

01.
概览
我们很高兴为大家带来 Milvus 2.5 最新版本的介绍。
在 Milvus 2.5 里,最重要的一个更新是我们带来了“全新”的全文检索能力,之所以说“全新”主要是基于以下两点:
第一,对于全文检索基于的 BM25 算法,我们采用的是 Sparse-BM25,基于 sparse vector 实现的 BM25 在存储效率、检索性能上都打开了更多的空间,同时也融合在了 Milvus 以向量为核心检索范式的产品理念里;
第二,我们首次在 Milvus 里引入了原始文本插入和查询的能力,不需要用户手动将文本转成 sparse vector,这使得 Milvus 朝着非结构化数据处理的方向迈进了一步。
而这两点在 Milvus 2.5 正是一个开始,在 2.5 发版的同时我们更新了 Milvus 产品路线图(https://milvus.io/docs/roadmap.md),在 Milvus 后续的产品迭代中,我们会着眼于从非结构化数据的处理、搜索质量与效率、数据管理和技术驱动降本这四大方向演进 Milvus 的各项能力,在 AI 数据爆发时代背景下做好既能“存得下”、又能“看得见”的数据基础设施。
02.
以向量为特色的全文检索功能
以典型的 RAG 场景为例,尽管语义搜索可以有更好的上下文感知和意图理解,但当用户的问题需要搜索具体的专有名词、序列号,又或者完全匹配一个短语时,具有关键词匹配能力的全文检索往往可以拿到更准确的结果。为了支持社区中对于全文检索的需求,Milvus 在 2.4 版本推出稀疏向量功能的时候,采用了额外的 pymilvus model library 中的 BM25 模块来进行文本稀疏向量的生成。然而这种外挂的实现也带来了只能单机使用,词表等参数无法动态更新以及管理困难等一系列痛点,而 Milvus 2.5 的全文检索将一次性解决这些问题。
Milvus 2.5 通过内置 Sparse-BM25 的方式对全文检索的核心组件进行了原生支持,具体包括:
基于 tantivy 构建的分词器:我们选择融入 tantivy 蓬勃发展的生态
原始文档的进出能力:支持直接插入和查询文本数据
BM25 相关性打分:基于 sparse vector 相似度来实现
首先,值得注意的是分词器的部分,对于有搜索引擎经验的用户来说其重要程度不言而喻,我们选择融入了发展良好的 tantivy 生态,基于 tantivy 构建了我们分词器的基础功能,而未来除了更多分词功能的支持和可观测性的优化之外,我们会探索基于深度学习的 tokenizer 和 stemmer 策略来进一步优化全文检索的表现。以下是在 Milvus 2.5 中使用和配置分词器的示例代码:
# 分词器配置
schema.add_field(field_name='text', datatype=DataType.VARCHAR, max_length=65535, enable_analyzer=True, # 在该列上开启分词器analyzer_params={"type": "english"}, # 配置分词器参数,此处选择 english 模版,此外也支持细粒度配置enable_match=True, # 构建针对 Text_Match 的倒排索引
)其次,在原始文档的处理方面,我们通过全文检索功能打开了这块的能力,用户所需要配置的是预定义在 schema 里,通过 add_function 方法新增一个从原始数据到 sparse vector 的 mapping 步骤,而这之后的增删改查等数据流都可以通过操作原始文档来完成,内部我们将其形象地称之为“Doc in Doc out”。而这只是在 2.5 迈出的第一步,在后续的大版本中,我们将对 dense/sparse embedding 新增 Data in Data out 的全面支持,我们的目标是构建非结构化数据与向量的映射来完成数据进出 Milvus 的能力。
# 在 schema 上定义好原始文本数据与向量的映射关系
bm25_function = Function(name="text_bm25_emb",input_field_names=["text"], # 输入的文本字段output_field_names=["sparse"], # 内部映射的 sparse 向量字段function_type=FunctionType.BM25, # 处理映射关系的模型
)schema.add_function(bm25_function)
...
