一。Mycat介绍
1.1简要概述
Mycat是一款分布式关系型数据库(中间件),它支持分布式SQL查询,兼容MySQL通信协议,以Java生态支持多种后端数据库,通过数据分片提高数据查询处理能力。
MyCAT是目前最流行的分布式数据库中间插件,是一个开源的分布式数据库系统,是一个实现了MySQL协议的服务器。前端用户可以把它看作一个数据库代理,用MySQL客户端工具和命令行访问,其后端可以用MySQL原生协议与多个MySQL服务器通信,也可以用JDBC协议与大多数主流数据库服务器通信,其核心功能是*分表分库*,即将一个大表水平分割为N个小表,存储在后端MySQL服务器里或者其他数据库里。
MyCAT发展到目前,已经不是一个单纯的MySQL代理了,它的后端可以支持MySQL,SQLServer、Oracle、DB2、PostgreSQL等主流数据库,也支持MongoDB这种新型NoSQL方式的存储。未来,它还会支持更多类型的存储。
不过,无论是哪种存储方式,在最终用户看,MyCAT里都是一个传统的数据库表,支持标准的SQL语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度。
1.2优点
1.支持读写分离,支持Mysgl双主多从,以及一主多从的模式
2.支持全局表,数据自动分片到多个节点,用于高效表关联查询
3.支持独有的基于E-R关系的分片策略,实现了高效的表关联查询
4.自动故障切换,高可用性
5.提供高可用性数据分片集群
6.支持JDBC连接ORACLE、DB2、SQL Server,将其模拟为 MySQL Server使用
7.支持Mysgl集群,可以作为Proxy使用
8.基于阿里开源的Cobar产品而研发,Cobar的稳定性、可靠性、优秀的架构和性能
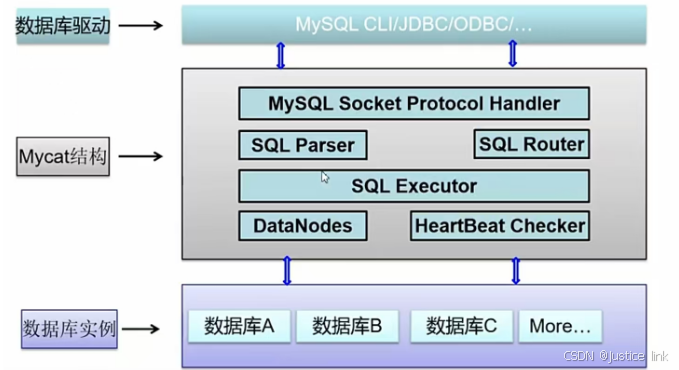
1.3Mycat框架
1.4为什么使用Mycat?
随着互联网的发展,数据的量级也是呈指数的增长,从GB到TB到PB,操作数据也是愈加的困难,传统的关系性数据库已经无法满足快速查询与插入数据的需求。
而NoSQL的出现暂时解决了这一危机。
