2025-04-01 10:45:00 |
结果预期
| user_id | page_url | view_start_time | view_end_time | merged_duration | total_real_duration |
|---|---|---|---|---|---|
| User1 | https://example.com | 2025-04-01 09:00:00 | 2025-04-01 09:30:00 | 30 | 20 (10+5+5) |
| User2 | https://example.net | 2025-04-01 10:00:00 | 2025-04-01 10:15:00 | 15 | 15 |
| User2 | https://example.net | 2025-04-01 10:30:00 | 2025-04-01 10:45:00 | 15 | 15 |
还是跟上题同样的套路~😝😝😝
| 步骤 | 核心操作 | 关键函数/逻辑 |
|---|---|---|
| 时间排序 | 获取前次结束时间 | LAG() + 窗口排序 |
| 标记会话起点 | 判断30分钟间隔 | TIMESTAMPDIFF() + CASE |
| 生成会话组 | 累加标记值 | SUM() OVER() |
| 分配会话ID | 生成唯一连续编号 | DENSE_RANK() |
| 聚合结果 | 计算时间跨度和累加时长 | MIN()/MAX()/SUM() |
步骤1:排序并获取前次结束时间✅
with ordered_views as(selectuser_id,page_url,view_start_time,view_end_time,lag(view_end_time) over(partition by user_id,page_url order by view_start_time) as prev_end_timefrom table
)

中间表 ordered_views ✅
| user_id | page_url | view_start_time | view_end_time | prev_end_time |
|---|---|---|---|---|
| User1 | https://example.com | 2025-04-01 09:00:00 | 2025-04-01 09:10:00 | NULL |
| User1 | https://example.com | 2025-04-01 09:15:00 | 2025-04-01 09:20:00 | 2025-04-01 09:10:00 |
| User1 | https://example.com | 2025-04-01 09:25:00 | 2025-04-01 09:30:00 | 2025-04-01 09:20:00 |
| User2 | https://example.net | 2025-04-01 10:00:00 | 2025-04-01 10:15:00 | NULL |
| User2 | https://example.net | 2025-04-01 10:30:00 | 2025-04-01 10:45:00 | 2025-04-01 10:15:00 |
步骤2:标记新会话起点✅
session_flags as(select *,casewhen prev_end_time IS NULL OR timestampdiff(minute, prev_end_time, view_start_time) > 30 then 1 else 0 end as is_new_sessionfrom ordered_views
)
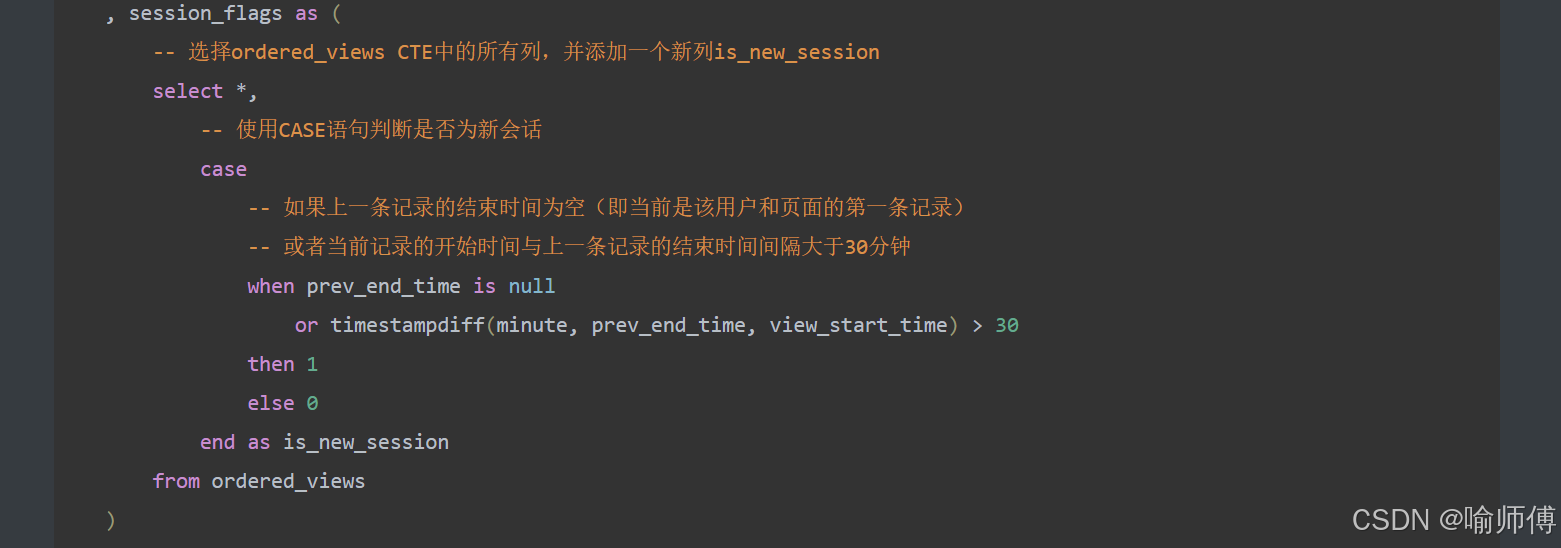
中间表 session_flags ✅
| user_id | page_url | is_new_session |
|---|---|---|
| User1 | https://example.com | 1 |
| User1 | https://example.com | 0 |
| User1 | https://example.com | 0 |
| User2 | https://example.net | 1 |
| User2 | https://example.net | 1 |
步骤3:生成会话分组ID✅
session_groups as(select*,sum(is_new_session) over(partition by user_id, page_url order by view_start_time) as session_groupfrom session_flags