# 支持原始文本进出
MilvusClient.insert('demo', [{'text': 'Artificial intelligence was founded as an academic discipline in 1956.'},{'text': 'Alan Turing was the first person to conduct substantial research in AI.'},{'text': 'Born in Maida Vale, London, Turing was raised in southern England.'},
])MilvusClient.search(collection_name='demo', data=['Who started AI research?'],anns_field='sparse',limit=3
)而在 BM25 相关性打分方面,我们采用了独特的 sparse vector 方案来做底层的实现,进而能充分利用 sparse vector 的优势,包括但不限于:
对长上下文 Query 可以构建图索引来加速搜索;
基于量化和 WAND 的 drop_ratio 等技术手段做近似匹配来提升性能;
更重要的是对于 Milvus 本身的产品而言,统一了语义检索和全文检索的表达方式,使用体验以及技术优化。
# 创建 sparse 列上的索引
index_params.add_index(field_name="sparse",index_type="AUTOINDEX", # 默认 WAND 索引metric_type="BM25" # 通过 metric_type 配置相关性打分
)# search 时可配置参数来加速搜索
search_params = {'params': {'drop_ratio_search': 0.6}, # WAND 的搜索参数配置可加速搜索}作为原生的向量数据库,Milvus 引入全文检索功能对基于 dense vector 的搜索能力进行了扩展,方便了用户构建更高质量的 AI 应用。在 Sparse-BM25 方面我们无疑是个探索者,但可以预见的是还有更多的优化手段能在未来尝试,相信这条路上将有更多旖旎风光可以分享给大家。
与全文检索同时推出的还有 Text Match 功能,该功能同样构建在分词的基础之上,通过 enable_match=True 开启。与全文检索不同的是它着重于关键词匹配,省去了文段相关性打分的能力,因此它的使用场景主要在匹配和过滤。需要注意的是 Text Match 中的 Query Text 的处理是分词后 OR 的逻辑,例如在下面的例子中,结果将返回 text 字段上含有 vector 或者 database 的所有文档。