NoSQL通过降低数据的安全性,减少对事务的支持,减少对复杂查询的支持,来提升性能。但是,NoSQL存在无法满足某些使用场景的情况,比如,有些使用场景绝对要有事务与安全指标。这时NoSQL肯定无法满足。
所以,我们还是需要使用关系型数据库。
那么,如何使用关系型数据库解决海量存储的问题呢?此时就需要做数据库集群,为了提高查询性能将一个数据库的数据分散到不同的数据库中存储,为应对该问题,MyCAT就出现了。
1.5MyCAT的作用:
1能满足数据库数据大量存储,2提高了查询性能,3 实现读写分离,4.分库分表。
二。配置Mycat
1.下载软件包:
wget -c http://dl.mycat.org.cn/2.0/install-template/mycat2-install-template-1.21.zip
wget -c http://dl.mycat.org.cn/2.0/1/21-release/mycat2-1.21-release-jar-with-dependencies.jar
yum install unzip -y

2.进行压缩:
unzip mycat2-install-template-1.21.zip -d /usr/local
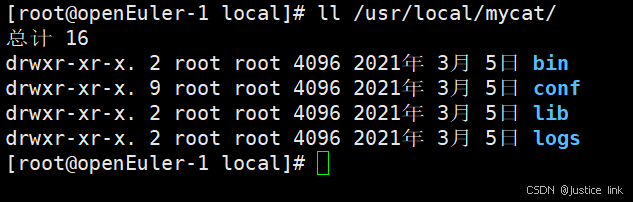
log:保存日志 lib:依赖包 conf:配置文件目录 bin:执行命令的目录
cp mycat2-1.21-release-jar-with-dependencies.jar /usr/local/mycat/lib/
3.修改文件夹及权限
chmod +x /usr/local/mycat/bin/*
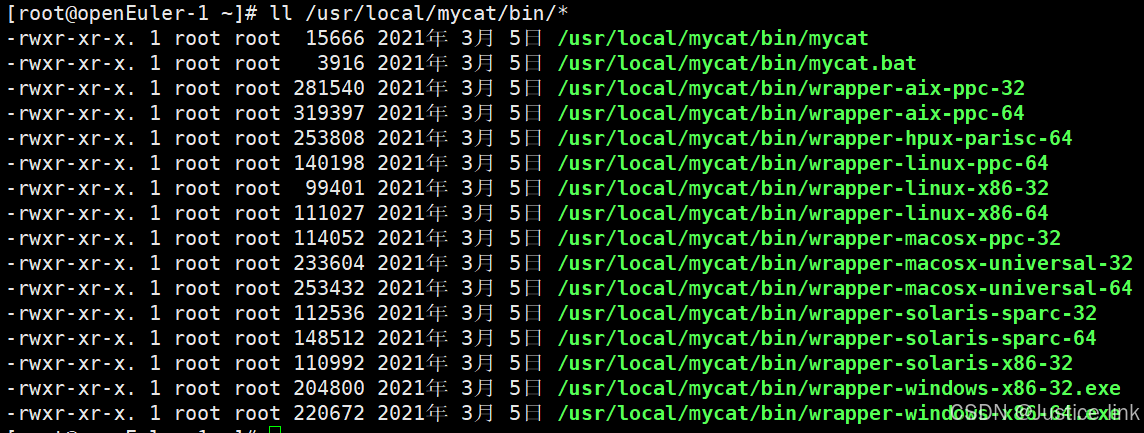
4.下载mysql并且启动
yum install mysql-server -y
systemctl enable --now mysqld
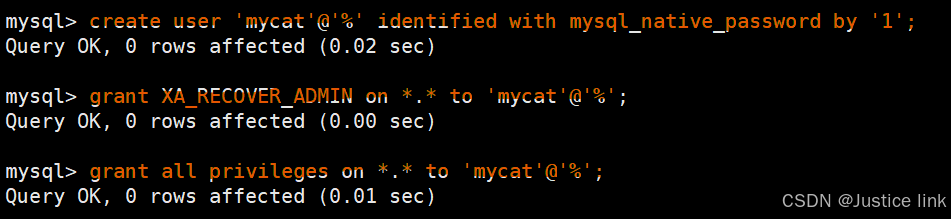
5.在mysql创建用户和授予权限(必须要mysql8.0以上,才可以进行第二条授权)