)
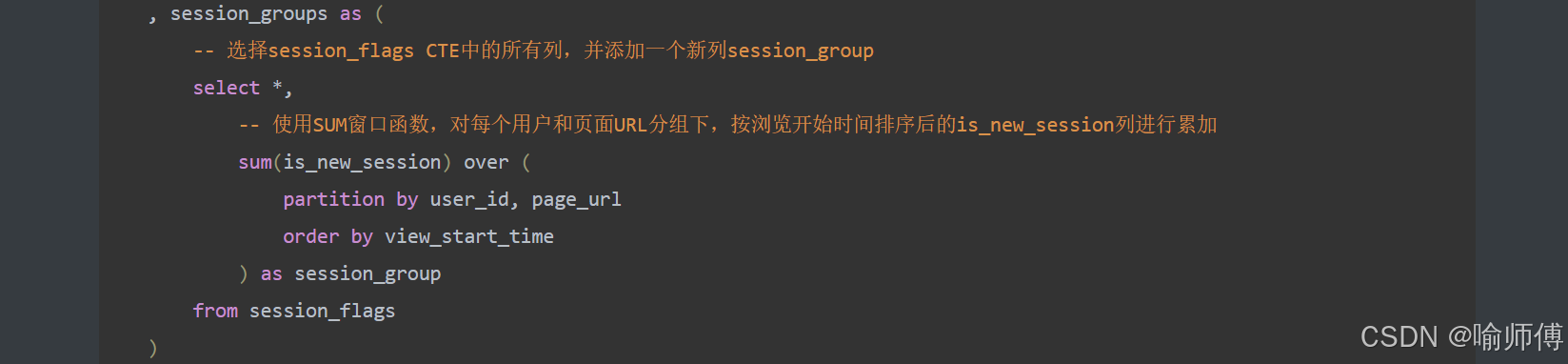
中间表 session_groups ✅
| user_id | page_url | session_group |
|---|---|---|
| User1 | https://example.com | 1 |
| User1 | https://example.com | 1 |
| User1 | https://example.com | 1 |
| User2 | https://example.net | 1 |
| User2 | https://example.net | 2 |
步骤4:分配唯一会话ID✅
session_ids AS (SELECT *,dense_rank() over (partition by user_id, page_url order by session_group ) as session_idfrom session_groups
)
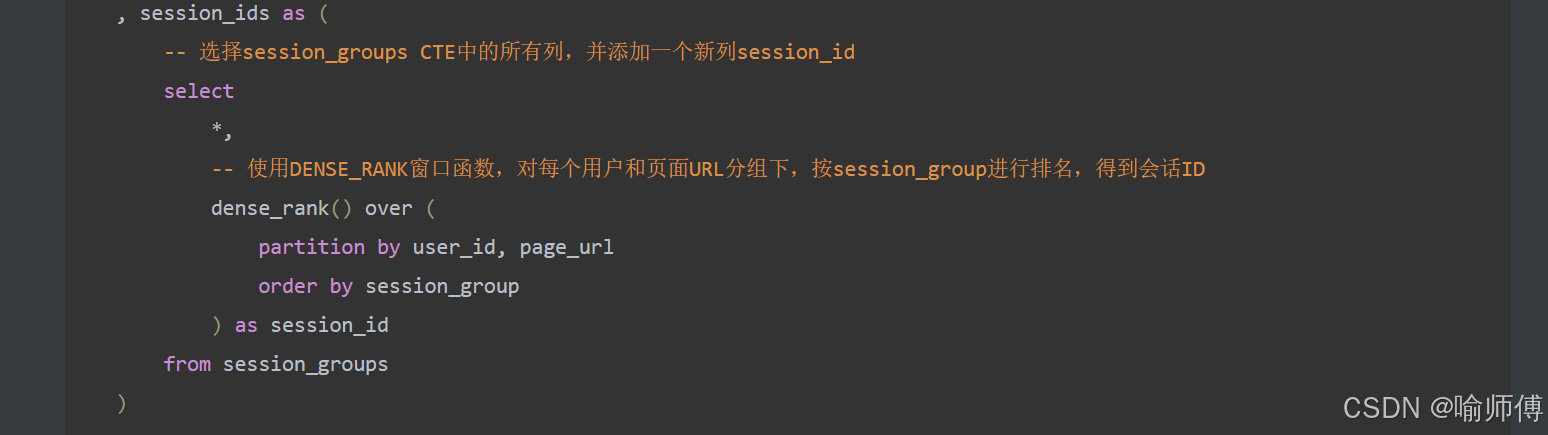
中间表 session_ids ✅
| user_id | page_url | session_id |
|---|---|---|
| User1 | https://example.com | 1 |
| User1 | https://example.com | 1 |
| User1 | https://example.com | 1 |
| User2 | https://example.net | 1 |
| User2 | https://example.net | 2 |
步骤5:聚合结果并计算双指标✅
selectuser_id,page_url,session_id,min(view_start_time) AS view_start_time,max(view_end_time) AS view_end_time,TIMESTAMPDIFF(MINUTE, min(view_start_time), max(view_end_time)) AS merged_duration,sum(TIMESTAMPDIFF(MINUTE, view_start_time, view_end_time)) AS total_real_duration
from session_ids
group by user_id, page_url, session_id;

最终结果 ✅
| user_id | page_url | session_id | view_start_time | view_end_time | merged_duration | total_real_duration |
|---|---|---|---|---|---|---|
| User1 | https://example.com | 1 | 2025-04-01 09:00:00 | 2025-04-01 09:30:00 | 30 | 20 |
| User2 | https://example.net | 1 | 2025-04-01 10:00:00 | 2025-04-01 10:15:00 | 15 | 15 |
| User2 | https://example.net | 2 | 2025-04-01 10:30:00 | 2025-04-01 10:45:00 | 15 | 15 |
还是有些难度的哈~
-- 使用CTE(公共表表达式),命名为ordered_views
with ordered_views as (-- 从“网站页面浏览记录表”中选择数据select user_id,page_url,view_start_time,view_end_time,-- 使用LAG窗口函数,获取每个用户和页面URL分组下,按浏览开始时间排序后的上一条记录的浏览结束时间lag(view_end_time) over (partition by user_id, page_url order by view_start_time) as prev_end_timefrom 网站页面浏览记录表
)
-- 第二个CTE,命名为session_flags