filter = "TEXT_MATCH(text, 'vector database')"如果您的场景需要既匹配 vector 又匹配 database,那么您需要写两个单独的 Text Match 并叠加 AND 的方式以达成目的。
filter = "TEXT_MATCH(text, 'vector') and TEXT_MATCH(text, 'database')"03.
标量过滤性能大幅提升
对于标量过滤性能的重视源于我们发现无论是在图片搜索场景如自动驾驶找 corner case 的应用,或是在企业知识库的复杂 RAG 场景中,向量检索与元数据过滤的结合,会使得查询性能和准确度上都取得极大的增益,因此很适合企业级用户在大规模数据的应用场景下进行业务落地。
然而,在真实场景下,不同的数据过滤量、数据分布和查询模式都会对性能和结果产生影响,这块涉及到诸多算法、执行链路和存储索引上的优化,功能层面上在 Milvus 2.5 我们基本上补足了 Scalar Index 上的索引类型,其中新增的部分包括:BitMap Index,Array Inverted Index,以及对 Varchar 文本字段分词后的 Inverted Index 等,这些索引在一些具体且实际的场景都能拿到很好的优化效果。
具体来说:
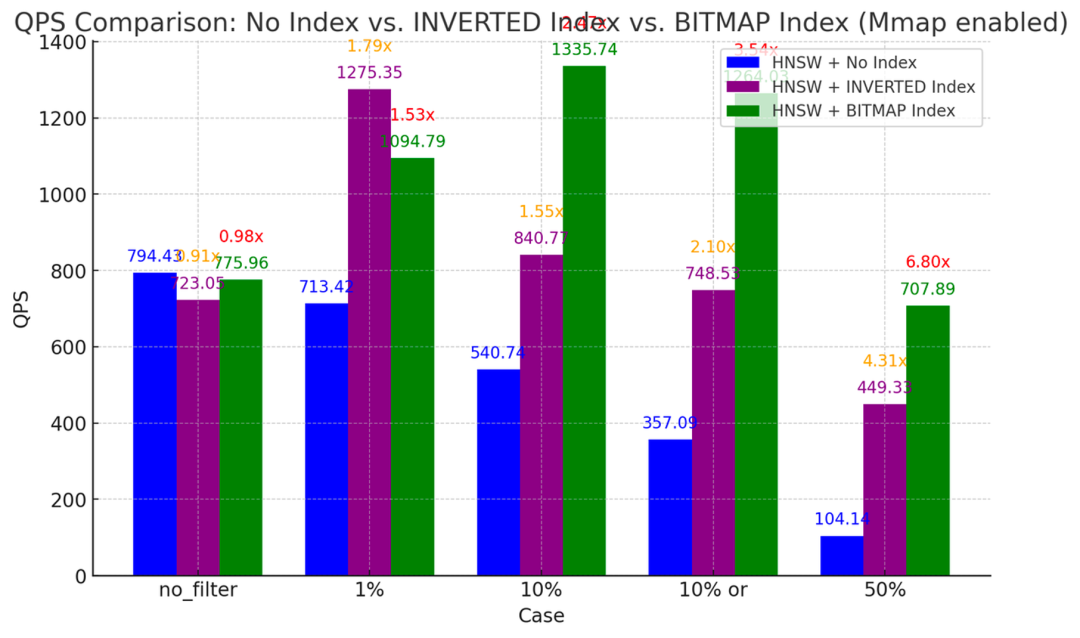
1、BitMap Index 可用于加速标签过滤(常用算子包括 in,array_contains 等),适用于字段类别数据(data cardinality)较少的场景,原理就是针对某行数据是否在某列上具有某个 value 来实现的,有就是 1, 没有就是 0,然后维护一个 BitMap 列表。以下图表展示了我们基于某客户业务场景下做的性能测试对比,这个场景的数据量是 5 亿,数据类别是 20,不同的值有不同的分布占比(1%,5%,10%,50%),在不同的过滤量的表现也有差别,在 50% 的过滤量下我们通过 BitMap Index 可以拿到 6.8 倍的性能收益。此外值得注意的是,随着 cardinality 的增加,相比于 BitMap Index, Inverted Index 将表现出更均衡的性能。
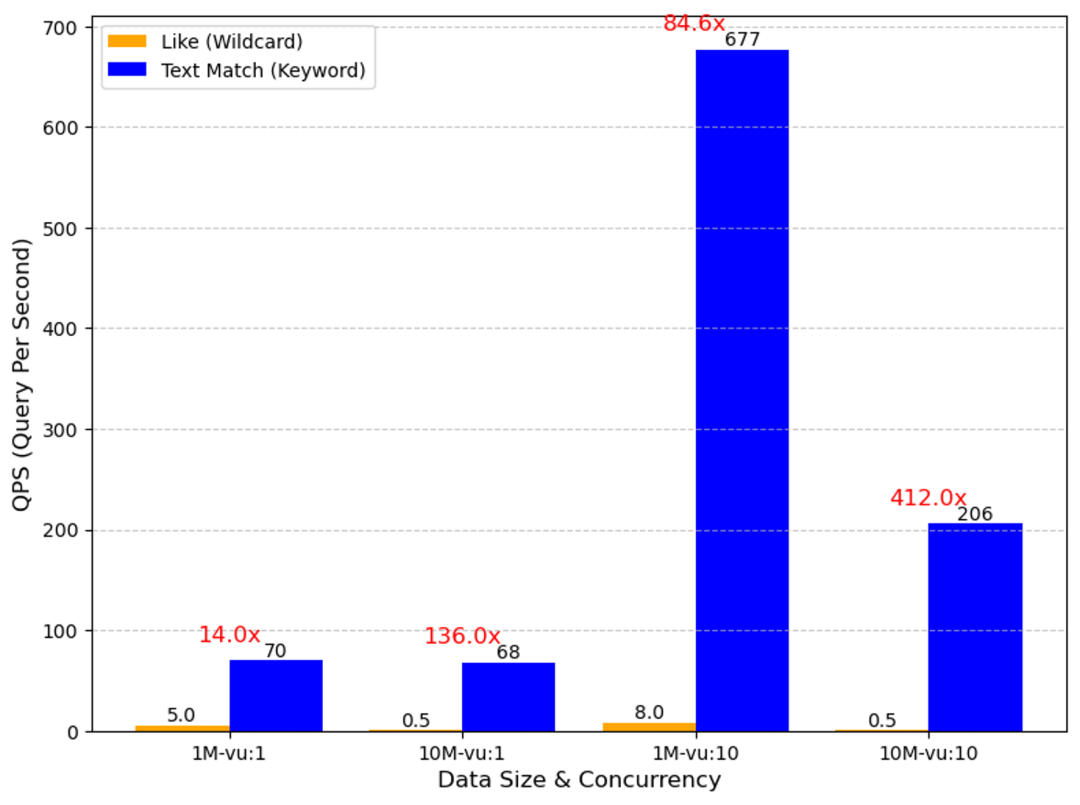
