项目地址
腾讯APIJSON官方网站
定义
APIJSON 可以定义为一个面向HTTP 协议的JSON 规范,一个面向数据访问层的ORM 框架。其主要工作流程包括:前端按照既定格式组装 JSON 请求报文,通过 APIJSON-ORM 将这些报文直接转换为 SQL 语句,进而执行数据库操作,如增删改查等。完成后,系统将数据再按照指定格式封装成 JSON 响应报文,高效地实现前后端的数据交互,并将最终结果反馈给用户。
架构

图2.1 基于APIJSON的交互流程图
通过图2.1 基于APIJSON的交互流程图我们可以发现,APIJSON 的设计思路,主要用于前端可以通过基于APIJSON的语法格式直接处理数据的增删改查。也可以说是后端通过使用APIJSON-ORM 框架,定义了一个万能的Controller接口层,从而使得前端可以通过这个接口实现全部的CRUD 操作。
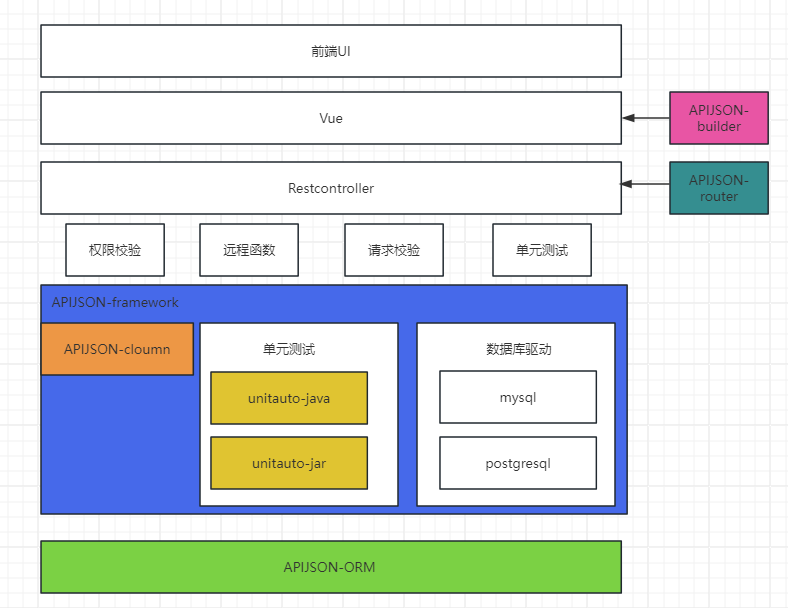
图2.2 基于APIJSON 构件生态的框架图
- APIJSON-ORM:APIJSON-ORM 是 APIJSON 框架的核心组件,它是一个对象关系映射(ORM)框架,专门用于将 JSON 格式的请求自动转换为 SQL 语句,从而快速实现对数据库的增删改查操作。
- APIJSON-framework:APIJSON-framework 是 APIJSON 的基础框架,它提供了一套完整的解决方案,包括请求的解析、处理、权限验证以及响应的封装等,还包含了基于unitAuto 的自动化单元测试的内容。这个框架使得开发者能够快速搭建起一个高效、安全、易用的后端 API 服务。
- APIJSON-cloumn:APIJSON 的字段处理插件,包含了表字段相关工具类
- unitauto-java:unitauto-java 是一个自动化测试框架,它可以自动生成和执行单元测试代码。这个框架旨在减少手动编写测试代码的工作量,提高代码质量和测试覆盖率。
- APIJSON-router:APIJSON 的路由插件,用于将Restful API 转成 APIJSON API格式请求
- APIJSON-builder:采用类似mybaits 中 wrapper 封装的方式组装前端请求报文。用于生成符合 APIJSON 规范的 JSON 请求和响应结构。
主要功能
- APIJSON 定义了前端请求后端操作数据库的JSON报文格式。
- APIJSON-framework 包含一套完整的前后端CRUD操作的解决方案,主要包括权限校验,远程函数/脚本调用,请求合法性校验, 单元测试等功能。
- APIJSON-ROM 简化了后端数据仓储层的操作,大大减少了软件运维过程中的重复造轮子过程,让开发者可以将精力专注于开发创新和商业赋能。
优缺点
- 优点:在此借用APIJSON 官网的图,来表述使用APIJSON的优点:


- 开发提速对比表:

- 缺点(个人观点):
- APIJSON-framework 依赖了mysql和postgresql两个数据库引擎,以及直接集成了作者的另一个自动化单元测试的项目UnitAuto。这使得APIJSON-framework 的技术架构耦合性比较高。
- APIJSON-cloumn 就是一个工具类,在我看来完全可以集成于APIJSON-framework
- APIJSON-ORM 的核心代码有待优化
使用规范
语法
"key[]":{} // 查询数组"key{}":[1,2,3] // 匹配选项范围"key{}":"<=10;length(key)>1..." // 匹配条件范围"key()":"function(arg0,arg1...)" // 远程调用函数"key@":"key0/key1.../targetKey" // 引用赋值"key$":"%abc%" // 模糊搜索"key~":"^[0-9]+$" // 正则匹配"key%":"2018-01-01,2018-10-01" // 连续范围"key+":[1] // 增加/扩展"key-":888.88 // 减少/去除 "name:alias" // 新建别名"@combine":"name~,tag~" // 条件组合"@column":"id,sex,name" // 返回字段"@group":"userId" // 分组方式"@having":"max(id)>=100" // 聚合函数"@order":"date-,name+" // 排序方式"@schema":"sys" // 集合空间"@database":"POSTGRESQL" // 跨数据库"@datasource":"DRUID" // 多数据源"@explain":true // 性能分析"@role":"LOGIN" // 访问角色功能列表
| 功能 | 键值对格式 | 使用示例 |