, session_flags as (-- 选择ordered_views CTE中的所有列,并添加一个新列is_new_sessionselect *,-- 使用CASE语句判断是否为新会话case -- 如果上一条记录的结束时间为空(即当前是该用户和页面的第一条记录)-- 或者当前记录的开始时间与上一条记录的结束时间间隔大于30分钟when prev_end_time is null or timestampdiff(minute, prev_end_time, view_start_time) > 30 then 1 else 0 end as is_new_sessionfrom ordered_views
)
-- 第三个CTE,命名为session_groups
, session_groups as (-- 选择session_flags CTE中的所有列,并添加一个新列session_groupselect *,-- 使用SUM窗口函数,对每个用户和页面URL分组下,按浏览开始时间排序后的is_new_session列进行累加sum(is_new_session) over (partition by user_id, page_url order by view_start_time) as session_groupfrom session_flags
)
-- 第四个CTE,命名为session_ids
, session_ids as (-- 选择session_groups CTE中的所有列,并添加一个新列session_idselect *,-- 使用DENSE_RANK窗口函数,对每个用户和页面URL分组下,按session_group进行排名,得到会话IDdense_rank() over (partition by user_id, page_url order by session_group) as session_idfrom session_groups
)-- 主查询
select user_id,page_url,session_id,-- 对于每个用户、页面和会话ID分组,获取最小的浏览开始时间min(view_start_time) as view_start_time,-- 对于每个用户、页面和会话ID分组,获取最大的浏览结束时间max(view_end_time) as view_end_time,-- 计算合并后的会话时长(以分钟为单位)timestampdiff(minute, min(view_start_time), max(view_end_time)) as merged_duration,-- 计算每个会话内实际的浏览时长总和(以分钟为单位)sum(timestampdiff(minute, view_start_time, view_end_time)) as total_real_duration
from session_ids
-- 按照用户ID、页面URL和会话ID进行分组
group by user_id, page_url, session_id
-- 按照用户ID、页面URL和会话ID进行排序
order by user_id, page_url, session_id;
三、公交乘客乘车时间分析🎈🎈🎈
根据公交乘客乘车记录,按照 “下车后90分钟内再次上车视为同一次出行” 的规则,完成以下任务:
- 分配出行ID:为每个乘客的每次连续出行分配唯一ID
- 计算双指标:
- 合并时长:从首次上车到最后一次下车的总时间跨度
- 实际时长:累加各次乘车的独立时长
| 表名 | 字段名 | 字段含义 | 数据类型 |
|---|---|---|---|
| 公交乘车记录表 | passenger_id | 乘客标识 | VARCHAR |
boarding_time | 上车时间 | DATETIME | |
alighting_time | 下车时间 | DATETIME |
| passenger_id | boarding_time | alighting_time |
|---|---|---|
| P001 | 2025-04-01 08:00:00 | 2025-04-01 08:30:00 |
| P001 | 2025-04-01 08:40:00 | 2025-04-01 09:00:00 |
| P002 | 2025-04-01 09:30:00 | 2025-04-01 10:00:00 |
| P001 | 2025-04-01 09:10:00 | 2025-04-01 09:30:00 |
| P002 | 2025-04-01 10:40:00 | 2025-04-01 11:00:00 |
结果预期 ✅
| passenger_id | trip_id | boarding_time | alighting_time | merged_duration | total_actual_duration |