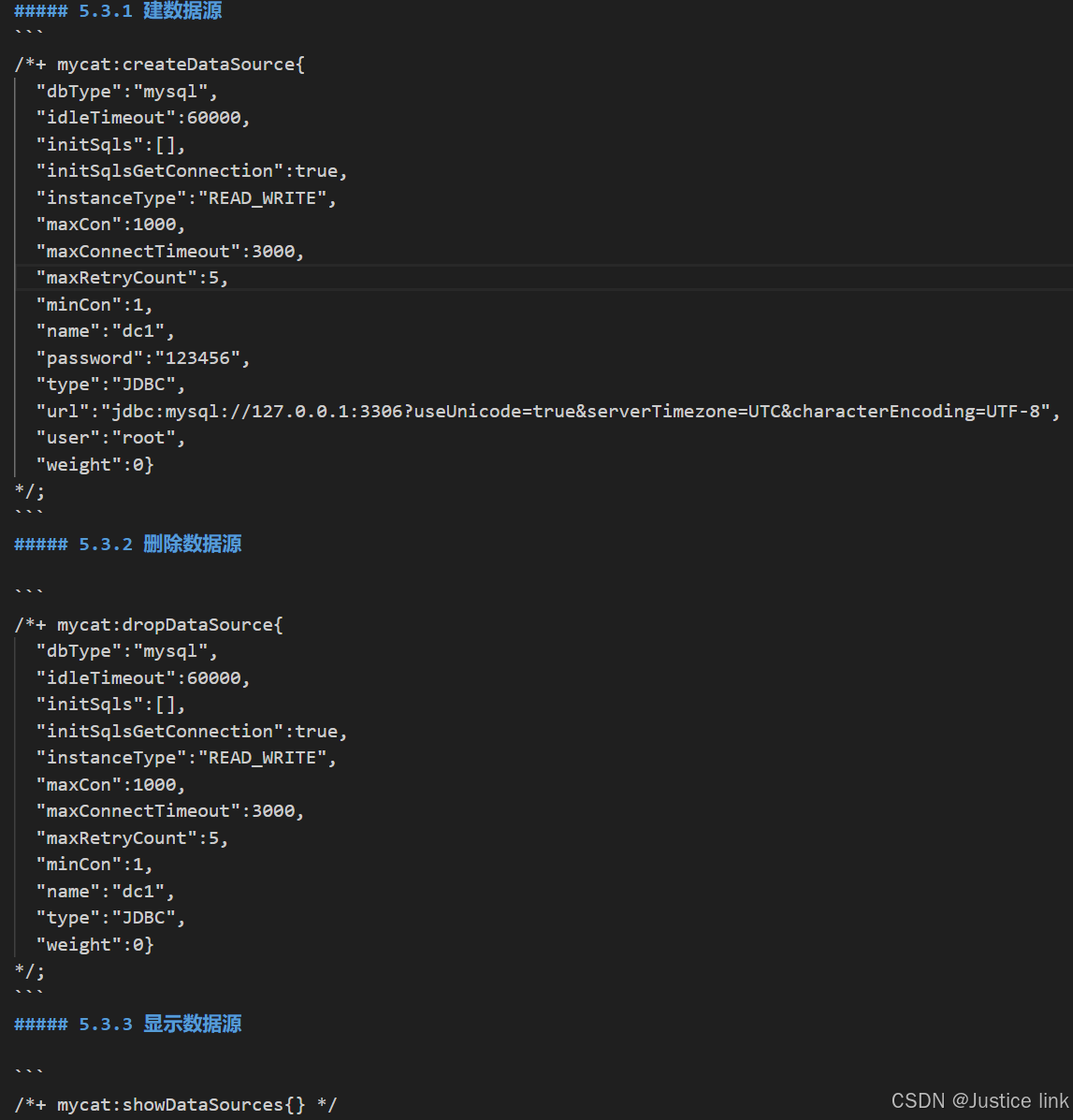
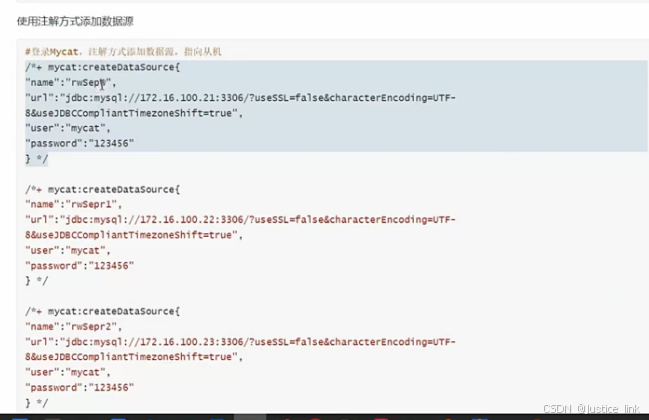
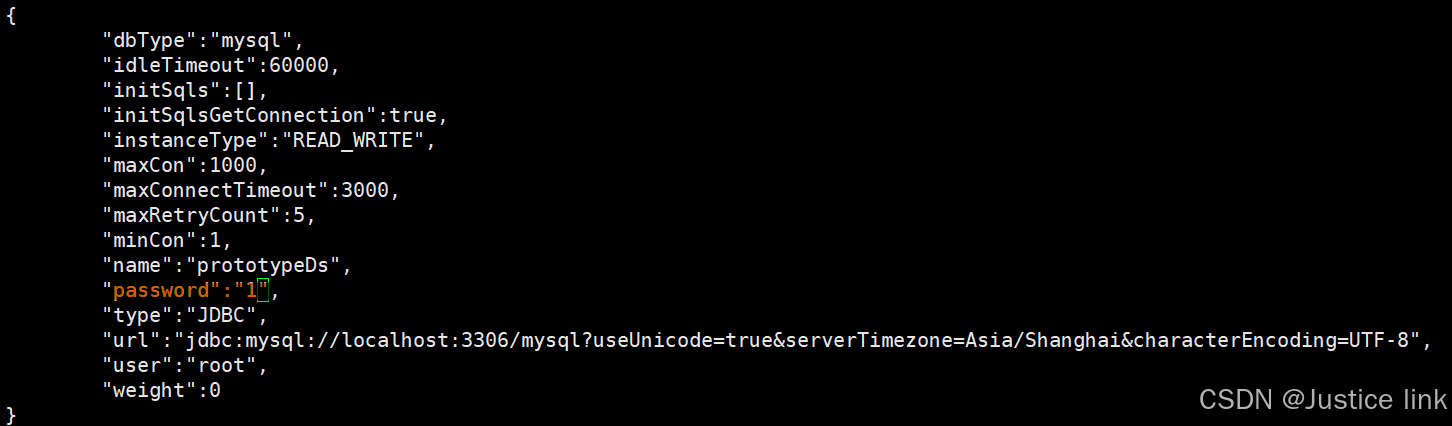
6.配置数据源:
vi /usr/local/mycat/conf/datasources/prototypeDs.datasource.json
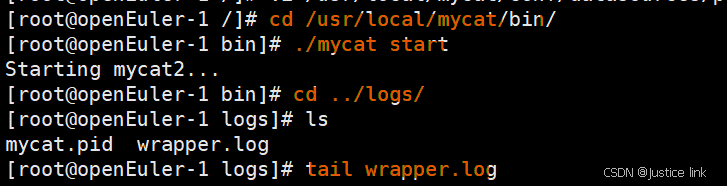
7.启动mycat:./mycat start:启动
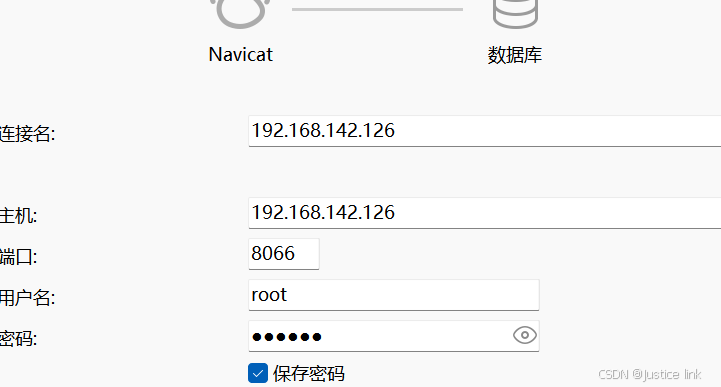
8.登陆数据库:默认数据端口为8066
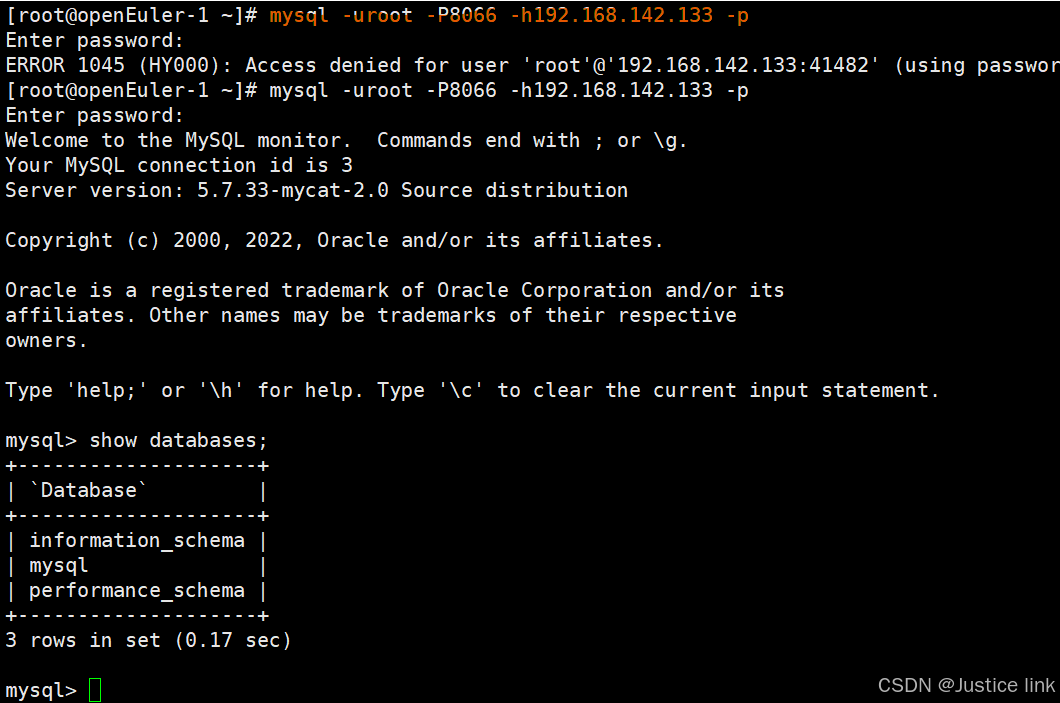
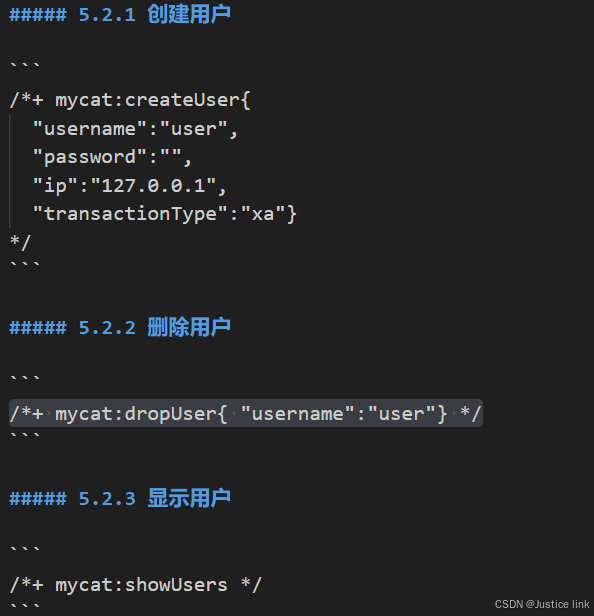
8.查看用户模块:
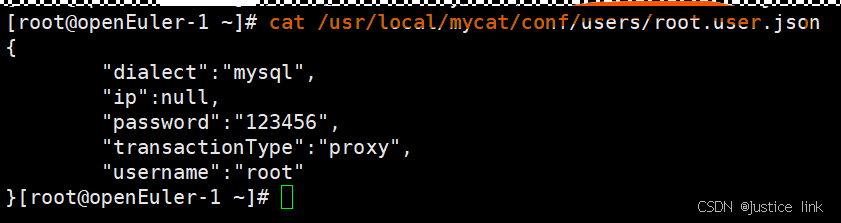
dialect:数据库类型