| 查询数组 | "key[]":{},后面是JSONObject,key可省略。当key和里面的Table名相同时,Table会被提取出来,即 {Table:{Content}} 会被转化为 {Content} | {"User[]":{"User":{}}}(opens new window) ,查询一个User数组。这里key和Table名都是User,User会被提取出来,即 {"User":{"id", ...}} 会被转化为 {"id", ...},如果要进一步提取User中的id,可以把User[]改为User-id[] |
| 匹配选项范围 | "key{}":[],后面是JSONArray,作为key可取的值的选项 | "id{}":[38710,82001,70793](opens new window) ,对应SQL是 ,查询id符合38710,82001,70793中任意一个的一个User数组 |
| 匹配条件范围 | "key{}":"条件0,条件1...",条件为SQL表达式字符串,可进行数字比较运算等 | "id{}":"<=80000,>90000"(opens new window) ,对应SQL是 ,查询id符合id<=80000 | id>90000的一个User数组 |
| 包含选项范围 | "key<>":Object => "key<>":[Object],key对应值的类型必须为JSONArray,Object类型不能为JSON | "contactIdList<>":38710(opens new window) ,对应SQL是 ,查询contactIdList包含38710的一个User数组 |
| 判断是否存在 | "key}{@":{ | "id}{@":{ "from":"Comment", "Comment":{ "momentId":15 }}(opens new window)
|
| 远程调用函数 | "key()":"函数表达式",函数表达式为 function(key0,key1...),会调用后端对应的函数 function(JSONObject request, String key0, String key1...),实现 参数校验、数值计算、数据同步、消息推送、字段拼接、结构变换 等特定的业务逻辑处理, | "isPraised()":"isContain(praiseUserIdList,userId)"(opens new window) ,会调用远程函数 boolean isContain(JSONObject request, String array, String value) ,然后变为 "isPraised":true 这种(假设点赞用户id列表包含了userId,即这个User点了赞) |
| 存储过程 | "@key()":"SQL函数表达式",函数表达式为 | "@limit":10,"@offset":0,"@procedure()":"getCommentByUserId(id,@limit,@offset)"(opens new window)
|
| 引用赋值 | "key@":"key0/key1/.../refKey",引用路径为用/分隔的字符串。以/开头的是缺省引用路径,从声明key所处容器的父容器路径开始;其它是完整引用路径,从最外层开始。 | "Moment":{ "userId":38710},"User":{ "id@":"/Moment/userId"}(opens new window)
|
| 子查询 | "key@":{ | "id@":{ "from":"Comment", "Comment":{ "@column":"min(userId)" }}(opens new window)
|
| 模糊搜索 | "key$":"SQL搜索表达式" => "key$":["SQL搜索表达式"],任意SQL搜索表达式字符串,如 %key%(包含key), key%(以key开始), %k%e%y%(包含字母k,e,y) 等,%表示任意字符 | "name$":"%m%"(opens new window) ,对应SQL是 ,查询name包含"m"的一个User数组 |
| 正则匹配 | "key~":"正则表达式" => "key~":["正则表达式"],任意正则表达式字符串,如 ^[0-9]+$ ,*~ 忽略大小写,可用于高级搜索 | "name~":"^[0-9]+$"(opens new window) ,对应SQL是 ,查询name中字符全为数字的一个User数组 |
| 连续范围 | "key%":"start,end" => "key%":["start,end"],其中 start 和 end 都只能为 Boolean, Number, String 中的一种,如 "2017-01-01,2019-01-01" ,["1,90000", "82001,100000"] ,可用于连续范围内的筛选 | "date%":"2017-10-01,2018-10-01"(opens new window) ,对应SQL是 ,查询在2017-10-01和2018-10-01期间注册的用户的一个User数组 |