|---|---|---|---|---|---|
| P001 | 1 | 2025-04-01 08:00:00 | 2025-04-01 09:30:00 | 90 | 70 (30+20+20) |
| P002 | 1 | 2025-04-01 09:30:00 | 2025-04-01 10:00:00 | 30 | 30 |
| P002 | 2 | 2025-04-01 10:40:00 | 2025-04-01 11:00:00 | 20 | 20 |
换汤不换药~😂
步骤1:排序并获取前次下车时间✅

中间表 ordered_records ✅
| passenger_id | boarding_time | alighting_time | prev_alighting_time |
|---|---|---|---|
| P001 | 2025-04-01 08:00:00 | 2025-04-01 08:30:00 | NULL |
| P001 | 2025-04-01 08:40:00 | 2025-04-01 09:00:00 | 2025-04-01 08:30:00 |
| P001 | 2025-04-01 09:10:00 | 2025-04-01 09:30:00 | 2025-04-01 09:00:00 |
| P002 | 2025-04-01 09:30:00 | 2025-04-01 10:00:00 | NULL |
| P002 | 2025-04-01 10:40:00 | 2025-04-01 11:00:00 | 2025-04-01 10:00:00 |
步骤2:标记新出行起点✅
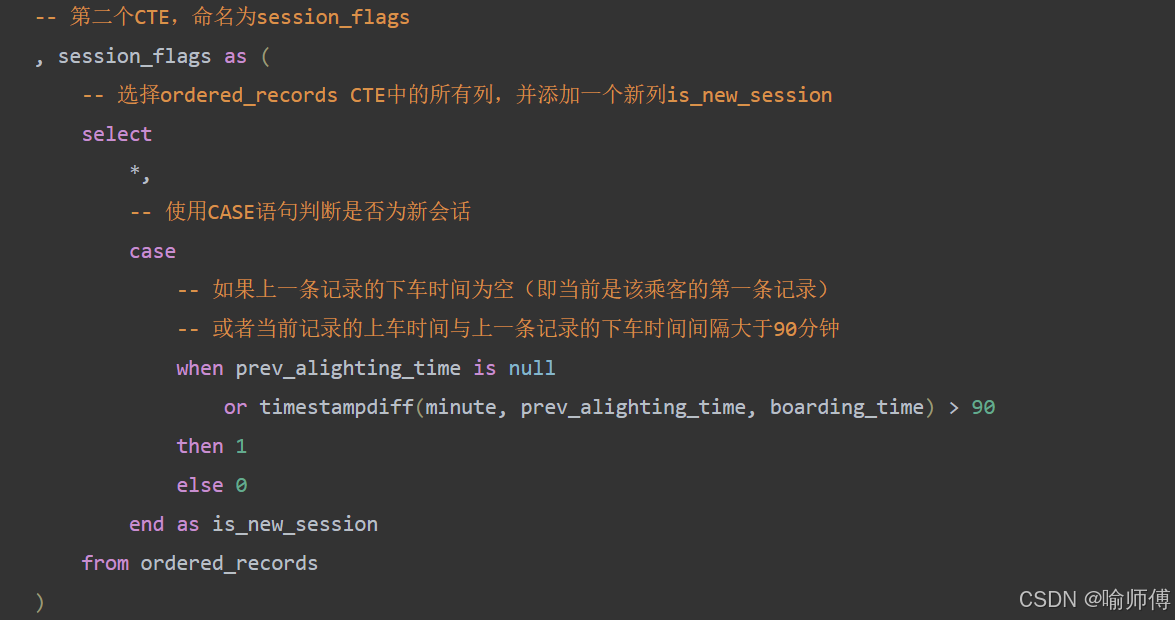
中间表 session_flags ✅
| passenger_id | is_new_session |
|---|---|
| P001 | 1 (首条记录) |
| P001 | 0 (间隔10分钟) |
| P001 | 0 (间隔10分钟) |
| P002 | 1 |
| P002 | 1 (间隔40分钟) |
步骤3:生成出行分组ID✅
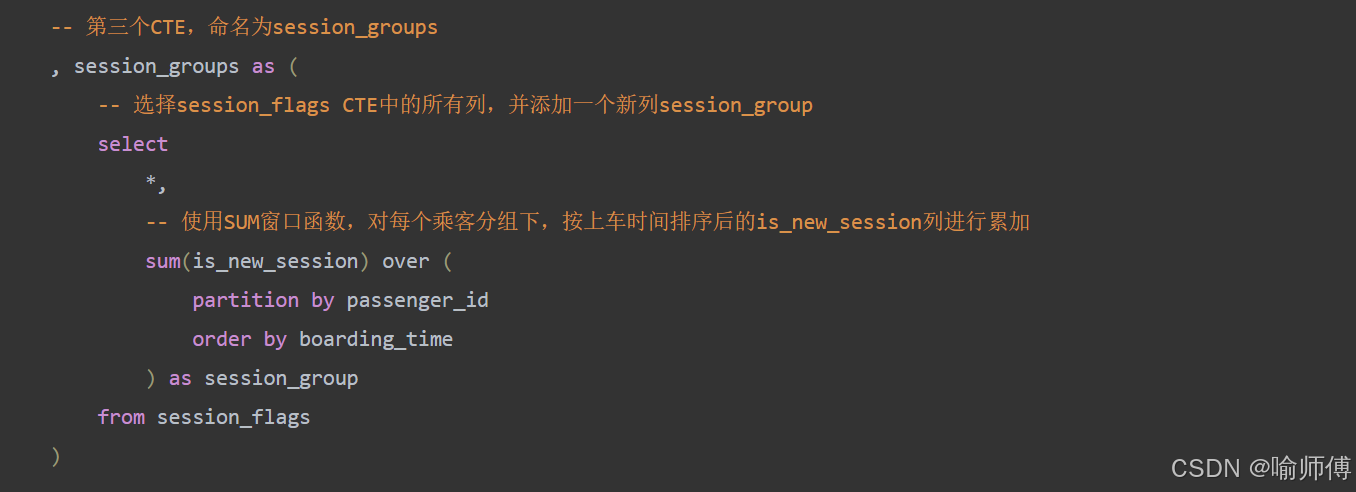
中间表 session_groups ✅
| passenger_id | session_group |
|---|---|
| P001 | 1 |
| P001 | 1 |
| P001 | 1 |
| P002 | 1 |
| P002 | 2 |
步骤4:分配出行ID并聚合结果✅
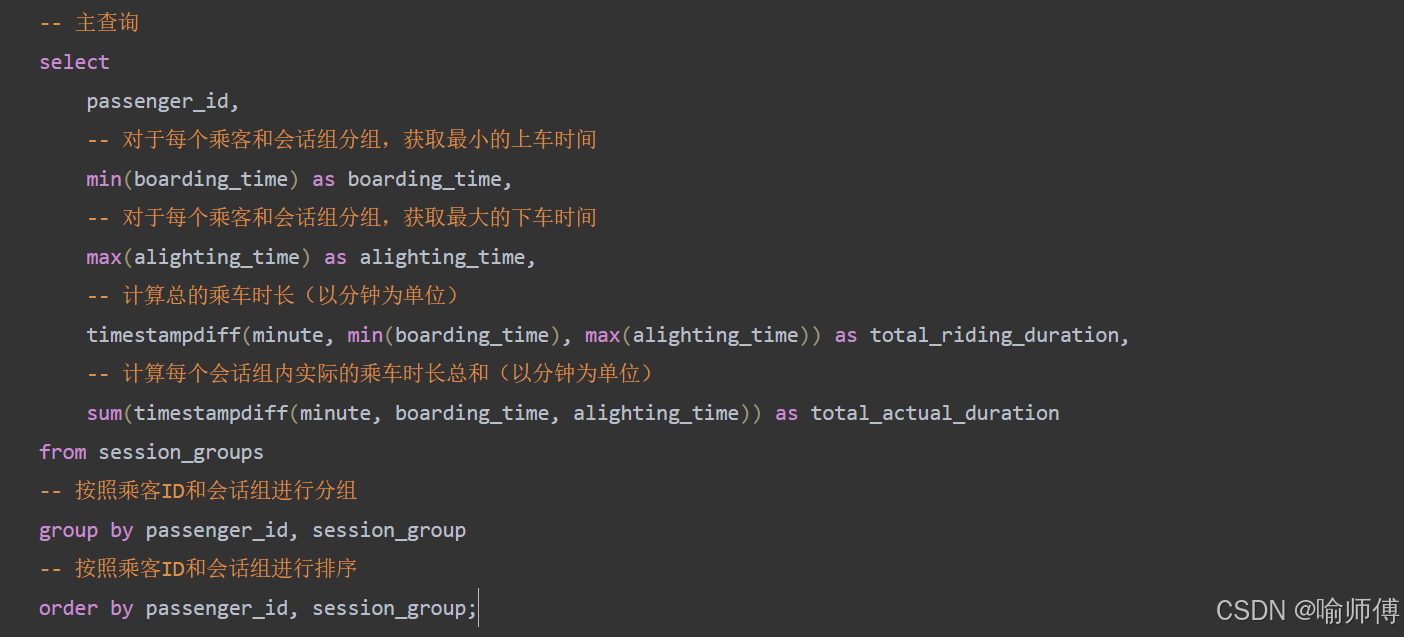
最终结果 ✅
| passenger_id | boarding_time | alighting_time | total_riding_duration | total_actual_duration |
|---|---|---|---|---|
| P001 | 2025-04-01 08:00:00 | 2025-04-01 09:30:00 | 90 | 70 (30+20+20) |
| P002 | 2025-04-01 09:30:00 | 2025-04-01 10:00:00 | 30 | 30 |
| P002 | 2025-04-01 10:40:00 | 2025-04-01 11:00:00 | 20 | 20 |
-- 使用CTE(公共表表达式),命名为ordered_records
with ordered_records as (-- 从“公交乘车记录表”中选择数据select passenger_id,boarding_time,alighting_time,-- 使用LAG窗口函数,获取每个乘客分组下,按上车时间排序后的上一条记录的下车时间lag(alighting_time) over (partition by passenger_id order by boarding_time) as prev_alighting_timefrom 公交乘车记录表
)
-- 第二个CTE,命名为session_flags
, session_flags as (-- 选择ordered_records CTE中的所有列,并添加一个新列is_new_sessionselect *,-- 使用CASE语句判断是否为新会话case -- 如果上一条记录的下车时间为空(即当前是该乘客的第一条记录)-- 或者当前记录的上车时间与上一条记录的下车时间间隔大于90分钟when prev_alighting_time is null or timestampdiff(minute, prev_alighting_time, boarding_time) > 90 then 1 else 0 end as is_new_sessionfrom ordered_records