2、Text Match 是基于文本字段分词后的 Inverted Index 做的,其性能表现远超我们在 2.4 提供的 Wildcard Match(即 like + %)功能,从内部的测试结果来看 Text Match 的优势非常明显,尤其在并发查询的场景下,最多可以拿到 400 倍的 QPS 提升。
而在 JSON 数据的处理方面,我们计划在 2.5.x 的后续版本中推出针对用户指定的 key 来建倒排索引以及默认针对 key 的位置建立位置索引,预期这两块都会对 JSON 和 Dynamic Field 的查询性能提供很大帮助,更多的信息我们计划在后续的 release note 和技术博客中展示,敬请期待!
04.
易用性提升
此外值得一提的还有易用性的提升。这个版本我们向开源用户推出了 Cluster Management WebUI 工具,这是针对数据库管理员等专业人士提供的 Milvus 可观测性工具,通过访问集群端口 + 9091/webui 这个后缀用户可以轻松访问 Milvus 的集群信息和运行时状态,如各节点的内存、segment、slow query 信息等,以往一些诊断难的系统问题也可以通过这个工具方便快速地定位排查。虽然目前还只是 beta 版本,但未来我们也计划融入更多可诊断、可交互、可 AI 辅助的能力,帮助用户更省心地管理好 Milvus 集群。
最后一点是文档和 SDK/API 的优化,我们从 2.4 起持续投入了很多时间和精力来建设这块的能力,希望通过更合理的文档结构、更易懂的图表介绍、更好用的 SDK 以及像 ASK AI 这样更智能的交互形式来帮助用户更好地使用 Milvus,相信您在阅读 2.5.x 系列的新文档内容时也会感受到这份努力。但文档优化之路并非一朝一夕,其成果也不可能一蹴而就,我们还将持续优化和调整文档结构与内容,希望和社区用户共同成长,也欢迎大家通过各类渠道给我们反馈文档 bug 和优化建议。
在 Milvus 2.5 这个版本里,我们和社区一同贡献了 13 个新功能以及多个系统级优化,由于篇幅有限,这里就不一一列举了,欢迎访问我们的 release note(https://milvus.io/docs/release_notes.md) 以及官方文档,获取更多信息!
今晚 8 点,Milvus 资深产品经理张粲宇将在直播间全面解读 Milvus 2.5 的新功能及优化,同时 RWKV 高级大模型算法工程师岳紫寅将分享 Milvus 在 RWKV 的应用实践,请点击下方“预约”,共享这场技术碰撞之旅!
作者介绍

张粲宇
Zilliz 高级产品经理
推荐阅读