| 新建别名 | "name:alias",name映射为alias,用alias替代name。可用于 column,Table,SQL函数 等。只用于GET类型、HEAD类型的请求 | "@column":"toId:parentId"(opens new window) ,对应SQL是 ,将查询的字段toId变为parentId返回 |
| 增加 或 扩展 | "key+":Object,Object的类型由key指定,且类型为Number,String,JSONArray中的一种。如 82001,"apijson",["url0","url1"] 等。只用于PUT请求 | "praiseUserIdList+":[82001],对应SQL是 ,添加一个点赞用户id,即这个用户点了赞 |
| 减少 或 去除 | "key-":Object,与"key+"相反 | "balance-":100.00,对应SQL是 ,余额减少100.00,即花费了100元 |
| 比较运算 | >, <, >=, <= 比较运算符,用于 | ① "id<=":90000(opens new window) ,对应SQL是 ,查询符合id<=90000的一个User数组
|
| 逻辑运算 | &, |, ! 逻辑运算符,对应数据库 SQL 中的 AND, OR, NOT。 | ① "id&{}":">80000,<=90000"(opens new window) ,对应SQL是 ,即id满足id>80000 & id<=90000 ,同"id{}":">90000,<=80000",对应SQL是 ,即id满足id>90000 | id<=80000 ,对应SQL是 ,即id满足 ! (id=82001 | id=38710),可过滤黑名单的消息 |
| 数组关键词,可自定义 | "key":Object,key为 "[]":{} 中{}内的关键词,Object的类型由key指定
| ① 查询User数组,最多5个:
|
| 对象关键词,可自定义 | "@key":Object,@key为 Table:{} 中{}内的关键词,Object的类型由@key指定 | ① 搜索name或tag任何一个字段包含字符a的User列表:
|
| 全局关键词 | 为最外层对象 {} 内的关键词。其中 @database,@schema, @datasource, @role, @explain 基本同对象关键词,见上方说明,区别是全局关键词会每个表对象中没有时自动放入,作为默认值。 | ① 查隐私信息:
|
适用场景
- 全栈开发一个小型web 项目:初识APIJSON,我认为APIJSON 可以大大简化后端,但需要前端同学学习APIJSON 定义的JSON 协议规则语法,以及需要前端同学对数据库操作语法有一定的理解。所以目前看来,我让前端同学直接从原有开发模式转成基于APIJSON 的开发是不现实的。所以我认为APIJSON 更适合个人全栈开发一个小型的web 项目。
- 报表类服务:报表类服务没有复杂的项目逻辑,大多数是基于数据的查询,APIJSON 比较适合。
- 数据维护服务:数据维护服务没有复杂的项目逻辑,大多数是基于数据的增删改查操作,APIJSON 比较适合。
项目重构思路
本人后续准备对APIJSON项目进行重构,编写一个基于APIJSON的开源项目:easy-APIJSON,重构的内容列表包括:
1. 使用配置文件的方式封装APIJSON-ORM 中AbstractSQLConfig 中关于数据库关键字,函数,运算符的配置,我想以文本文档的方式将这些内容封装整理,方便后续的软件维护工作
2. 整体重构 APIJSON-framework
- 去掉强相关的数据库依赖,以及单元测试依赖等;去掉APIJSON-framework 关于权限校验,请求校验等基于数据库操作的内容。
- 将APIJSON-clolumn 的内容集成与APIJSON-framework中;
- 加入通用排序工具,通用分页工具等,丰富APIJSON-framework的内容。

图3.1 easy-APIJSON 架构图
3. 我希望的easy-APIJSON的架构是这样的:easy-APIJSON 整体项目与三方依赖以及数据库无关,APIJSON 提供的是通用的处理方法。用户可以自主选择技术实现方案,如采用数据库配置、代码配置或文件配置等方式去实现某个功能。
4. 基于easy-APIJSON,APIJSON-builder 提供前端明确的语法文档和示例,在easy-APIJSON运行时可提供网页文档。
参考文献
APIJSON 官方网站:腾讯APIJSON官方网站
APIJSON 官方文档:介绍 | apijson-doc