)
-- 第三个CTE,命名为session_groups
, session_groups as (-- 选择session_flags CTE中的所有列,并添加一个新列session_groupselect *,-- 使用SUM窗口函数,对每个乘客分组下,按上车时间排序后的is_new_session列进行累加sum(is_new_session) over (partition by passenger_id order by boarding_time) as session_groupfrom session_flags
)-- 主查询
select passenger_id,-- 对于每个乘客和会话组分组,获取最小的上车时间min(boarding_time) as boarding_time,-- 对于每个乘客和会话组分组,获取最大的下车时间max(alighting_time) as alighting_time,-- 计算总的乘车时长(以分钟为单位)timestampdiff(minute, min(boarding_time), max(alighting_time)) as total_riding_duration,-- 计算每个会话组内实际的乘车时长总和(以分钟为单位)sum(timestampdiff(minute, boarding_time, alighting_time)) as total_actual_duration
from session_groups
-- 按照乘客ID和会话组进行分组
group by passenger_id, session_group
-- 按照乘客ID和会话组进行排序
order by passenger_id, session_group;
熟悉的套路😂
| 步骤 | 核心操作 | 关键函数/逻辑 |
|---|---|---|
| 数据排序 | 按乘客和时间排序 | LAG() + 窗口排序 |
| 标记新出行起点 | 判断90分钟间隔 | TIMESTAMPDIFF() + CASE |
| 生成分组ID | 累加标记值 | SUM() OVER() |
| 聚合结果 | 计算时间跨度和实际时长 | MIN()/MAX()/SUM() |
后面大家可以自己做一做 博主就不啰嗦啦~ 答案贴在最后啦 做完再看哈🤣
📚 时间序列分组与合并扩展题库
题目一:用户登录会话合并
题干
合并用户登录记录,若两次登录间隔 ≤15分钟 视为同一会话,计算每个会话的持续时间和登录次数。
表结构
| 表名 | 字段名 | 字段含义 | 数据类型 |
|---|---|---|---|
| user_login | user_id | 用户ID | VARCHAR |
| login_time | 登录时间 | DATETIME |
示例数据
| user_id | login_time |
|---|---|
| U1001 | 2024-03-01 08:00:00 |
| U1001 | 2024-03-01 08:05:00 |
| U1001 | 2024-03-01 08:25:00 |
期望输出
| user_id | session_start | session_end | duration_min | login_count |
|---|---|---|---|---|
| U1001 | 2024-03-01 08:00:00 | 2024-03-01 08:05:00 | 5 | 2 |
| U1001 | 2024-03-01 08:25:00 | 2024-03-01 08:25:00 | 0 | 1 |
题目二:设备故障时段统计
题干
合并设备的连续故障时段(故障状态代码=500),若两次故障间隔 ≤10分钟 视为同一故障事件。
表结构
| 表名 | 字段名 | 字段含义 | 数据类型 |
|---|---|---|---|
| device_log | device_id | 设备ID | VARCHAR |
| log_time | 日志时间 | DATETIME | |
| status_code | 状态码 | INT |
示例数据
| device_id | log_time | status_code |
|---|---|---|
| D001 | 2024-03-01 10:00:00 | 500 |