ip:配置白名单使用,一般写null,如果限制了这个用户
password:配置Mycat用户的密码(明文)
transactionType:本地事务proxy兼容性最好
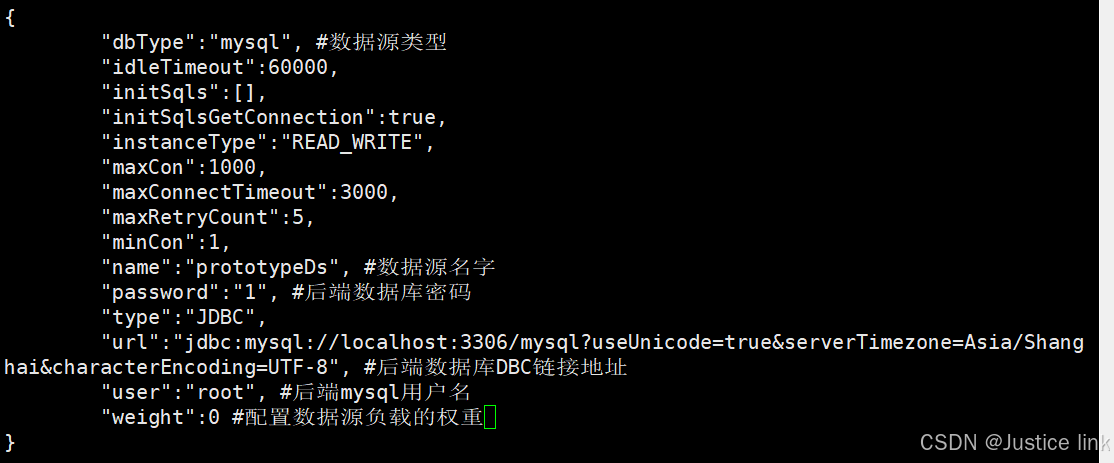
9.查看数据源:cat /usr/local/mycat/conf/datasources/prototypeDs.datasource.json
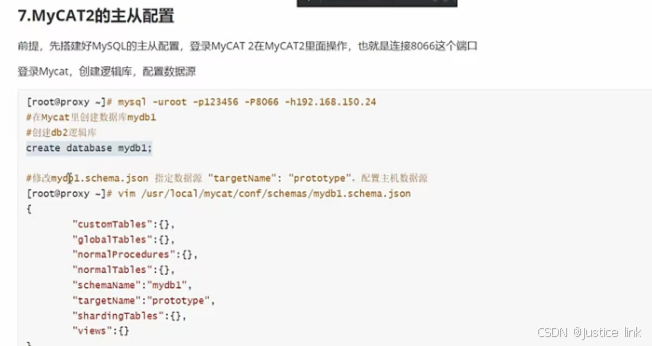
10.逻辑表与逻辑库:cat /usr/local/mycat/conf/schemas/{数据库}.schema.json
1)customTables:自定义表
2)globalTables:全局表
3)normalTables:默认表
4)schemaName:库名
5)shardingTables:分片表
6)targetName:数据源名,也可以是集群名
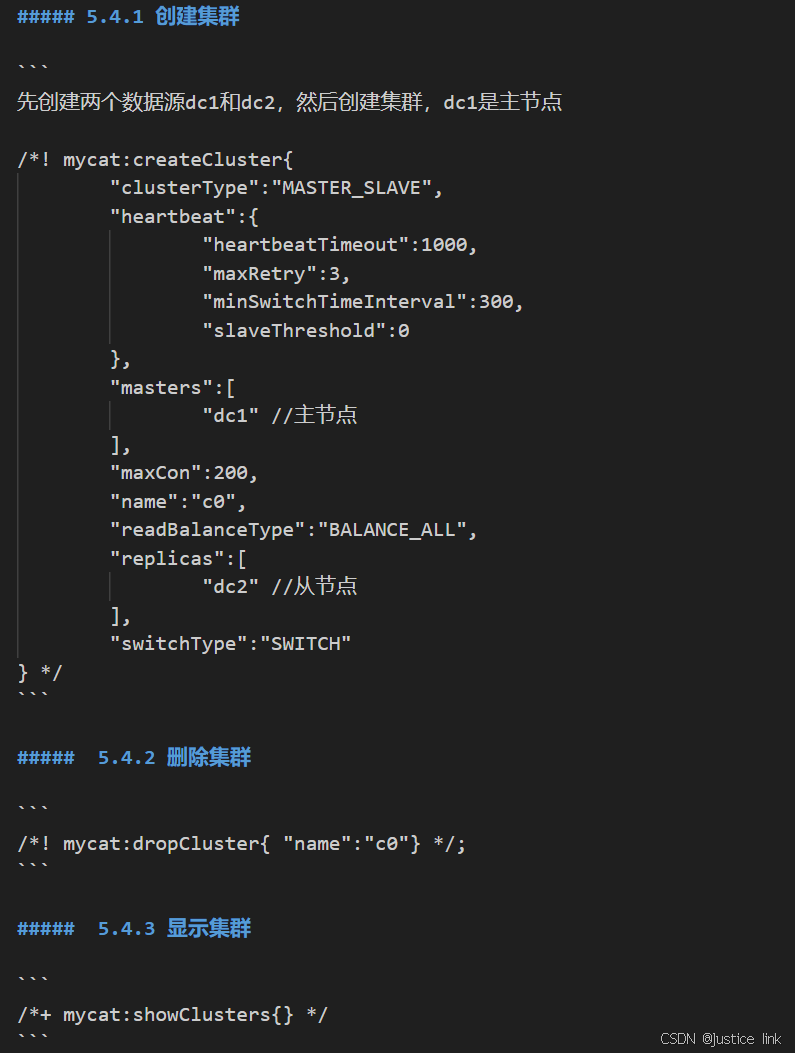
11.mycat操作:先链接数据库