| D001 | 2024-03-01 10:05:00 | 500 |
| D001 | 2024-03-01 10:20:00 | 500 |
期望输出
| device_id | start_time | end_time | error_duration_min |
|---|---|---|---|
| D001 | 2024-03-01 10:00:00 | 2024-03-01 10:05:00 | 5 |
| D001 | 2024-03-01 10:20:00 | 2024-03-01 10:20:00 | 0 |
题目三:订单支付超时分析
题干
合并订单的创建和支付操作,若支付时间在创建后 30分钟内 视为有效支付,统计每个订单的实际支付处理时长。
表结构
| 表名 | 字段名 | 字段含义 | 数据类型 |
|---|---|---|---|
| orders | order_id | 订单ID | VARCHAR |
| create_time | 创建时间 | DATETIME | |
| pay_time | 支付时间 | DATETIME |
示例数据
| order_id | create_time | pay_time |
|---|---|---|
| O1001 | 2024-03-01 12:00:00 | 2024-03-01 12:05:00 |
| O1001 | 2024-03-01 12:10:00 | 2024-03-01 12:30:00 |
| O1002 | 2024-03-01 13:00:00 | NULL |
期望输出
| order_id | valid_pay_duration_min |
|---|---|
| O1001 | 25 (12:05-12:30) |
| O1002 | 0 |
题目四:交通卡口连续通行分析
题干
合并车辆通过相邻卡口的记录,若通过时间间隔 ≤5分钟 且行驶方向相同,视为连续通行,计算平均速度。
表结构
| 表名 | 字段名 | 字段含义 | 数据类型 |
|---|---|---|---|
| traffic_log | car_plate | 车牌号 | VARCHAR |
| direction | 行驶方向 | VARCHAR | |
| pass_time | 通过时间 | DATETIME | |
| location | 卡口位置 | VARCHAR |
示例数据
| car_plate | direction | pass_time | location |
|---|---|---|---|
| 沪A12345 | 东向 | 2024-03-01 09:00:00 | 卡口A |
| 沪A12345 | 东向 | 2024-03-01 09:03:00 | 卡口B |
| 沪A12345 | 东向 | 2024-03-01 09:10:00 | 卡口C |
期望输出
| car_plate | start_time | end_time | avg_speed_kmh |
|---|---|---|---|
| 沪A12345 | 2024-03-01 09:00:00 | 2024-03-01 09:10:00 | 48 |
答案:
题目一:用户登录会话合并
-- 使用公共表表达式(CTE),命名为 ordered_logins
with ordered_logins as (-- 从 user_login 表中选择数据select user_id,login_time,-- 使用 LAG 窗口函数,在每个 user_id 分区内,按照 login_time 排序-- 获取当前记录的上一条记录的 login_time,命名为 prev_loginlag(login_time) over (partition by user_id order by login_time) as prev_loginfrom user_login
)
-- 第二个 CTE,命名为 session_flags
, session_flags as (-- 选择 ordered_logins CTE 中的所有列,并添加一个新列 is_new_sessionselect *,-- 使用 CASE 语句判断是否为新的会话case -- 如果上一条记录的登录时间为空(即当前是该用户的第一条登录记录)-- 或者当前记录的登录时间与上一条记录的登录时间间隔大于 15 分钟when prev_login is null or timestampdiff(minute, prev_login, login_time) > 15 then 1 else 0 end as is_new_sessionfrom ordered_logins
)
-- 第三个 CTE,命名为 session_groups
, session_groups as (-- 选择 session_flags CTE 中的所有列,并添加一个新列 session_idselect *,-- 使用 SUM 窗口函数,在每个 user_id 分区内,按照 login_time 排序-- 对 is_new_session 列进行累加,得到每个会话的唯一标识 session_idsum(is_new_session) over (partition by user_id order by login_time) as session_idfrom session_flags
)
-- 主查询
select user_id,-- 对于每个用户和会话 ID 分组,获取最小的登录时间作为会话开始时间min(login_time) as session_start,-- 对于每个用户和会话 ID 分组,获取最大的登录时间作为会话结束时间max(login_time) as session_end,-- 计算会话的持续时间(以分钟为单位)timestampdiff(minute, min(login_time), max(login_time)) as duration_min,-- 统计每个会话内的登录次数count(*) as login_count
from session_groups
-- 按照用户 ID 和会话 ID 进行分组
group by user_id, session_id;
题目二:设备故障时段统计
-- 使用公共表表达式(CTE),命名为 ordered_logs
with ordered_logs as (-- 从 device_log 表中选择数据,且只选择状态码为 500 的记录select device_id,log_time,-- 使用 LAG 窗口函数,在每个 device_id 分区内,按照 log_time 排序-- 获取当前记录的上一条记录的 log_time,命名为 prev_loglag(log_time) over (partition by device_id order by log_time) as prev_logfrom device_logwhere status_code = 500
)
-- 第二个 CTE,命名为 session_flags
, session_flags as (-- 选择 ordered_logs CTE 中的所有列,并添加一个新列 is_new_sessionselect *,-- 使用 CASE 语句判断是否为新的故障时段case -- 如果上一条记录的日志时间为空(即当前是该设备的第一条故障记录)-- 或者当前记录的日志时间与上一条记录的日志时间间隔大于 10 分钟when prev_log is null or timestampdiff(minute, prev_log, log_time) > 10 then 1 else 0 end as is_new_sessionfrom ordered_logs
)
-- 第三个 CTE,命名为 session_groups
, session_groups as (-- 选择 session_flags CTE 中的所有列,并添加一个新列 session_idselect *,-- 使用 SUM 窗口函数,在每个 device_id 分区内,按照 log_time 排序-- 对 is_new_session 列进行累加,得到每个故障时段的唯一标识 session_idsum(is_new_session) over (partition by device_id order by log_time) as session_idfrom session_flags
)
-- 主查询
select device_id,-- 对于每个设备和故障时段 ID 分组,获取最小的日志时间作为故障开始时间min(log_time) as start_time,-- 对于每个设备和故障时段 ID 分组,获取最大的日志时间作为故障结束时间max(log_time) as end_time,-- 计算故障时段的持续时间(以分钟为单位)timestampdiff(minute, min(log_time), max(log_time)) as error_duration_min
from session_groups
-- 按照设备 ID 和故障时段 ID 进行分组
group by device_id, session_id;
题目三:订单支付超时分析
select order_id,-- 使用 COALESCE 函数,若第一个参数不为 NULL,则返回第一个参数的值,否则返回第二个参数的值-- 这里计算有效支付时长(以分钟为单位)coalesce(-- 计算在创建时间和支付时间间隔不超过 30 分钟的情况下,最大支付时间和最小支付时间的差值(以分钟为单位)timestampdiff(minute, min(case when timestampdiff(minute, create_time, pay_time) <= 30 then pay_time end), max(case when timestampdiff(minute, create_time, pay_time) <= 30 then pay_time end)), 0) as valid_pay_duration_min
from orders
-- 按照订单 ID 进行分组
group by order_id;
题目四:交通卡口连续通行分析
-- 使用公共表表达式(CTE),命名为 ordered_passes
with ordered_passes as (-- 从 traffic_log 表中选择数据select car_plate,direction,pass_time,-- 使用 LAG 窗口函数,在每个 car_plate 和 direction 分区内,按照 pass_time 排序-- 获取当前记录的上一条记录的 pass_time,命名为 prev_passlag(pass_time) over (partition by car_plate, direction order by pass_time) as prev_passfrom traffic_log
)
-- 第二个 CTE,命名为 session_flags
, session_flags as (-- 选择 ordered_passes CTE 中的所有列,并添加一个新列 is_new_groupselect *,-- 使用 CASE 语句判断是否为新的连续通行组case -- 如果上一条记录的通过时间为空(即当前是该车牌和方向的第一条记录)-- 或者当前记录的通过时间与上一条记录的通过时间间隔大于 5 分钟when prev_pass is null or timestampdiff(minute, prev_pass, pass_time) > 5 then 1 else 0 end as is_new_groupfrom ordered_passes
)
-- 第三个 CTE,命名为 session_groups
, session_groups as (-- 选择 session_flags CTE 中的所有列,并添加一个新列 group_idselect *,-- 使用 SUM 窗口函数,在每个 car_plate 和 direction 分区内,按照 pass_time 排序-- 对 is_new_group 列进行累加,得到每个连续通行组的唯一标识 group_idsum(is_new_group) over (partition by car_plate, direction order by pass_time) as group_idfrom session_flags
)
-- 第四个 CTE,命名为 aggregated
, aggregated as (-- 选择 car_plate、计算每个连续通行组的最小通过时间、最大通过时间和通过次数select car_plate,min(pass_time) as start_time,max(pass_time) as end_time,count(*) as num_passesfrom session_groups-- 按照 car_plate、direction 和 group_id 进行分组group by car_plate, direction, group_id
)
-- 主查询
select car_plate,start_time,end_time,-- 计算平均速度(单位:km/h),假设每次通过间隔 4 公里((num_passes - 1) * 4)-- 用通过间隔距离除以总时间(以小时为单位),并四舍五入到整数round((num_passes - 1) * 4 / (timestampdiff(minute, start_time, end_time) / 60.0), 0) as avg_speed_kmh
from aggregated
-- 只选择通过次数大于 1 的记录
where num_passes > 1;
